Download as PDF, PPTX





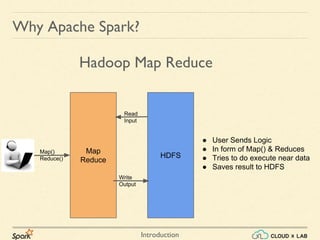
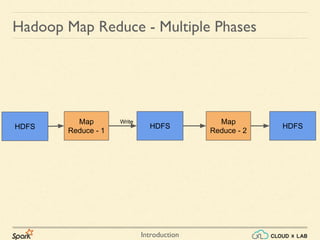

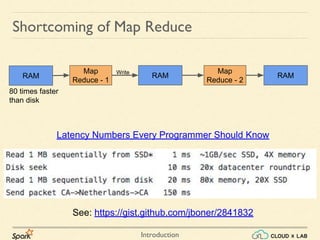

![Introduction
1. Find out hadoop version:
○ [student@hadoop1 ~]$ hadoop version
○ Hadoop 2.4.0.2.1.4.0-632
2. Go to https://spark.apache.org/downloads.html
3. Select the release for your version of hadoop & Download
4. On servers you could use wget
5. Every download can be run in standalone mode
6. Unzip - tar -xzvf spark*.tgz
7. In this folder, the bin folder contains the spark commands
Getting Started - Downloading](https://image.slidesharecdn.com/s0-180514105344/85/Apache-Spark-Introduction-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-10-320.jpg)

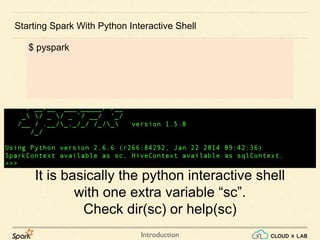






Apache Spark is a fast data processing engine that outperforms Hadoop MapReduce by being 100 times faster in-memory and 10 times faster on disk, built on similar paradigms. The document discusses the shortcomings of MapReduce, such as heavy latency and the difficulty of converting logic to its paradigm, while highlighting Spark's ability to perform in-memory computing. It also provides guidance on getting started with Spark on CloudxLab, including installation steps and commands for running Spark applications.














































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)







































