Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
MN
Uploaded by
Masato Nakai
PDF, PPTX
6,689 views
Inverse Reinforcement On POMDP
Describe Inverse Reinforcement and Probabilistic Robotics
Data & Analytics
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PDF
線形計画法入門
by
Shunji Umetani
PDF
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
PPTX
確率ロボティクス第八回
by
Ryuichi Ueda
PDF
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PDF
強化学習@PyData.Tokyo
by
Naoto Yoshida
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
線形計画法入門
by
Shunji Umetani
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
確率ロボティクス第八回
by
Ryuichi Ueda
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
報酬設計と逆強化学習
by
Yusuke Nakata
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
強化学習@PyData.Tokyo
by
Naoto Yoshida
Similar to Inverse Reinforcement On POMDP
PDF
強化学習勉強会_No1@産総研
by
robotpaperchallenge
PPTX
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
PPTX
強化学習1章
by
hiroki yamaoka
PPT
Reinforcement learning
by
Hirotoka Sakatani
PPT
Reinforcement learning
by
Hirotoka Sakatani
PDF
未来画像予測モデルと時間重み付けを導入した価値関数に基づく強化学習
by
MILab
PDF
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
by
Eiji Uchibe
PDF
Study aiラビットチャレンジ 深層学習Day4
by
Naoki Nishikawa
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course)
by
hirokazutanaka
PPTX
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
PDF
「これからの強化学習」勉強会#1
by
Chihiro Kusunoki
DOCX
レポート深層学習Day4
by
ssuser9d95b3
PPTX
強化学習 と ゲーム理論 (MARL)
by
HarukaKiyohara
PDF
Never give up
by
harmonylab
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
by
Shota Imai
PDF
強化学習その5
by
Hirokazu Nishio
PDF
強化学習その5
by
nishio
PDF
強化学習メモスライド
by
twiponta_suzuki
PDF
報酬が殆ど得られない場合の強化学習
by
Masato Nakai
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
強化学習勉強会_No1@産総研
by
robotpaperchallenge
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
強化学習1章
by
hiroki yamaoka
Reinforcement learning
by
Hirotoka Sakatani
Reinforcement learning
by
Hirotoka Sakatani
未来画像予測モデルと時間重み付けを導入した価値関数に基づく強化学習
by
MILab
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
by
Eiji Uchibe
Study aiラビットチャレンジ 深層学習Day4
by
Naoki Nishikawa
Computational Motor Control: Reinforcement Learning (JAIST summer course)
by
hirokazutanaka
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
「これからの強化学習」勉強会#1
by
Chihiro Kusunoki
レポート深層学習Day4
by
ssuser9d95b3
強化学習 と ゲーム理論 (MARL)
by
HarukaKiyohara
Never give up
by
harmonylab
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
by
Shota Imai
強化学習その5
by
Hirokazu Nishio
強化学習その5
by
nishio
強化学習メモスライド
by
twiponta_suzuki
報酬が殆ど得られない場合の強化学習
by
Masato Nakai
多様な強化学習の概念と課題認識
by
佑 甲野
More from Masato Nakai
PDF
Padoc_presen4R.pdf
by
Masato Nakai
PDF
Factor analysis for ml by padoc 6 r
by
Masato Nakai
PDF
Padocview anonimous2
by
Masato Nakai
PDF
presentation for padoc
by
Masato Nakai
PDF
Ai neuro science_pdf
by
Masato Nakai
PDF
Deep IRL by C language
by
Masato Nakai
PDF
Open pose時系列解析7
by
Masato Nakai
PDF
Team ai 3
by
Masato Nakai
PDF
Semi vae memo (2)
by
Masato Nakai
PDF
Open posedoc
by
Masato Nakai
PPT
Dr.raios papers
by
Masato Nakai
PDF
Deep genenergyprobdoc
by
Masato Nakai
PDF
Irs gan doc
by
Masato Nakai
PDF
Semi vae memo (1)
by
Masato Nakai
PDF
Ai論文サイト
by
Masato Nakai
PDF
Vae gan nlp
by
Masato Nakai
PDF
機械学習の全般について 4
by
Masato Nakai
PDF
Word2vecの理論背景
by
Masato Nakai
PDF
粒子フィルターによる自動運転
by
Masato Nakai
PDF
Icpによる原画像推定
by
Masato Nakai
Padoc_presen4R.pdf
by
Masato Nakai
Factor analysis for ml by padoc 6 r
by
Masato Nakai
Padocview anonimous2
by
Masato Nakai
presentation for padoc
by
Masato Nakai
Ai neuro science_pdf
by
Masato Nakai
Deep IRL by C language
by
Masato Nakai
Open pose時系列解析7
by
Masato Nakai
Team ai 3
by
Masato Nakai
Semi vae memo (2)
by
Masato Nakai
Open posedoc
by
Masato Nakai
Dr.raios papers
by
Masato Nakai
Deep genenergyprobdoc
by
Masato Nakai
Irs gan doc
by
Masato Nakai
Semi vae memo (1)
by
Masato Nakai
Ai論文サイト
by
Masato Nakai
Vae gan nlp
by
Masato Nakai
機械学習の全般について 4
by
Masato Nakai
Word2vecの理論背景
by
Masato Nakai
粒子フィルターによる自動運転
by
Masato Nakai
Icpによる原画像推定
by
Masato Nakai
Inverse Reinforcement On POMDP
1.
強化確率ロボットモデルでの 逆強化学習について 2016/01/31 @mabonakai0725
2.
趣旨 1.自立的ロボット(工作機械、自動運転)は PO-MDFのアルゴリズムで一般に記述できる POMDF:Partially Observable Markov
Dicsion Process 2.MDFはML(パターン認識)に報酬と戦略の要 素を入れた最適化技術である 3.POは部分的な観察により確信度を更新する ベイズモデル 4.最近は報酬も戦略も行動データから学習でき る(報酬を学習する逆強化学習論文紹介) Googleの碁ロボット(AlphaGo)も同様の方法
3.
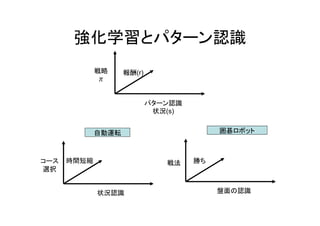
強化学習とパターン認識 報酬(r) パターン認識 状況(s) 戦略 π 時間短縮 状況認識 コース 選択 勝ち 盤面の認識 自動運転 囲碁ロボット 戦法
4.
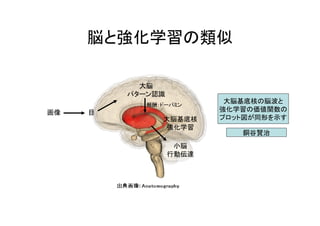
脳と強化学習の類似 大脳 パターン認識 画像 小脳 行動伝達 大脳基底核 強化学習 報酬:ドーパミン 目 大脳基底核の脳波と 強化学習の価値関数の プロット図が同形を示す 銅谷賢治
5.
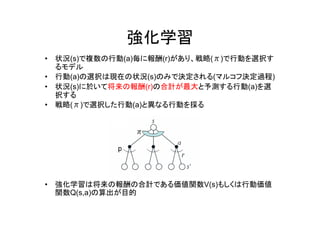
強化学習 • 状況(s)で複数の行動(a)毎に報酬(r)があり、戦略(π)で行動を選択す るモデル • 行動(a)の選択は現在の状況(s)のみで決定される(マルコフ決定過程) •
状況(s)に於いて将来の報酬(r)の合計が最大と予測する行動(a)を選 択する • 戦略(π)で選択した行動(a)と異なる行動を採る • 強化学習は将来の報酬の合計である価値関数V(s)もしくは行動価値 関数Q(s,a)の算出が目的
6.
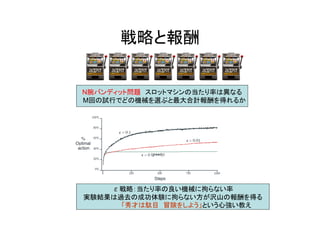
戦略と報酬 N腕バンディット問題 スロットマシンの当たり率は異なる M回の試行でどの機械を選ぶと最大合計報酬を得れるか ε戦略:当たり率の良い機械に拘らない率 実験結果は過去の成功体験に拘らない方が沢山の報酬を得る 「秀才は駄目 冒険をしよう」という心強い教え
7.
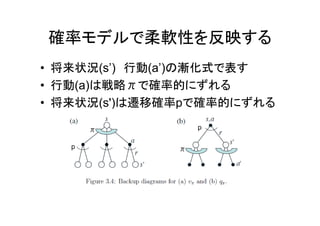
確率モデルで柔軟性を反映する • 将来状況(s’) 行動(a’)の漸化式で表す • 行動(a)は戦略πで確率的にずれる •
将来状況(s')は遷移確率pで確率的にずれる π π π πp p
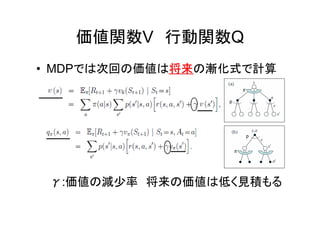
8.
価値関数V 行動関数Q • MDPでは次回の価値は将来将来の漸化式で計算 γ:価値の減少率 将来の価値は低く見積もる
9.
価値関数V 行動関数Qの算出方法 • 将来の状況と行動の分岐を繰返し展開して末端から BackUpで関数を算出する(rollout) •
将来価値にγ:減少率があるので無限に展開しなくて 良い(n期先まで展開)。 – 動的計画法 (遷移を定常になるまで繰返し) – モンテカルロ法 (ランダムに経路を辿り報酬確率を計算) – TD(n)法 (V関数のパラメータをSDGで計算) – Sarsa(n)法(Q関数のパラメータをSDGで計算) – ニューロ法 (Q関数をニューロで汎用化)
10.
DQN(Deep Q-Learning Net) •
行動価値関数QをDeep CNNで訓練する ゲーム画面 最適操作
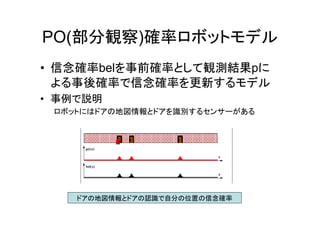
11.
PO(部分観察)確率ロボットモデル • 信念確率belを事前確率として観測結果pに よる事後確率で信念確率を更新するモデル • 事例で説明 ロボットにはドアの地図情報とドアを識別するセンサーがある ドアの地図情報とドアの認識で自分の位置の信念確率
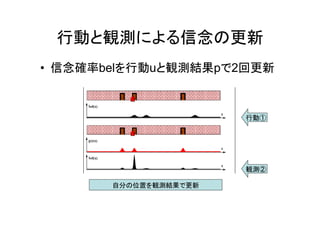
12.
行動と観測による信念の更新 • 信念確率belを行動uと観測結果pで2回更新 自分の位置を観測結果で更新 行動① 観測②
13.
ベイズ信念更新アルゴリズム 3行目 行動uによる状況xに対する信念の更新 矢印① 4行目 観測pによる状況xに対する信念の更新 矢印②
14.
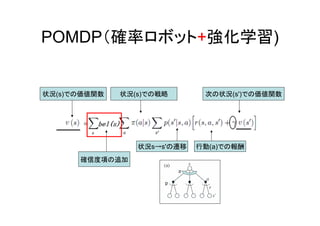
POMDP(確率ロボット+強化学習) 確信度項の追加 状況(s)での価値関数 次の状況(s')での価値関数 行動(a)での報酬 状況(s)での戦略 状況s→s'の遷移
15.
逆強化学習(報酬の学習) • ゲームでは報酬は得点として明らか • 現実の世界では報酬は不明 ↓ •
複数の専門家(熟練者)の行動データから報 酬を学習するのが逆強化学習(IRL) • 文献の紹介 – Maximum Entropy Deep Inverse Reinforcement Learning (ICPR2015) – Inverse Reinforcement Learning with Locally Consistent Reward Functions (NIPS2015)
16.
Maximum Entropy Deep
Inverse Reinforcement Learning 報酬の累計が最大になる様にθをDeep NNの重みとして解く 報酬の累計 尤度の式 Dは熟練者のデータ θの微分値 熟練者のデータ 報酬 θの繰返し更新 特徴量 報酬の関数 backup
17.
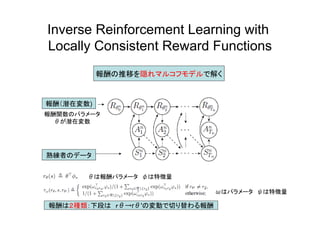
Inverse Reinforcement Learning
with Locally Consistent Reward Functions 報酬の推移を隠れマルコフモデルで解く 報酬(潜在変数) 熟練者のデータ 報酬は2種類:下段は rθ→rθ'の変動で切り替わる報酬 報酬関数のパラメータ θが潜在変数 θは報酬パラメータ φは特徴量 ωはパラメータ ψは特徴量
18.
まとめ • 限られたセンサデータから自立的に動くロボットのモ デルはPOMDPで一般に記述できる • POMDPでは、将来の価値の漸化式を解き累計価 値の予測をする必要がある •
ゲームではDeepLearningを使うとゲーム画面と最 高点が得た操作を対で学習させてモデル化できる • 現実の問題では報酬(得点)が不明なので専門家 (熟練者)のデータから報酬を推定できる逆強化学 習の仕組みが有効である
Download














![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)








































