This document discusses syntax analysis in language processing. It covers lexical analysis, which breaks programs into tokens, and parsing, which analyzes syntax based on context-free grammars. Lexical analysis uses state machines or tables to recognize patterns in code. Parsing can be done top-down with recursive descent or bottom-up with LR parsers that shift and reduce based on lookahead. Well-formed grammars and separation of lexical and syntax analysis enable efficient parsing.












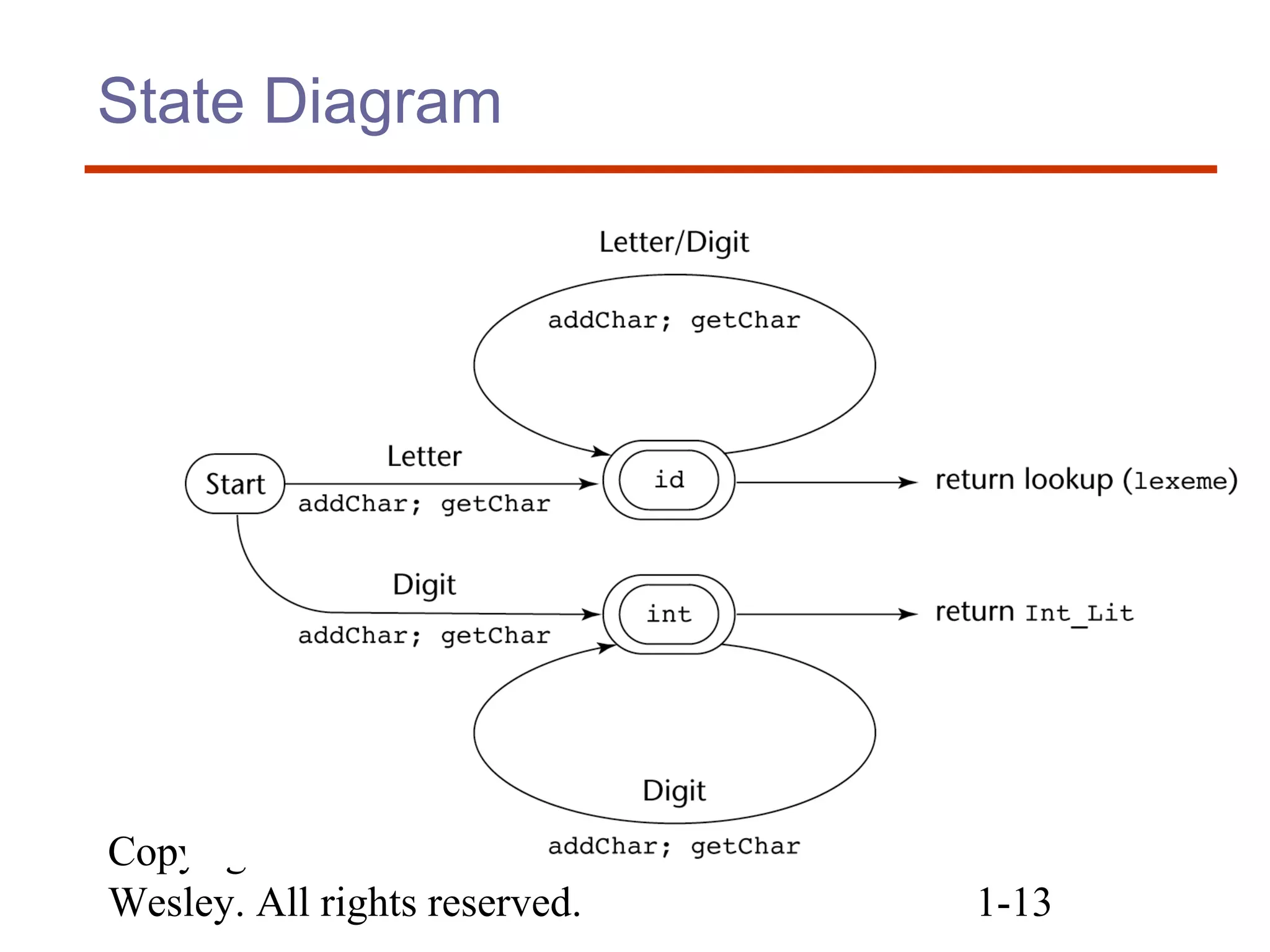
![Copyright © 2007 Addison-
Wesley. All rights reserved. 1-14
Lexical Analysis (cont.)
Implementation (assume initialization):
/* Global variables */
int charClass;
char lexeme [100];
char nextChar;
int lexLen;
int Letter = 0;
int DIGIT = 1;
int UNKNOWN = -1;](https://image.slidesharecdn.com/4lexicalandsyntax-170401094733/75/4-lexical-and-syntax-14-2048.jpg)























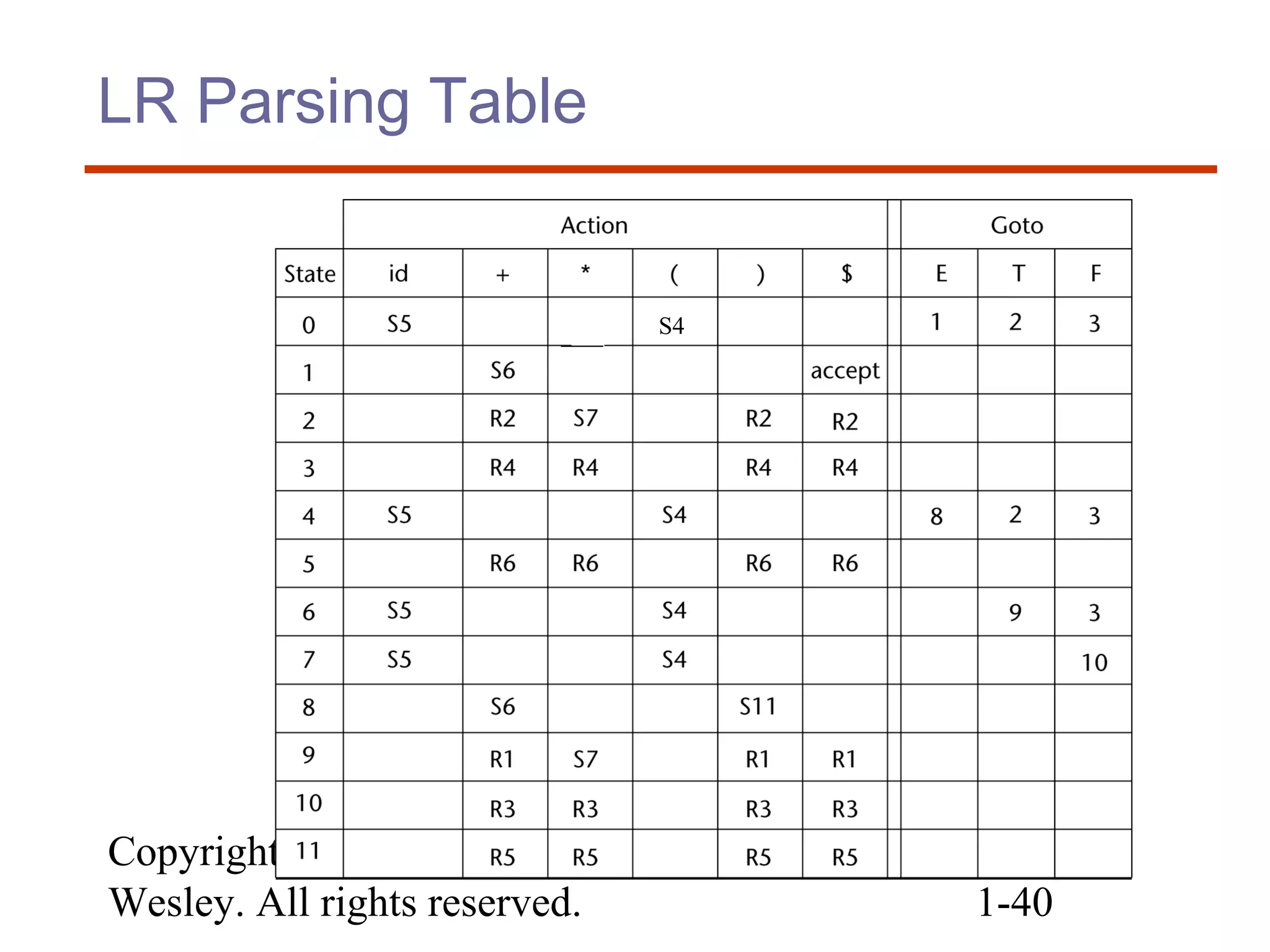
![Copyright © 2007 Addison-
Wesley. All rights reserved. 1-38
Bottom-up Parsing (cont.)
• Parser actions (continued):
– If ACTION[Sm, ai] = Accept, the parse is complete and
no errors were found.
– If ACTION[Sm, ai] = Error, the parser calls an error-
handling routine.](https://image.slidesharecdn.com/4lexicalandsyntax-170401094733/75/4-lexical-and-syntax-38-2048.jpg)