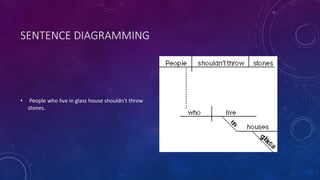
Lexing and parsing involves breaking down input like code, markup languages, or configuration files into individual tokens and analyzing the syntax and structure according to formal grammars. Common techniques include using lexer generators to tokenize input and parser generators to construct parse trees and abstract syntax trees based on formal grammars. While regular expressions are sometimes useful, lexers and parsers are better suited for many formal language tasks and ensure well-formed syntax.









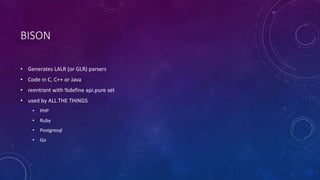
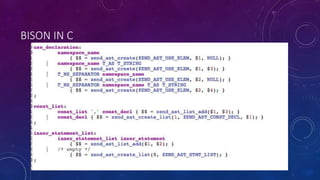
![LEXING PHP - $Y = 5;
• $y
• array[309, ‘$y’, 1],
• =
• =
• 5
• array[305, 5, 1]
• 309 == T_VARIABLE
• 305 == T_LNUMBER](https://image.slidesharecdn.com/lexingandparsing-141031111011-conversion-gate01/85/Lexing-and-parsing-11-320.jpg)


































![Inside Python [OSCON 2012]](https://cdn.slidesharecdn.com/ss_thumbnails/insidepythonpresentation-120724001527-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![Inside PHP [OSCON 2012]](https://cdn.slidesharecdn.com/ss_thumbnails/insidephppresentation-120724002136-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[Infographic] How will Internet of Things (IoT) change the world as we know it?](https://cdn.slidesharecdn.com/ss_thumbnails/iotinfographicv3-160309101328-thumbnail.jpg?width=640&height=640&fit=bounds)











































































