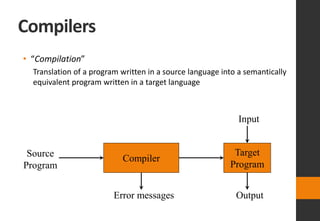
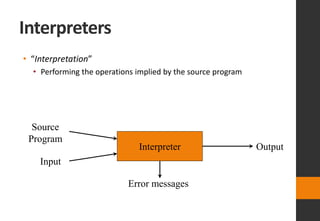
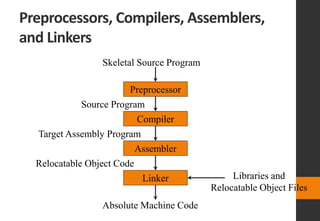
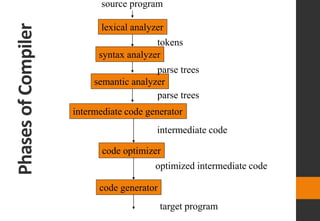
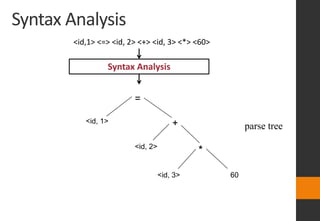
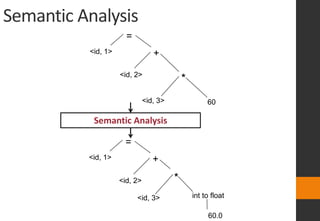
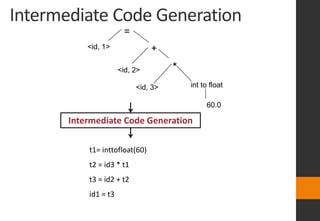
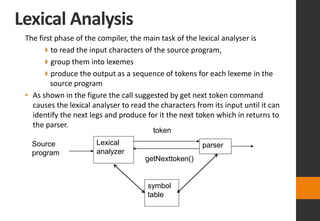
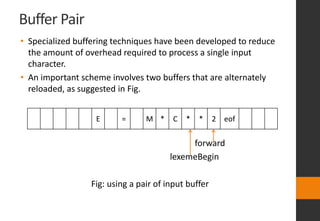
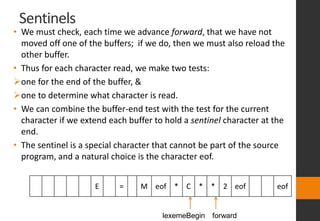
The document discusses lexical analysis in compilers. It begins with an overview of lexical analysis and its role as the first phase of a compiler. It describes how a lexical analyzer works by reading the source program as a stream of characters and grouping them into lexemes (tokens). Regular expressions are used to specify patterns for tokens. The document then discusses specific topics like lexical errors, input buffering techniques, specification of tokens using regular expressions and grammars, recognition of tokens using transition diagrams, and the transition diagram for identifiers and keywords.

























![Ex 1:
letters A|B|……|Z|a|b|…..|z|_
digit 0|1|2|…|9
id letter (letter|digit)
Updated to
• letter [A-Za-z_]
• digit [0-9]
• id letter (letter|digit)*](https://image.slidesharecdn.com/module22018-210520093255/85/Module-2-35-320.jpg)
![Ex 2:
digit 0|1|2|….|9
digits digit digit*
optionalFraction . digit |
optinalExponent (e|E(+|-| )digits) |
number digits optionalFraction optinalExponent
Updated to
• digit [0-9]
• digits digit+
• number digits(.digits)? (e|E[+-]? digits )?](https://image.slidesharecdn.com/module22018-210520093255/85/Module-2-36-320.jpg)



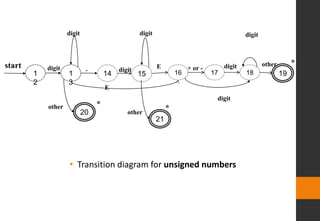
![digit [0-9]
digits digit+
number digits(.digits)? (e[+-]? digits )?
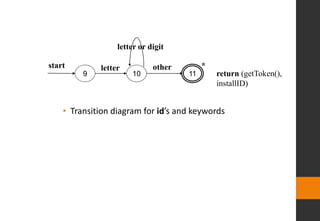
letter [A-Za-z_]
id letter (letter|digit)*
if if
then then
else else
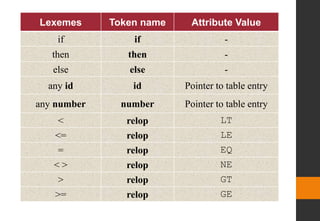
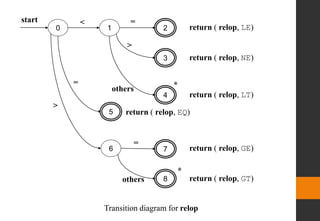
relop < | > | <= | >= | = | < >
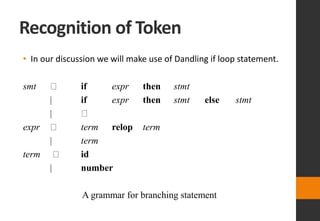
Patterns for token for if-else-then statement
For this language, the lexical analyzer will recognize the keywords
if, then, and else, as well as lexemes that match the
patterns for relop, id, and number](https://image.slidesharecdn.com/module22018-210520093255/85/Module-2-41-320.jpg)