Downloaded 407 times


































































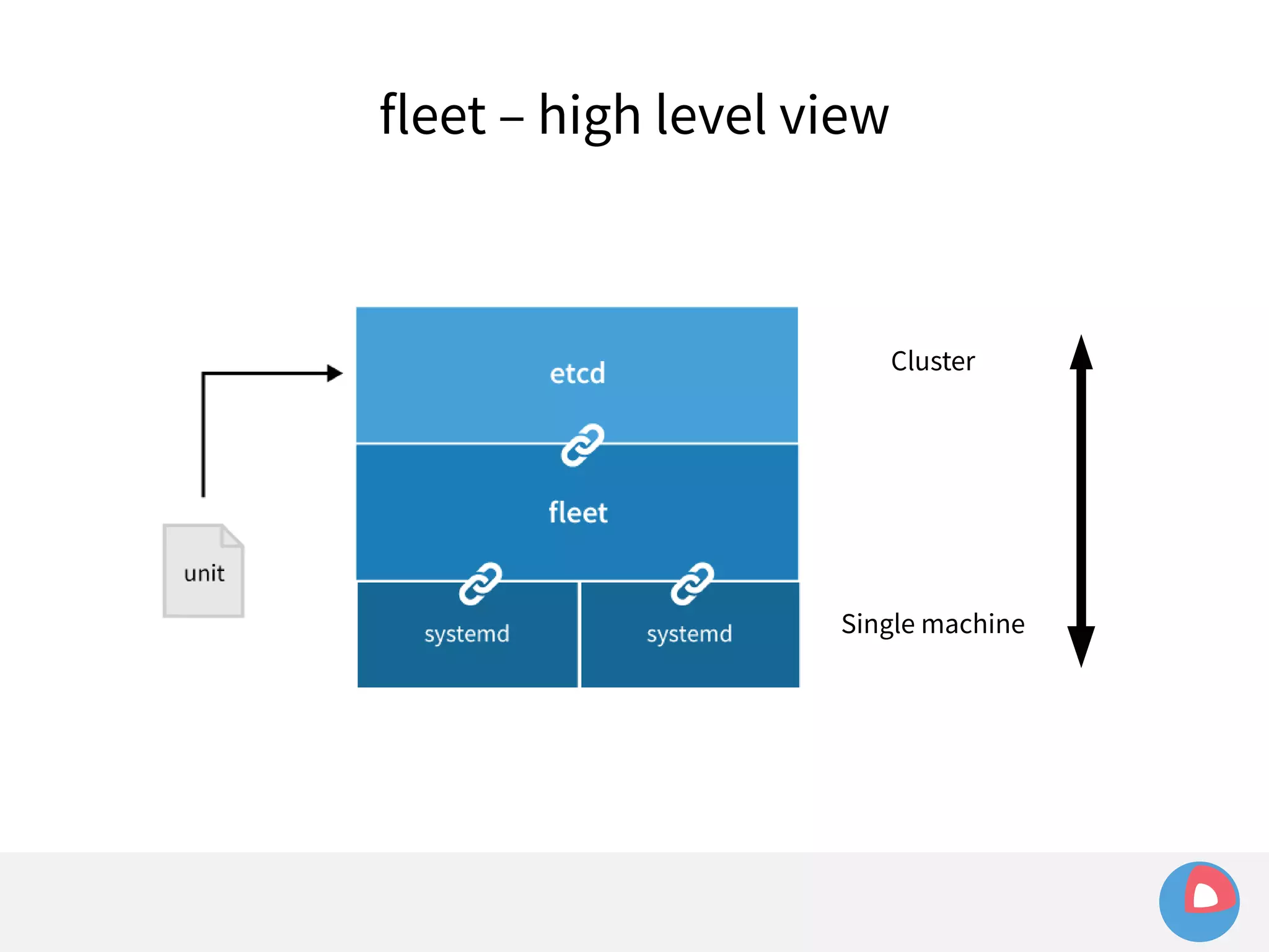


























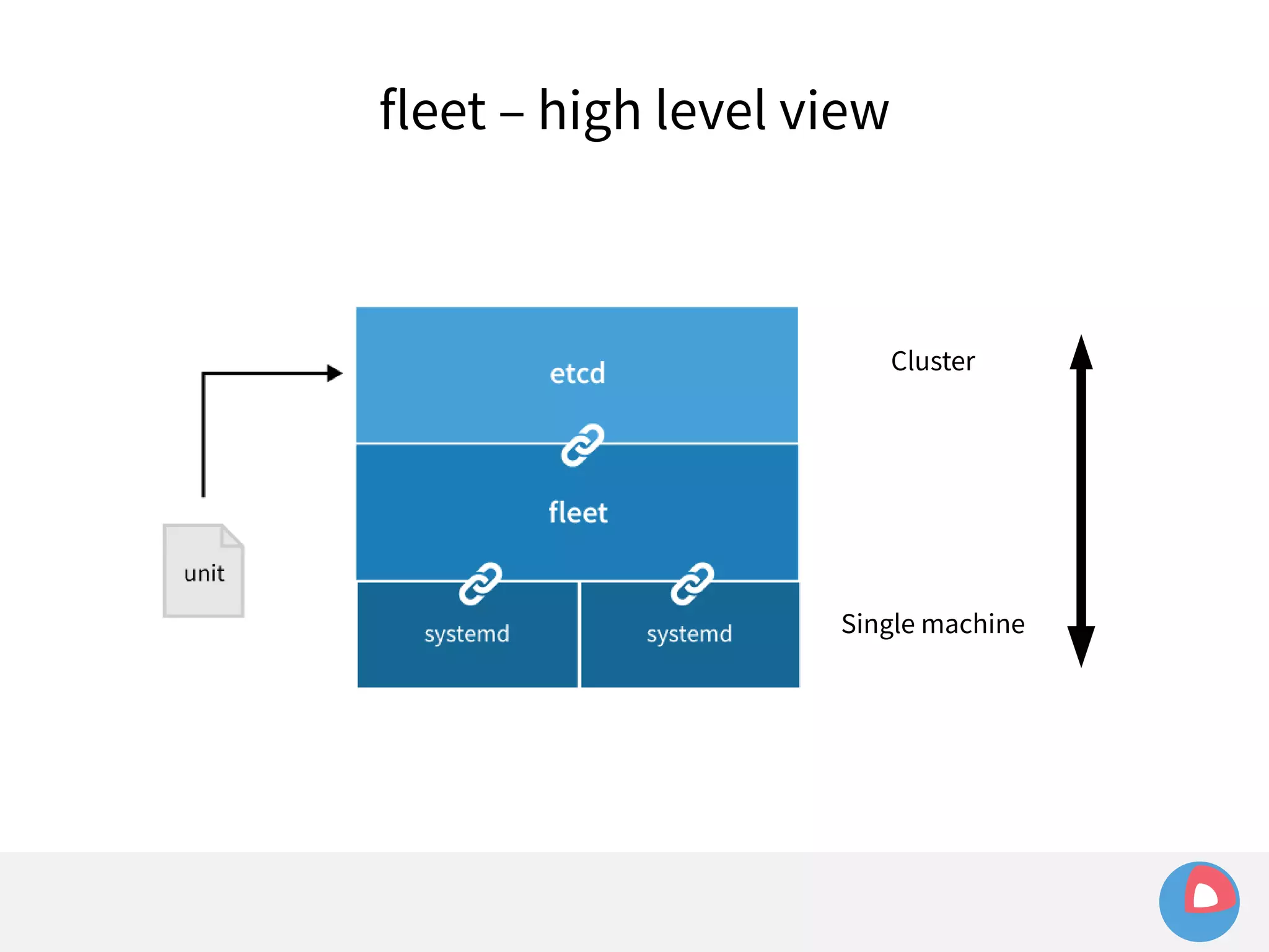
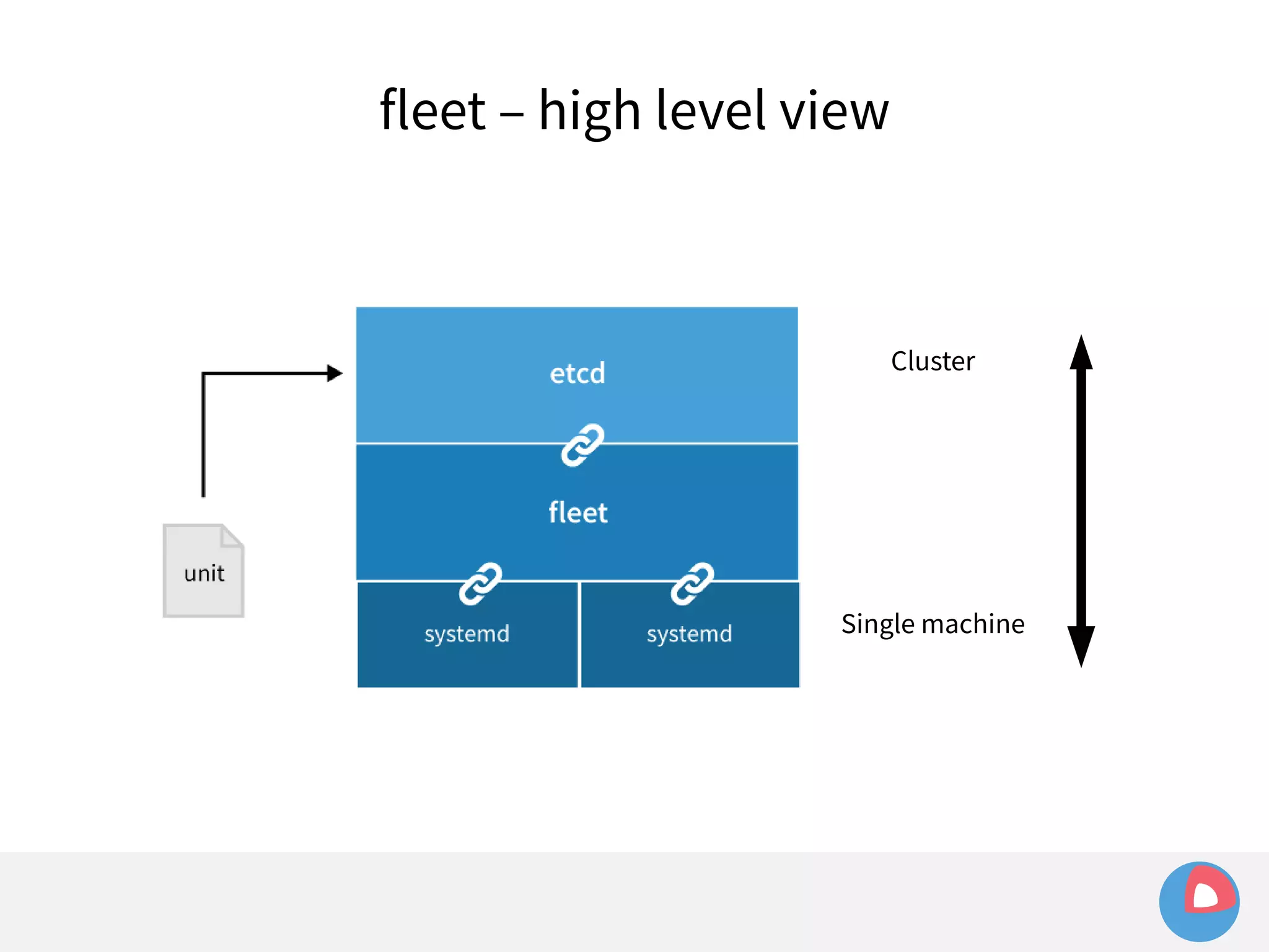
![fleet + systemd
systemd takes care of things so we don't have to
fleet configuration is just systemd unit files
fleet extends systemd to the cluster-level, and adds
some features of its own (using [X-Fleet])](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-119-2048.jpg)
![fleet + systemd
systemd takes care of things so we don't have to
fleet configuration is just systemd unit files
fleet extends systemd to the cluster-level, and adds
some features of its own (using [X-Fleet])
– Template units (run n identical copies of a unit)](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-120-2048.jpg)
![fleet + systemd
systemd takes care of things so we don't have to
fleet configuration is just systemd unit files
fleet extends systemd to the cluster-level, and adds
some features of its own (using [X-Fleet])
– Template units (run n identical copies of a unit)
– Global units (run a unit everywhere in the cluster)](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-121-2048.jpg)
![fleet + systemd
systemd takes care of things so we don't have to
fleet configuration is just systemd unit files
fleet extends systemd to the cluster-level, and adds
some features of its own (using [X-Fleet])
– Template units (run n identical copies of a unit)
– Global units (run a unit everywhere in the cluster)
– Machine metadata (run only on certain machines)](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-122-2048.jpg)


















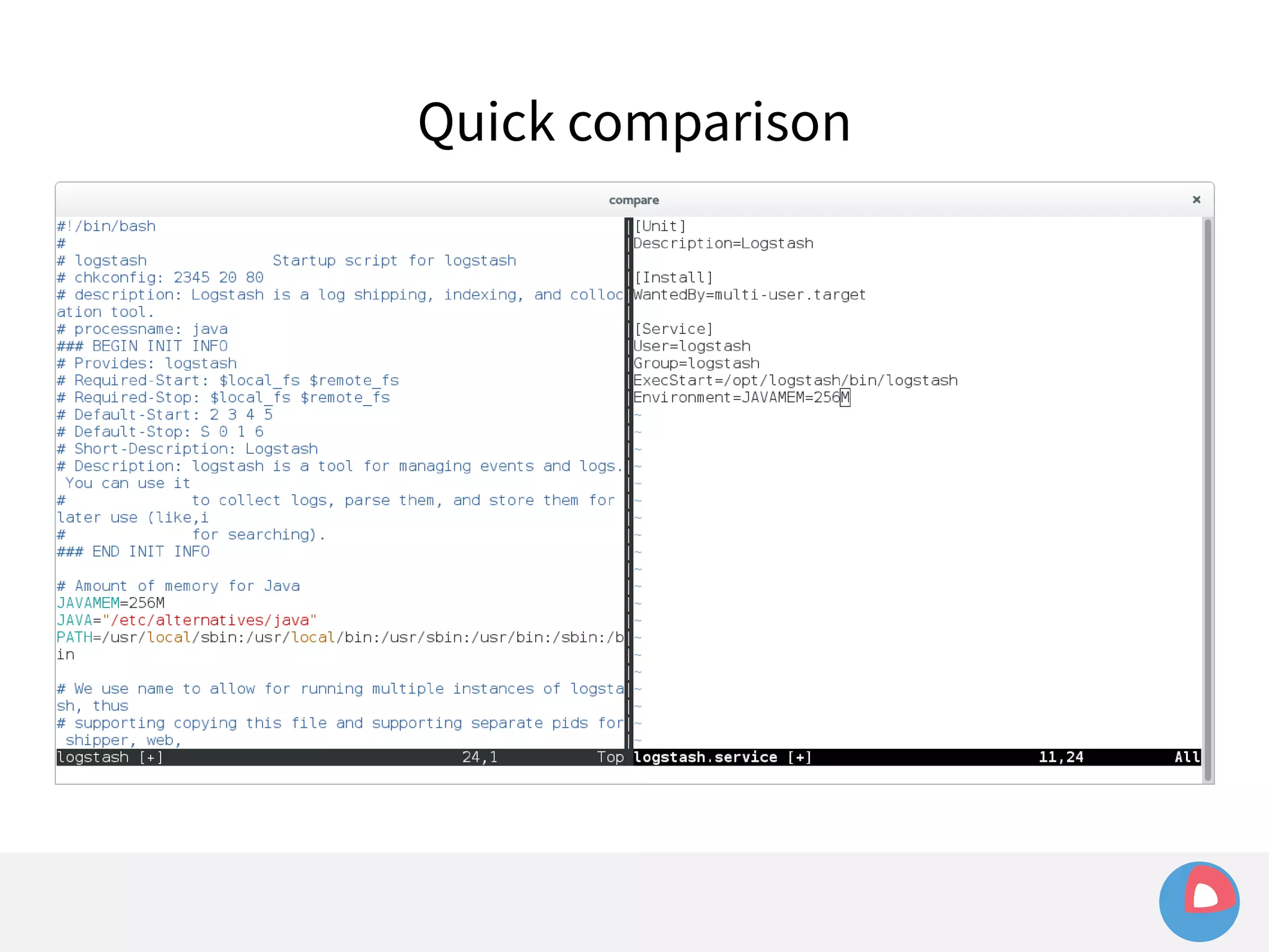
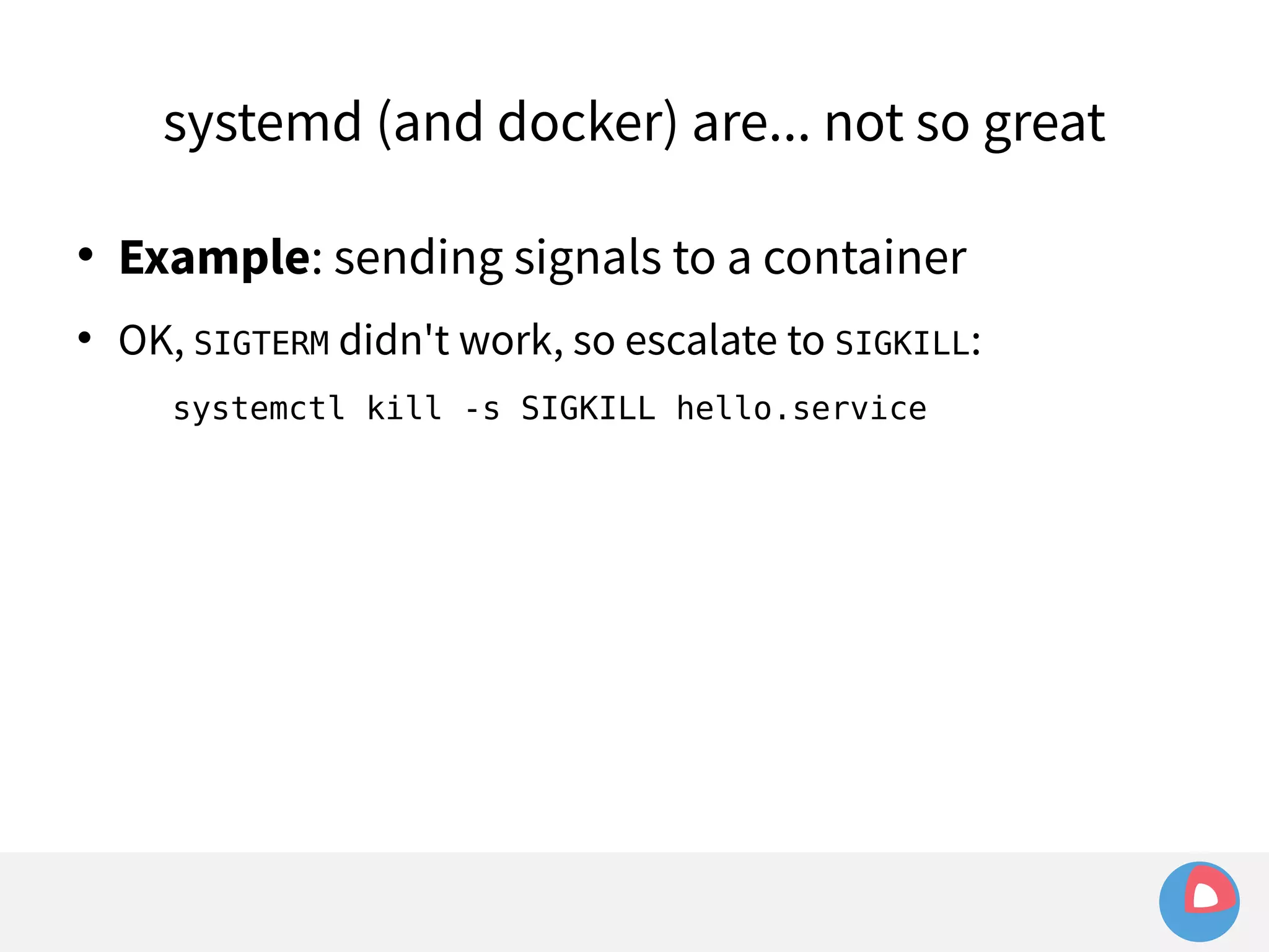
![systemd (and docker) are... not so great
Example: sending signals to a container
– Given a simple container:
[Service]
ExecStart=/usr/bin/docker run busybox /bin/bash -c
"while true; do echo Hello World; sleep 1; done"](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-143-2048.jpg)
![systemd (and docker) are... not so great
Example: sending signals to a container
– Given a simple container:
[Service]
ExecStart=/usr/bin/docker run busybox /bin/bash -c
"while true; do echo Hello World; sleep 1; done"
– Try to kill it with systemctl kill hello.service](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-144-2048.jpg)
![systemd (and docker) are... not so great
Example: sending signals to a container
– Given a simple container:
[Service]
ExecStart=/usr/bin/docker run busybox /bin/bash -c
"while true; do echo Hello World; sleep 1; done"
– Try to kill it with systemctl kill hello.service
– ... Nothing happens](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-145-2048.jpg)
![systemd (and docker) are... not so great
Example: sending signals to a container
– Given a simple container:
[Service]
ExecStart=/usr/bin/docker run busybox /bin/bash -c
"while true; do echo Hello World; sleep 1; done"
– Try to kill it with systemctl kill hello.service
– ... Nothing happens
– Kill command sends SIGTERM, but bash in a Docker
container has PID1, which happily ignores the signal...](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-146-2048.jpg)


![systemd (and docker) are... not so great
Example: sending signals to a container
OK, SIGTERM didn't work, so escalate to SIGKILL:
systemctl kill -s SIGKILL hello.service
● Now the systemd service is gone:
hello.service: main process exited, code=killed, status=9/KILL
● But... the Docker container still exists?
# docker ps
CONTAINER ID COMMAND STATUS NAMES
7c7cf8ffabb6 /bin/sh -c 'while tr Up 31 seconds hello
# ps -ef|grep '[d]ocker run'
root 24231 1 0 03:49 ? 00:00:00 /usr/bin/docker run -name hello ...](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-151-2048.jpg)



![systemd (and docker) are... not so great
# systemctl cat hello.service
[Service]
ExecStart=/bin/bash -c 'while true; do echo Hello World; sleep 1; done'
# systemd-cgls
...
├─hello.service
│ ├─23201 /bin/bash -c while true; do echo Hello World; sleep 1; done
│ └─24023 sleep 1](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-157-2048.jpg)
![systemd (and docker) are... not so great
# systemctl cat hello.service
[Service]
ExecStart=/usr/bin/docker run -name hello busybox /bin/sh -c
"while true; do echo Hello World; sleep 1; done"
# systemd-cgls
...
│ ├─hello.service
│ │ └─24231 /usr/bin/docker run -name hello busybox /bin/sh -c while
true; do echo Hello World; sleep 1; done
...
│ ├─docker-
51a57463047b65487ec80a1dc8b8c9ea14a396c7a49c1e23919d50bdafd4fefb.scope
│ │ ├─24240 /bin/sh -c while true; do echo Hello World; sleep 1; done
│ │ └─24553 sleep 1](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-158-2048.jpg)















































![● Example:
Limited event history
– etcd holds history of last 1000 events
– fleet sets watch at i=100 to watch for machine loss
– Meanwhile, many changes occur in other parts of the
keyspace, advancing index to i=1500
– Leader election/network hiccup occurs and severs watch
– fleet tries to recreate watch at i=100 and fails:
err="401: The event in requested index is outdated and
cleared (the requested history has been cleared [1500/100])](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-214-2048.jpg)















































![Sharing a binary
● client/daemon often share much of the same code
– Encapsulate multiple tools in one binary, symlink the
different command names, switch off command name
– Example: fleetd/fleetctl
func main() {
switch os.Args[0] {
case “fleetctl”:
Fleetctl()
case “fleetd”:
Fleetd()
}
}](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-269-2048.jpg)
![Sharing a binary
● client/daemon often share much of the same code
– Encapsulate multiple tools in one binary, symlink the
different command names, switch off command name
– Example: fleetd/fleetctl
func main() {
switch os.Args[0] {
case “fleetctl”:
Fleetctl()
case “fleetd”:
Fleetd()
}
}
Before:
9150032 fleetctl
8567416 fleetd
After:
11052256 fleetctl
8 fleetd -> fleetctl](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-270-2048.jpg)







![type Command struct {
Name string
Summary string
Usage string
Description string
Flags flag.FlagSet
Run func(args []string) int
}
fleetctl CLI](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-278-2048.jpg)


![Wrap up/recap
CoreOS Linux
– Minimal OS with cluster capabilities built-in
– Containerized applications --> a[u]tom[at]ic updates](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-282-2048.jpg)
![Wrap up/recap
CoreOS Linux
– Minimal OS with cluster capabilities built-in
– Containerized applications --> a[u]tom[at]ic updates
fleet](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-283-2048.jpg)
![Wrap up/recap
CoreOS Linux
– Minimal OS with cluster capabilities built-in
– Containerized applications --> a[u]tom[at]ic updates
fleet
– Simple, powerful cluster-level application manager](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-284-2048.jpg)
![Wrap up/recap
CoreOS Linux
– Minimal OS with cluster capabilities built-in
– Containerized applications --> a[u]tom[at]ic updates
fleet
– Simple, powerful cluster-level application manager
– Glue between local init system (systemd) and cluster-level
awareness (etcd)](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-285-2048.jpg)
![Wrap up/recap
CoreOS Linux
– Minimal OS with cluster capabilities built-in
– Containerized applications --> a[u]tom[at]ic updates
fleet
– Simple, powerful cluster-level application manager
– Glue between local init system (systemd) and cluster-level
awareness (etcd)
– golang++](https://image.slidesharecdn.com/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01/75/2C4-Clustered-computing-with-CoreOS-fleet-and-etcd-286-2048.jpg)




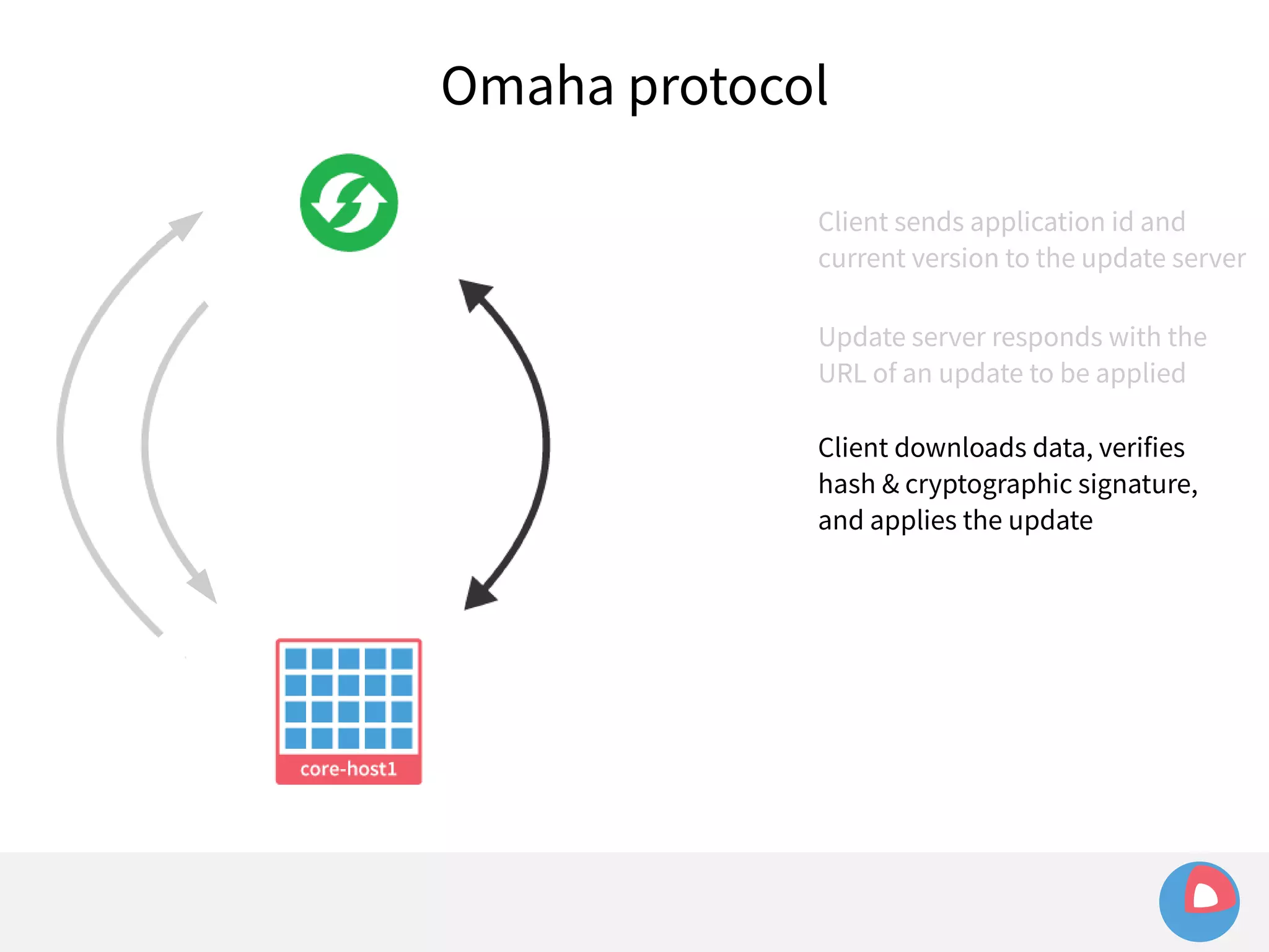
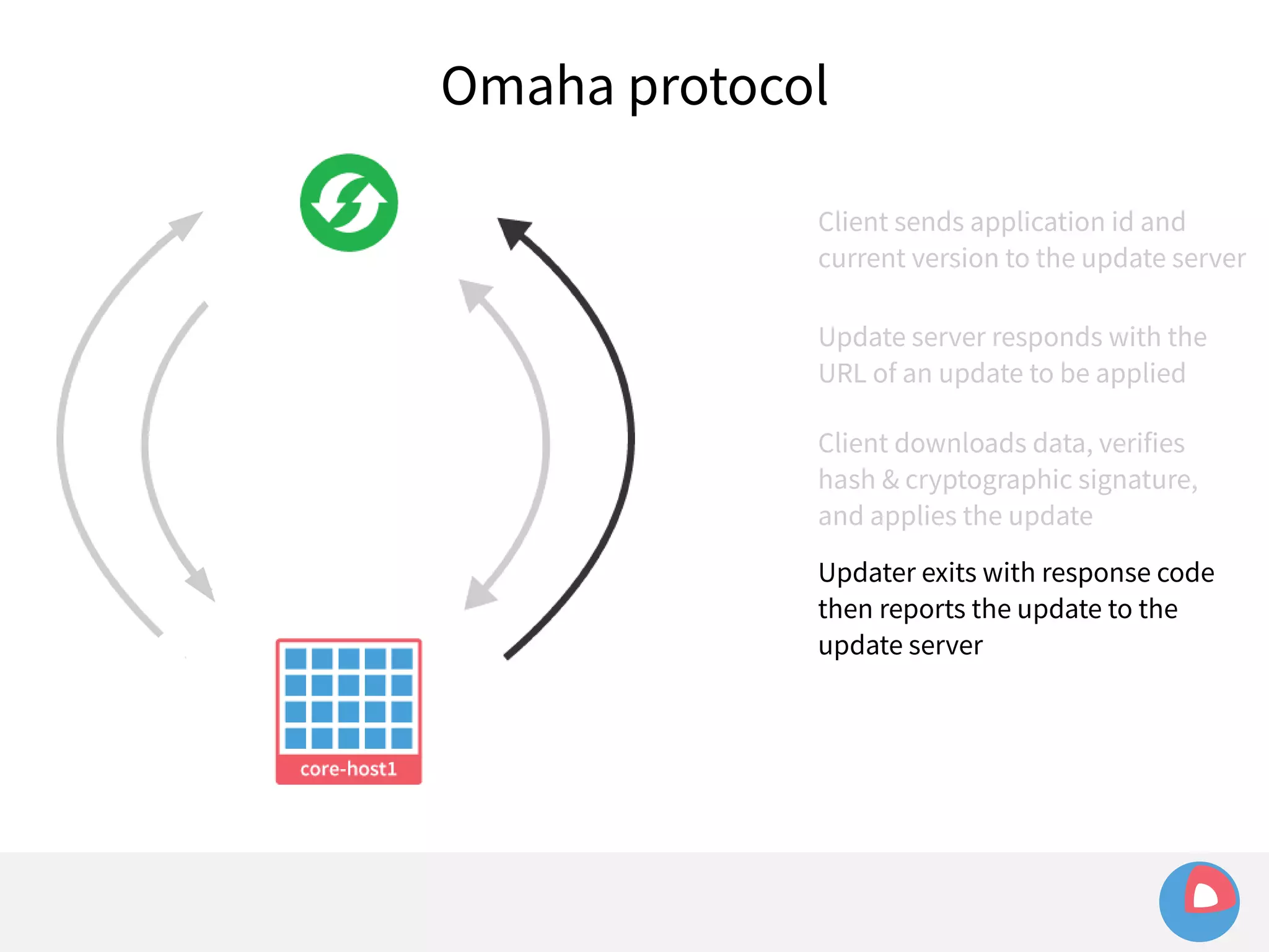
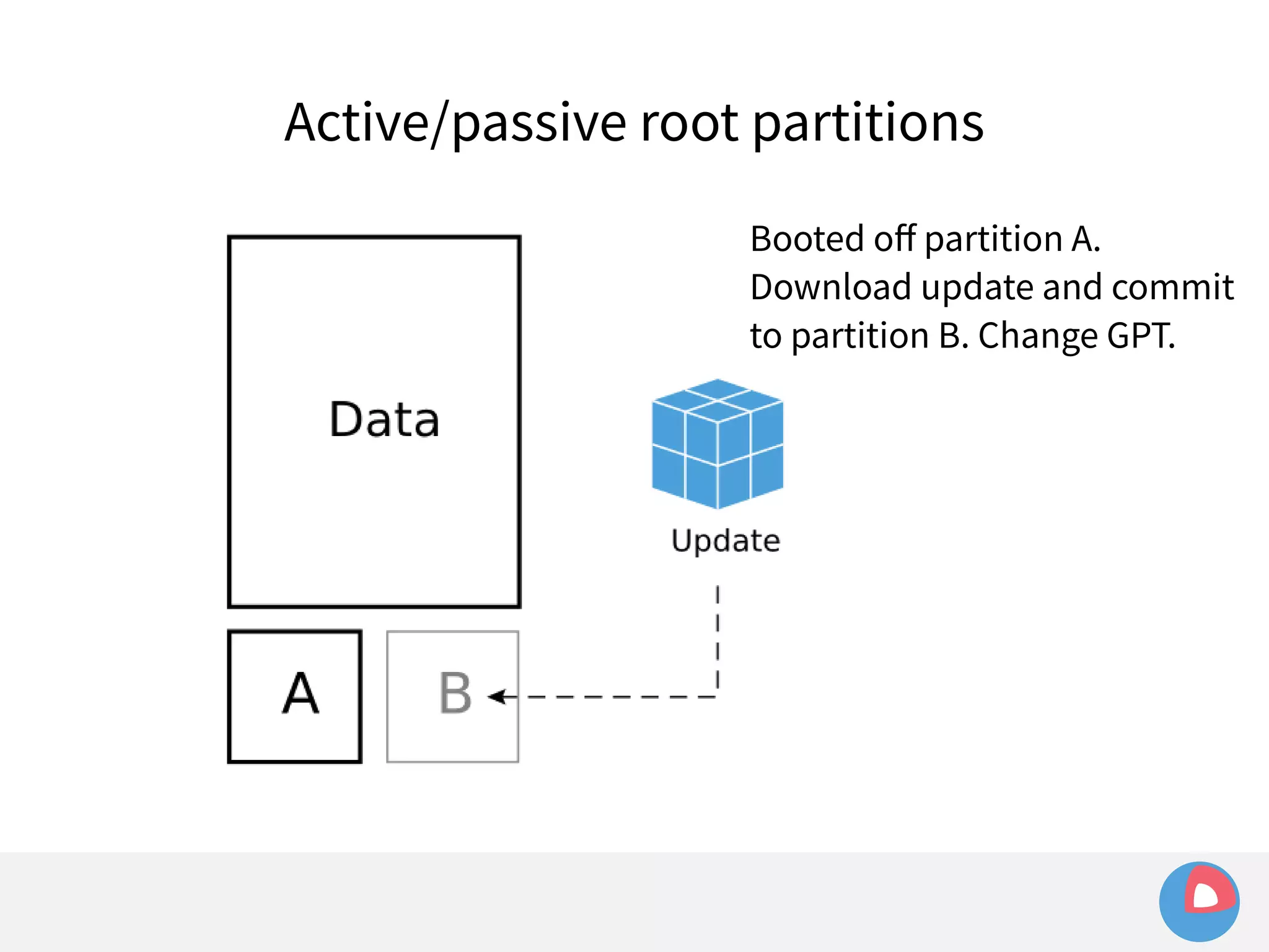
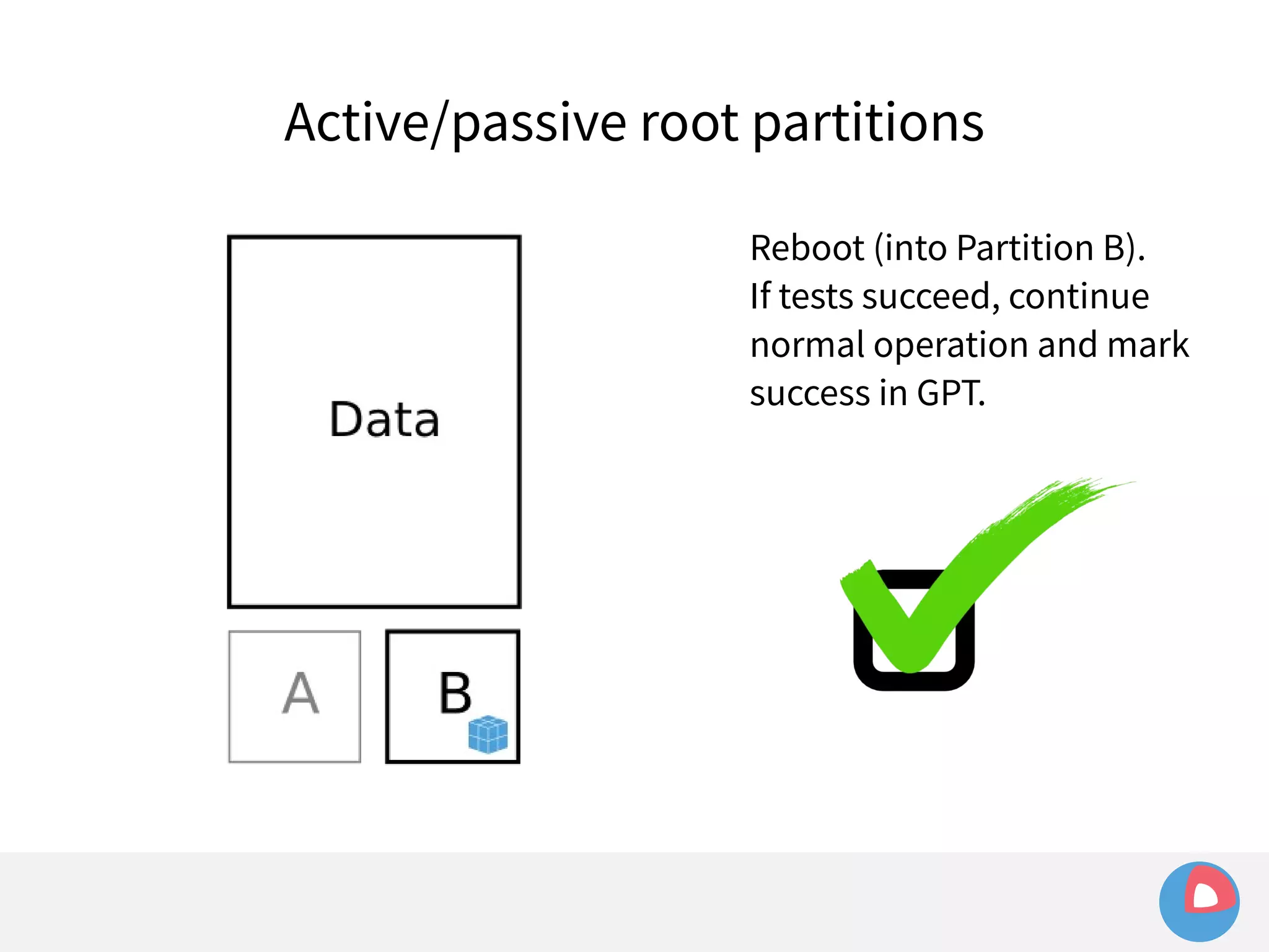
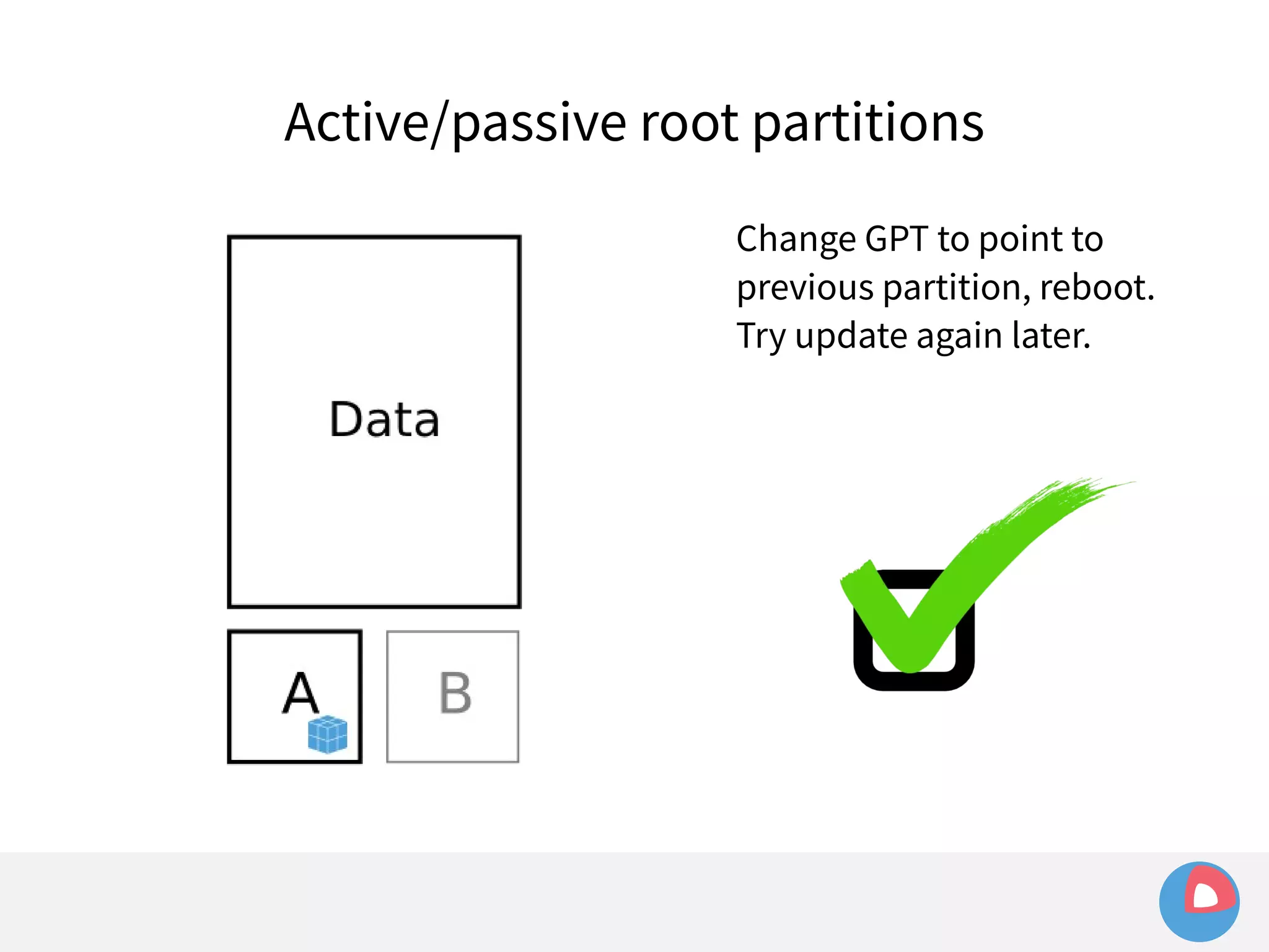
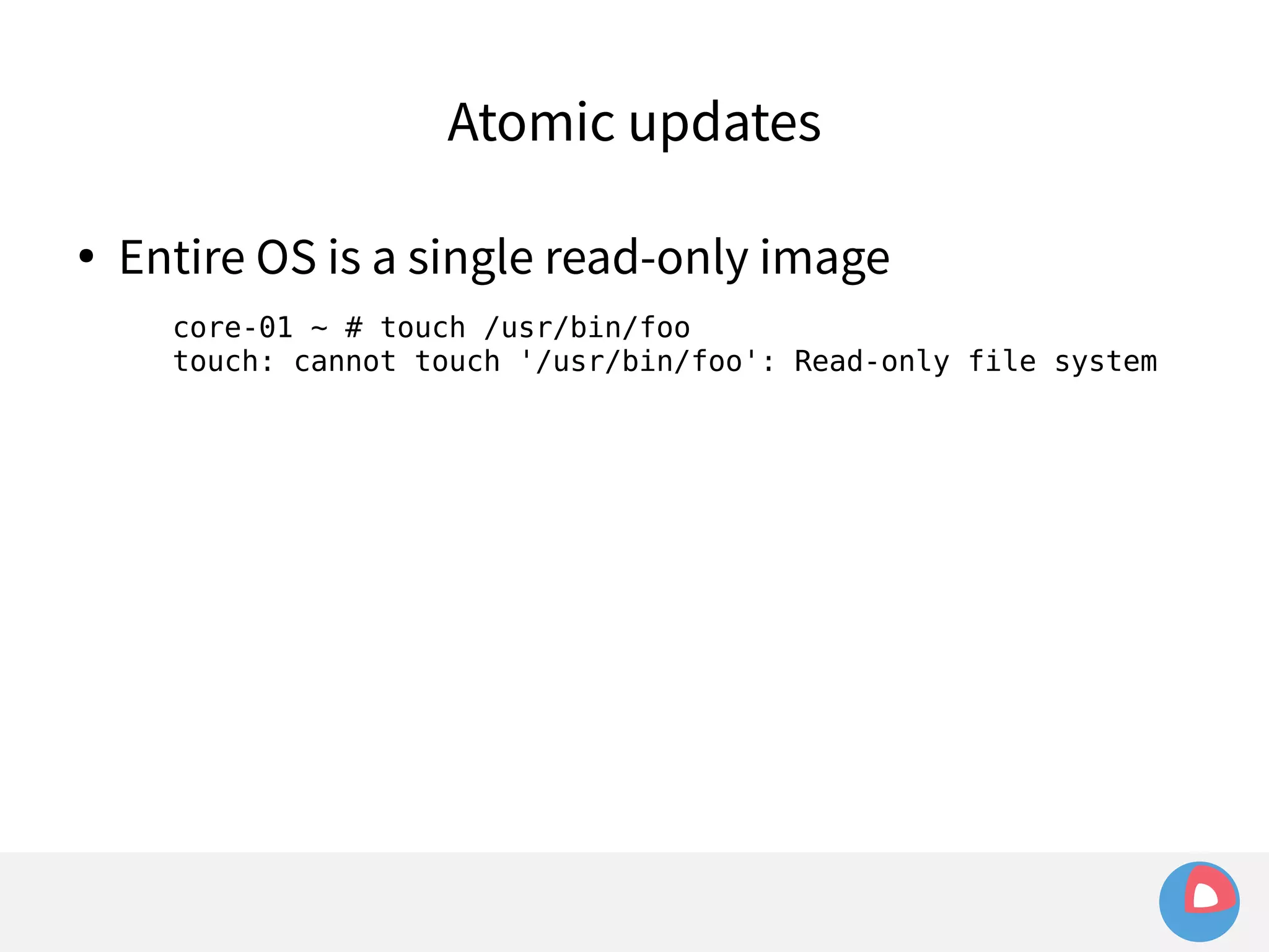
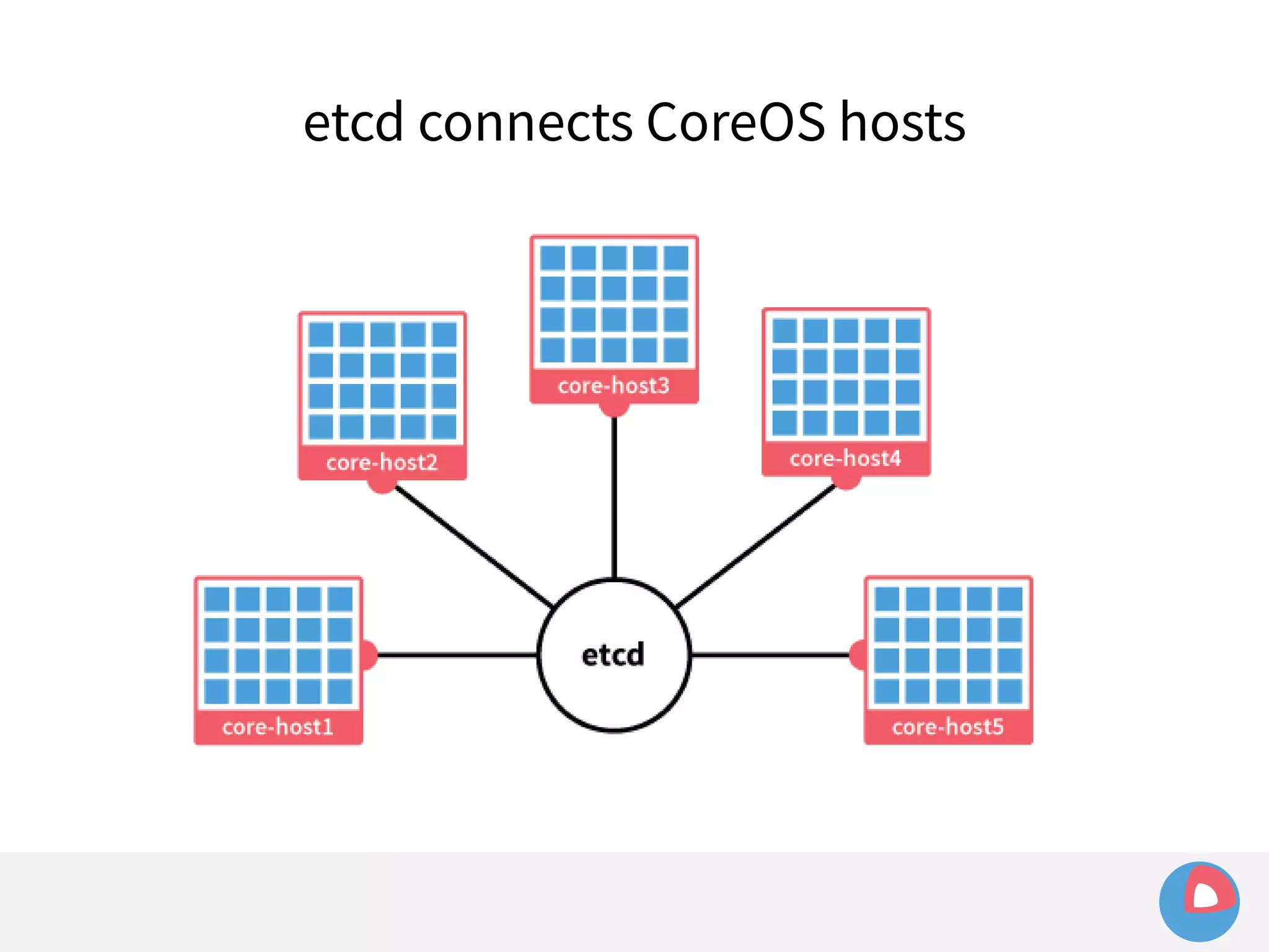
This document is a presentation on clustered computing with CoreOS, fleet and etcd given by Jonathan Boulle of CoreOS. It begins with introducing the speaker and his background. The bulk of the presentation covers CoreOS Linux, its self-updating operating system design and use of application containers. It also discusses fleet, CoreOS's cluster management system, and how it allows applications to remain highly available during server updates using atomic operating system updates and active/passive root file systems.


![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] Linux Network Troubleshooting](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingnetworktroubleshootingyjlee20210412-210413014206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E6 - OpenInfra monitoring with Prometheus](https://cdn.slidesharecdn.com/ss_thumbnails/e61520monitoringopeninfrawithprometheusv1-180704062709-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2018.10.19] 김용기 부장 - IAC on OpenStack (feat. ansible)](https://cdn.slidesharecdn.com/ss_thumbnails/iaconopenstackansible-20181019-ykim-181022130142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] EFK Stack 소개와 설치 방법](https://cdn.slidesharecdn.com/ss_thumbnails/elasticstack-210712042246-thumbnail.jpg?width=640&height=640&fit=bounds)









![[OpenInfra Days Korea 2018] Day 2 - E5-1: "Invited Talk: Kubicorn - Building ...](https://cdn.slidesharecdn.com/ss_thumbnails/e60955buildingsimplekubernetes-180705043459-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018.10.19] Andrew Kong - Tunnel without tunnel (Seminar at OpenStack Korea ...](https://cdn.slidesharecdn.com/ss_thumbnails/tunnelwithouttunnel-181022130534-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2A1]Line은 어떻게 글로벌 메신저 플랫폼이 되었는가](https://cdn.slidesharecdn.com/ss_thumbnails/2a1line-140929191515-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[1D2]아이비컨과 공유기 해킹을 통한 인도어 IOT 삽질기](https://cdn.slidesharecdn.com/ss_thumbnails/1d2iot-140927230515-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1D4]오타 수정과 편집 기능을 가진 Android Keyboard Service 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/1d4androidkeyboardservice-140928192141-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2C5]Map-D: A GPU Database for Interactive Big Data Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/2c5map-dagpudatabaseforinteractivebigdataanalytics-140930010539-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2D3]TurboGraph- Ultrafast graph analystics engine for billion-scale graphs i...](https://cdn.slidesharecdn.com/ss_thumbnails/2d3turbograph-ultrafastgraphanalysticsengineforbillion-scalegraphsinasinglemachine-140929210257-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Hello world]n forge](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldnforge-120831022354-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hello world]nodejs helloworld chaesuwon](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldnodejshelloworldchaesuwon-120831010259-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hello world]play framework소개](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldplayframework-120831011102-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[1B5]github first-principles](https://cdn.slidesharecdn.com/ss_thumbnails/1b5github-first-principles-140929003833-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[1B2]자신있는개발자에서훌륭한개발자로](https://cdn.slidesharecdn.com/ss_thumbnails/1b2-140927230722-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2B4]Live Broadcasting 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/2b4livebroadcasting-140929210948-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hello world]git internal](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldgit-internal-120831010436-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[1A1]행복한프로그래머를위한철학](https://cdn.slidesharecdn.com/ss_thumbnails/1a1-140927225723-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















