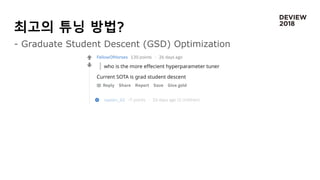
Naver AI Hackathon2018
영화 리뷰 평점 예측 / 지식인 질문 유사도 예측의 두 문제로 진행
영화 리뷰 평점: 문장으로 된 영화 리뷰를 보고 점수 예측
지식인 질문 유사도: 두 지식인 질문이 같은 질문인지 아닌지 판별
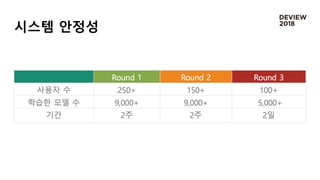
총 250+명 참여
한 달 동안 총 3라운드로 진행 (Online 2라운드, Offline 1라운드)
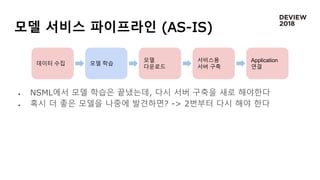
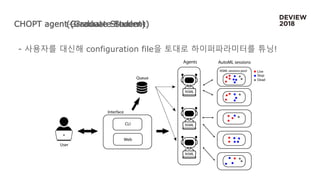
모델 서비스 파이프라인(AS-IS)
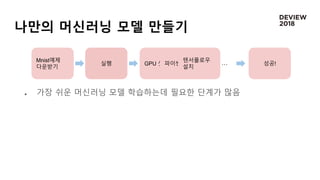
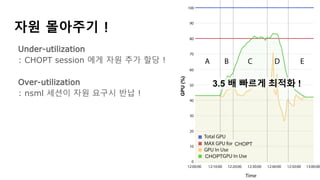
NSML에서 모델 학습은 끝냈는데, 다시 서버 구축을 새로 해야한다
혹시 더 좋은 모델을 나중에 발견하면? -> 2번부터 다시 해야 한다
데이터 수집 모델 학습
모델
다운로드
서비스용
서버 구축
Application
연결
31.
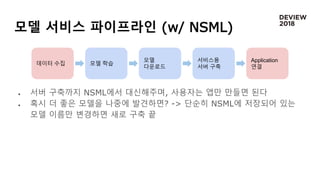
모델 서비스 파이프라인(w/ NSML)
서버 구축까지 NSML에서 대신해주며, 사용자는 앱만 만들면 된다
혹시 더 좋은 모델을 나중에 발견하면? -> 단순히 NSML에 저장되어 있는
모델 이름만 변경하면 새로 구축 끝
데이터 수집 모델 학습
모델
다운로드
서비스용
서버 구축
Application
연결


































![네. 됩니다.
- 저자들이 피땀흘려 얻은 결과를, 쉽고 빠르게 갱신 할 수 있습니다!
● Image Classification with CIFAR-100[1]
● Reasoning-QA with SQuAD 1.1[2]](https://image.slidesharecdn.com/225nsmlmachinelearningntuningautomize-181012023407/85/225-NSML-51-320.jpg)










![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PYCON Korea 2018] Python Application Server for Recommender System](https://cdn.slidesharecdn.com/ss_thumbnails/20180818pyconapplicationserverforrecommendersystematkakaorev3-180820011512-thumbnail.jpg?width=640&height=640&fit=bounds)





![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)




![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)



![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[금융사를 위한 AWS Generative AI Day 2023] 4_AWS Generative AI 서비스의 활용 방ᄇ...](https://cdn.slidesharecdn.com/ss_thumbnails/4awsgenerativeaiaws-230818063630-9fd7ffea-thumbnail.jpg?width=640&height=640&fit=bounds)
![[부스트캠프 Tech Talk] 진명훈_datasets로 협업하기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkjinmyunghoon-211210113319-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AWS Innovate 온라인 컨퍼런스] 수백만 사용자 대상 기계 학습 서비스를 위한 확장 비법 - 윤석찬, AWS 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session1channyyun-200319071657-thumbnail.jpg?width=640&height=640&fit=bounds)








![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)



![[25D2S08]_Amazon Bedrock과 SageMaker를 이용한 LLM 파인튜닝 및 커스터마ᄋ...](https://cdn.slidesharecdn.com/ss_thumbnails/25d2s08amazonbedrocksagemakerllm-250403123343-76e0215a-thumbnail.jpg?width=640&height=640&fit=bounds)






![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231] Clova 화자인식](https://cdn.slidesharecdn.com/ss_thumbnails/231deview2018clovaspeakerrecognition-181012005901-thumbnail.jpg?width=640&height=640&fit=bounds)