Download as PDF, PPTX











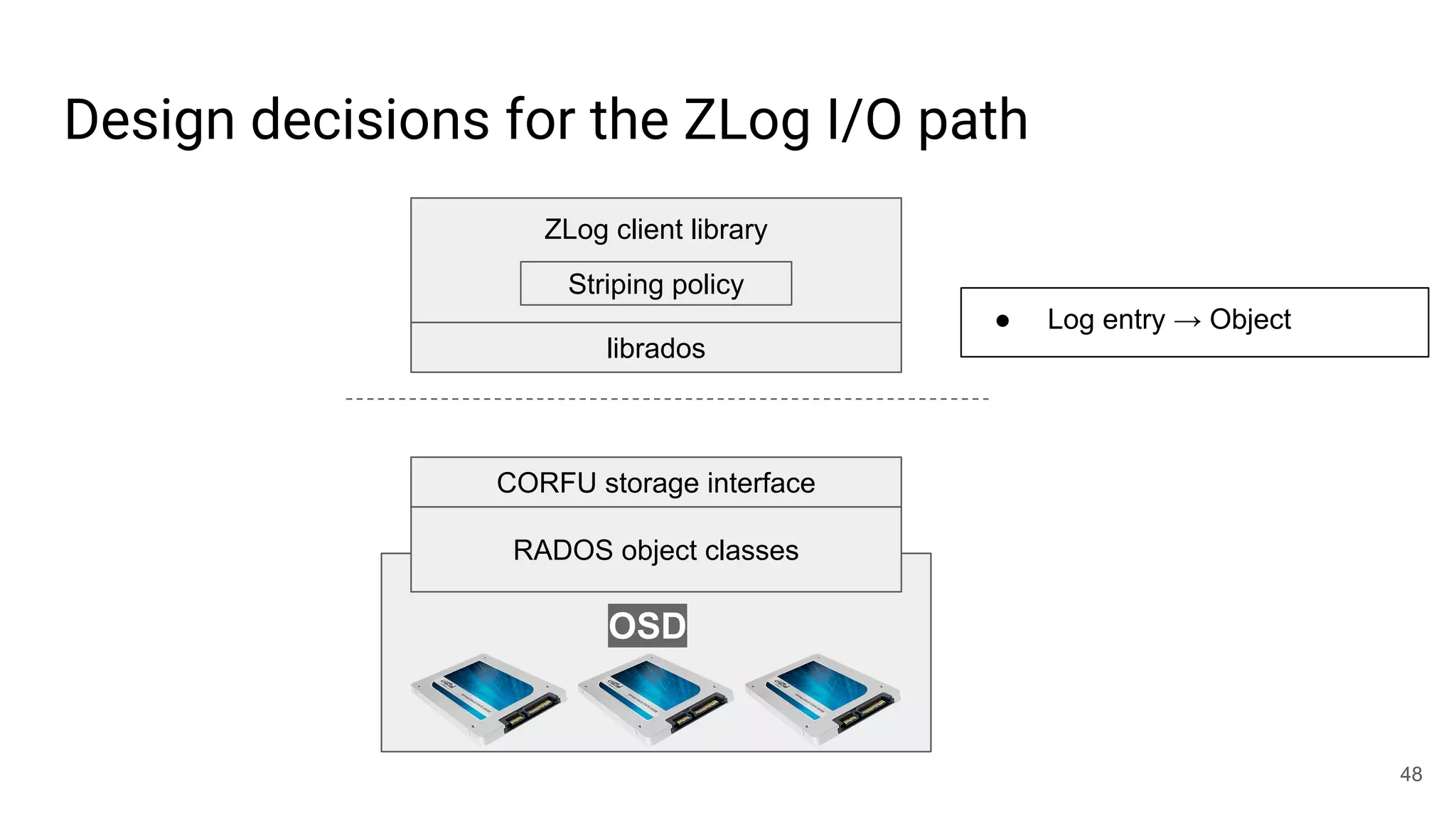
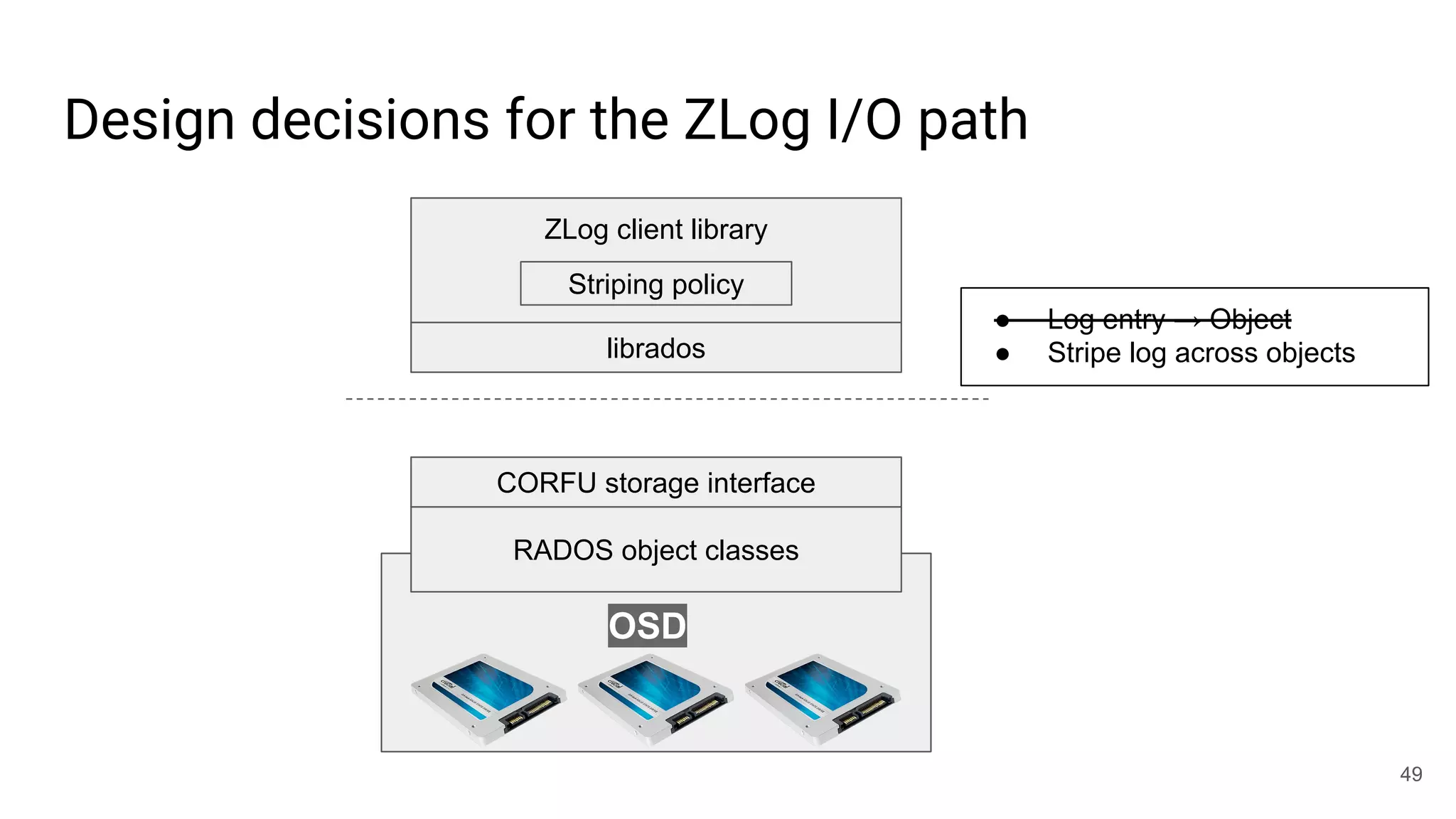
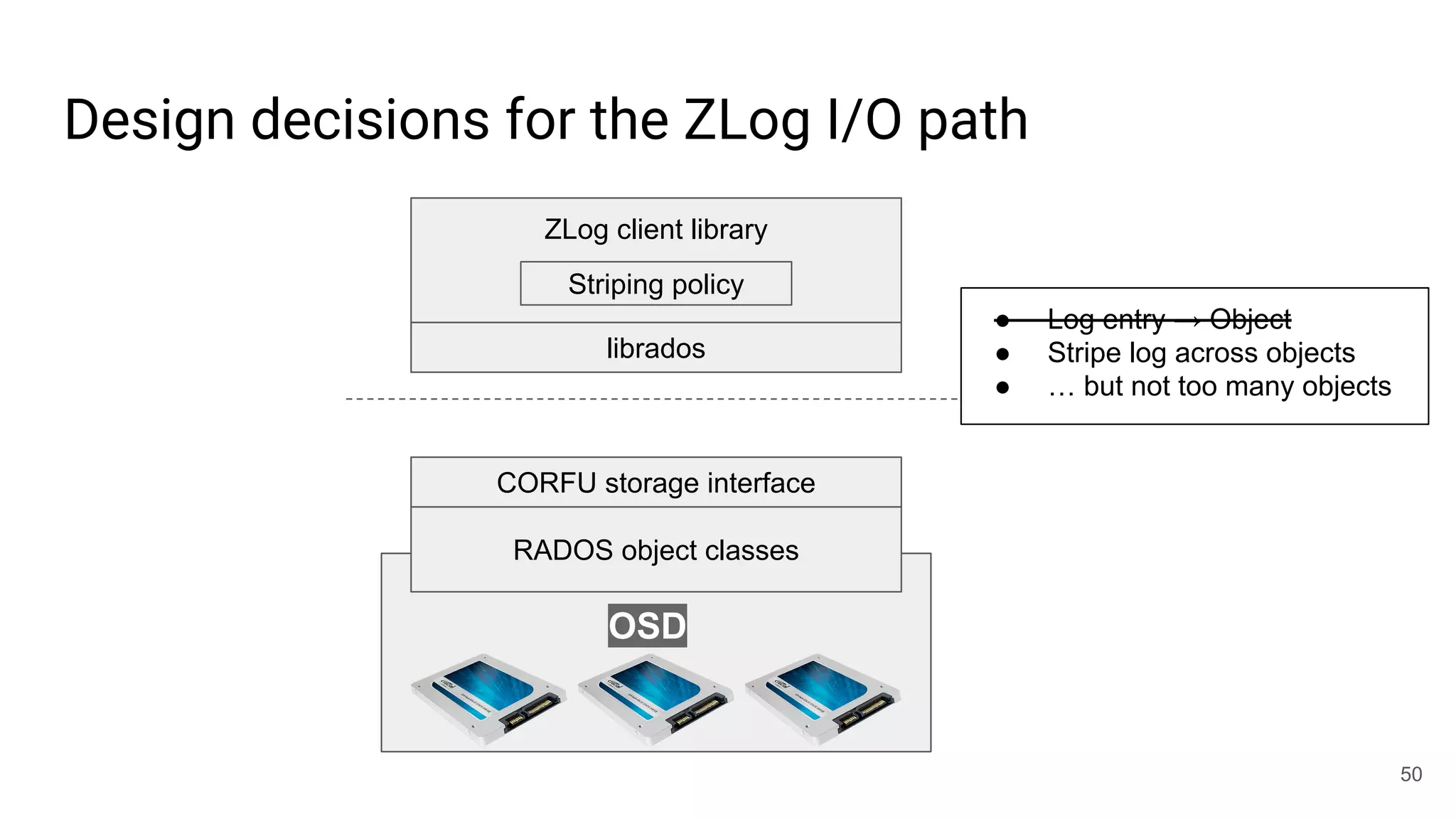
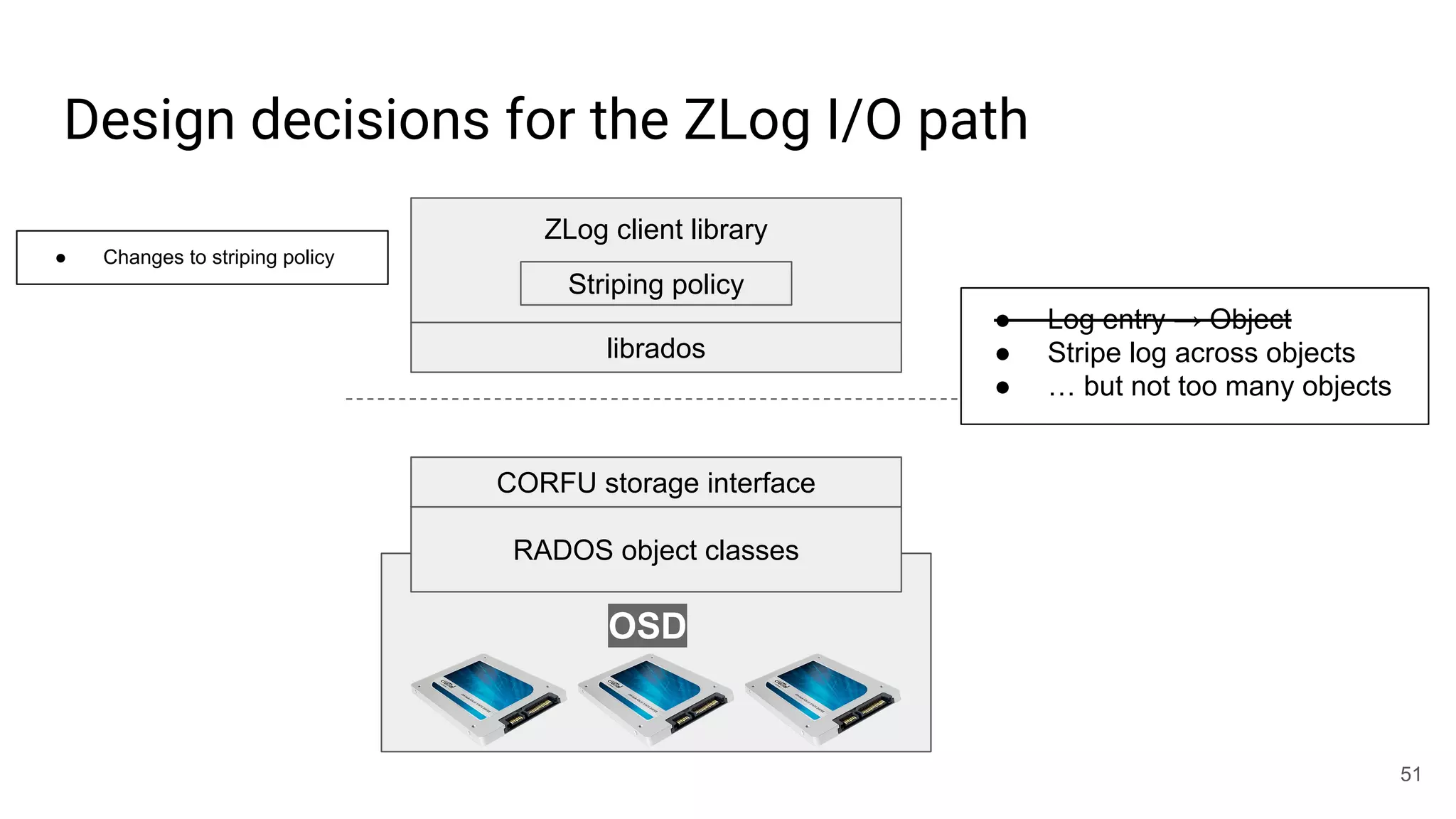
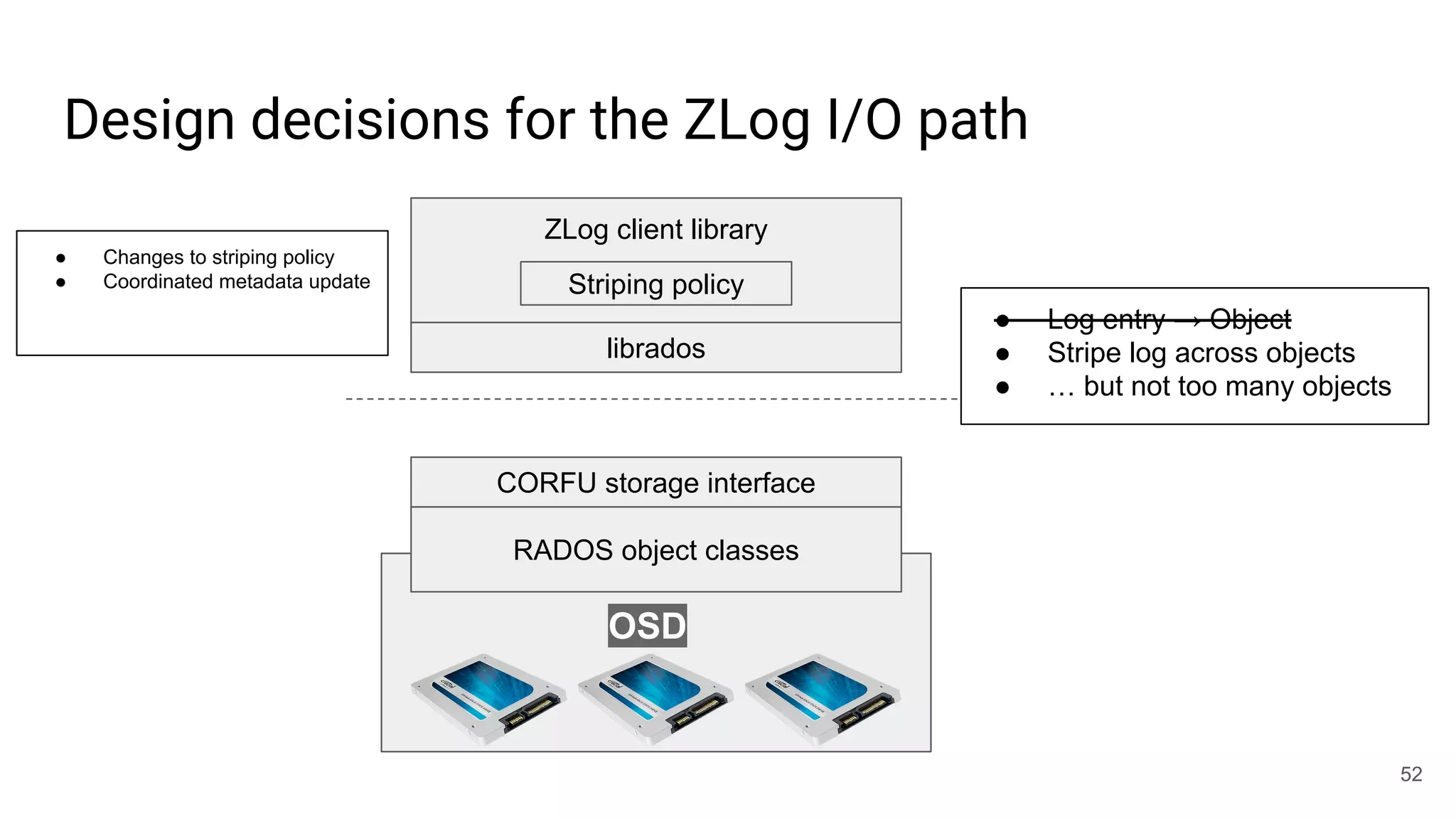
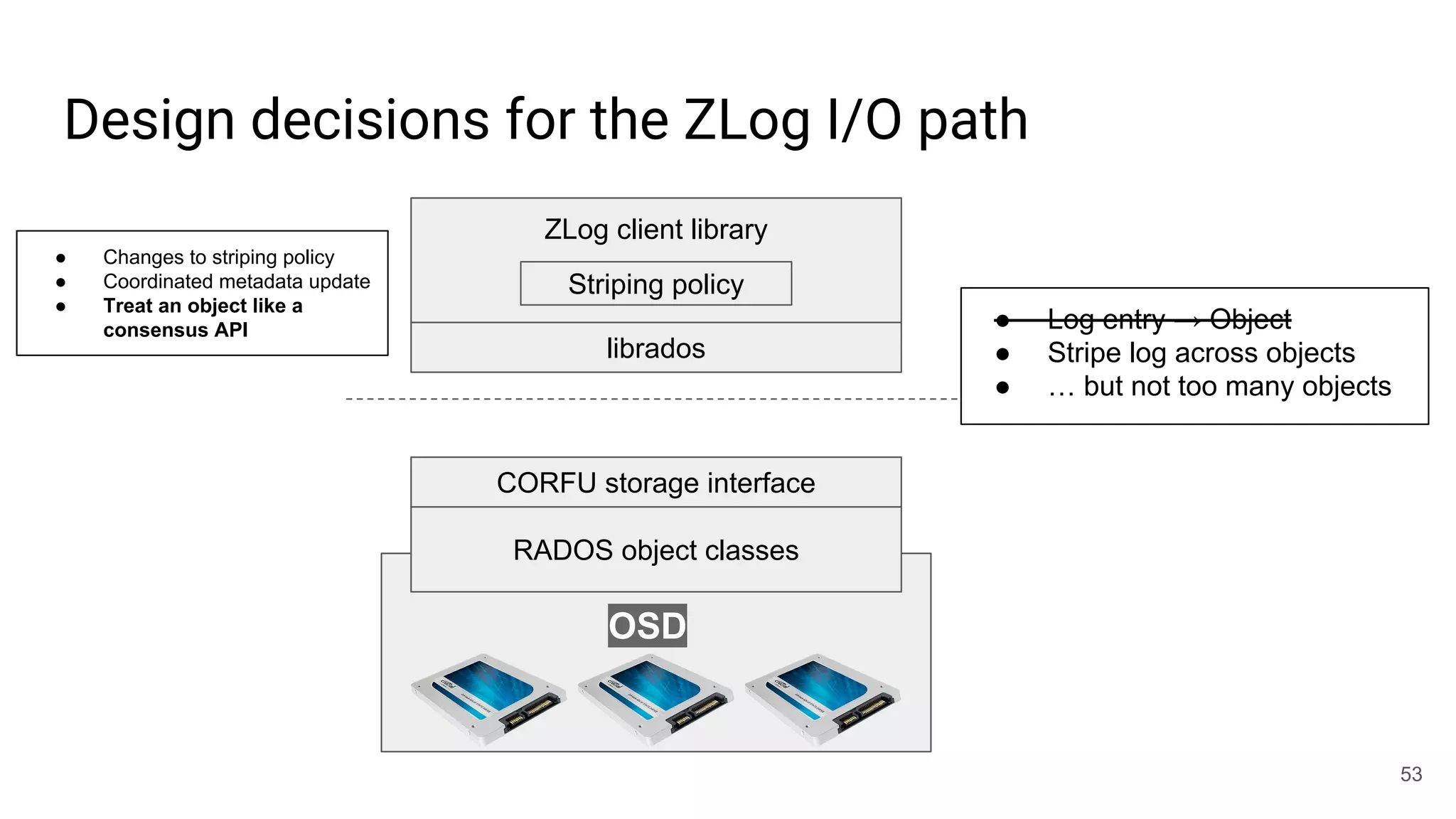
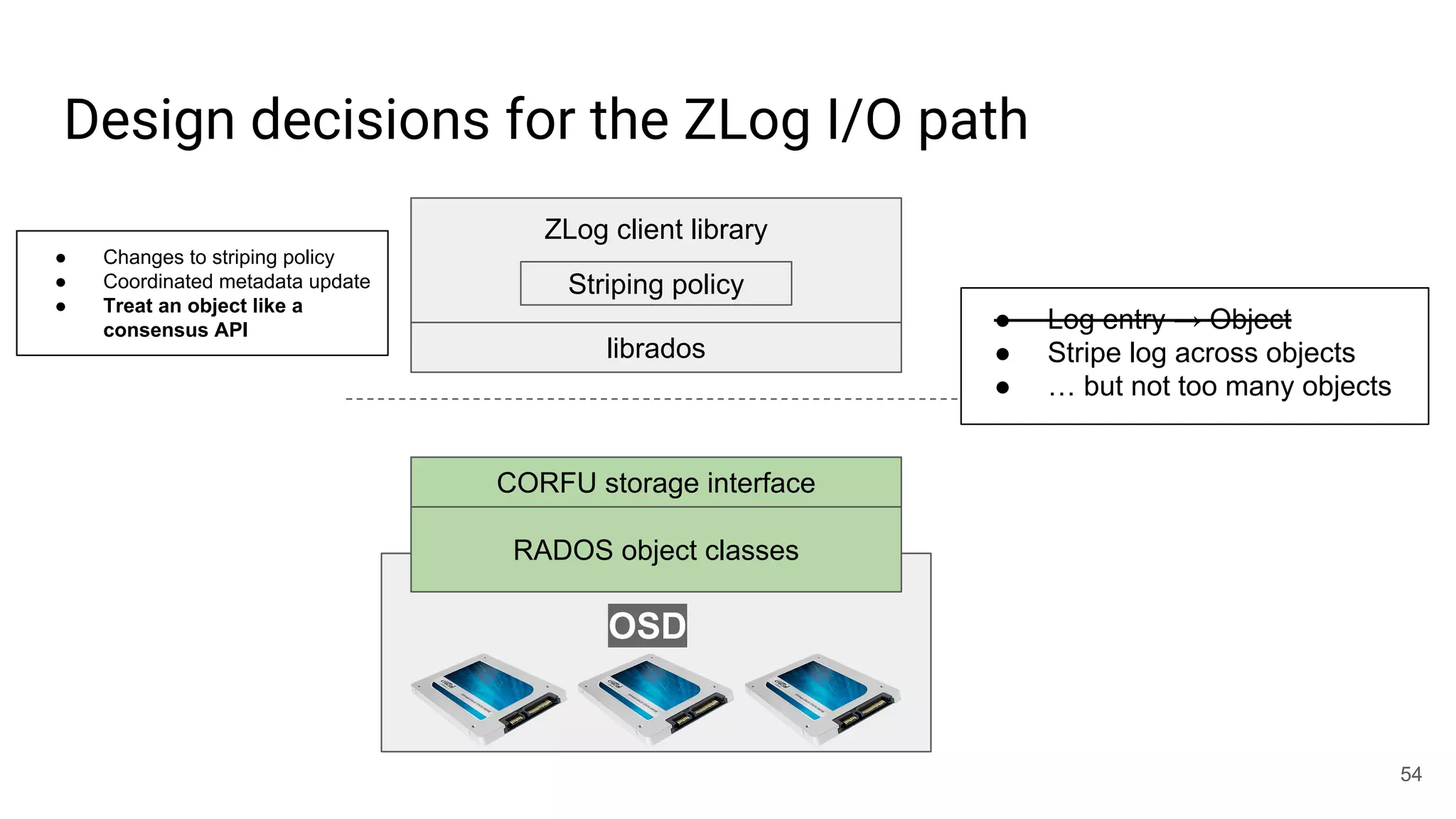







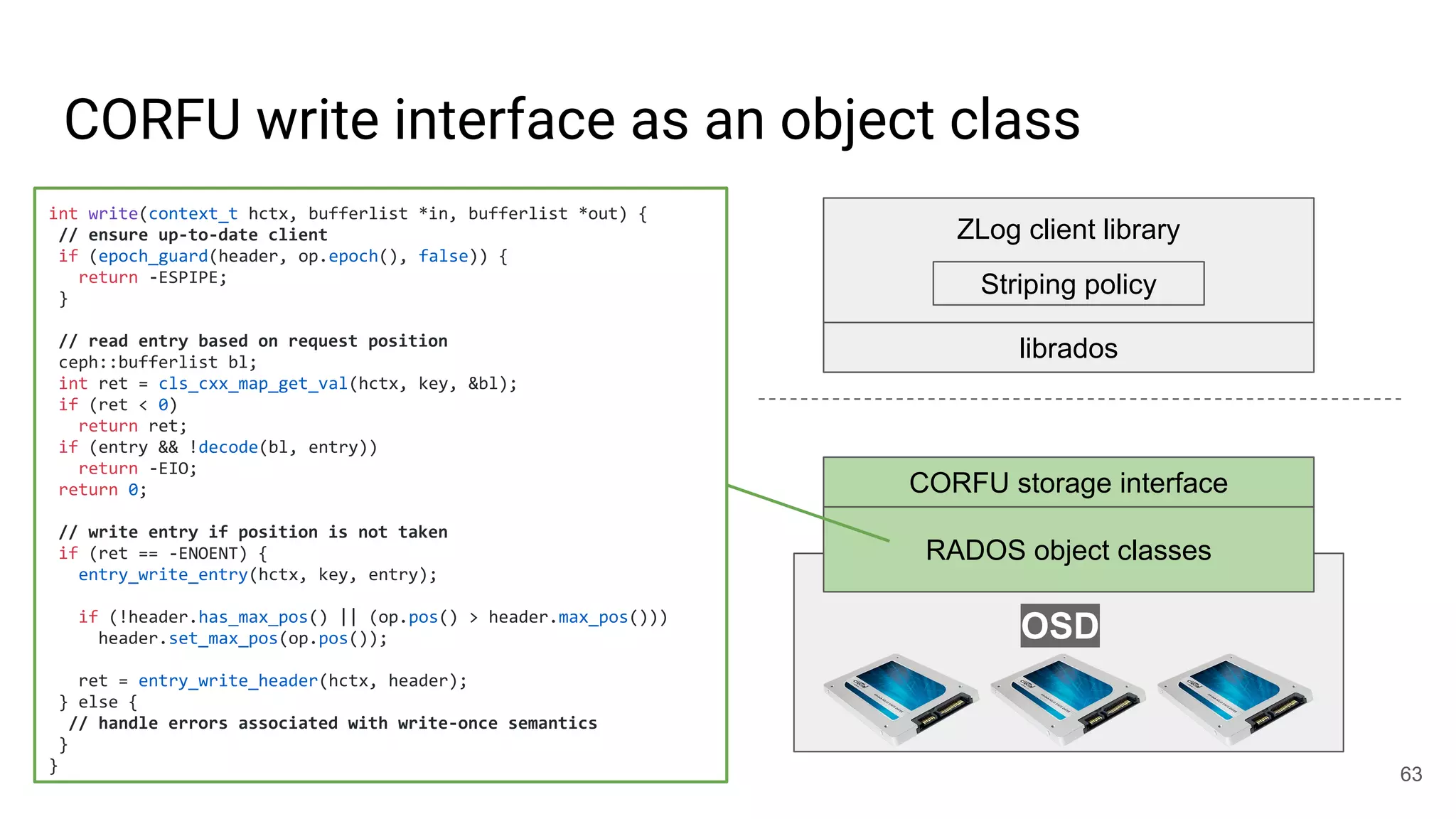
![librados won’t [currently] cut it for this job
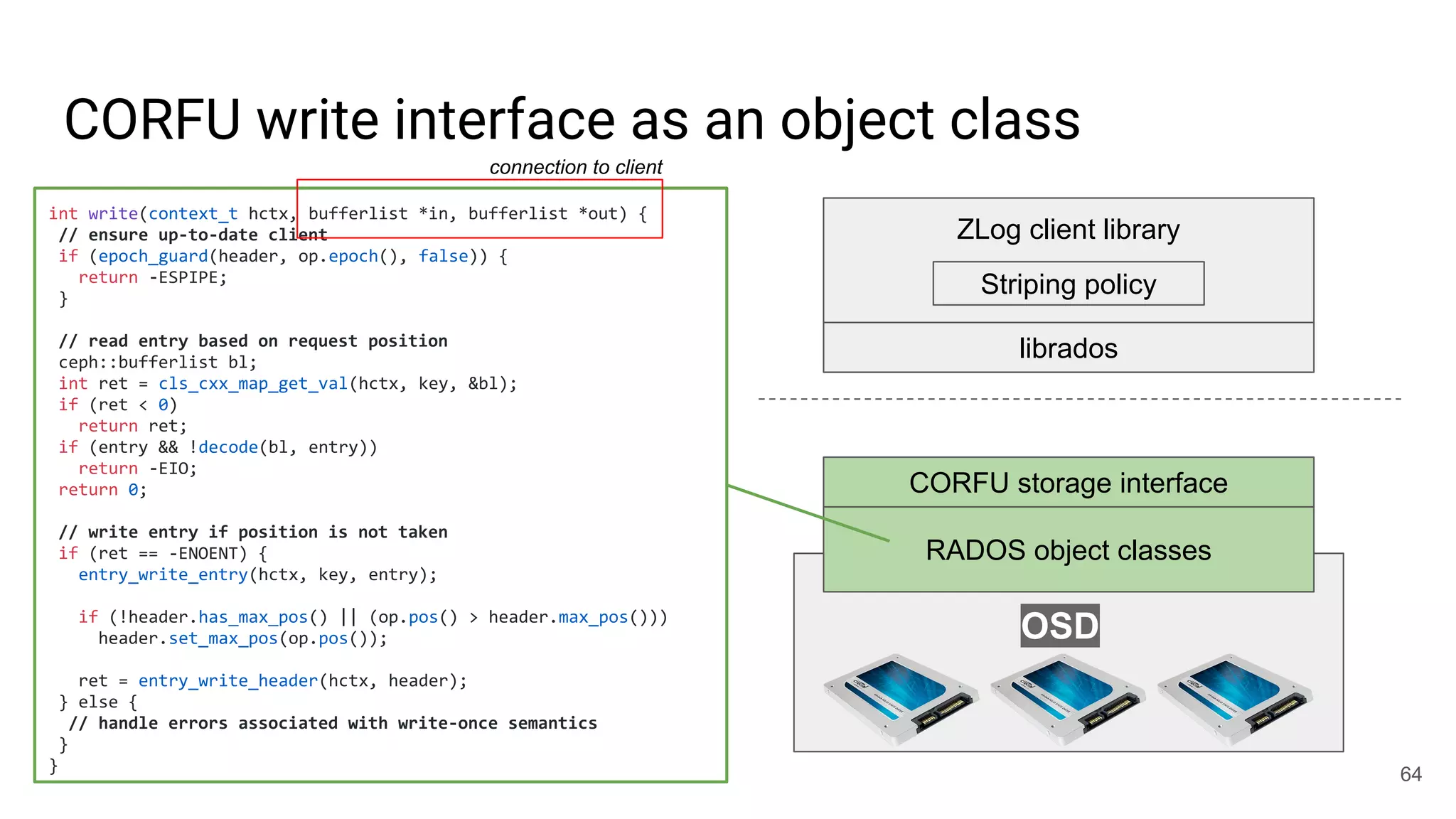
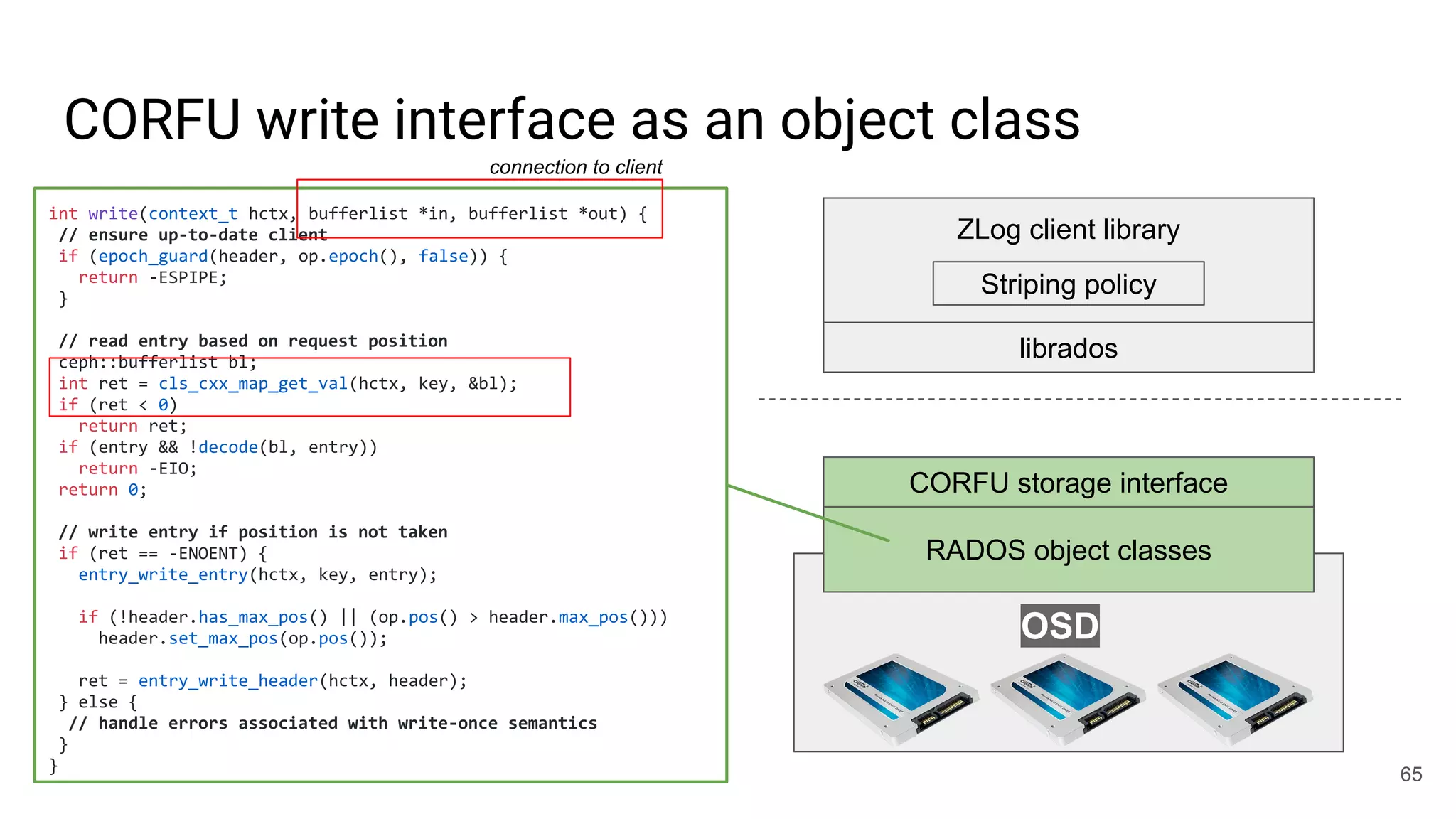
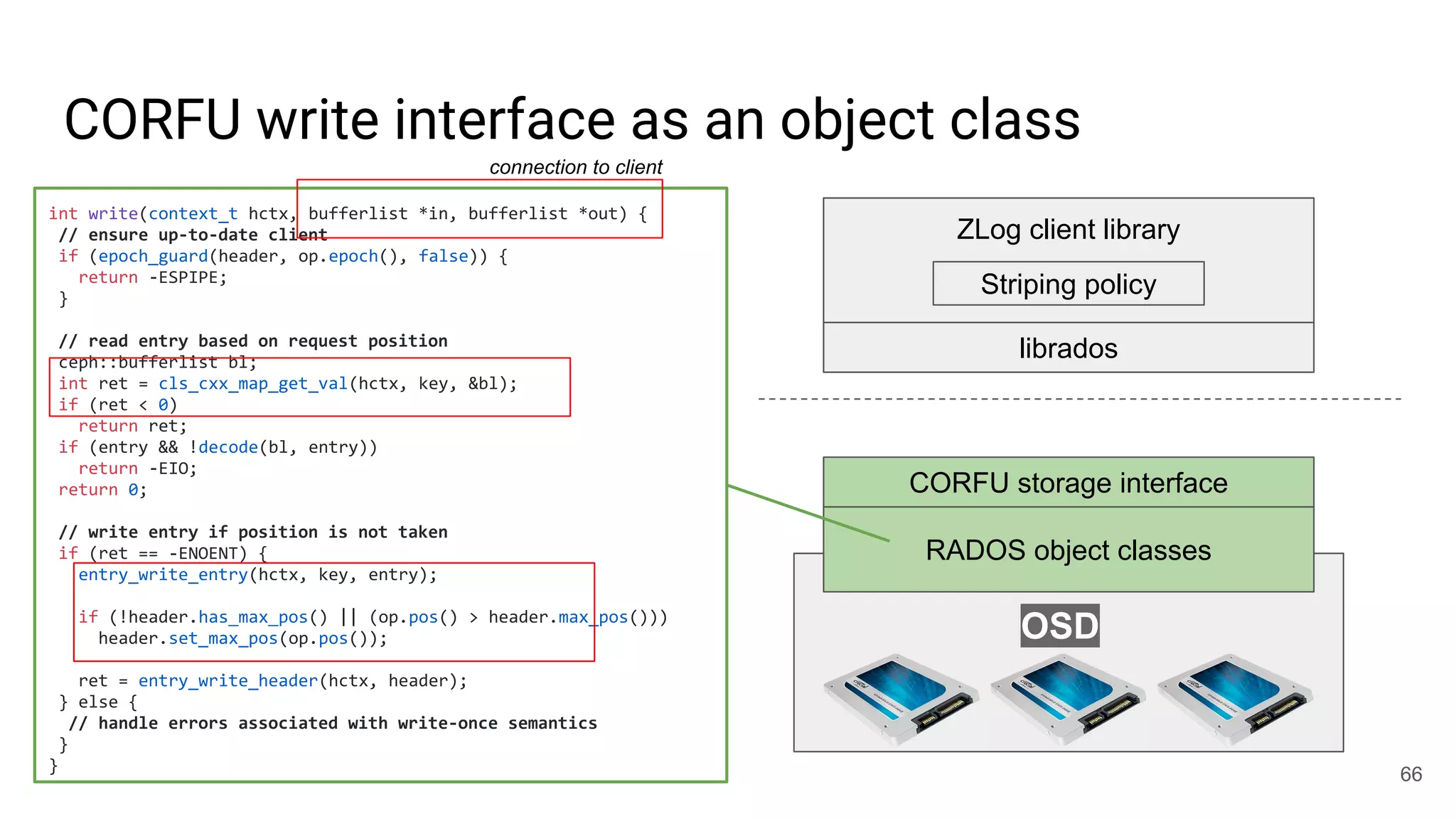
● write(obj, position, data)
○ Write-once: position must be open
○ Request must be tagged with up-to-date epoch
○ Position must not fall within a GC’d range
○ Optionally update maximum position observed
○ Atomic update
● read(obj, position)
● invalidate(obj, position)
● trim(obj, position)
○ Mark for GC
● seal(obj, epoch)
62](https://image.slidesharecdn.com/01-experiencesbuildingadistributedshared-logonrados-noahwatkins-180419044114/75/Experiences-building-a-distributed-shared-log-on-RADOS-Noah-Watkins-62-2048.jpg)



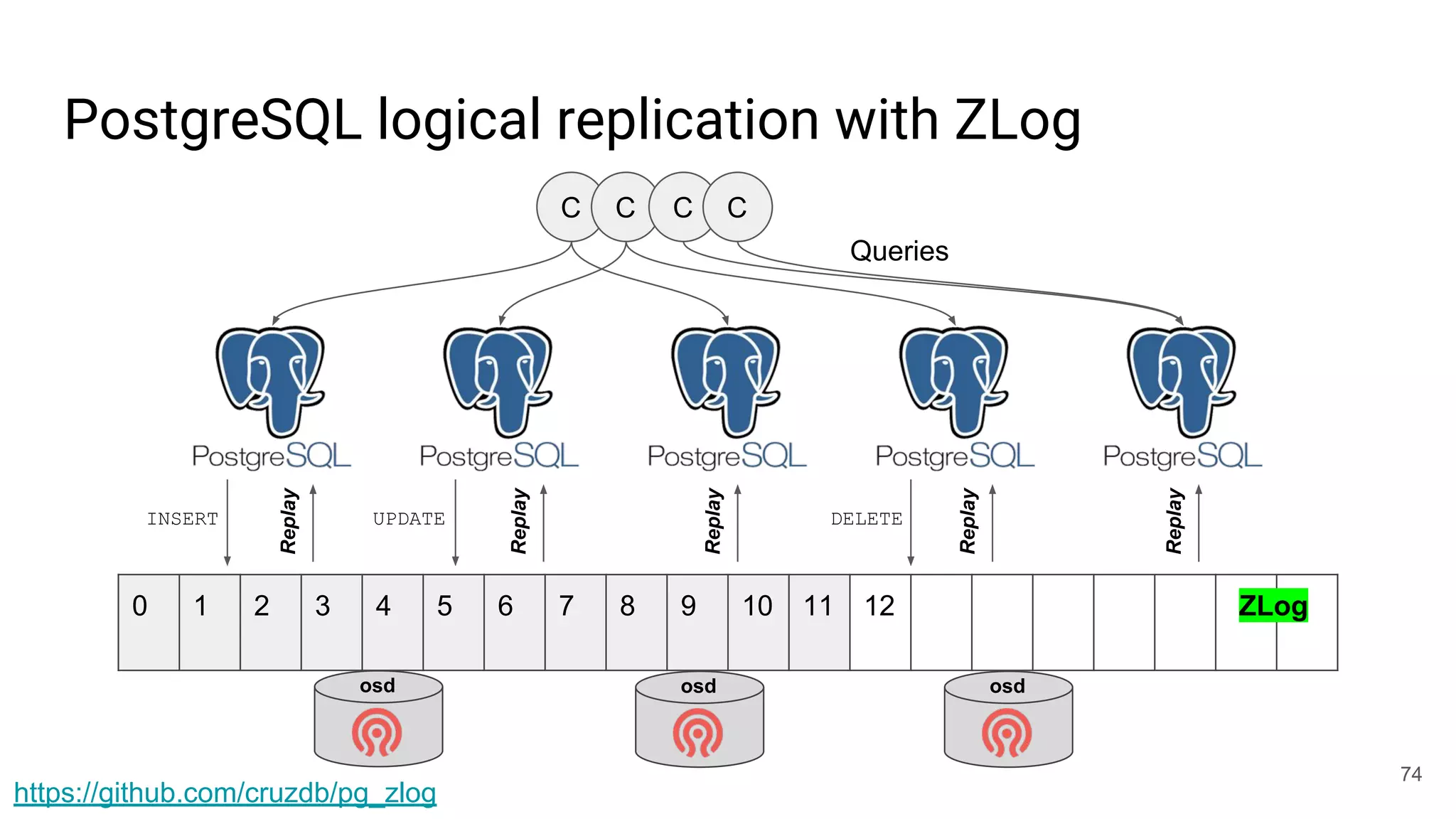
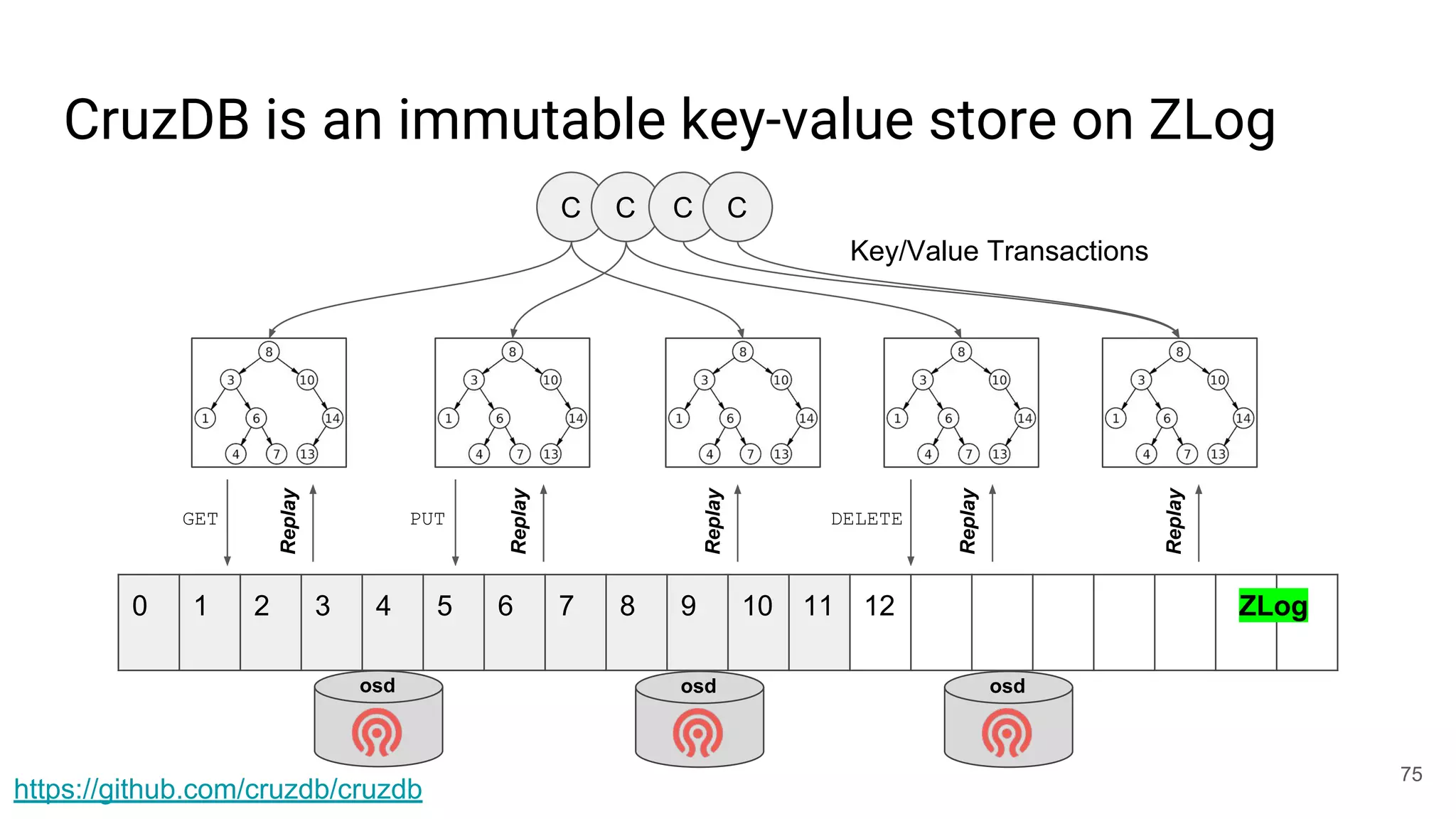
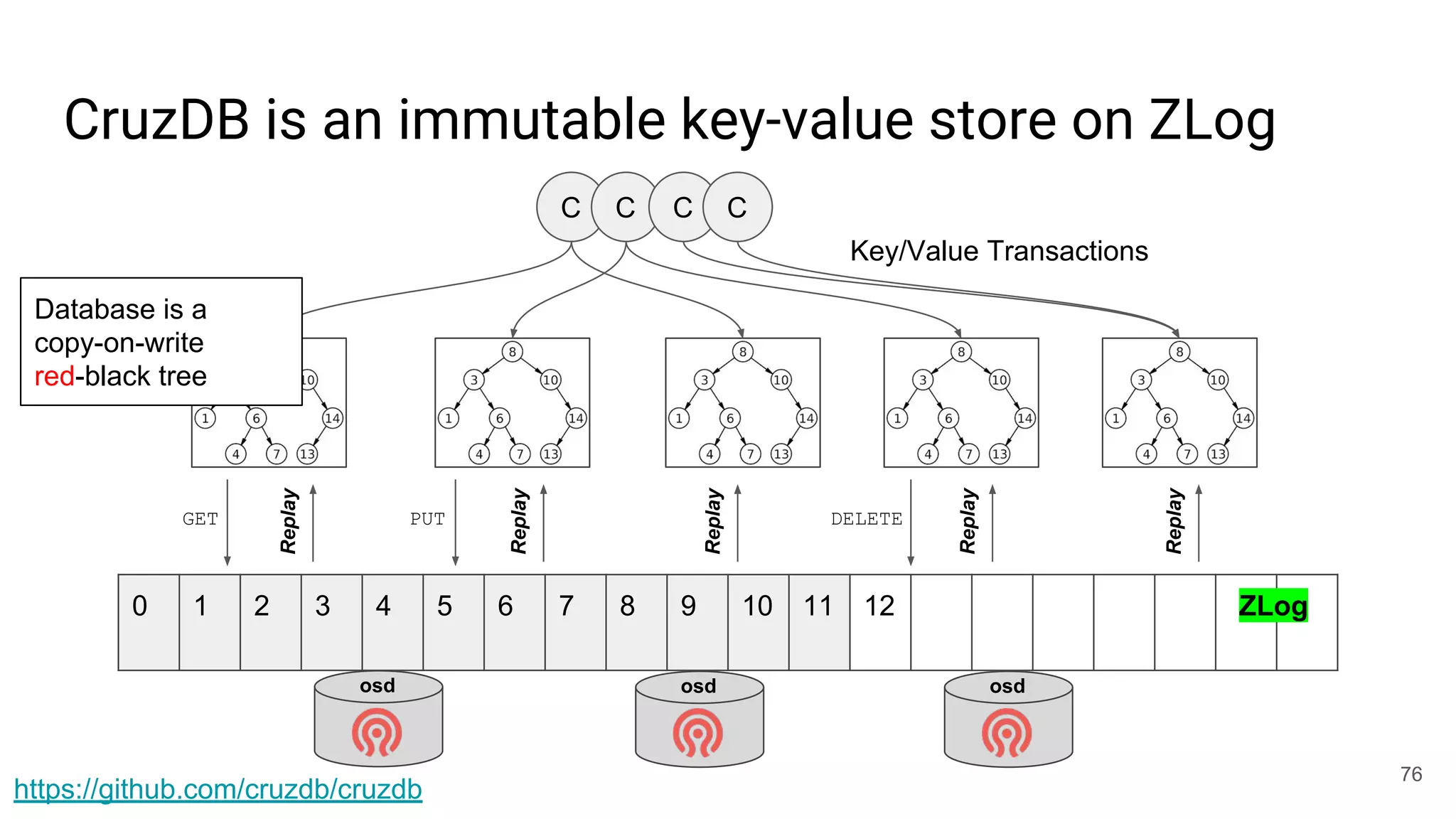
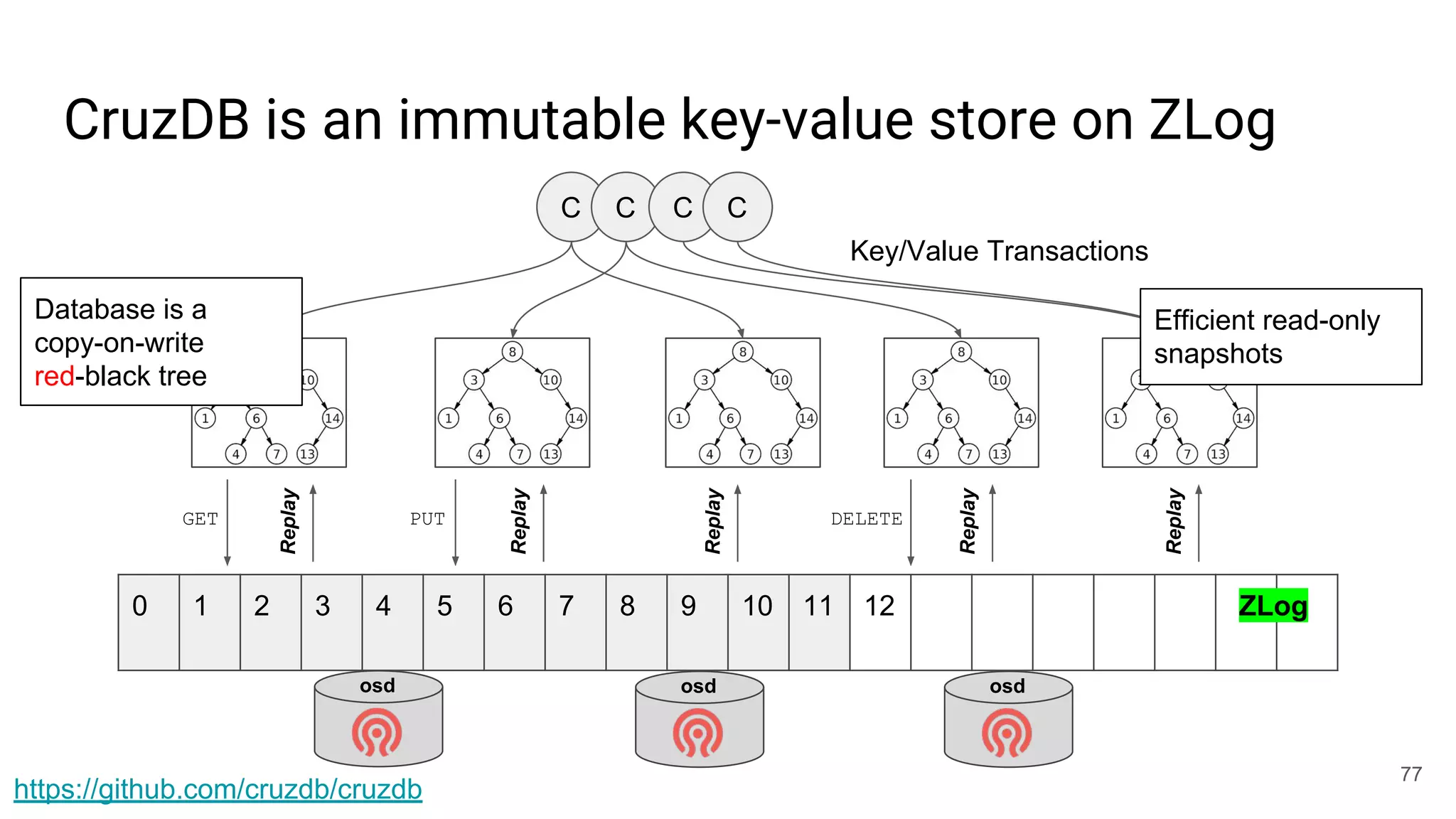
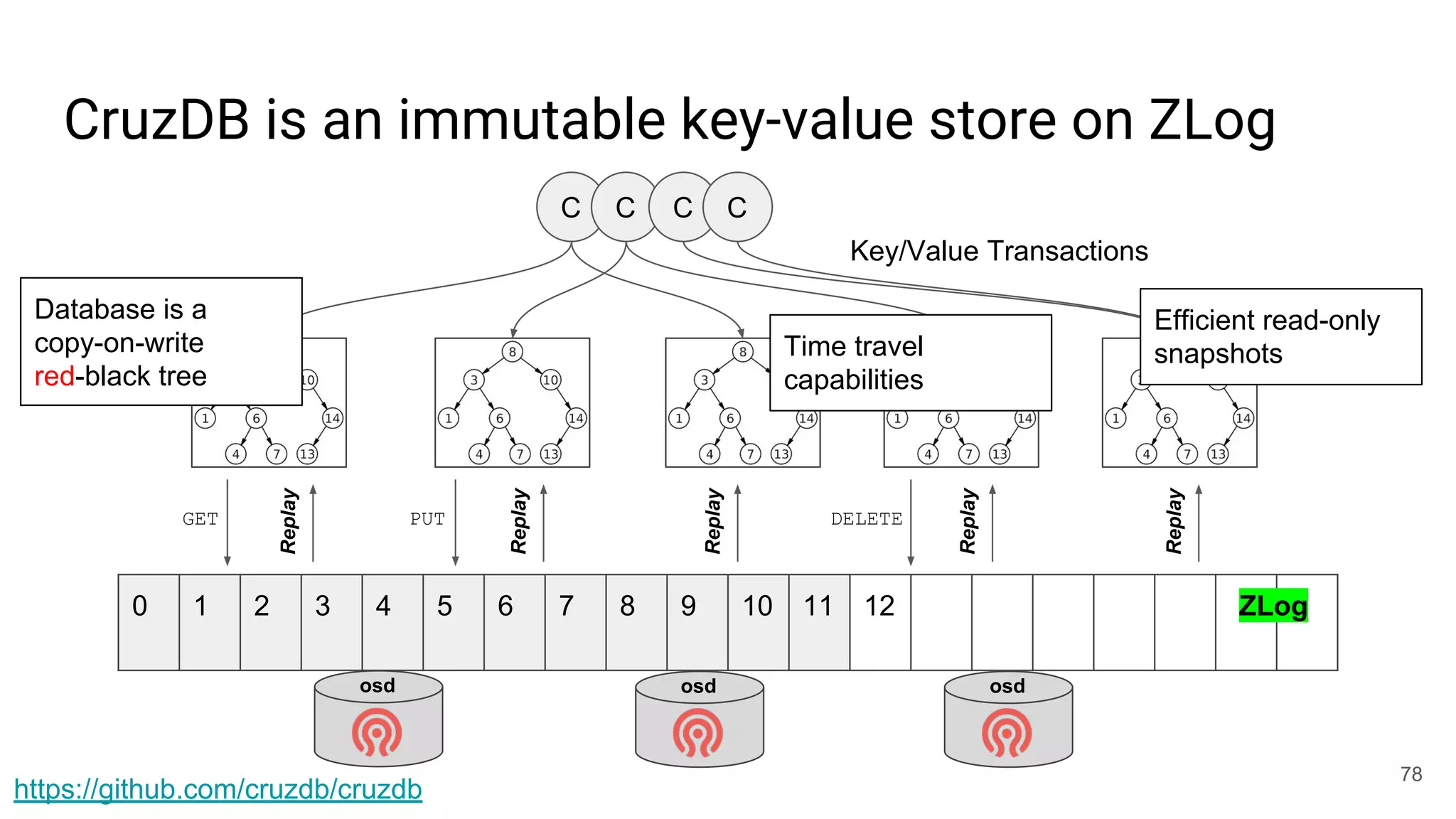



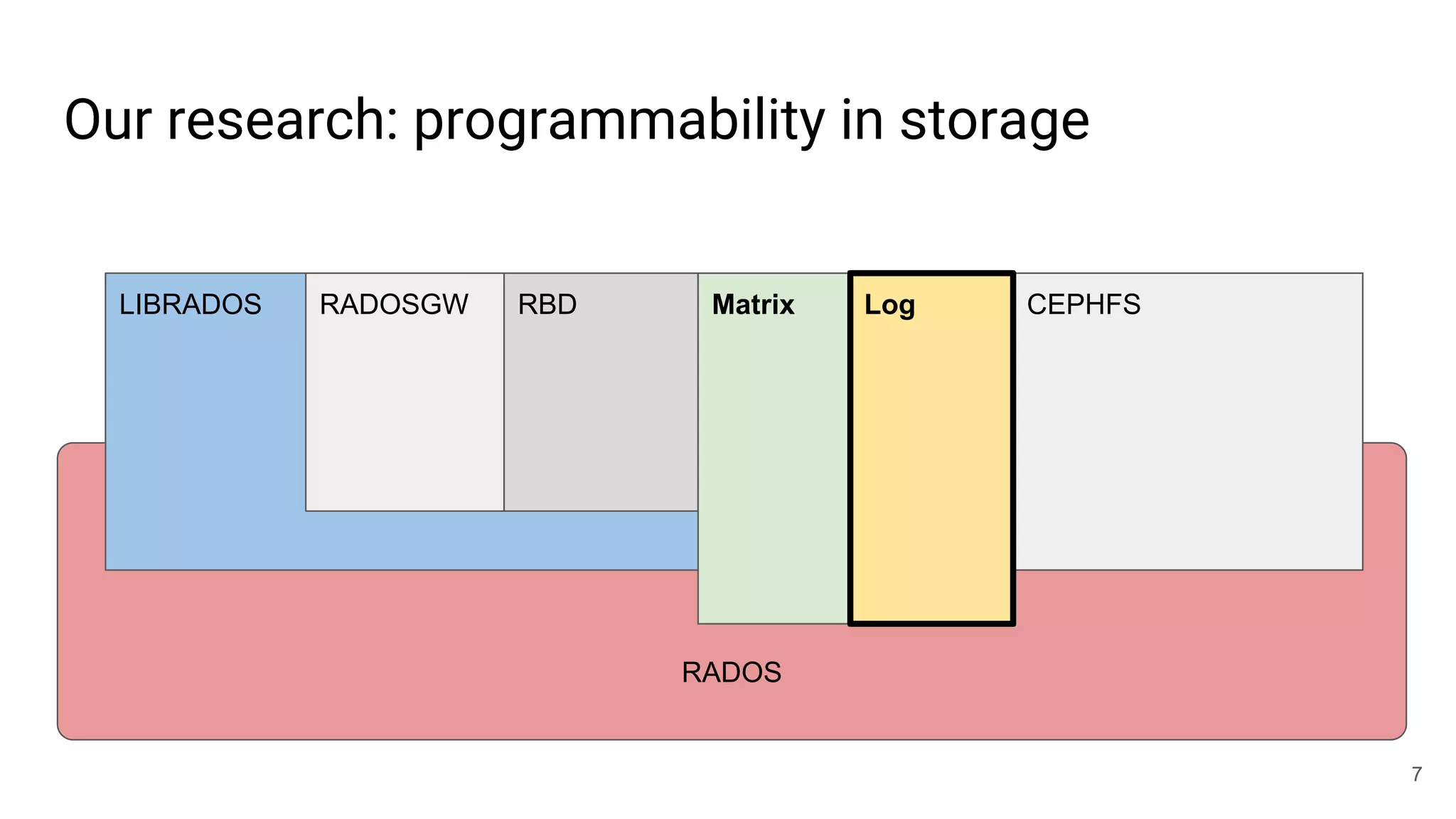
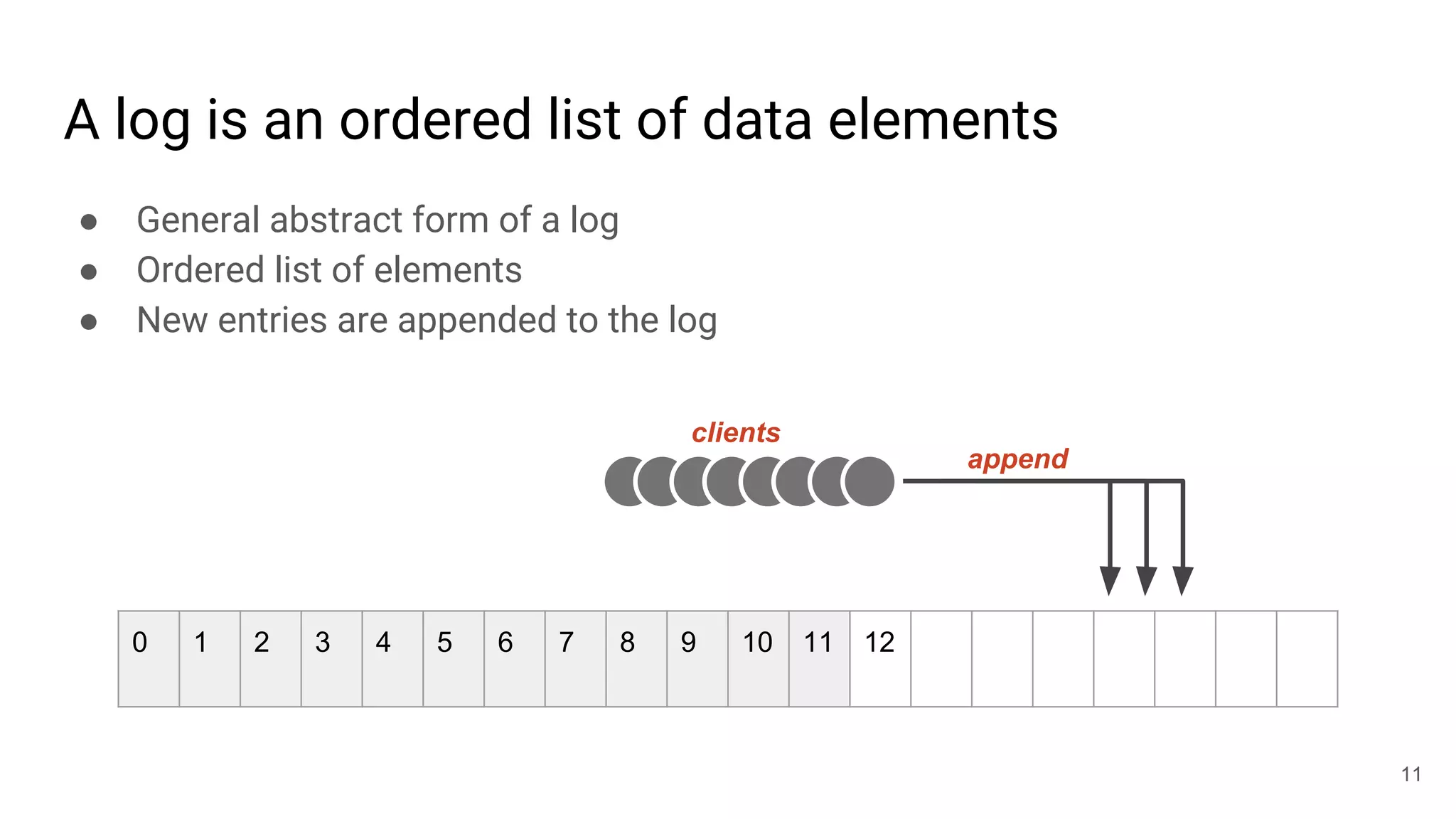
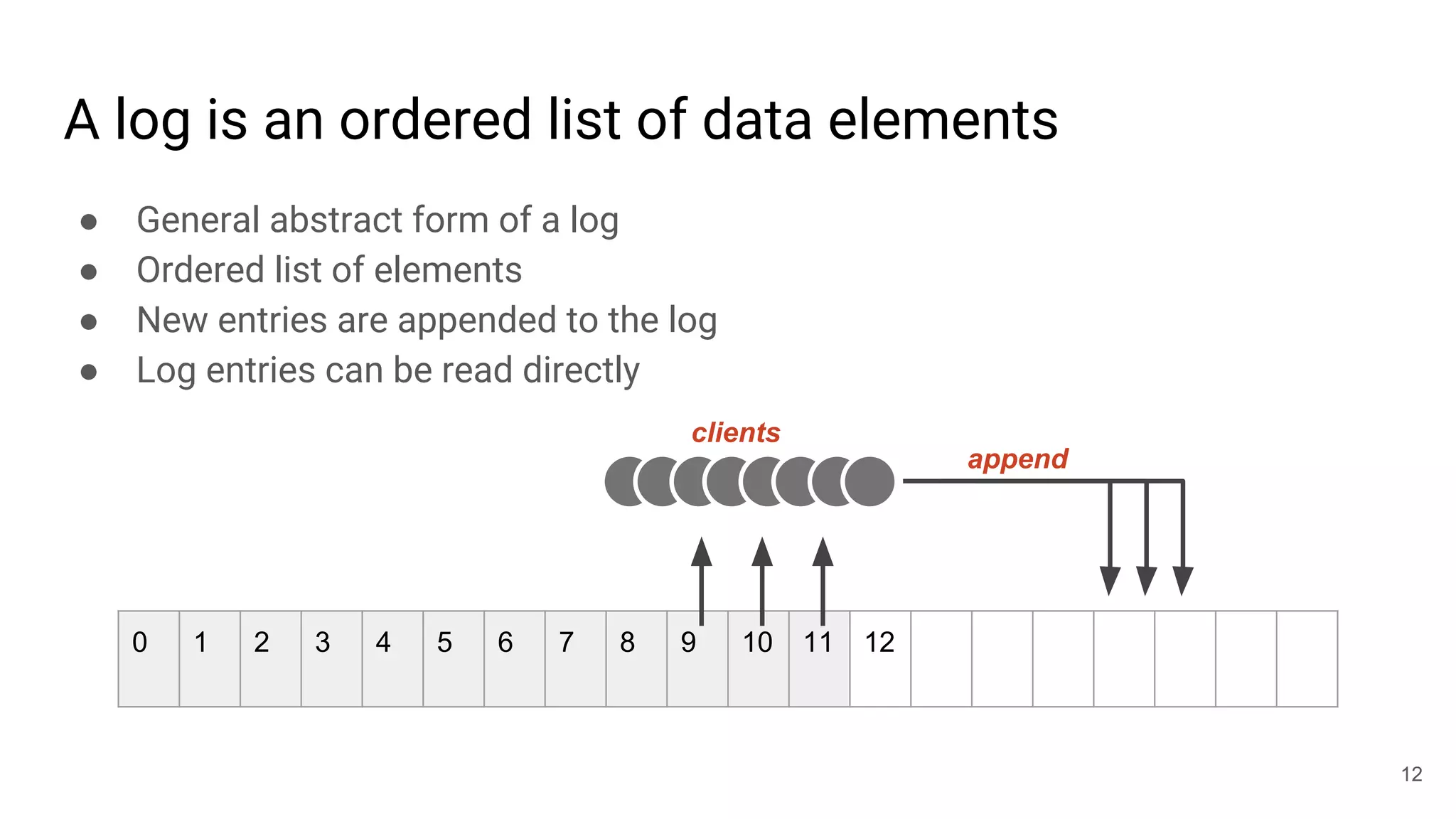
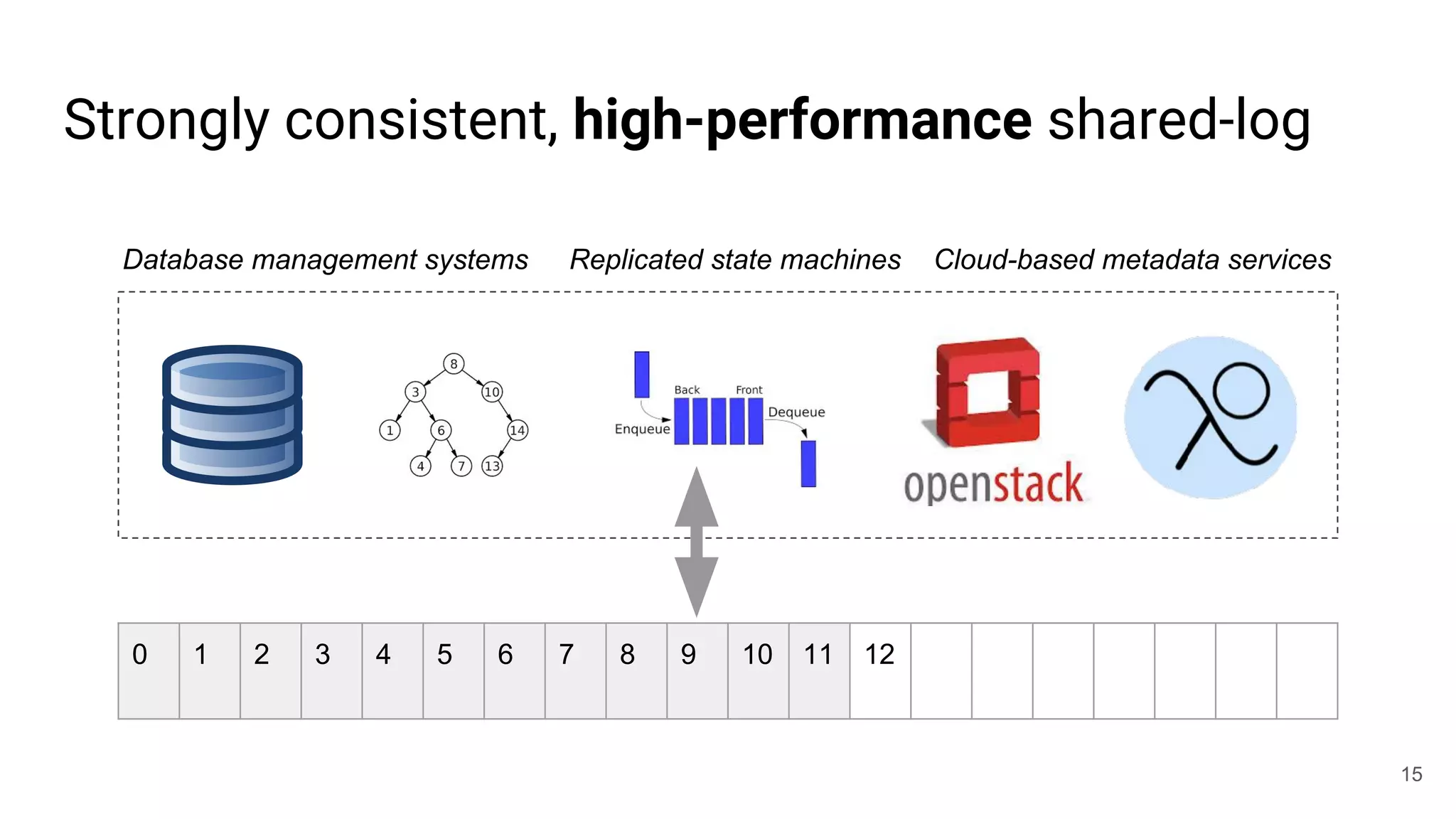
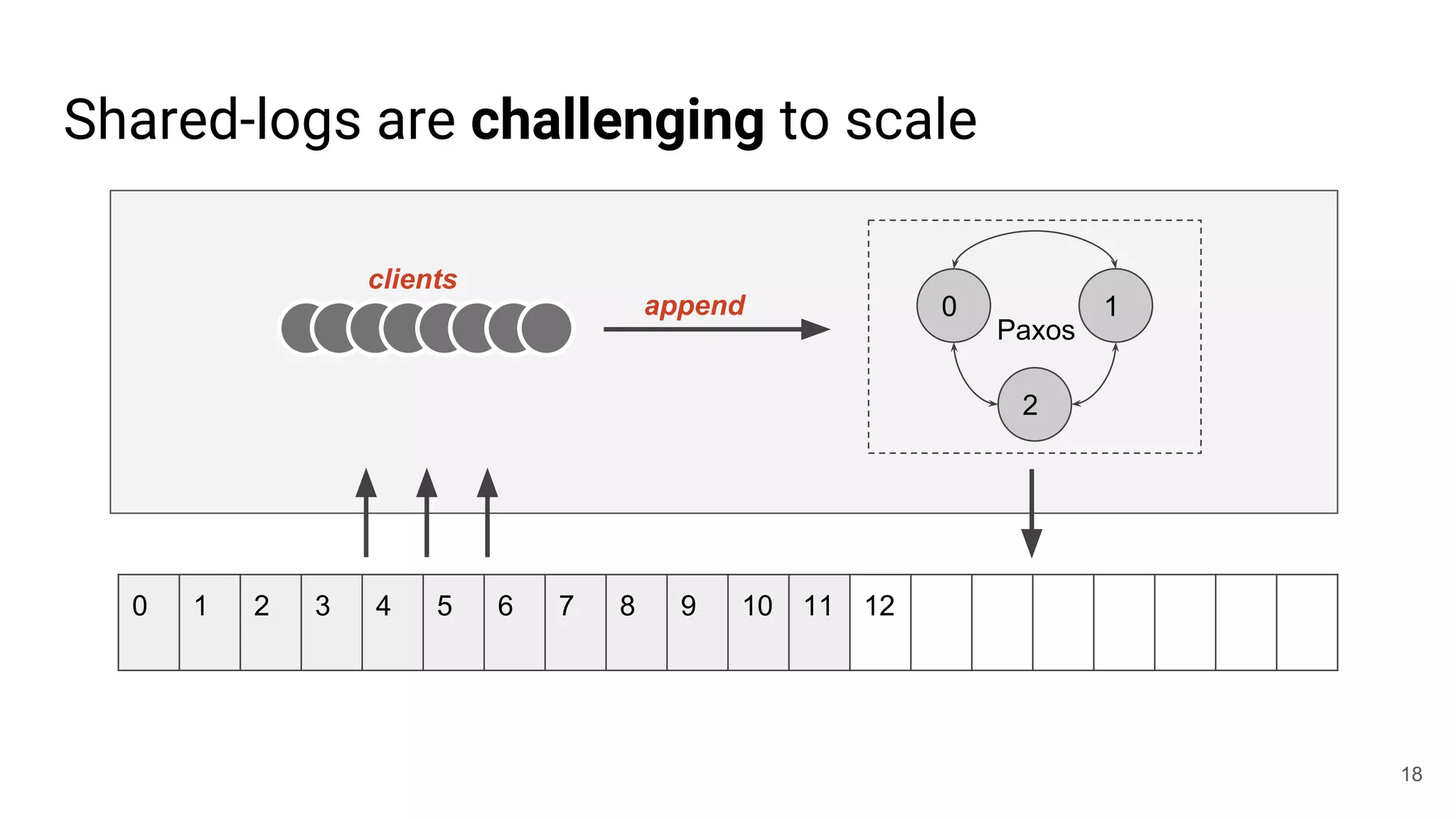
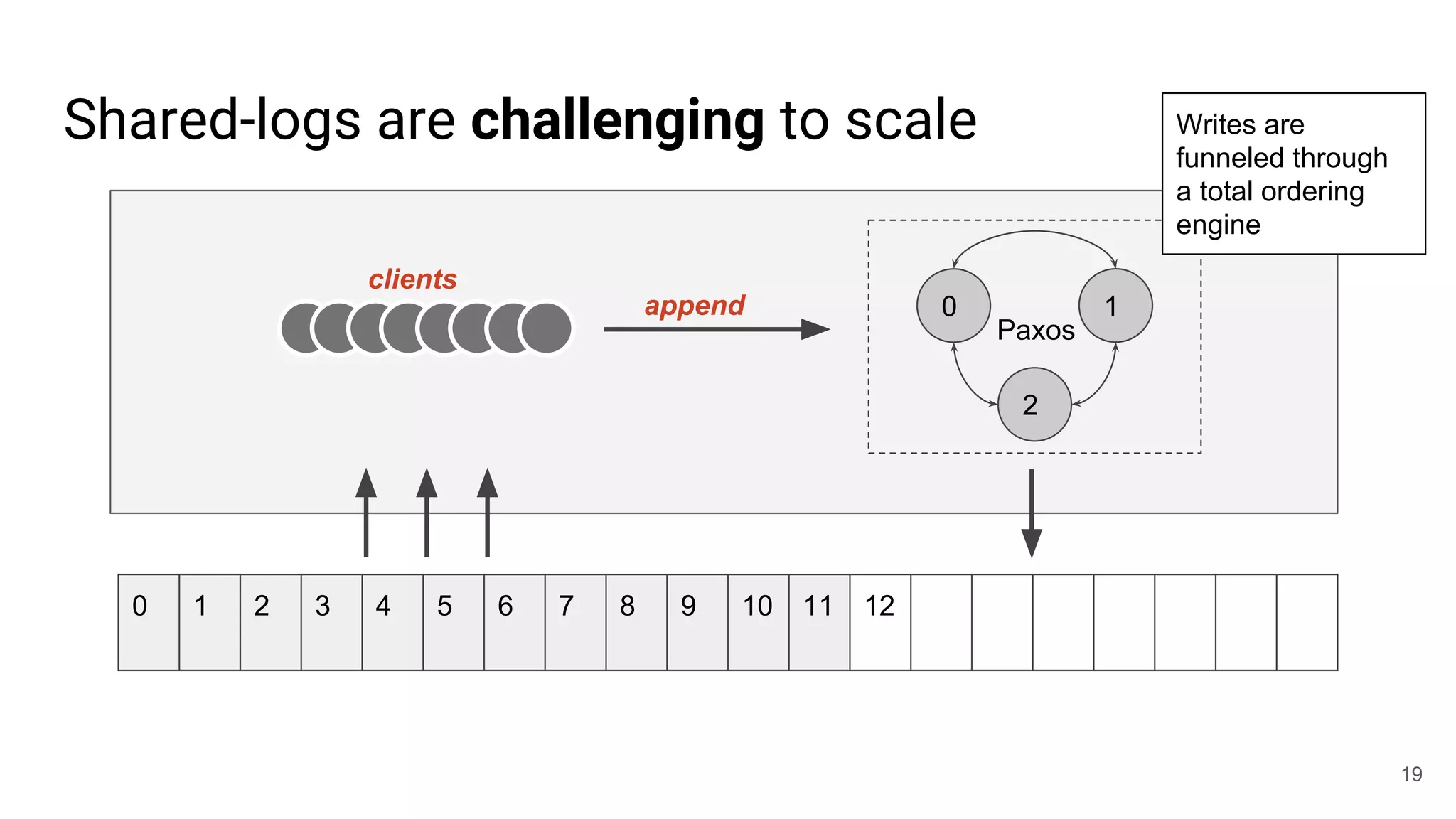
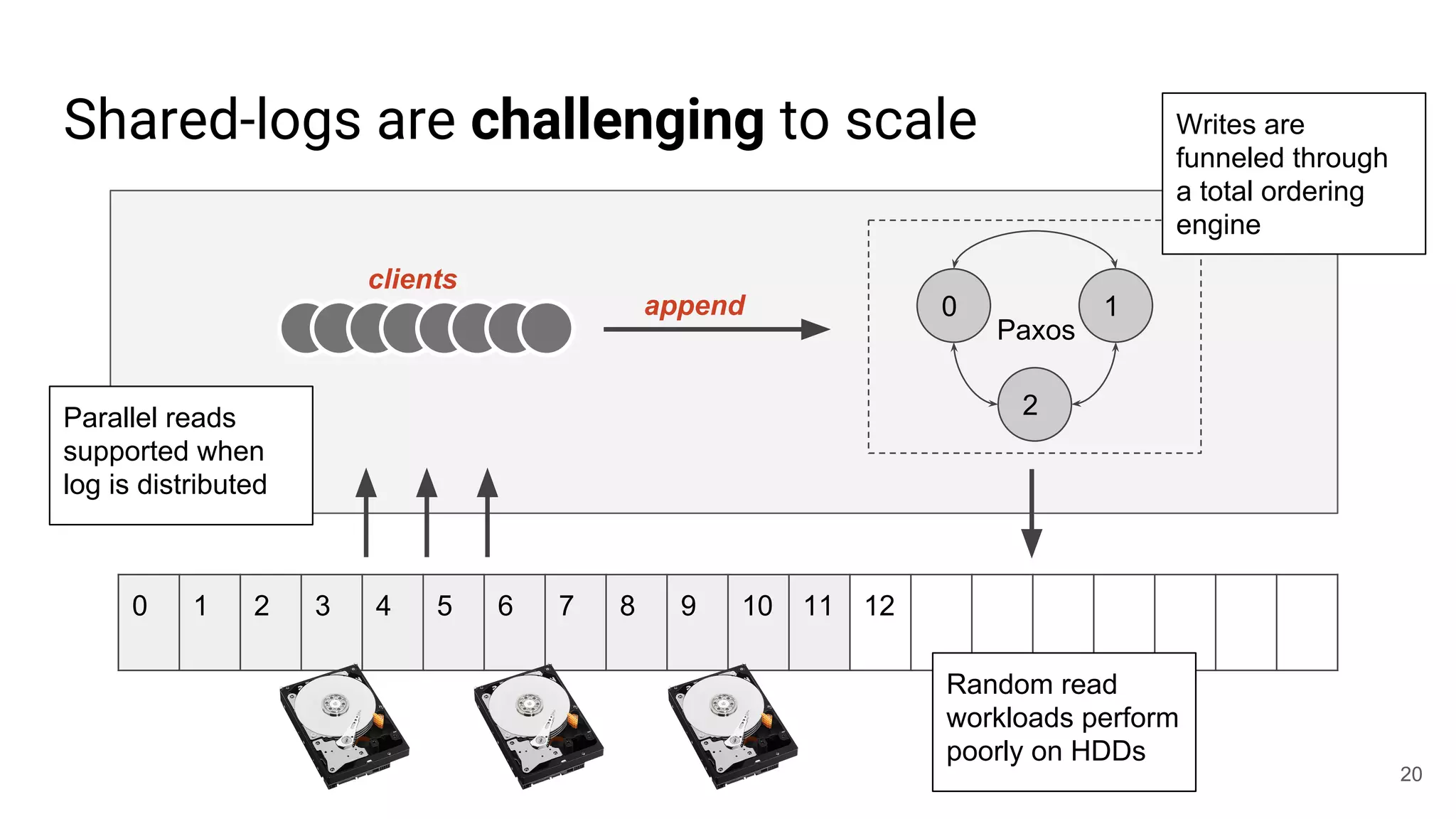
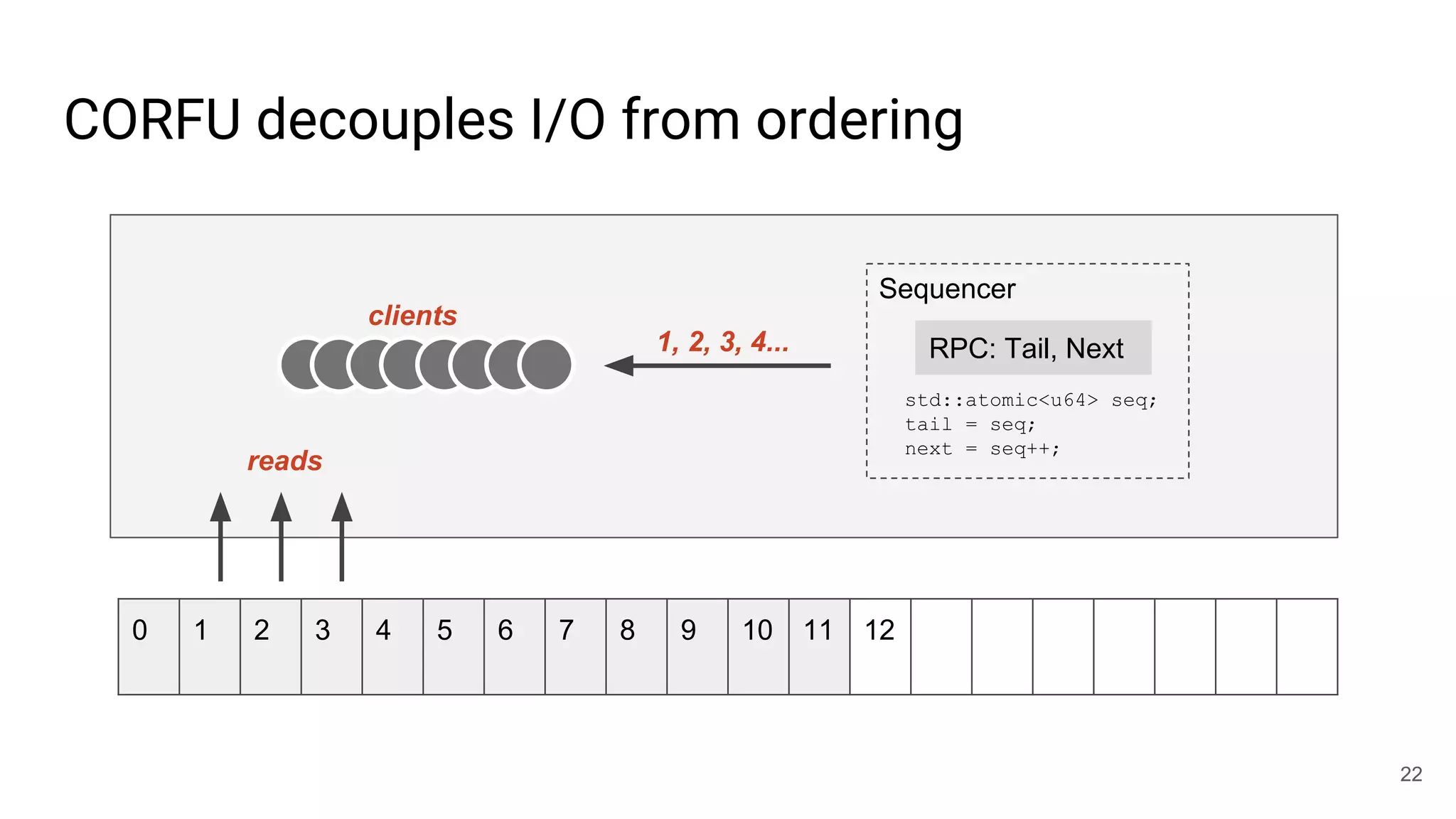
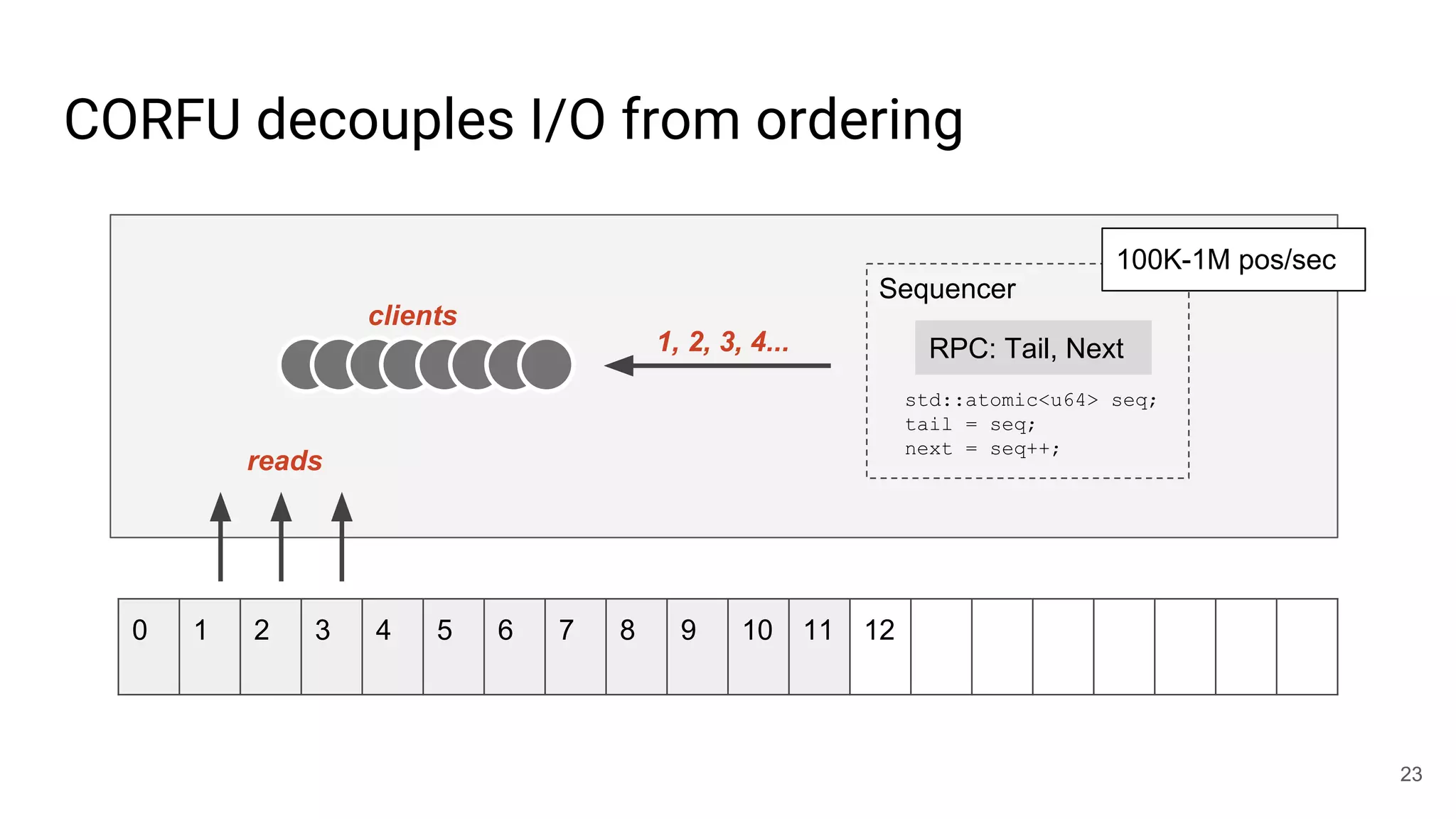
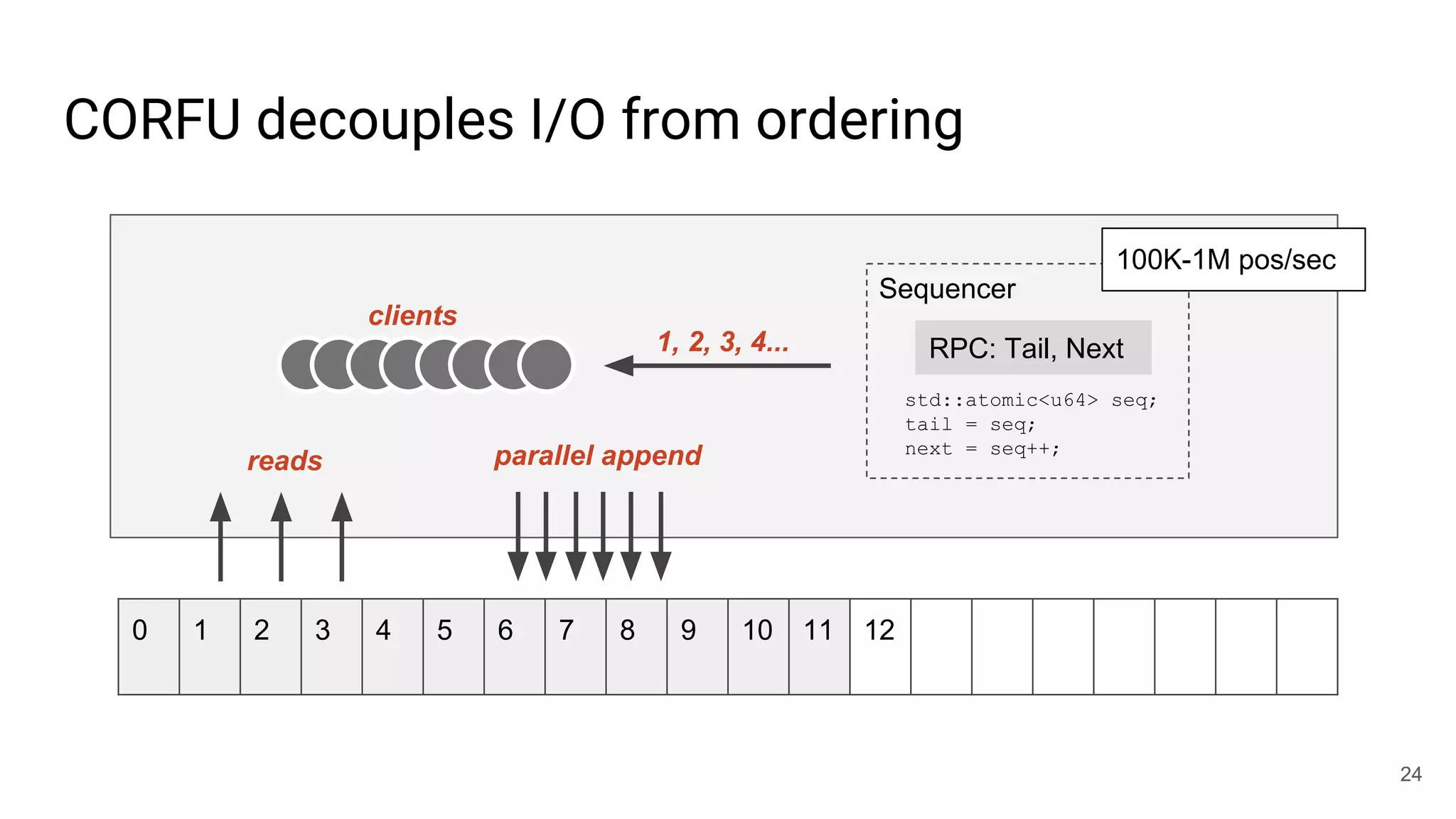
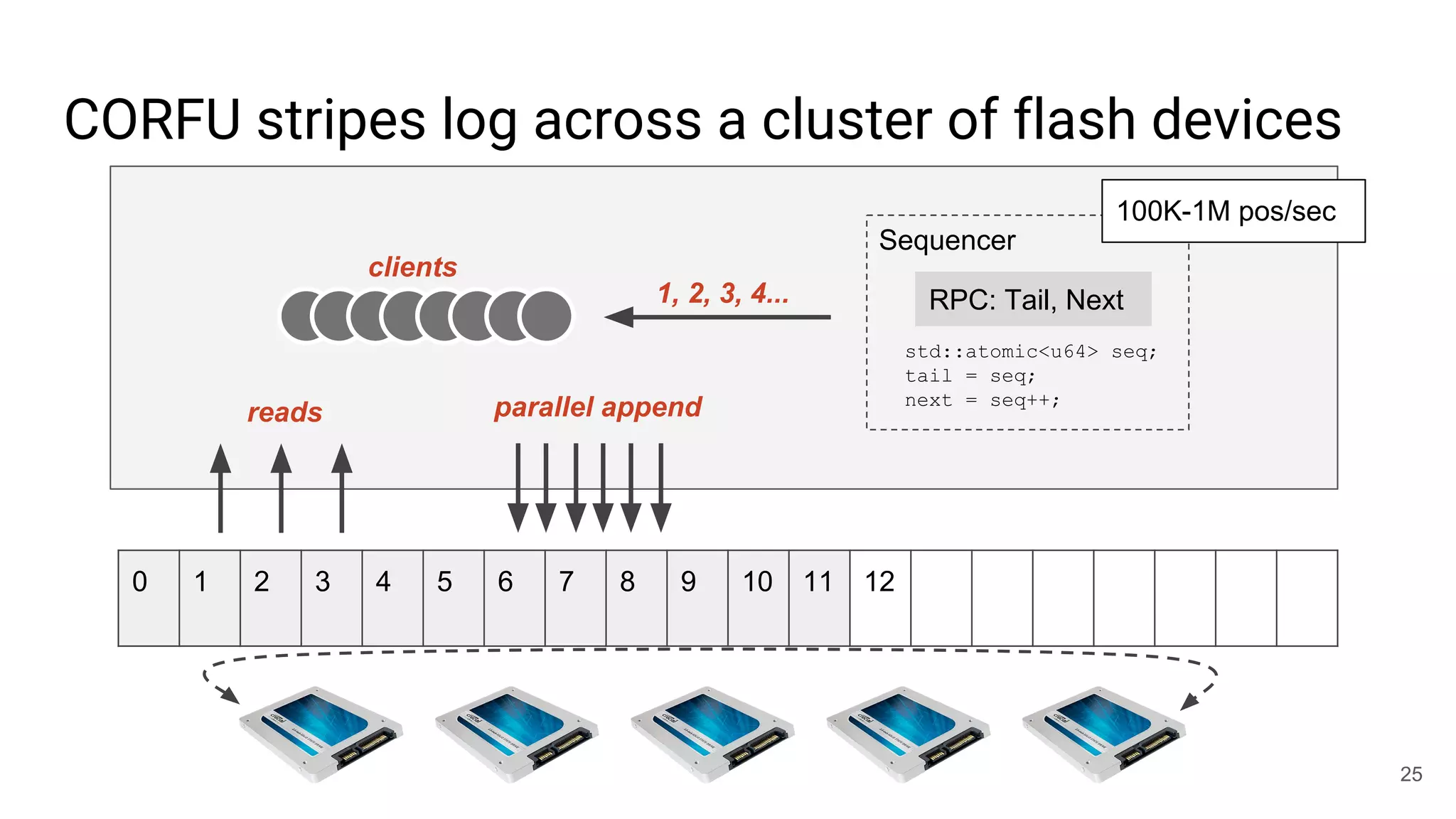
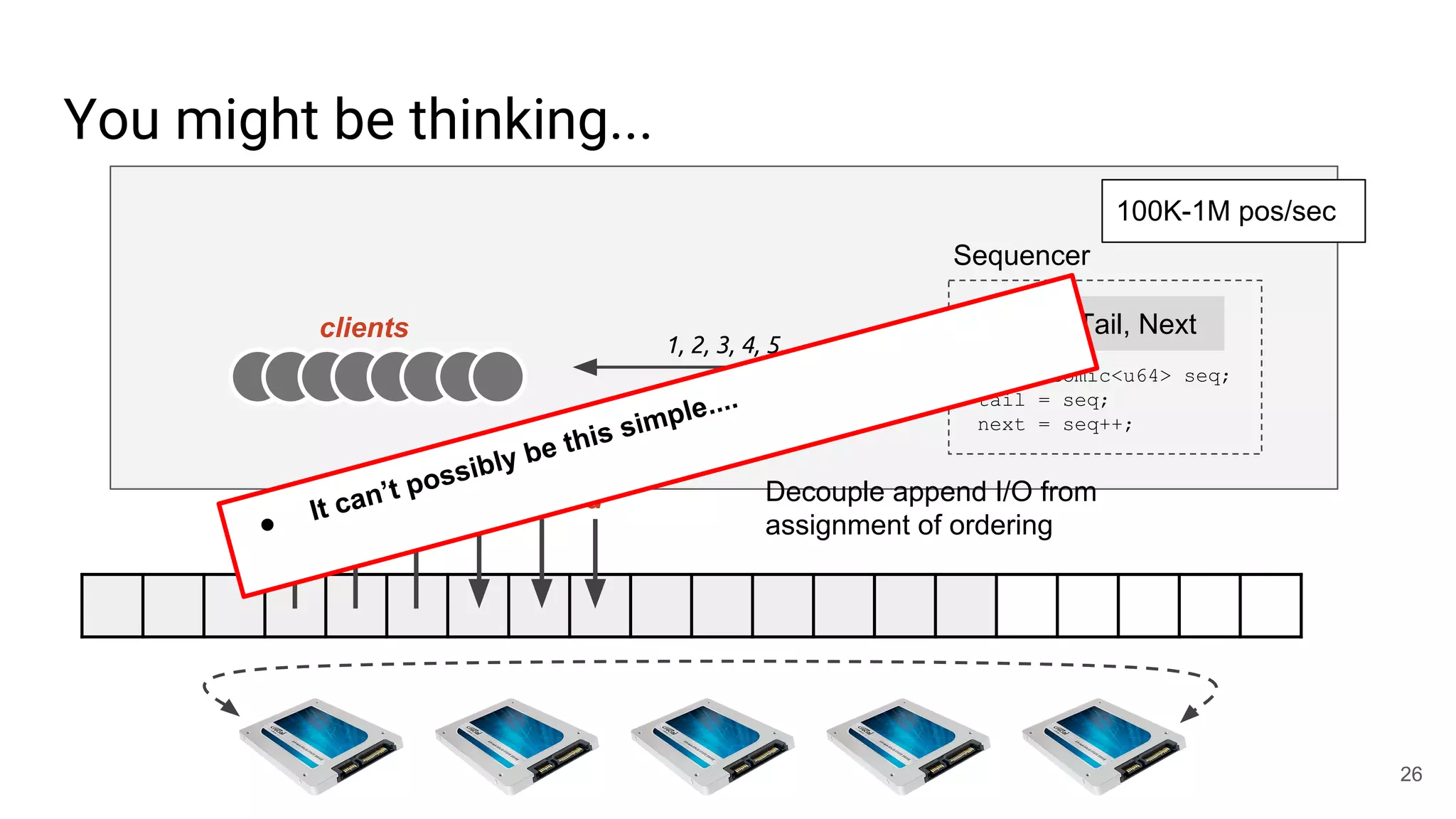
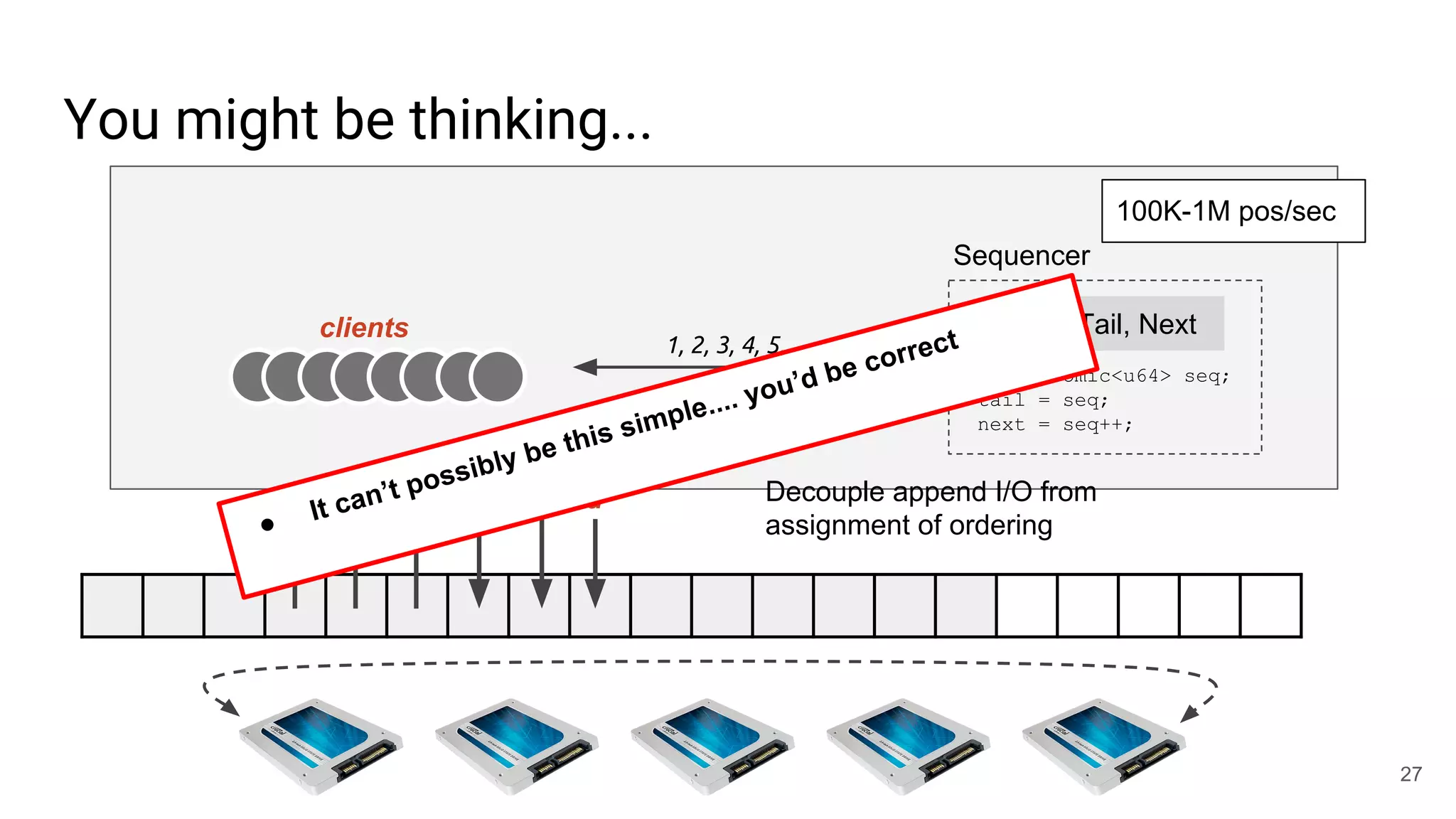
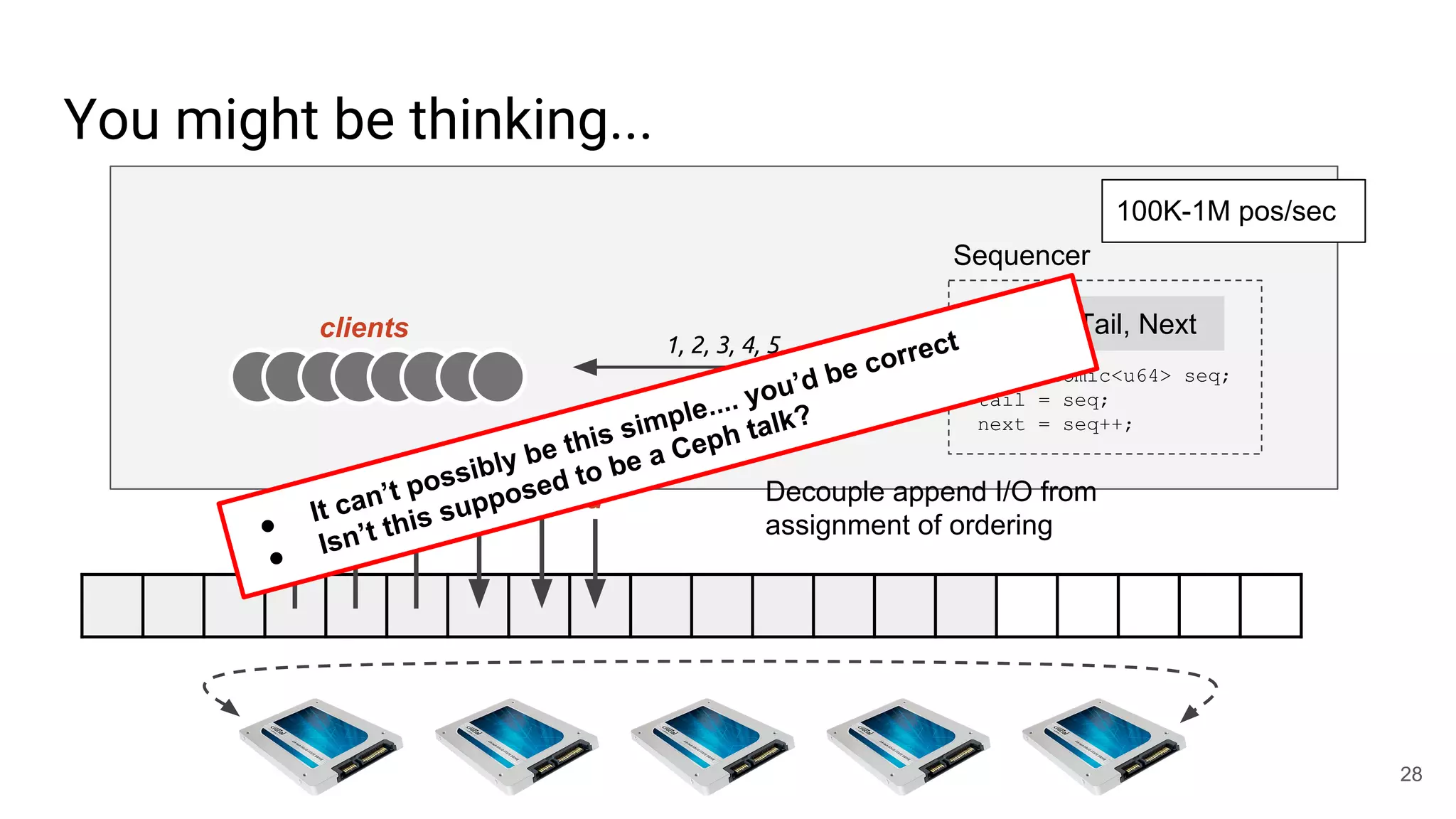
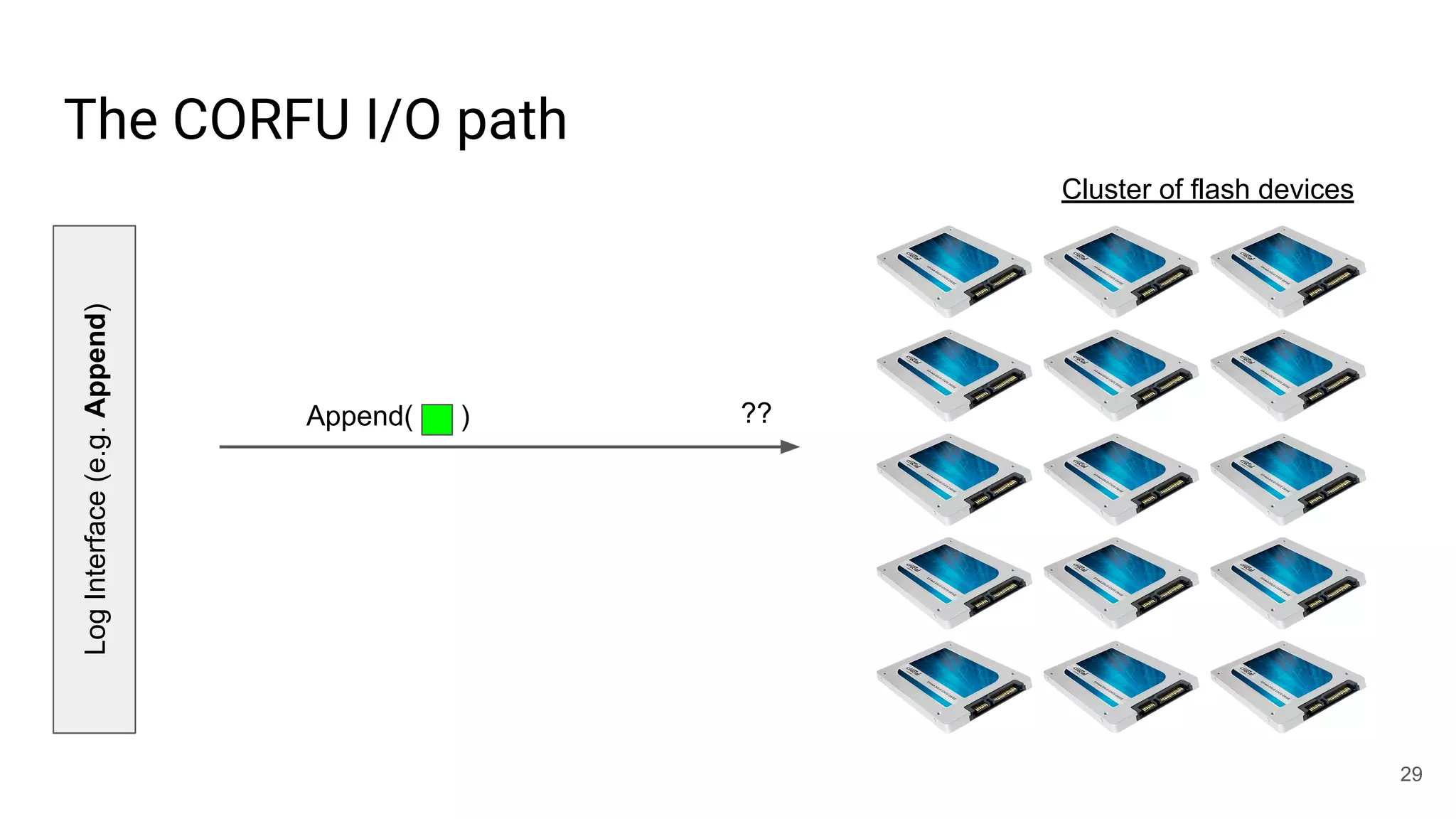
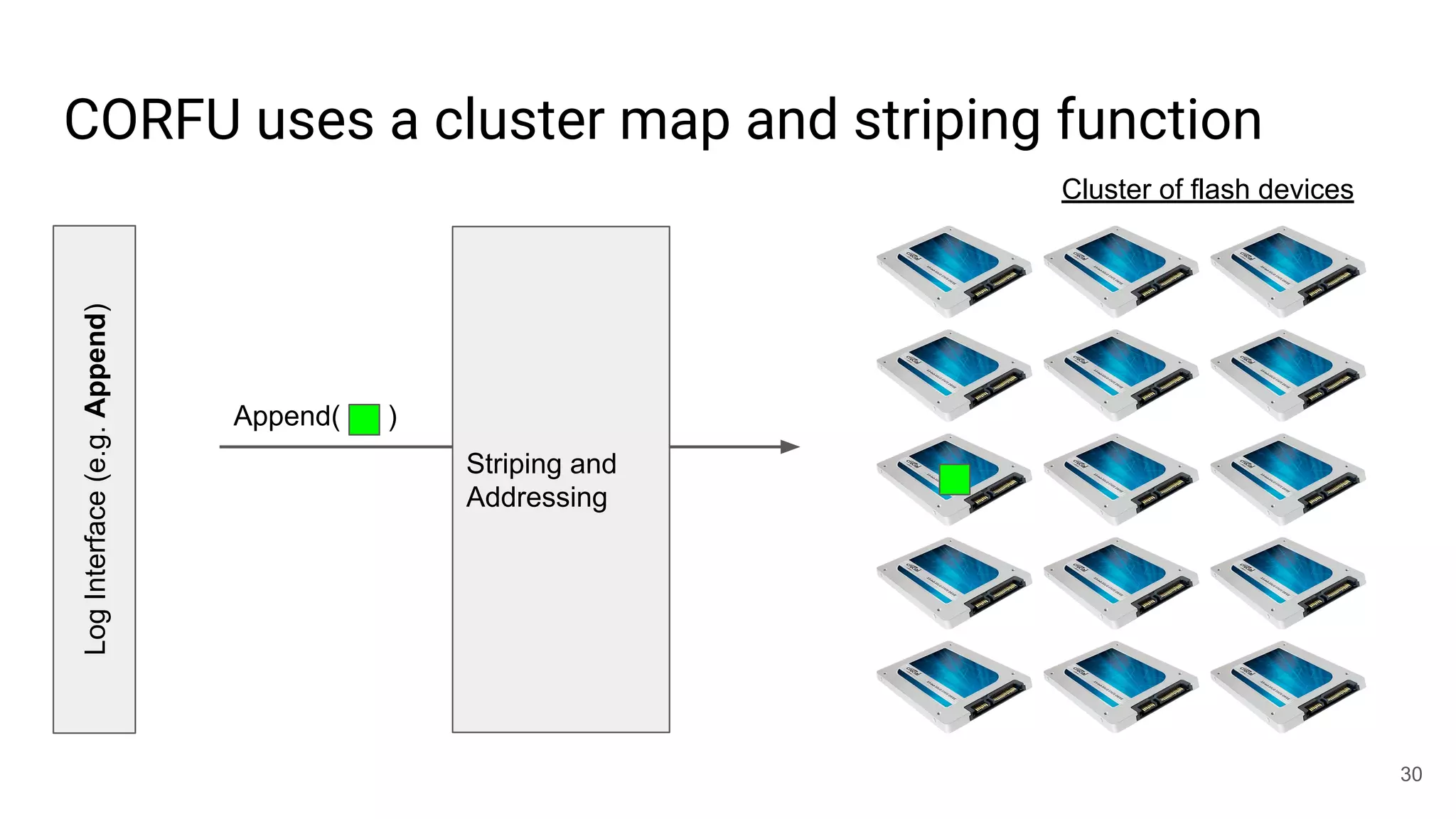
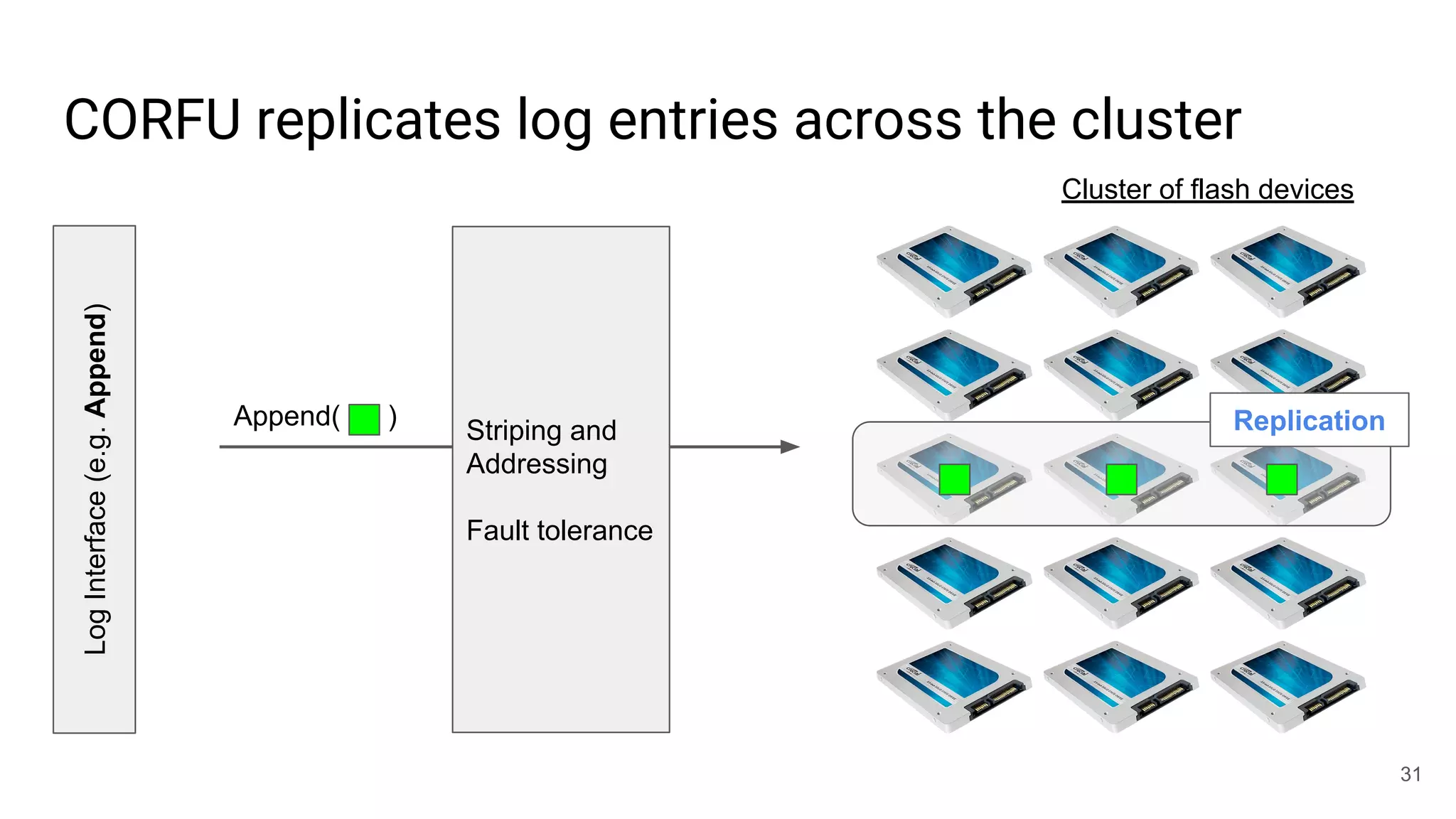
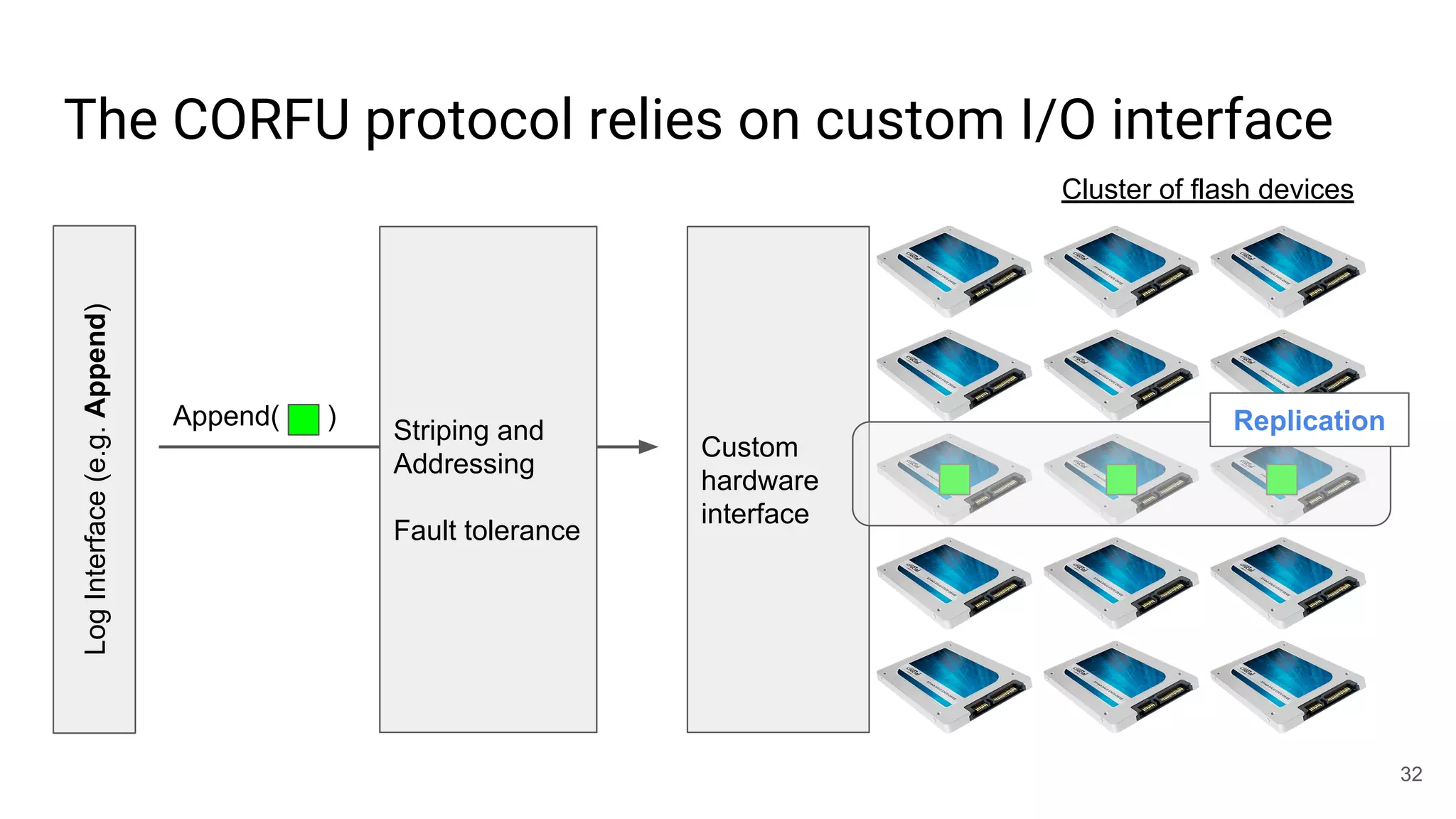
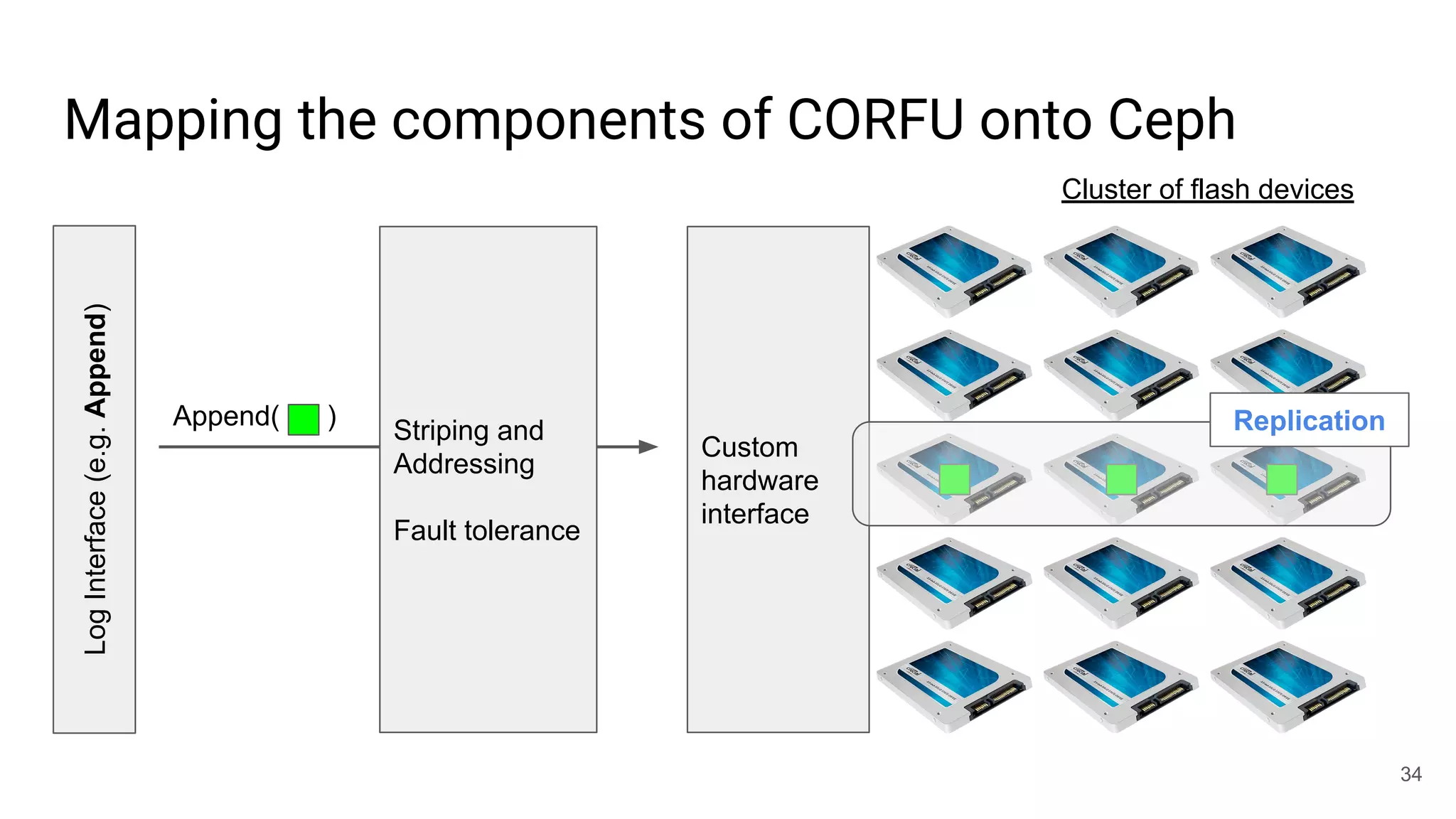
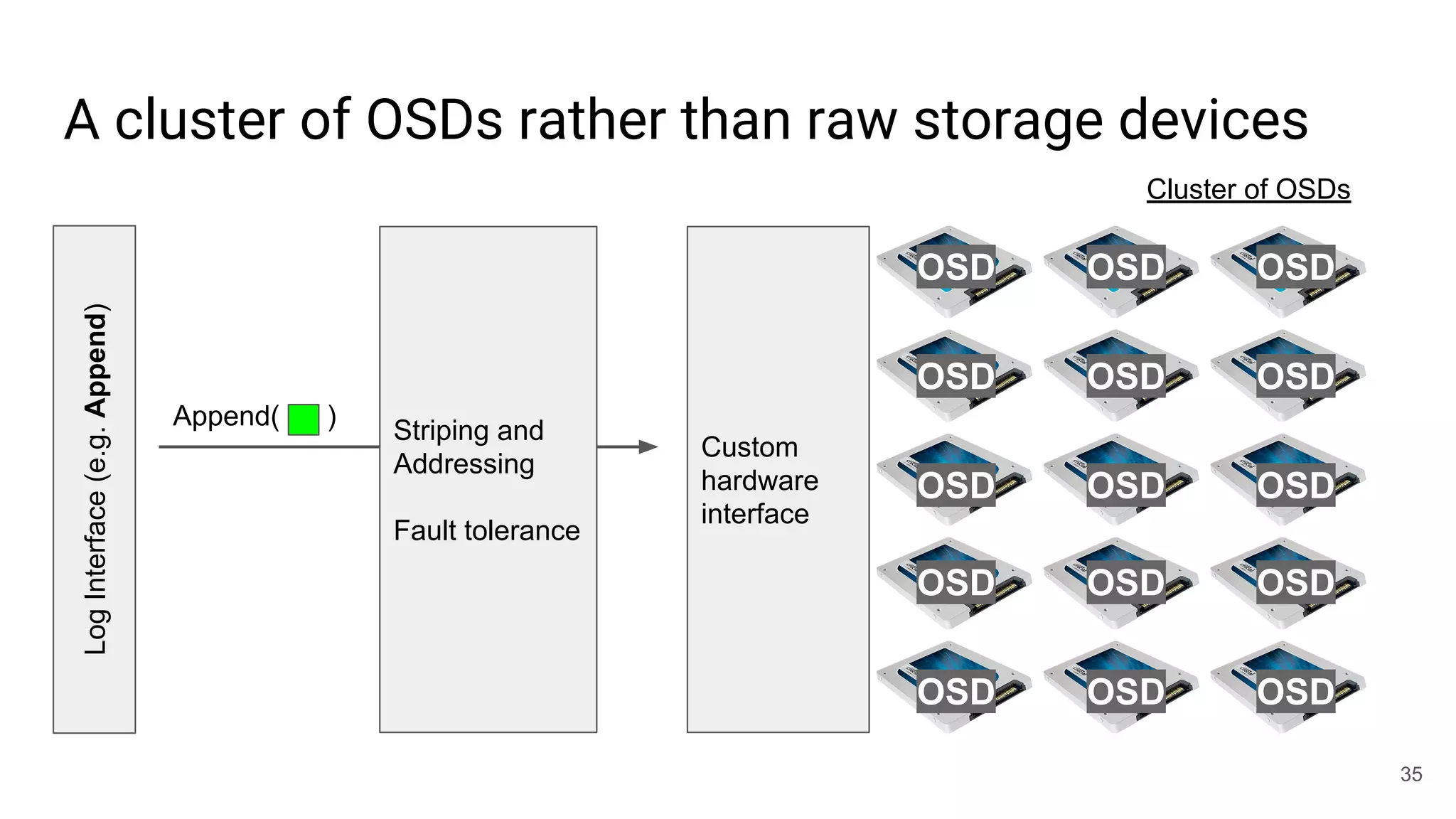
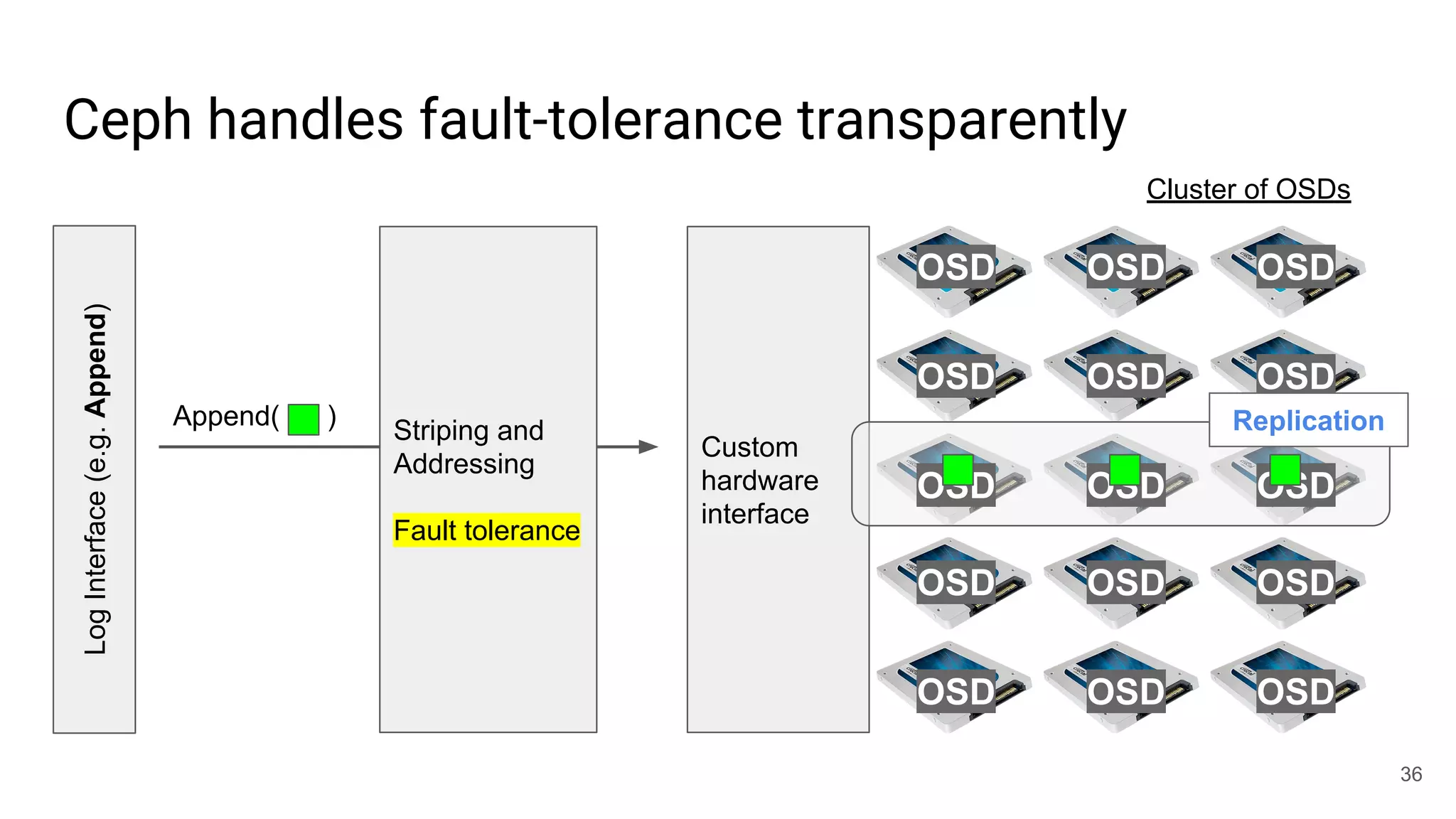
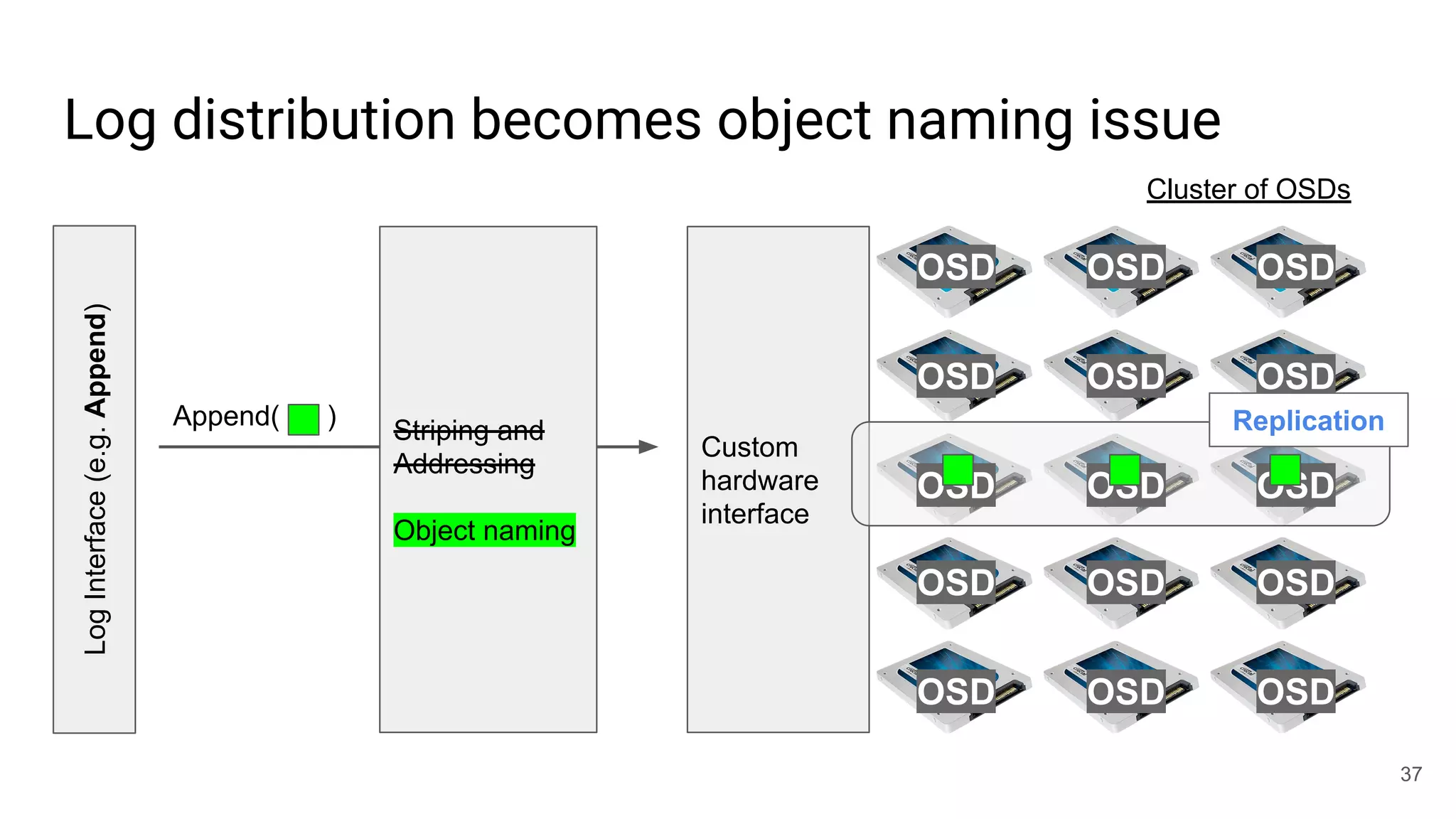
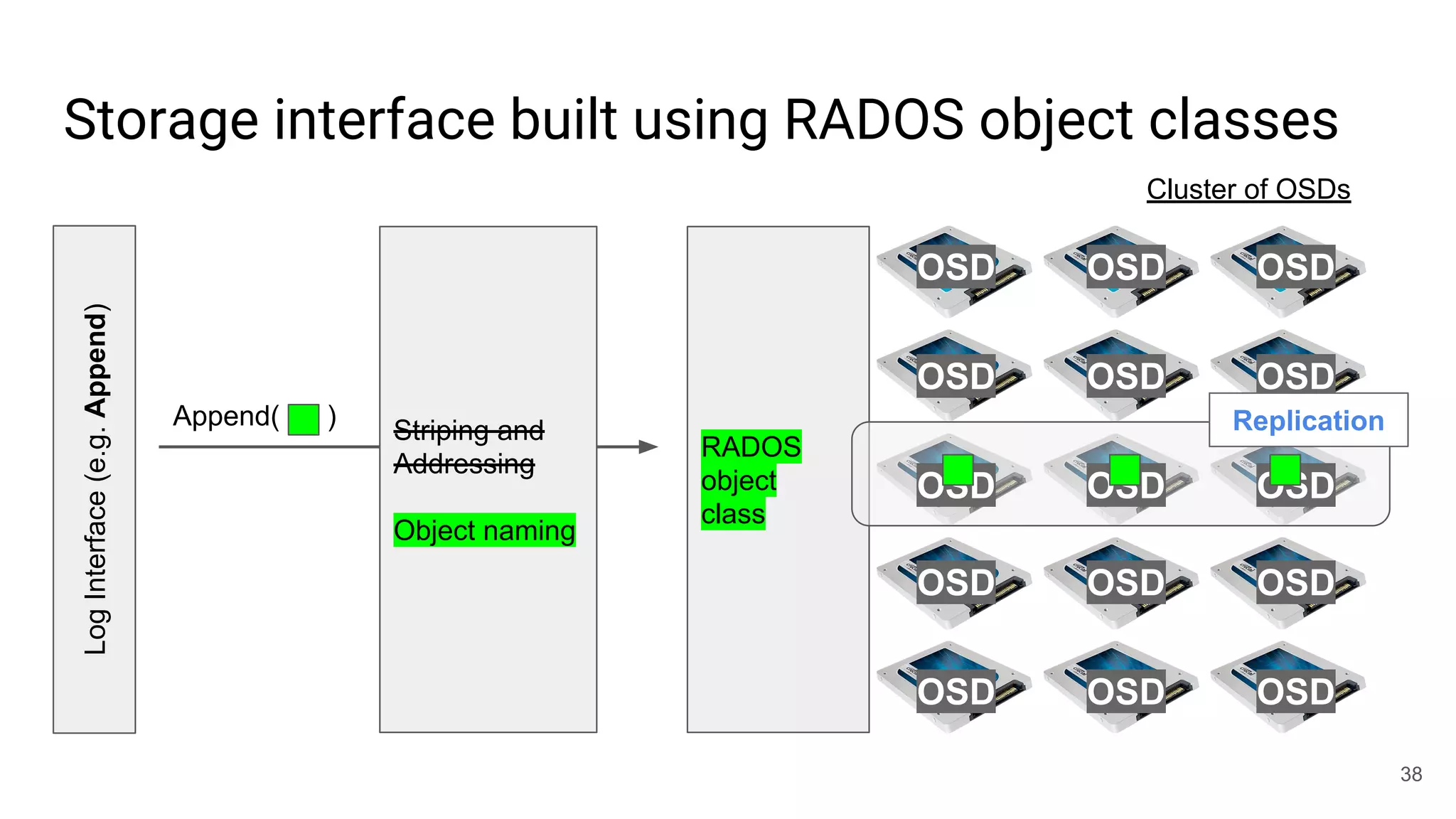
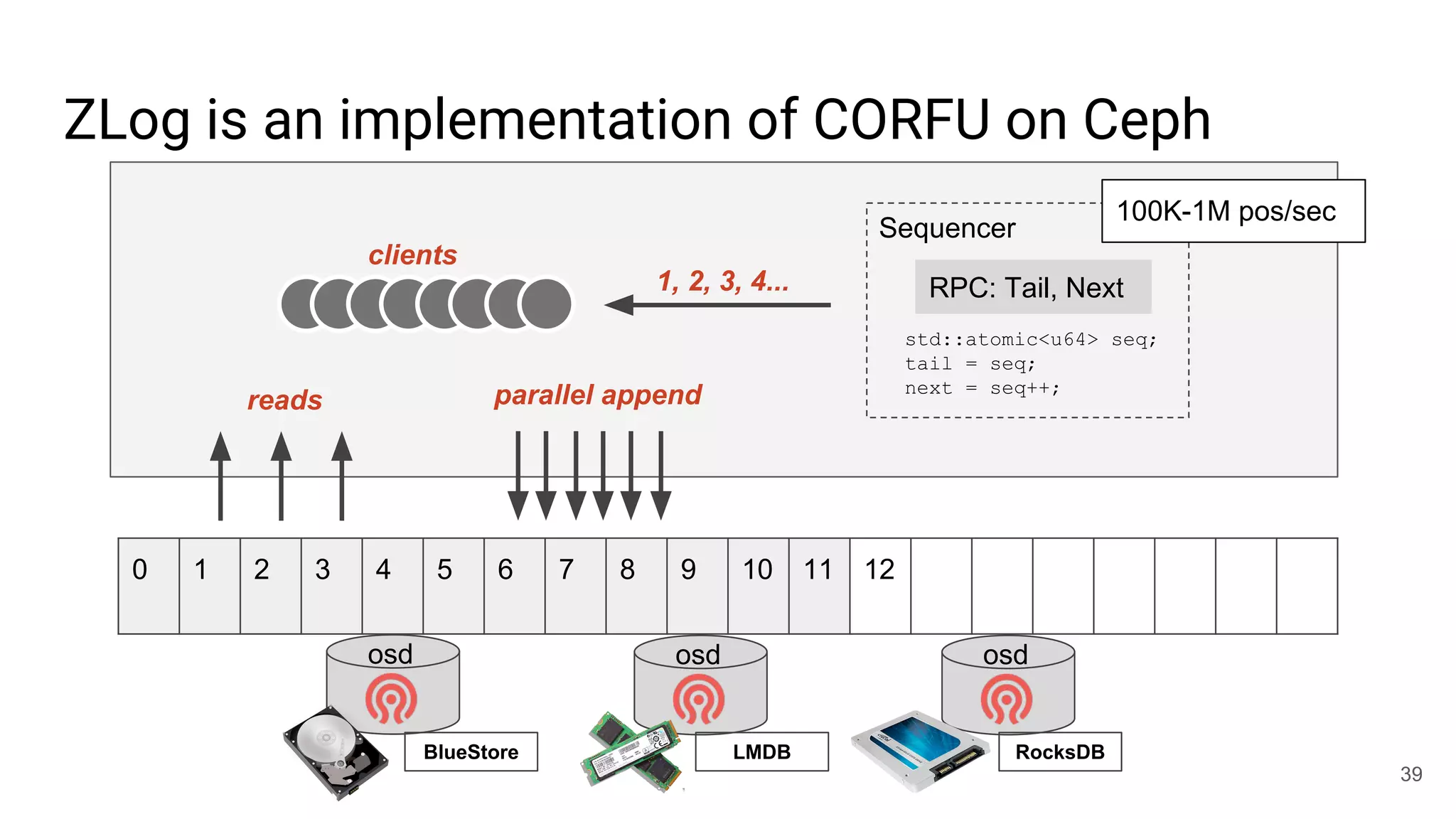
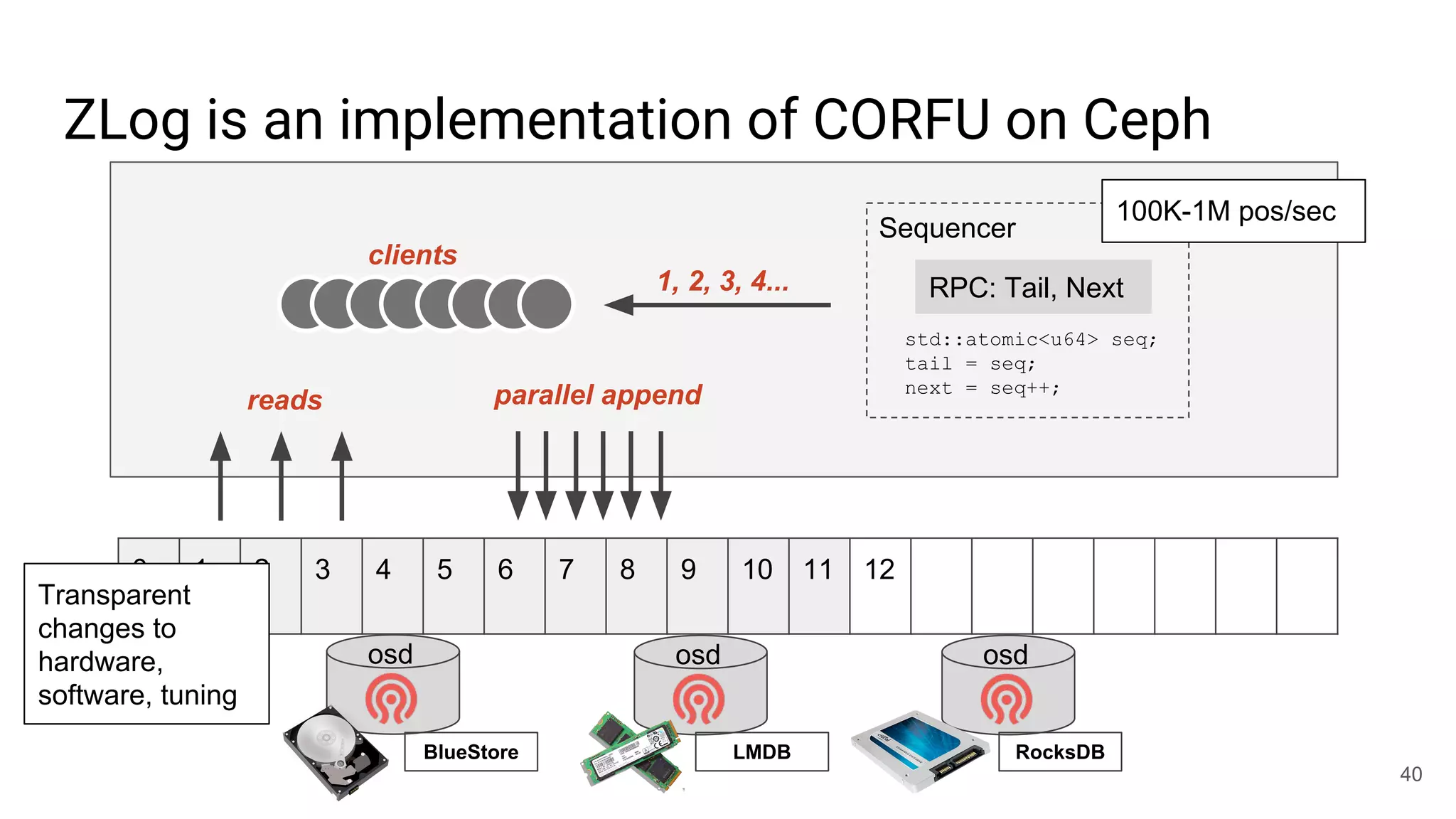
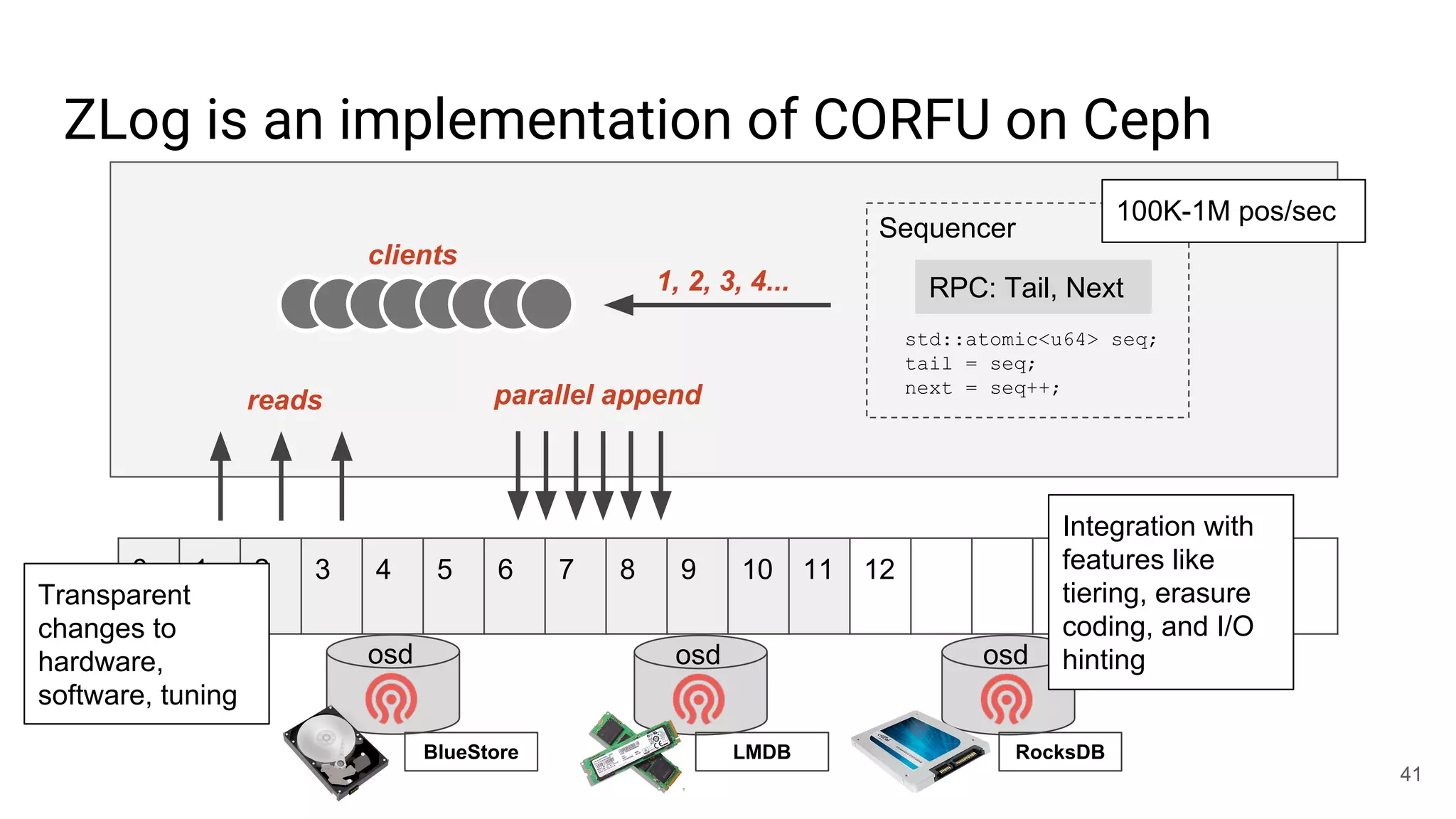
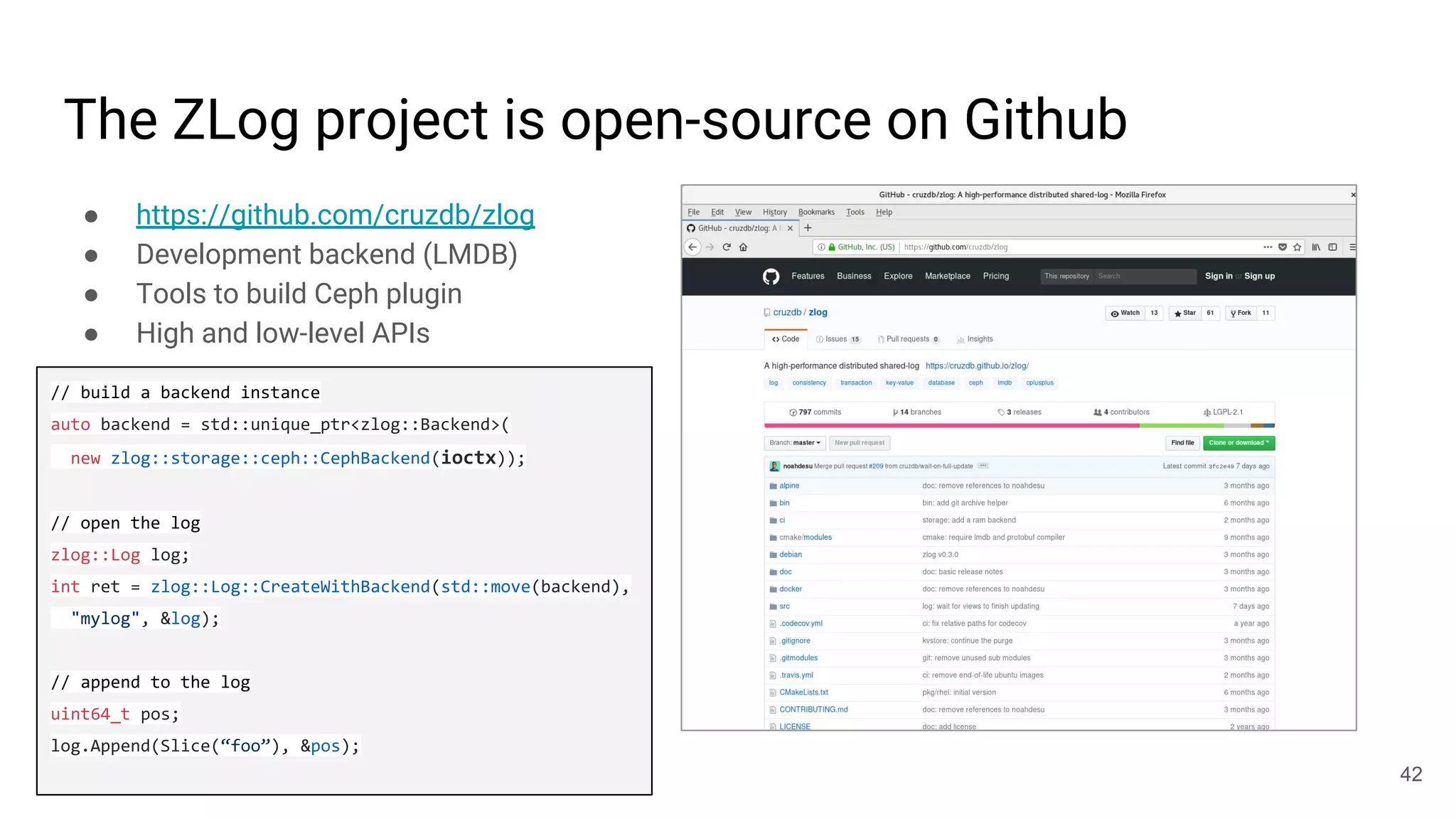
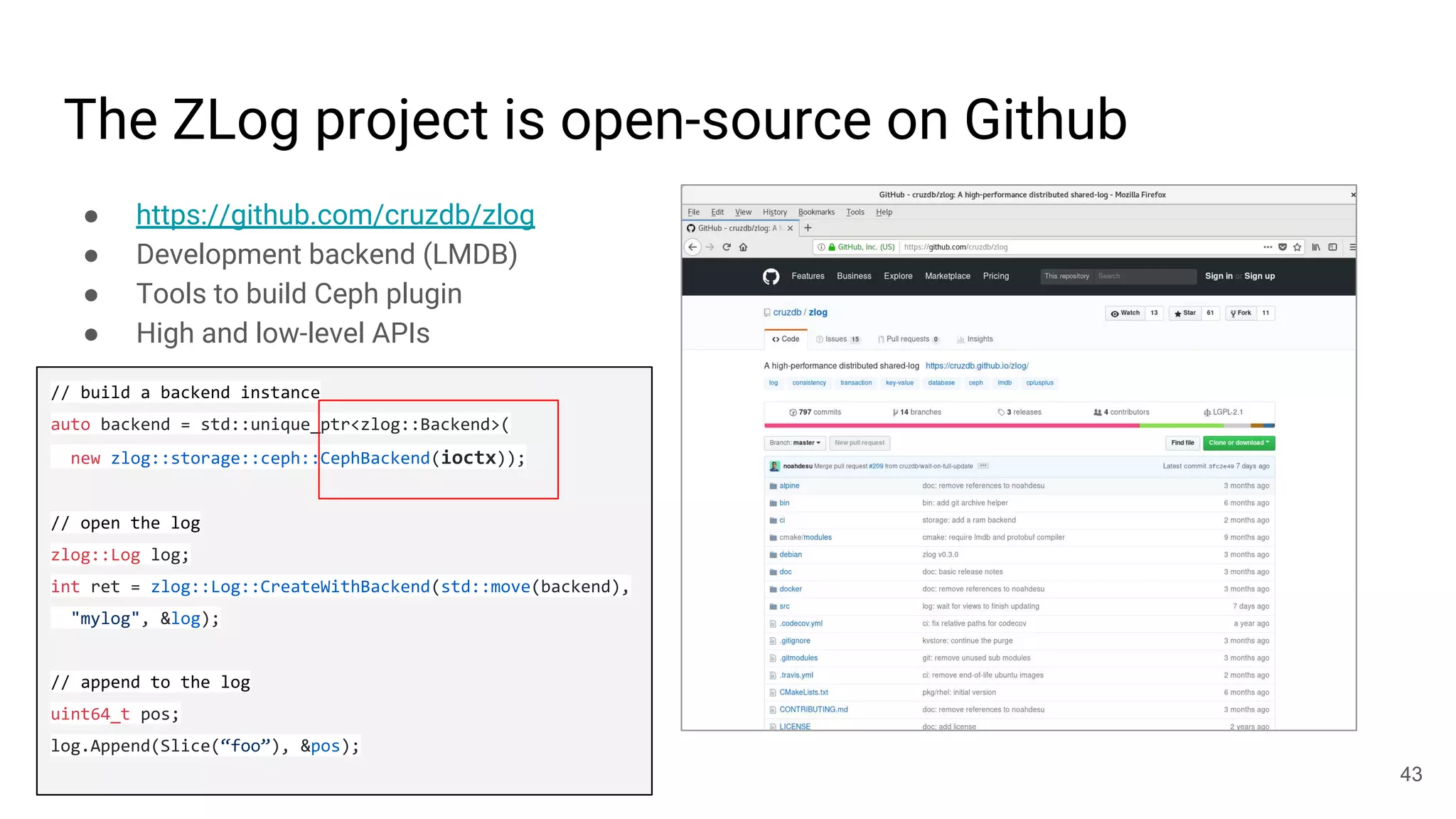
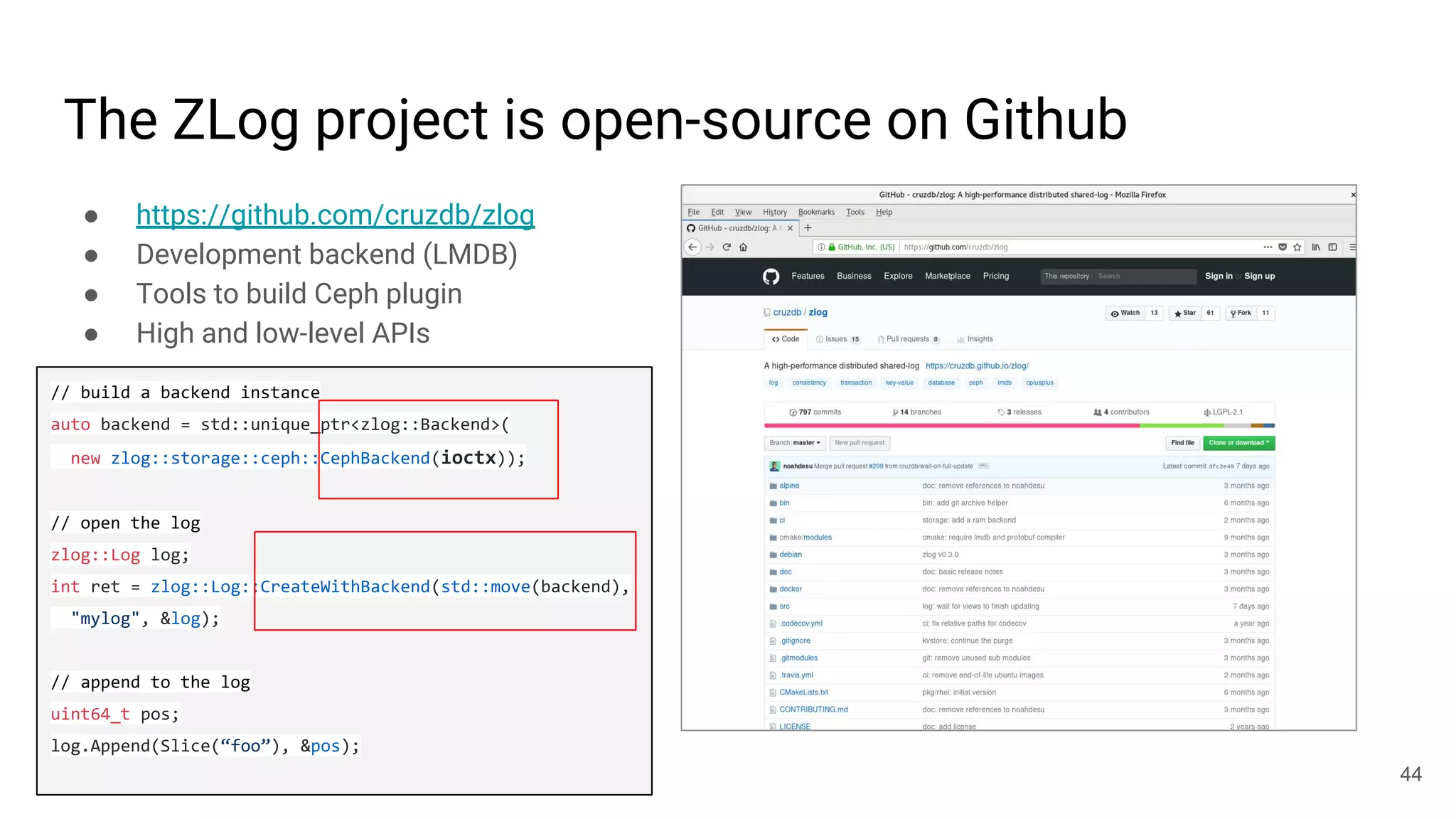
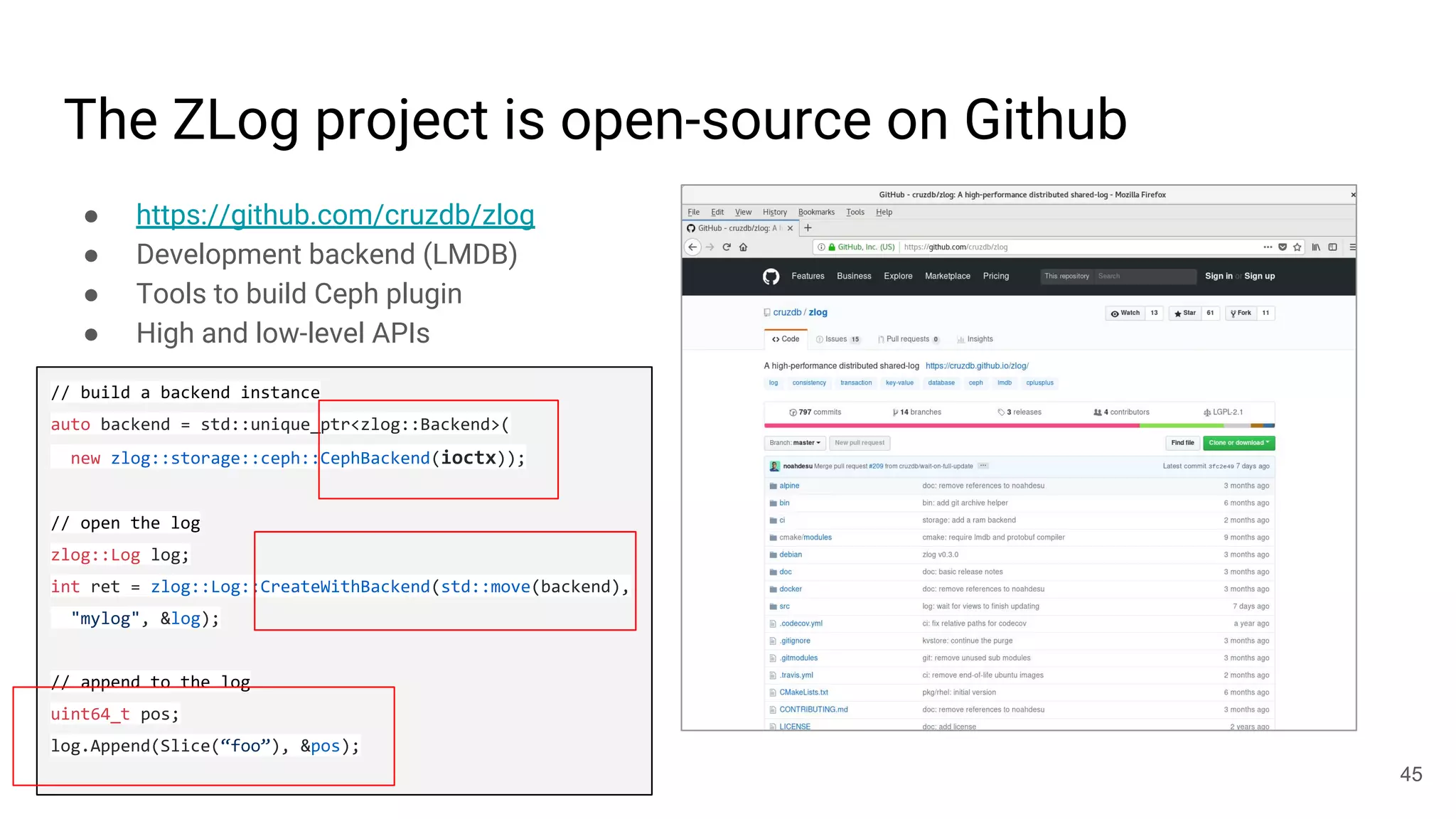
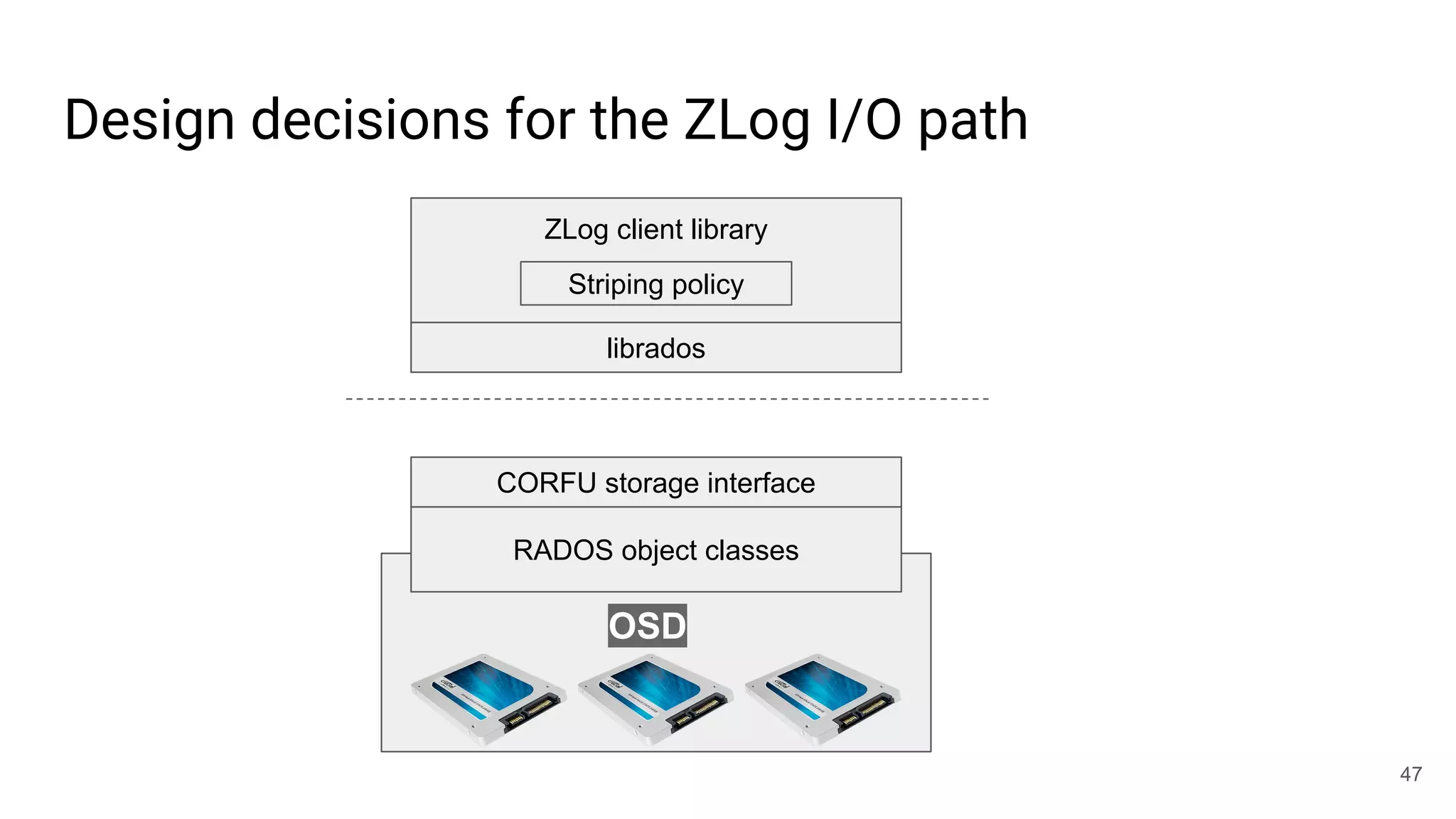
This document summarizes Noah Watkins' presentation on building a distributed shared log using Ceph. The key points are: 1) Noah discusses how shared logs are challenging to scale due to the need to funnel all writes through a total ordering engine. This bottlenecks performance. 2) CORFU is introduced as a shared log design that decouples I/O from ordering by striping the log across flash devices and using a sequencer to assign positions. 3) Noah then explains how the components of CORFU can be mapped onto Ceph, using RADOS object classes, librados, and striping policies to implement the shared log without requiring custom hardware interfaces. 4) ZLog is presented



















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














