Downloaded 17 times




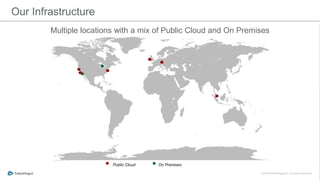


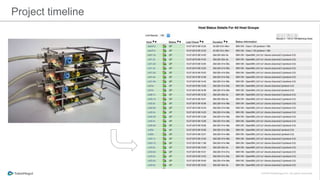
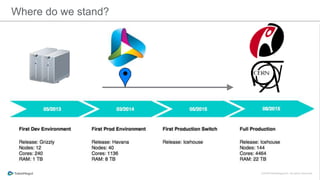




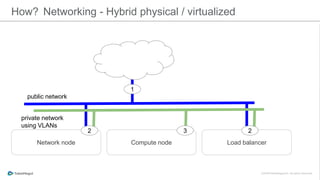
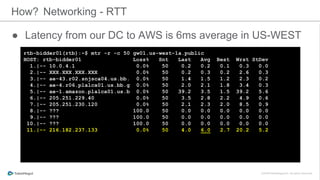







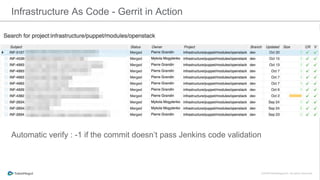
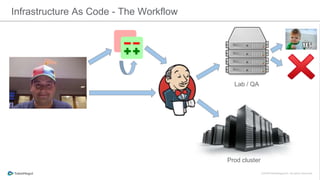






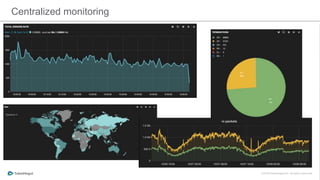
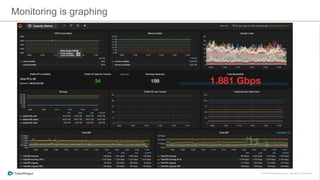

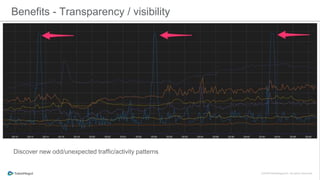

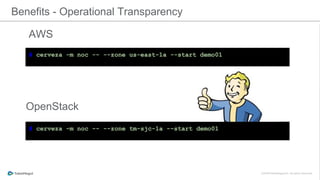
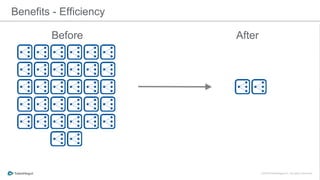
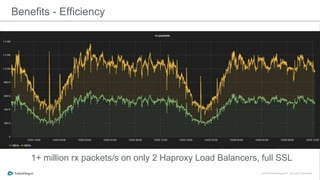






The document discusses the implementation of a private cloud by Tubemogul, designed to handle over 40 billion requests per day while optimizing costs and operational stability. It outlines the challenges faced during the transition from AWS to OpenStack, including application migration, networking concerns, and the need for an effective monitoring system. The document also emphasizes lessons learned regarding hybrid systems and the importance of ensuring continuous communication between development and operations teams.






































![[Rakuten TechConf2014] [F-4] At Rakuten, The Rakuten OpenStack Platform and B...](https://cdn.slidesharecdn.com/ss_thumbnails/f4openstackrakutentechnologyconference20141025-141105211349-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




























