Downloaded 99 times













![for (i= 0; i< 128; i++) {
a[i] = b[i] + c[i];
} for (i= 0; i< 128; i+=4) { a[i] = b[i] + c[i]; a[i+1] = b[i+1] + c[i+1]; a[i+2] = b[i+2] + c[i+2]; a[i+3] = b[i+3] + c[i+3]; }
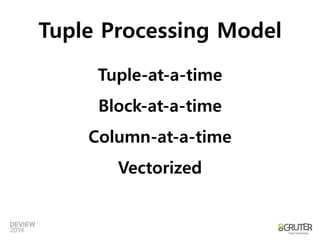
Original Loop
Unrolled Loop
지시자: #pragmaGCC optimize ("unroll-loops")
컴파일옵션: -funroll-loops 등
Loop unrolling
컴파일러옵션또는지시자로설정가능
Control Hazard 개선
조건비교](https://image.slidesharecdn.com/2a2vectorizedprocessinginanutshell-140929192632-phpapp02/85/2A2-Vectorized_processing_in_a_Nutshell-19-320.jpg)
![for (inti= 0; i< num; i++) {
if (data[i] >= 128) {
sum += data[i];
}
}
for (inti= 0; i< num; i++) {
int v = (data[i] -128) >> 31;
sum += ~v & data[i];
}
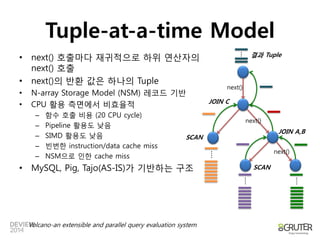
Branch version
Non branch version
Branch avoidance
http://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-an-unsorted-array
Random data : 35,683 ms
Sorted data : 11,977 ms
11,977 ms10,402 ms
Control Hazard 개선](https://image.slidesharecdn.com/2a2vectorizedprocessinginanutshell-140929192632-phpapp02/85/2A2-Vectorized_processing_in_a_Nutshell-20-320.jpg)


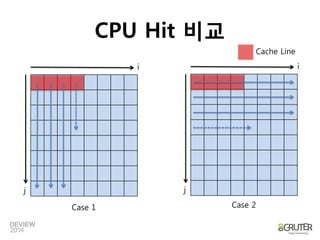
![for (i= 0 to size)
for (j = 0 to size)
do something with ary[j][i]
for (i= 0 to size)
for (j = 0 to size)
do something with ary[i][j]
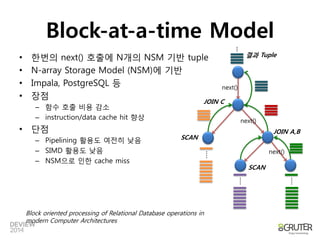
인접하지않은메모리를반복해서
읽기때문에비효율적
순차읽기로인한높은cache hit
Case 1
Case 2
CPU Hit 비교
Classic Example of Spatial Locality](https://image.slidesharecdn.com/2a2vectorizedprocessinginanutshell-140929192632-phpapp02/85/2A2-Vectorized_processing_in_a_Nutshell-23-320.jpg)




![OR
출처:[Marcin2009]
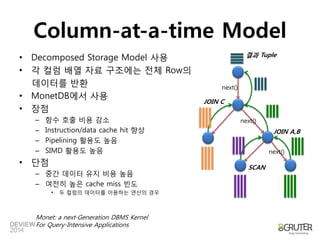
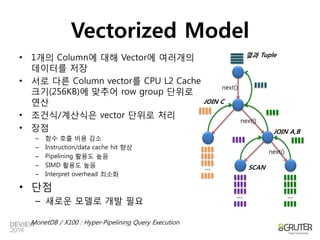
TupleMemory Model
N-array Storage Model
Decomposed Storage
Model](https://image.slidesharecdn.com/2a2vectorizedprocessinginanutshell-140929192632-phpapp02/85/2A2-Vectorized_processing_in_a_Nutshell-30-320.jpg)

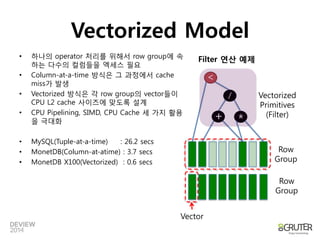
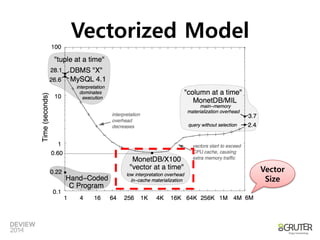
![Column-at-a-time Model
•성능비교
–MySQL: 26.2 sec, MonetDB: 3.7 sec
–TPCH-Q1(1 Table Groupby, Orderby, 결과데이터는4건)
–In-memory 데이터에대한비교실험결과
•논리연산/사칙연산별로별도Primitive 연산자필요
/* Returns a vector of row IDs’ satisfying comparison
* and count of entries in vector. */
intselect_gt_float(int* res, float* column, float val, intn) {
intidx=0;
for (inti= 0; i< n; i++) {
idx+= column[i] > val;
res[idx] = j;
}
return idx;
}
Greater-than primitive 연산자의예
기본데이터타입, 사칙연산, 논리연산에약5천여개필요](https://image.slidesharecdn.com/2a2vectorizedprocessinginanutshell-140929192632-phpapp02/85/2A2-Vectorized_processing_in_a_Nutshell-36-320.jpg)




This document discusses techniques for optimizing database query performance by better utilizing CPU resources. It introduces vectorized processing which processes multiple data values simultaneously using SIMD instructions. This improves CPU pipeline utilization and reduces cache misses. Vectorized processing requires storing data in columns rather than rows and processing columns of data together in vectors to enable SIMD instructions.




























![[SSA] 04.sql on hadoop(2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/04-140225072610-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[AWS summit 2019] 마이크로 서비스 패턴 데이터 베이스](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2019jkhkyd20190417final-191217131802-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [BICS팀] : Boaz Industry Classification Standard](https://cdn.slidesharecdn.com/ss_thumbnails/bics-210806012608-thumbnail.jpg?width=640&height=640&fit=bounds)







![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)



















