Download to read offline





![キーワード
• ⽬目的
– 耐障害性 [1]、省省電⼒力力 [2, 6]、性能指標 [4, 5]、
⾼高性能 [6, 7]
• システム
– リソースプロビジョニング・スケジューラ [1, 4, 5]
– IaaS: OpenStack [6], CloudStack [7]
– ワークフロー [8]
• アプリケーション
– MPI [6, 7]
– Bag of Tasks [2], Bag of Distributed Tasks [4]
– Webアプリ (FFmpeg, MongoDB, Ruby on Rails) [5]
– モンテカルロ [8]
– Earthquake Engineering [3]
6](https://image.slidesharecdn.com/jpgridws-150206082455-conversion-gate02/85/IEEE-CloudCom-2014-6-320.jpg)



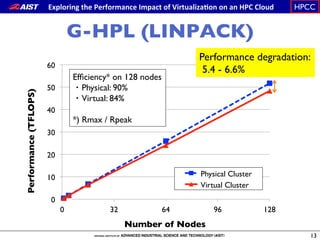
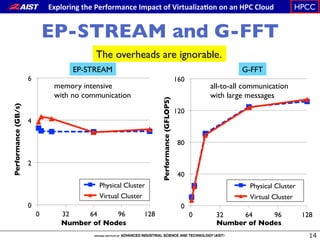
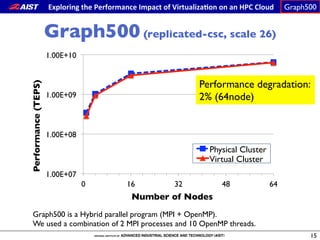


The document summarizes the author's participation report at the IEEE CloudCom 2014 conference. Some key points include: - The author attended sessions on virtualization and HPC on cloud. - Presentations had a strong academic focus and many presenters were Asian. - Eight papers on HPC on cloud covered topics like reliability, energy efficiency, performance metrics, and applications like Monte Carlo simulations.























































































