Download to read offline


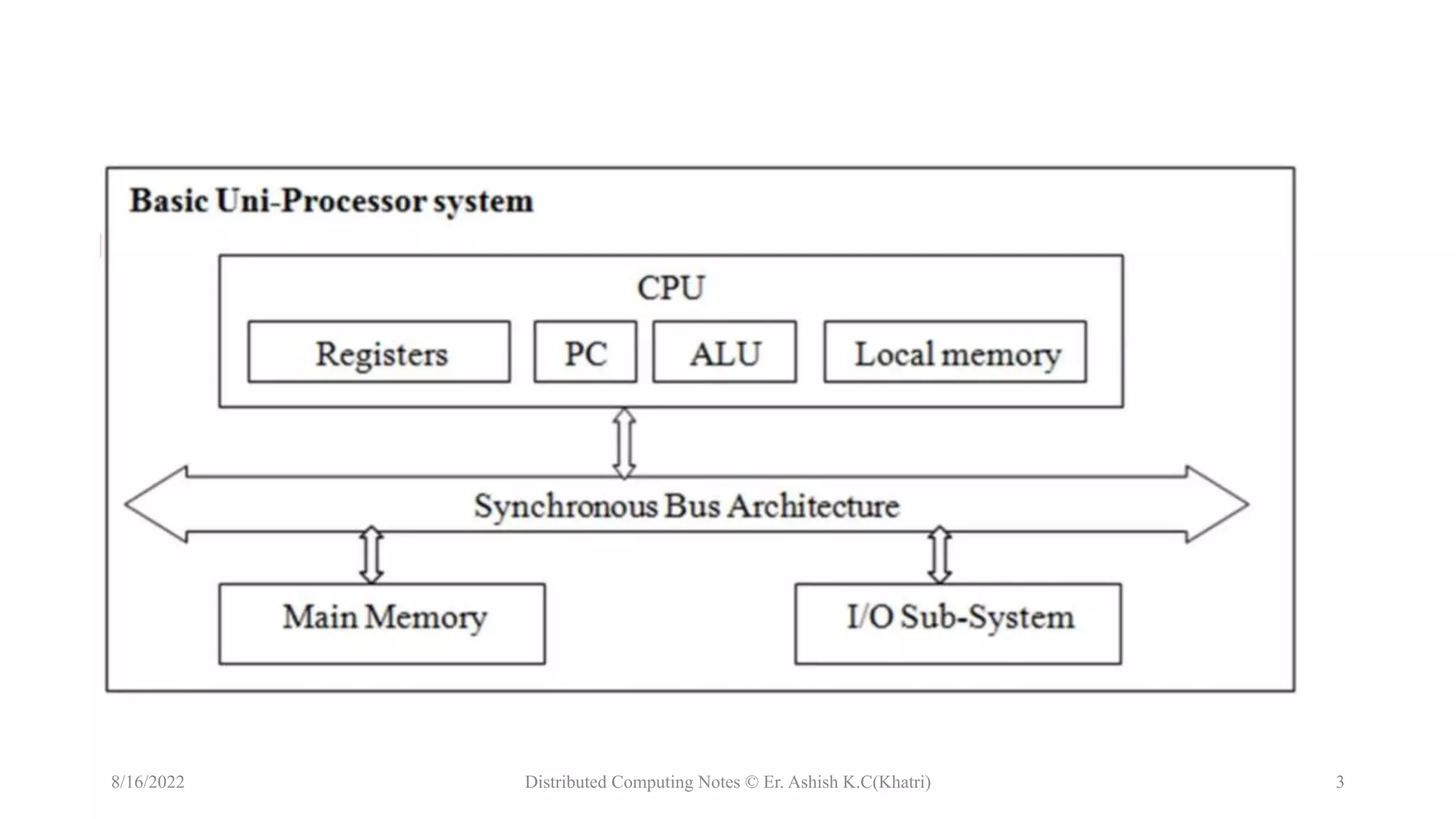
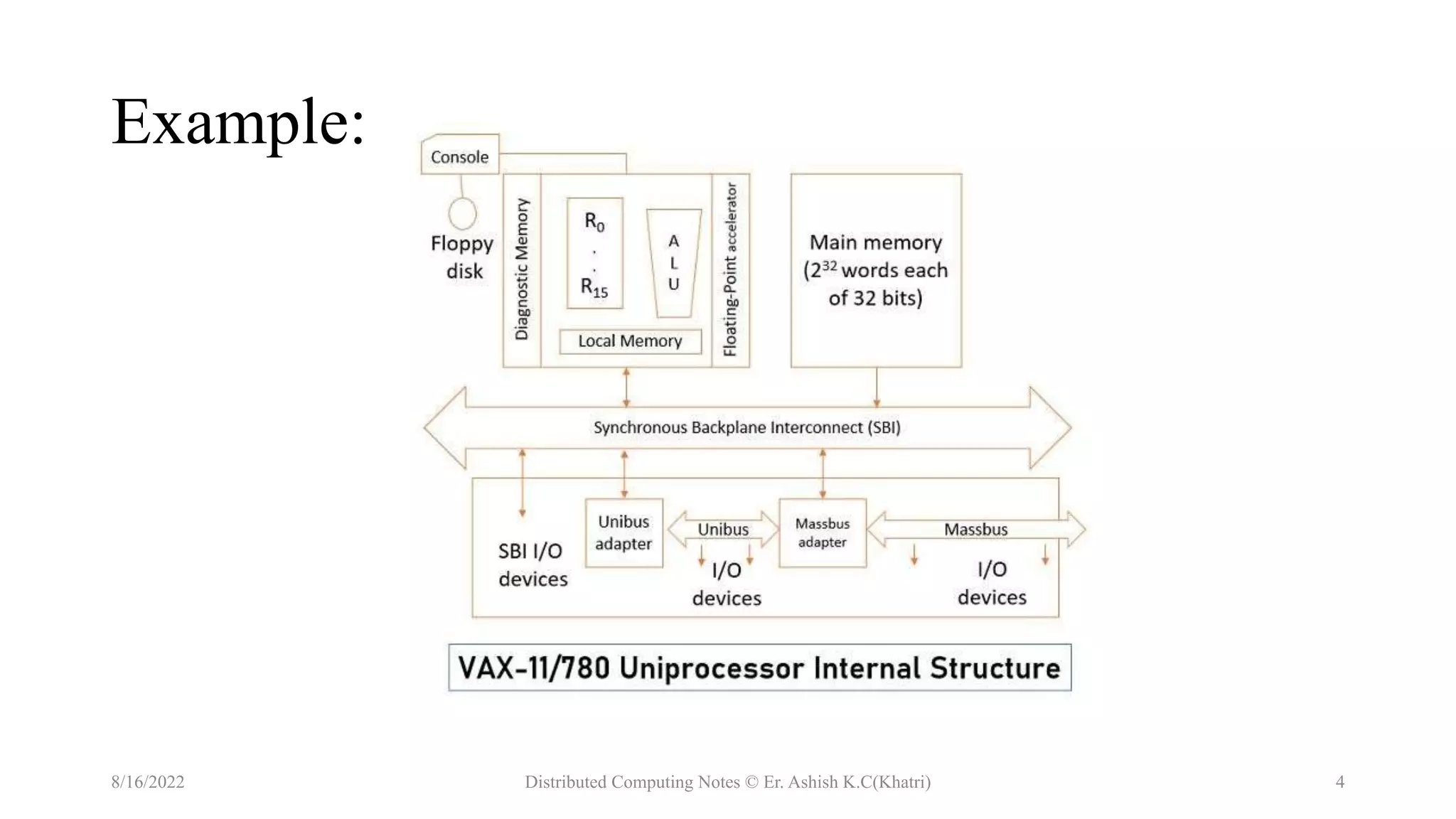





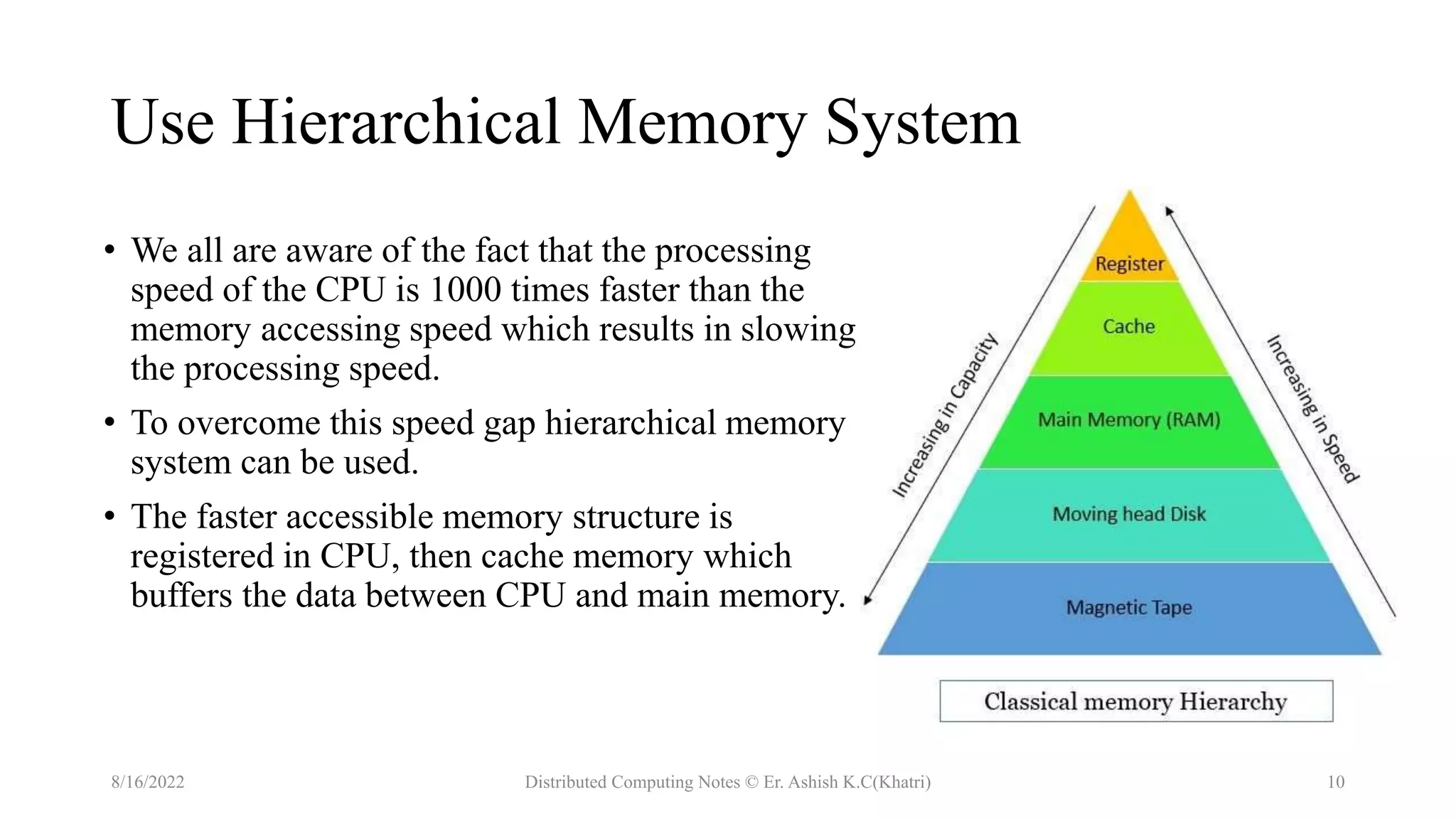












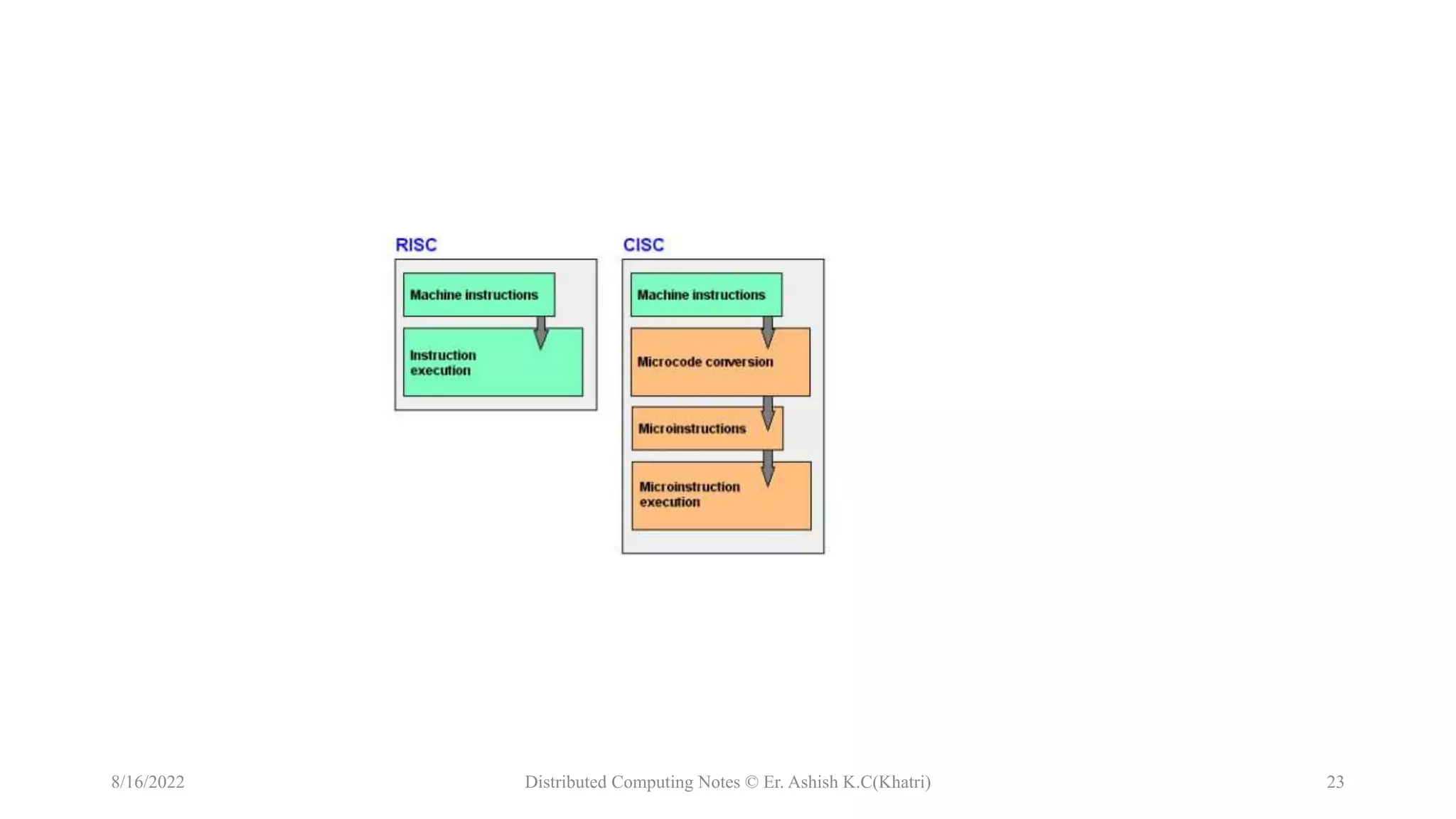


The document discusses uniprocessor architecture, detailing its components including the CPU, main memory, and I/O systems, and explores mechanisms for parallel processing. It contrasts CISC (Complex Instruction Set Computer) and RISC (Reduced Instruction Set Computer) architectures, highlighting their characteristics, advantages, and disadvantages. The text emphasizes the importance of hardware and software approaches to enhance processing efficiency through parallelism and task interleaving.























































































