


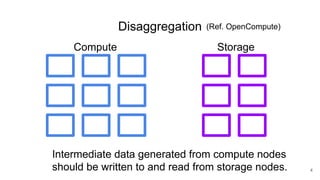

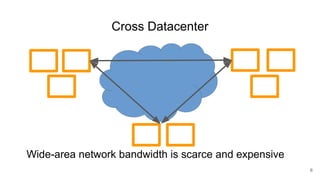





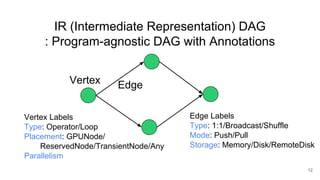

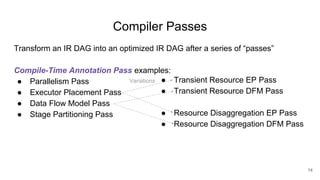
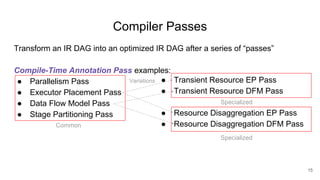


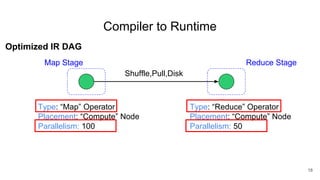
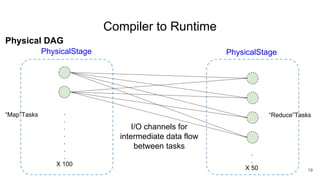
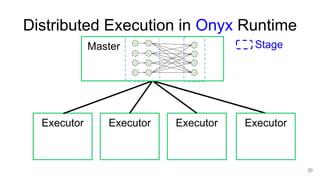




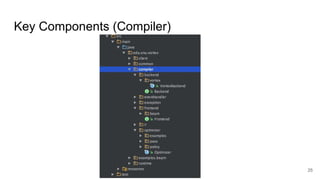

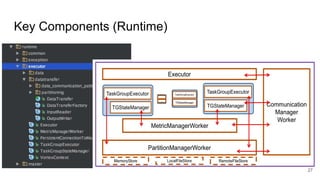


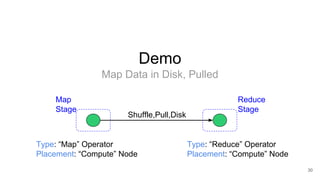





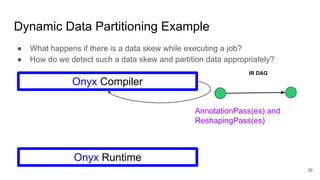
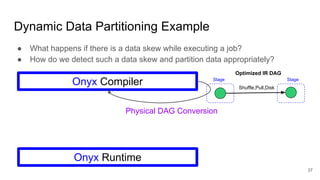




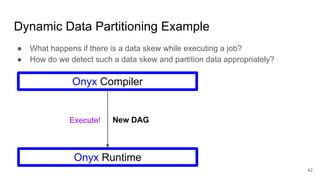







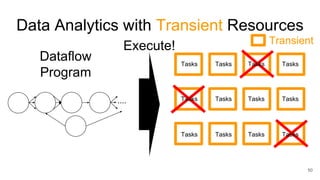


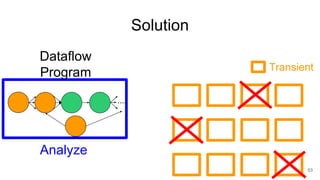
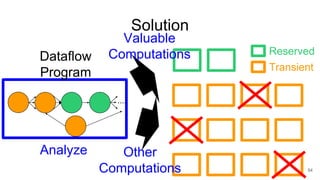
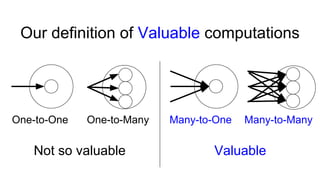
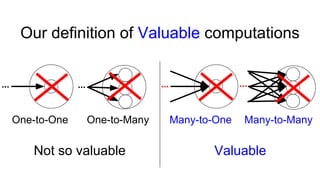

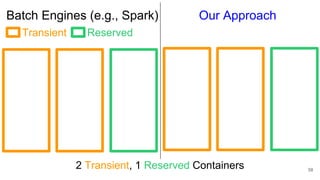
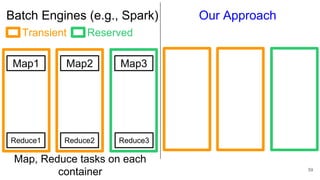



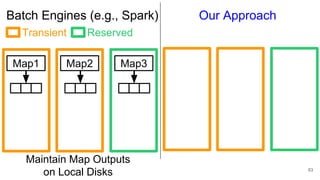
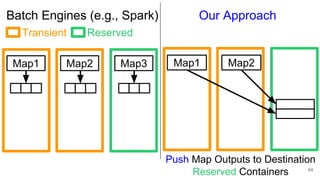



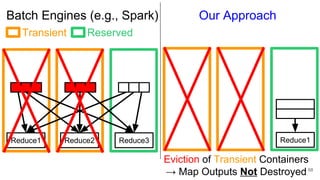
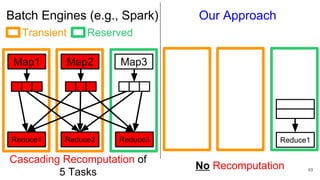


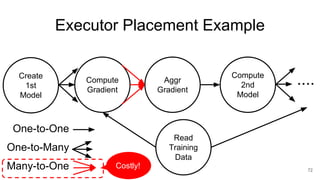
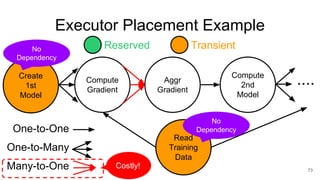
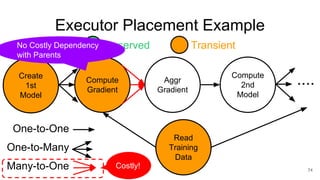



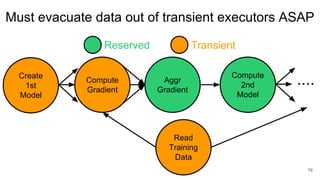
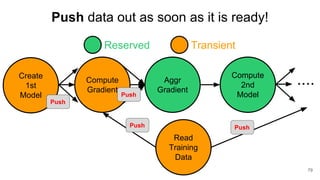
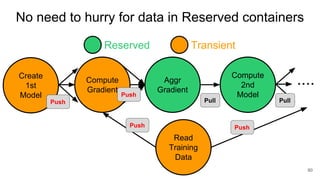


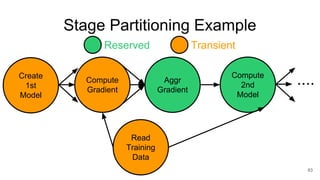







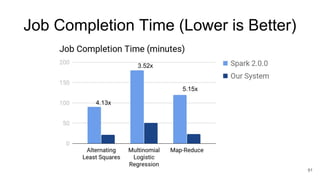




The document describes Onyx, a new flexible and extensible data processing system. It discusses limitations of existing frameworks in new resource environments like resource disaggregation and transient resources. The Onyx architecture includes a compiler that transforms dataflow programs into optimized physical execution plans using passes, and a runtime that executes the plans across cluster resources. It provides examples of compiling and running MapReduce and ALS jobs, and handling dynamic data skew through runtime optimization.
![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2C5]Map-D: A GPU Database for Interactive Big Data Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/2c5map-dagpudatabaseforinteractivebigdataanalytics-140930010539-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[253] apache ni fi](https://cdn.slidesharecdn.com/ss_thumbnails/235apachenifi-150915053924-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[오픈소스컨설팅]클라우드기반U2L마이그레이션 전략 및 고려사항](https://cdn.slidesharecdn.com/ss_thumbnails/u2l-171114134117-thumbnail.jpg?width=640&height=640&fit=bounds)
![[142] 생체 이해에 기반한 로봇 – 고성능 로봇에게 인간의 유연함과 안전성 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/142-171016082840-thumbnail.jpg?width=640&height=640&fit=bounds)

![[242]open stack neutron dataplane 구현](https://cdn.slidesharecdn.com/ss_thumbnails/242openstackneutron-dataplane-171017004554-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]streetwise machine learning for painless parking](https://cdn.slidesharecdn.com/ss_thumbnails/215streetwisemachinelearningforpainlessparking-171017050417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)
![[221]똑똑한 인공지능 dj 비서 clova music](https://cdn.slidesharecdn.com/ss_thumbnails/221djclovamusic-171016101800-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213]building ai to recreate our visual world](https://cdn.slidesharecdn.com/ss_thumbnails/213buildingaitorecreateourvisualworld-171017023224-thumbnail.jpg?width=640&height=640&fit=bounds)
![[246]reasoning, attention and memory toward differentiable reasoning machines](https://cdn.slidesharecdn.com/ss_thumbnails/246reasoningattentionandmemory-towarddifferentiablereasoningmachines-171017054258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)

![[213] 의료 ai를 위해 세상에 없는 양질의 data 만드는 도구 제작하기](https://cdn.slidesharecdn.com/ss_thumbnails/213aidata-171016104902-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232]mist 고성능 iot 스트림 처리 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/232mist-iot-171017012717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)



















