백억 개의 로그를모아
검색하고 분석하고 학습도 시켜보자: 로기스
현동석 / 김광림 / 양은숙
Naver Search
NAVER
LOGISS
Log gathering system for search, analysis, and machine learning.
2.
이런 얘기를 하겠습니다.
1.Problems and solutions
• 로그를 모을 수 없어 발생하는 문제
• 이를 해결하기 위해 LOGISS 설계하며 고민했던 내용
2. Lesson learned
• 빅데이터 로그 인덱싱을 위한 시스템 튜닝
• 점진적 규모 확장과 장애처리를 위한 관리 자동화
• 무중단 롤링 업그레이드 경험으로 얻은 노하우
3. Applications
• LogFlow 문제 추적을 위한 로그 트레이싱
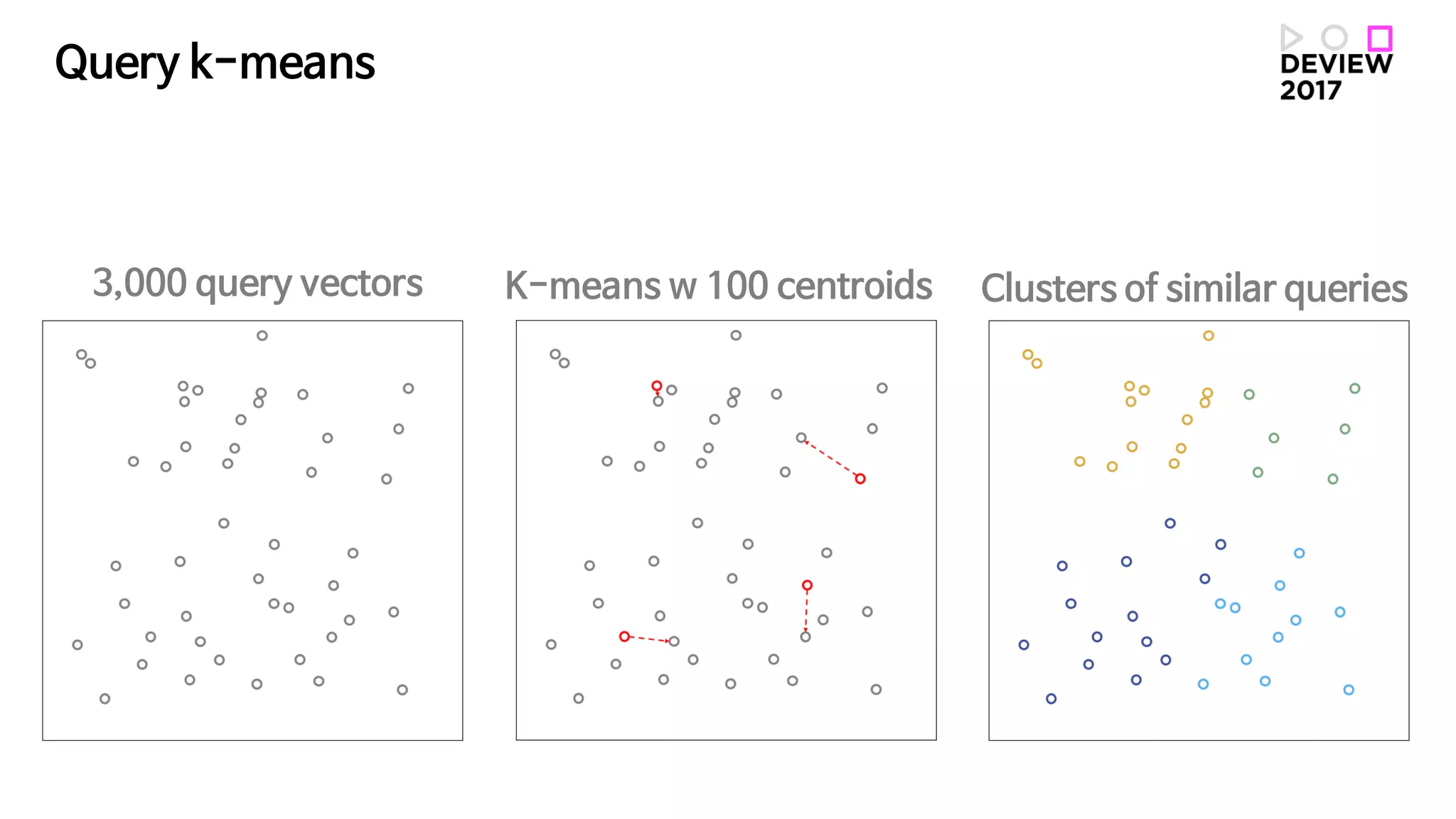
• Query k-means Word2vec 임베딩을 사용한 질의어 클러스터링
• HawkSee 로그에서 추출한 시퀀스를 사용한 RNN 자동 완성
4. Closing
매일 수십억 건의로그가 수천 수만대의 장비에 만들어짐
로그 하나 보려면 수십 대의 장비에 수백 기가의 로그 파일을 뒤져야 함
문제1: A needle in a haystack
도커 컨테이너 재시작하면 로그는?
볼륨 디렉토리? 같은 장비에 컨테이너가 뜰까?
볼륨 컨테이너? 장비간 로그 전송 트래픽은?
문제2: Log is volatile
어떤 시스템의 어떤 서버가 어떤 요청을 처리하다 남긴 로그인가
IP has not enough information for trouble-shooting.
문제3: Originality problem
5.
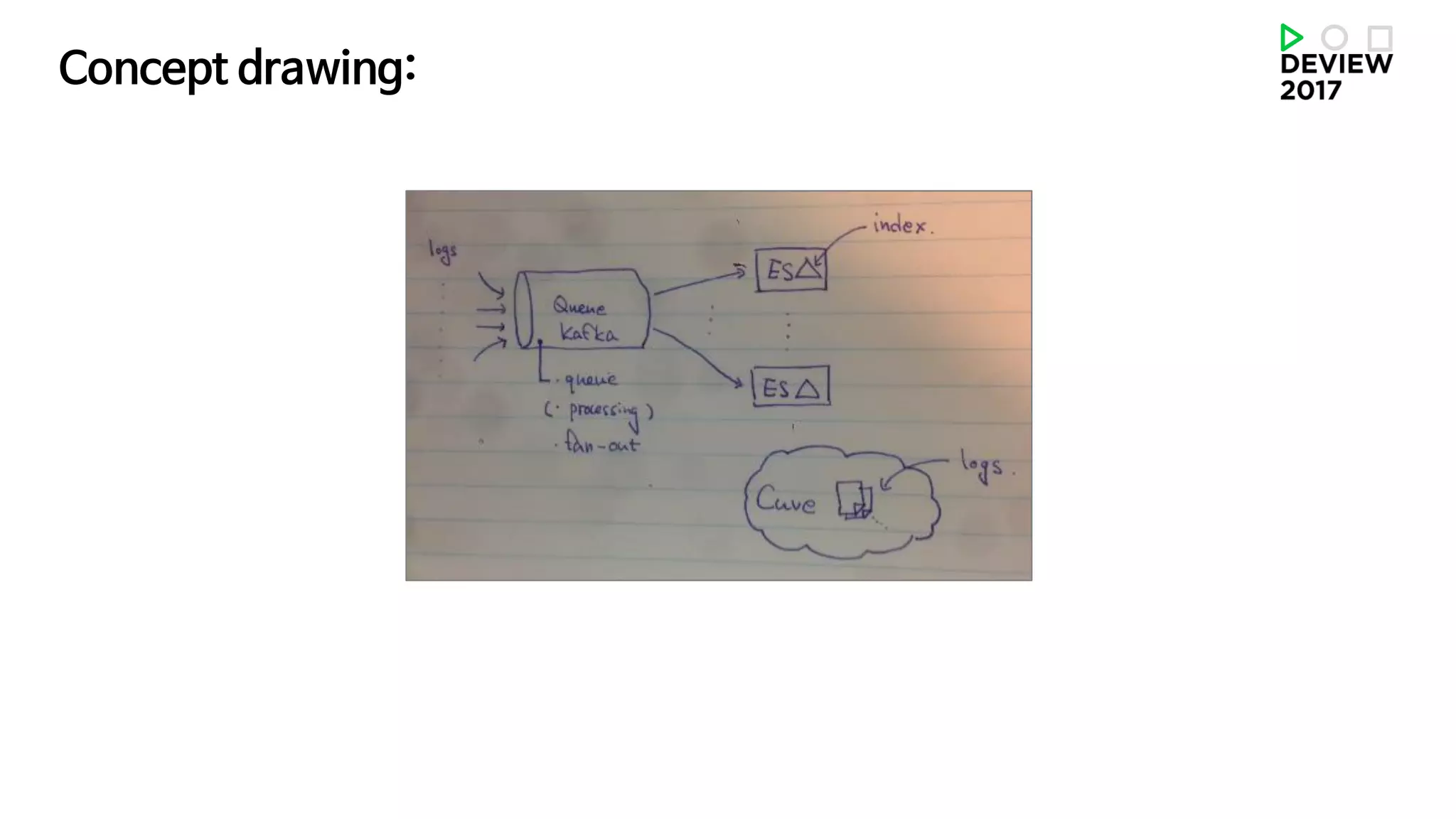
해결1,2: 로그 검색기능 제공
많은 문서(로그)에서 특정 조건에 맞는 문서(로그)를 찾는 문제
= 검색을 제공하여 해결. 어떤 검색 엔진을 써야할까?
해결3: 로그 헤더 포맷을 정의
언제 어떤 시스템의 Custom 어떤 서버가 어떤 시스템의 Custom 어떤 서버로 보낸 어떤 포맷의 로그 내용
Sender Logger
1 12341234
12.123
naver Custom front-end blog Custom search-application accesslog [2017/09/17 11:22:33.456
+0900] GET
1 12341234
12.123
naver hostname front-end blog Container-
hash,misc-
info
search-application accesslog [2017/09/17 11:22:33.456
+0900] GET
Log header
6.
ES를 도입한 다른사례를 살펴보니, 사용 시나리오에 맞는 시스템을 제공해야 함을 발견!
• Elastic search
• 로그 브라우저 제공 > 문제 추적, 데이터 가시화
• ES API 제공 > 사용자 대시보드, 알림 시스템 구현, 딥러닝 등의 프로토타이핑
• 사내 분산 저장시스템 Cuve[큐브]에 넣어 제공(HBase)
• Production level big data processing.
• Long running ML training with big data.
해결+: 사용 시나리오에 맞는 시스템을 제공하자
Multiplexer
(Kafka)
For search,
prototyping
For big data
processing
ELK
Cuve (Hbase)
Aggregator
KafCuve
Design: #4
Docker out.
WholeELK stack
Monitoring tools
Dashboards
Beats
…
대량의 데이터를 물고 뜨는 서버에 대한 컨테이너라이징에 대한 고민은 충분히 하지 않음. 방법은 있을 것 같은
데 운영 비용까지 고려해서 사용할 만한지, 노드 리플리케이션에 비해 경쟁력이 있는 지는 충분한 고민이 필요.
(이 부분은 의견을 듣고 싶습니다 ^^)
Logs from thesame system go to the same index
로그 헤더 적용은 쉽지 않았지만 해놓으니 이렇게 깔끔했습니다.
14.
Users load theirlogs into HDFS using a single command
$ HADOOP_USER_NAME=<USERNAME> $HADOOP_COMMON_HOME/bin/hadoop --config $C3_CONF_DIR jar
target/CuveC3-1.0-SNAPSHOT.jar <SSUID> <ROLE> <FROM_TIME> <TO_TIME> <HDFS_OUTPUT_PATH>
TIP. 쌓아놓은 로그의 접근성을 좋게 하기 위해 MR 탬플릿을 만들어 제공했더니,
- 추천 등의 데이터 분석작업에서 활용하기 편해졌습니다.
- 동시에 ES에 무리한 질의를 던지지 않는 효과도 있습니다.
15.
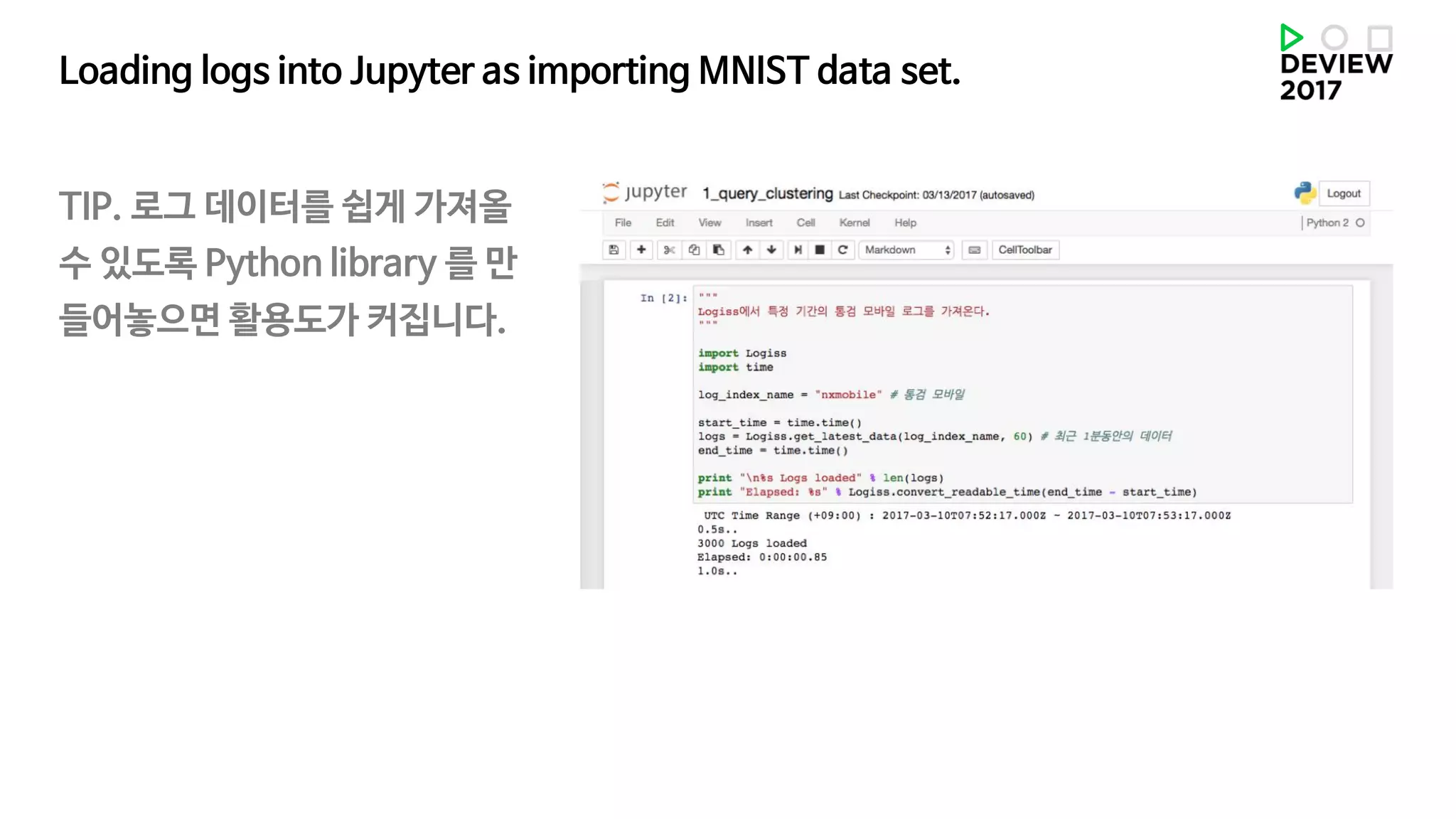
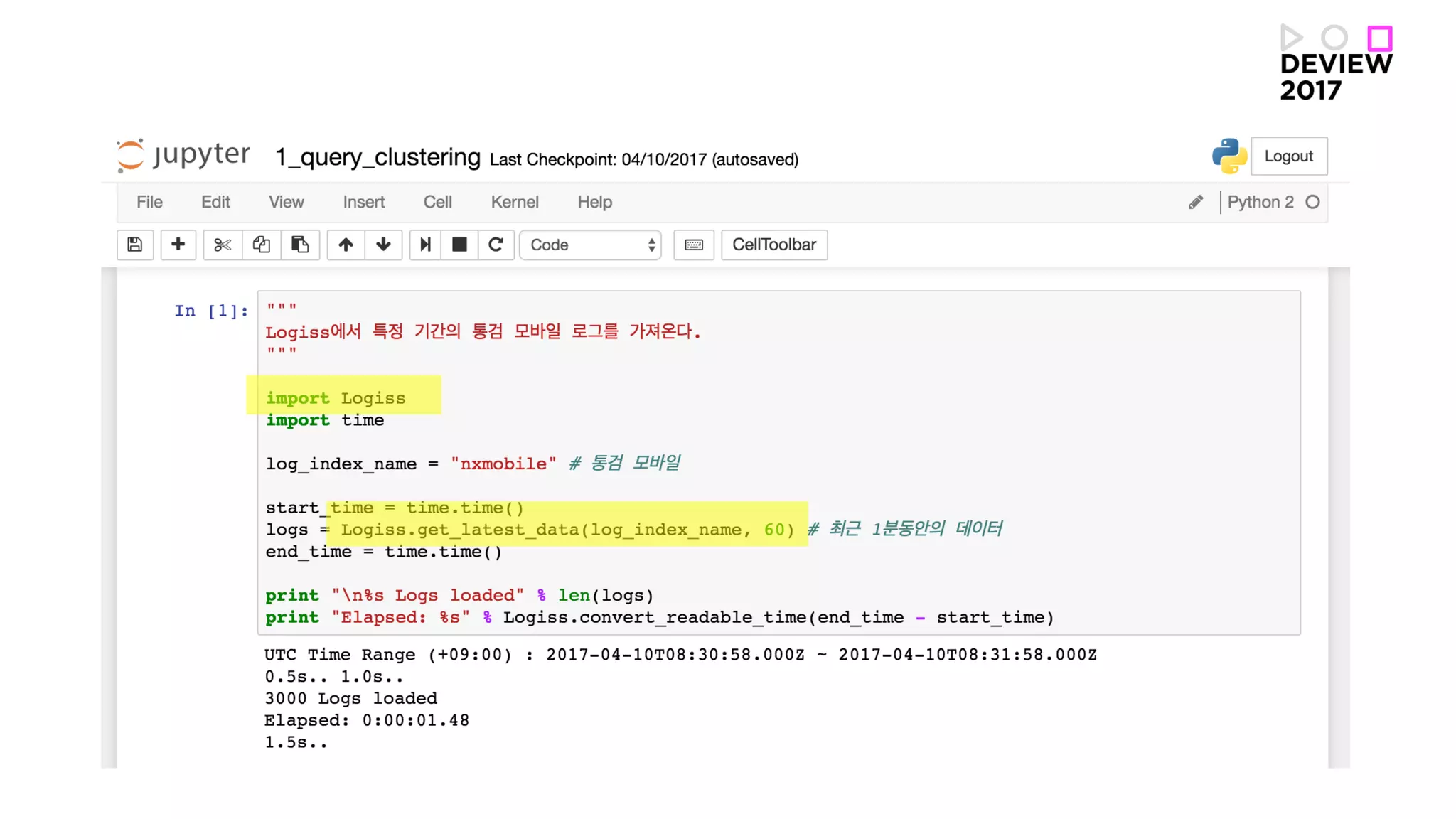
Loading logs intoJupyter as importing MNIST data set.
TIP. 로그 데이터를 쉽게 가져올
수 있도록 Python library 를 만
들어놓으면 활용도가 커집니다.
16.
Security
로그의 접근 제한을고민했습니다.
Searchguard 쓰려면,.
- (지금은 안쓰지만) x-pack과 충돌
- SSL 오버헤드 감수(로기스는 초당 5만건 이상이
라 오버헤드가 있습니다)
- Curator, ansible, haproxy, prometheus 등
에 ssl 설정 해주고 인증서 작업 진행
- 이 것 외에도 권한/인증 운영 부담
- 모든 걸 감수하고 운영까지 검증하신 분 있다면
공유 부탁드려요
그냥 개인 정보를 미리 삭제 했습니다.
OAuth2 사내 인증을 적용했습니다.
Hbase의 경우 Cuve의 티켓 권한 관
리 기능을 활용했습니다.
배운점 하나 |docker가 만능은 아니다. (docker 탈출기)
배운점 둘 | 튜닝은 끝나지 않는다.
빅데이터 로그 인덱싱을 위한 시스템 튜닝
19.
Docker 너만 믿었건만…
빅데이터로그 인덱싱을 위한 시스템 튜닝
처음에는 (당연히)
Docker 사용
Docker Swarm 으로
관리도 편하게 해 볼까?
대용량 데이터 들어오면서 문제 발생!
Elasticsearch
롤링 업그레이드 시 data loss
컨테이너별 업데이트시
’아주’ 충분한 시간 두고 띄우자
: 비효율
색인을 컨테이너 바깥에 두면?
: 그러면 굳이 swarm을 쓸 필요가?
수동으로 컨테이너팜 관리… 잘 할 수 있겠니?
다시 Swarm을 걷어내고 container로만 쓴다면?
그럼 Docker를 쓸 필요가 있을까?
Ansible로 충분히 운영가능함.
우리가 주력으로 써야 하는
Elasticsearch, Kafka 는 이미
분산처리가 기본으로 잘 되어 있다.
서버 튜닝할 때 컨테이너라서 어려운 것도 많은데…
대규모 트래픽을 받지만 scale-out 이 빈번하게 일어나지는 않는다.
Docker… Swarm… 너 정말 필요하겠니?
색인 데이터 컨테이너 안에 두고
docker service update
: 데이터 유실 위험
성능 튜닝 -다들 하고 계시는 것, 그것입니다.
빅데이터 로그 인덱싱을 위한 시스템 튜닝
Elasticsearch
• JVM swap 방지 : memlock unlimited, vm.swappiness, vm.max_map_count,
bootstrap.memory_lock
• file descriptor 최대값: nofile, noproc
• elasticsearch thread pool 옵션 살펴보기: bulk, bulk_queue size 늘리기 등
• SSD 이용한다면 성능 올릴 수 있는 옵션 설정:
indices.store.throttle.max_bytes_per_sec
• 샤드, 인덱스 밸런스 맞추기 위해 계산 잘 하기
• 색인 크기가 너무 커서 성능이 떨어지지 않도록 하기(<10GB). 너무 크면 shard
allocation 에도 문제가 생긴다.
• index merge를 줄이기위한 노력 필요: index.refresh_interval
• OOM 방지를 위한 index 관련 설정: indices.fielddata.cache.size,
indices.breaker.total.limit, indices.breaker.fielddata.limit,
indices.breaker.request.limit, network.breaker.inflight_requests.limit
Logstash
• I/O 를 실제로 지켜보면서 튜닝하는 것이 필요: heap_size, pipeline.workers,
pipeline.output.workers, pipeline.batch.size, kafka_consumer_threads
• grok filter 성능 이슈: 아주 편리하지만 너무 많은 rule이 들어가면 병목이 될 수 있음.
현재진행중인 고민
• 대용량 데이터 유입 테스트 위해 dutchdrop filter 만들기
Kibana
• custom plugin 만들때 주의할 사항들 있음: upgrade, 다른 plugin과 충돌
Kafka
• 의도치않게 장비가 종종 죽는 문제: 커널업으로 해결
AS-IS: CentOS 7.2.1511 (Core) 3.10.0-327.36.2.el7.x86_64
TO-BE : CentOS 7.3.1611 (Core) 3.10.0-514.21.1.el7.x86_64
22.
성능 튜닝 -우리 시스템 성능 개선만 하면 ok? 당연히 아닙니다.
연동되어 있는 곳이 많은데 큰 데이터를 다룬다면?
• 전송 횟수 줄이려 log aggregation 해서 데이터 저장소에 보냈더니
그곳에서는 폭탄. (결국 10M -> 512k 로 줄여서 전송)
• 혼자만 잘 살 수 없음. 우리도 전체 시스템의 일부일 뿐…
전체의 밸런스를 위해 우리 성능을 (어느정도) 희생할 필요도
한계 용량보다 더 많은 로그가 들어온다면?
• Logstash throttling 으로 버틸 수 있지만 worker thread 간 counter 동기화로 성능 저하
빅데이터 로그 인덱싱을 위한 시스템 튜닝
어디서나 중요한 것은 밸런스, 밸런스, 밸런스 !
23.
성능 튜닝 -여전히 진행중입니다.
초기의 구성의 물리적 변화는 최소화하며 처리 용량 늘리고 있음.
마른 걸레 쥐어짜기
빅데이터 로그 인덱싱을 위한 시스템 튜닝
24.
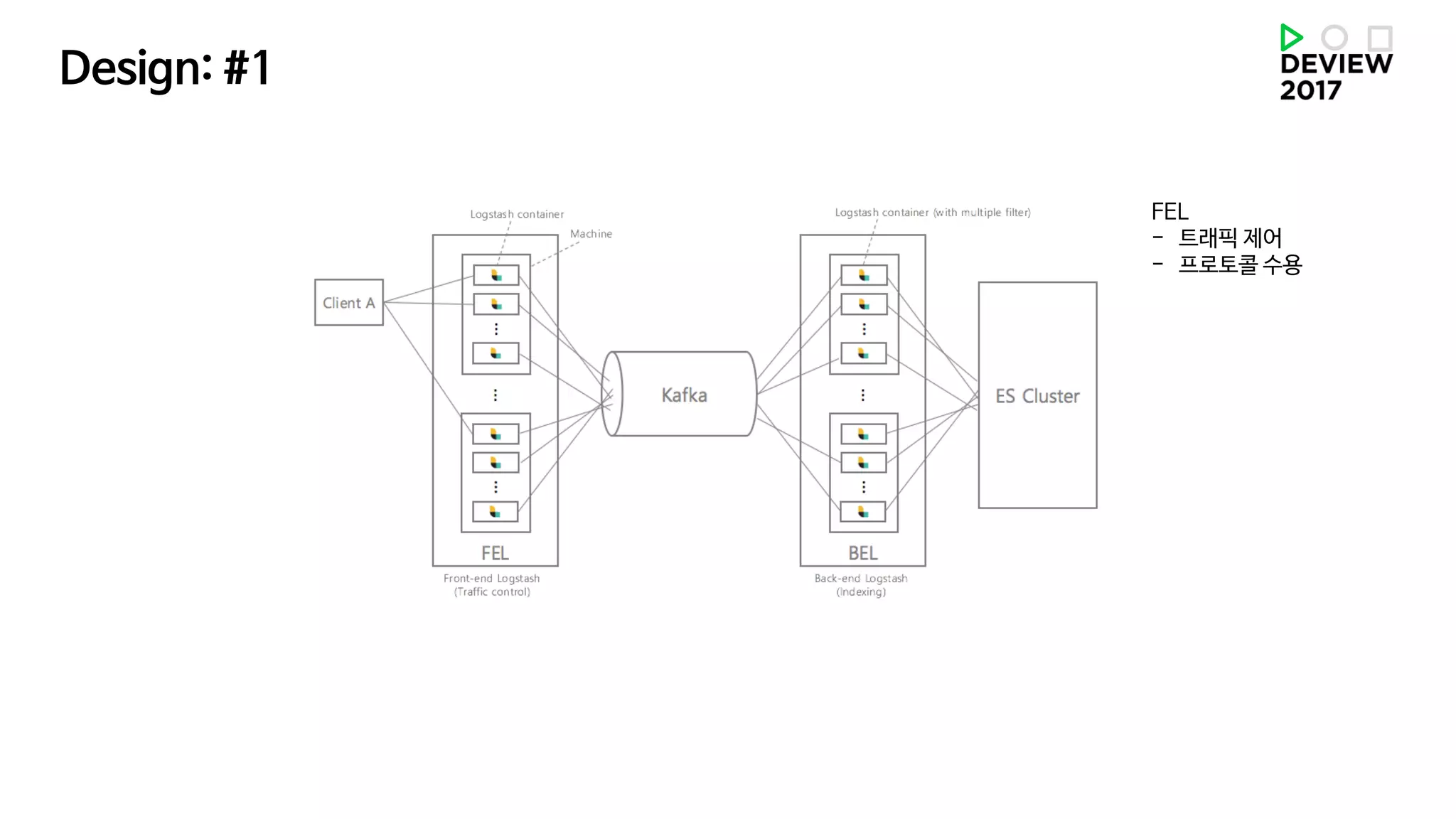
첫번째 | 복잡한시스템에서 Ansible 효과적으로 쓰기 위한 작업들
두번째 | Monitoring – 장애처리 + 성능튜닝을 동시에 하자.
점진적 규모 확장과 장애 처리를 위한 관리 자동화
25.
Ansible https://www.ansible.com/
점진적 규모확장과 장애 처리를 위한 관리 자동화
Role
Sub system 마다 Role 부여
• Role 하나에는 다음 파일들이 있음
- 작업 실행을 위한
ansible-playbook 파일 (yml)
- 변수 치환하여 사용가능한 설정파일
들 (conf, properfies 등)
• 손쉬운 구조화를 위해 Ansible의 표준
디렉토리 구성을 따름
• Tasks 디렉토리 안에는
제일 기본이 되는 main.yml외에도
필요한 작업을 설정해 둠
Inventory
Dev/Staging/Production 별
Inventory로 관리
• 동일한 작업을 inventory만 다르게 지
정하여 손쉽게 수행 가능
• Inventory별로 변수 지정을 다르게 하
여 테스트, 외부시스템 연동에 자유도
를 높일 수 있다.
• 주의점: variable 선언시 Ansible의
우선순위가 있음.
- inventory에서 재정의하여 쓸 수 없
는 것도 있음: roles/xxx/vars,
include_vars, registered vars
- inventory defined vars 는 우선순
위가 낮은 편이므로 yml 작성시 주의
Ansible 표준
Directory 구조
Role
Inventory 이름
26.
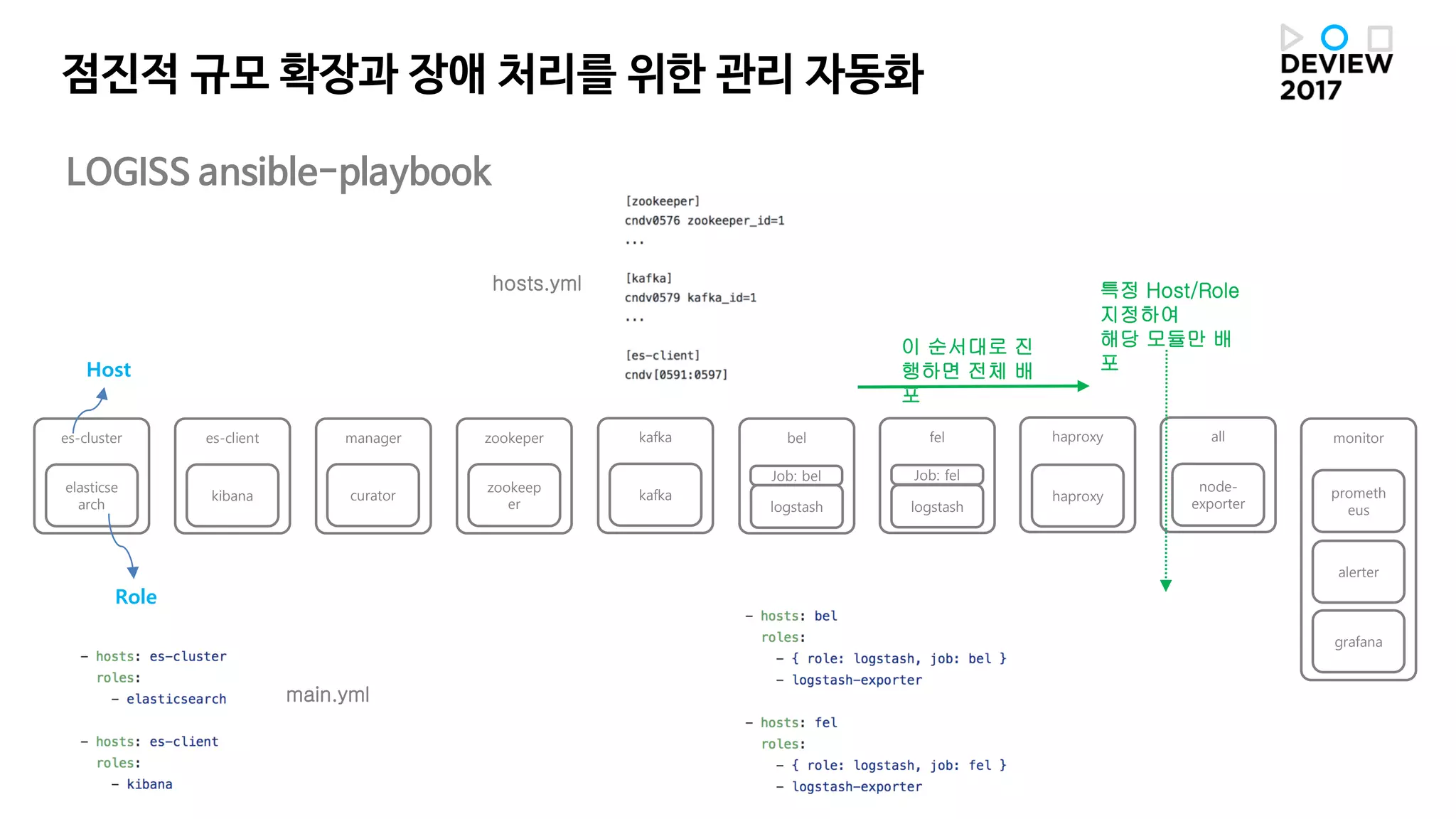
점진적 규모 확장과장애 처리를 위한 관리 자동화
elasticse
arch
es-cluster
kibana
es-client
curator
manager
zookeep
er
zookeper
kafka
kafka
logstash
bel
logstash
fel
haproxy
haproxy
node-
exporter
all
prometh
eus
alerter
grafana
monitor
LOGISS ansible-playbook
Host
Role
Job: bel Job: fel
hosts.yml
main.yml
이 순서대로 진
행하면 전체 배
포
특정 Host/Role
지정하여
해당 모듈만 배
포
27.
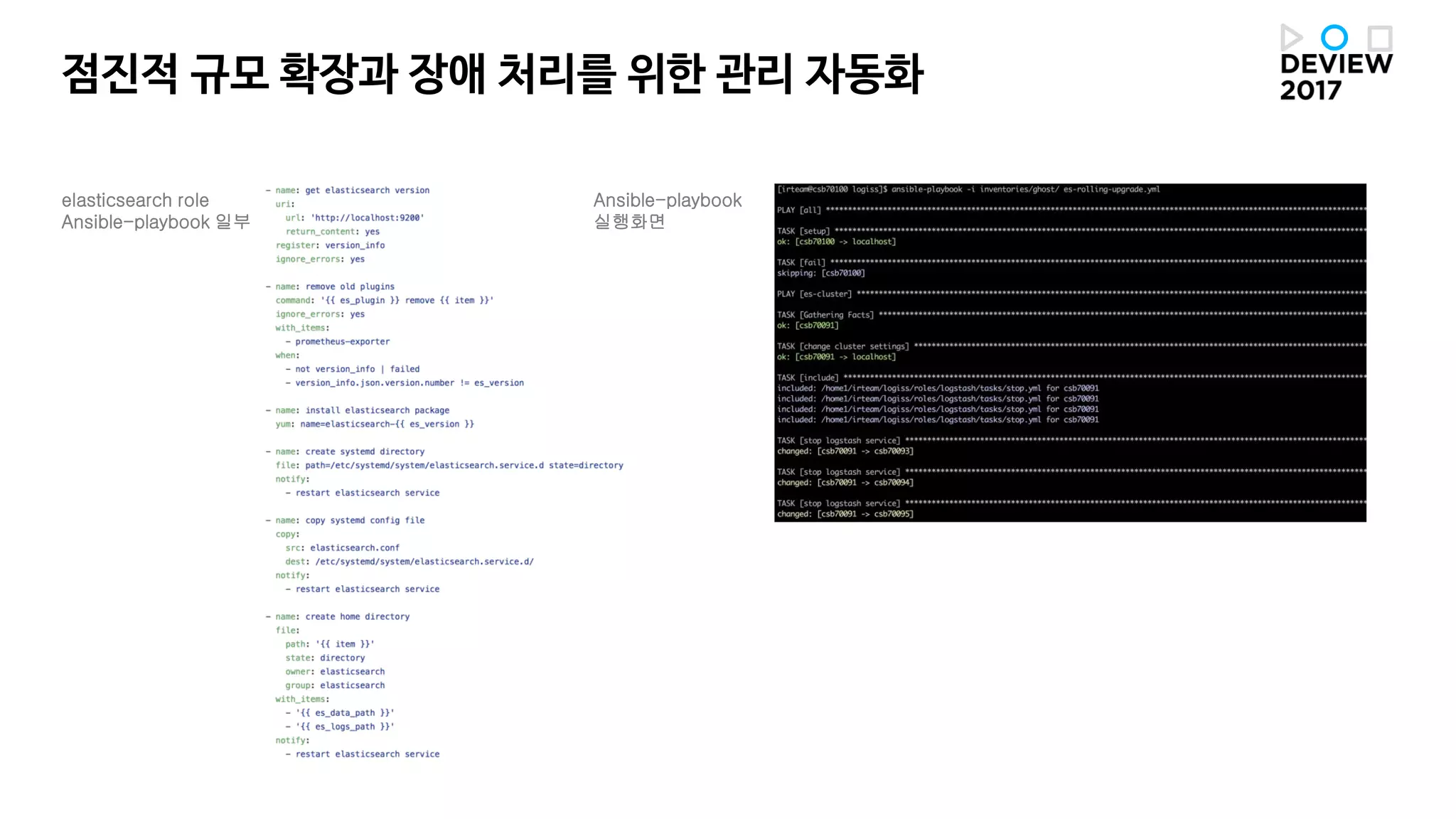
점진적 규모 확장과장애 처리를 위한 관리 자동화
elasticsearch role
Ansible-playbook 일부
Ansible-playbook
실행화면
28.
시스템이 복잡할수록 Ansible이유용합니다.
내부 시스템/모듈과 다양한 opensources 모두 잘 엮어서
ansible-playbook 을 시나리오별로 만들어 사용
(ex: site.yml, es-rolling-upgrade.yml, es-full-restart.yml, kafka-partition.yml …)
ansible-vault : 파일 암호화가 필요한 경우 유용 (공개 github repo 에 올릴때)
처음 설정할때는 힘들지만, 이후 시스템 확장/변경 될 때는 대응하기 (아주) 편리합니다.
Dockerfile 만들때 느낌…?
점진적 규모 확장과 장애 처리를 위한 관리 자동화
첫번째 | ElasticsearchRolling upgrades
두번째 | Logiss는 이렇게 자주 버전을 올리나요?
세번째 | 롤링 업그레이드는 어떻게 하나요?
무중단 롤링 업그레이드 경험으로 얻은 노하우
31.
Elasticsearch Rolling upgrades
롤링업그레이드란?
Elasticsearch 클러스터에 { }버전 업그레이드를 하는 것입니다.
언제 하나요?
• 무중단 서비스 제공이 필요할 때 유용합니다.
• Elasticsearch 마이너 버전 업그레이드에만 가능합니다. (5.x => 5.y)
• 5.6.0 => 6.x 업그레이드는 가능!
무중단 롤링 업그레이드 경험으로 얻은 노하우
다운타임 없이
노드 하나씩
32.
로기스는 가능한 Elasticstack 최신 버전을 유지하려고 합니다.
(자주) 버전업하는 이유는,
bug fix, 최신 기능등을 빠르게 적용
시스템을 건전한 상태로 유지하기에 좋은 방법
기술 부채, 업그레이드 부채
(운영) 자신감도 조금씩 업그레이드
실제로 5.x 에서는 롤링 업그레이드가 수월합니다.
무중단 롤링 업그레이드 경험으로 얻은 노하우
2/6 3/14 3/31 4/26 5/1 5/10 6/9 6/23 7/7 7/29 8/26 9/16
5.0.1LOGISS
Upgrade
Timeline
Cases
• 5.6.0 적용: Logstash throughput 약 40% up
• 5.4.0 적용: Logstash persistent queues 사용하여 data 유실 최소화
• 5.3.0 적용:
- Elasticsearch 의 multi data path 버그 해결
- Logstash 에서 age filter 적용
• Lucene 버전이 꾸준히 올라가면서 Elasticsearch 색인 성능 조금씩 개선됨
{
9/23
33.
롤링 업그레이드는 어떻게하나요? – 한번에 노드 하나씩!
무중단 롤링 업그레이드 경험으로 얻은 노하우
순차적으로 하나씩
업그레이드
샤드 할당 활성화
색인 재개
클러스터 상태확인
Elasticsearch Cluster
색인 중단
노드 재시작
Node 1
(master)
Node 2
(master)
Node 3
(Ingest)
Node 4
(Data)
Node 5
(Data)
Node K
(Data)
…
롤링 업그레이드
Timeline
synced flush
노드 하나에서
작업 시작
작업완료 후
다음 노드에
적용전까지 대기
Ver. 5.5.2 Ver. 5.6.0
Logstash
Logstash (BEL)
색인 중단시
유입 차단
샤드 할당 비활성
34.
롤링 업그레이드는 어떻게하나요? – LOGISS에서 실제 작업과정
무중단 롤링 업그레이드 경험으로 얻은 노하우
동영상 예정
LogFlow: 문제 추적을위한 로그 트레이싱
Distributed Tracing System
• Google – Dapper
• Facebook – The Mystery Machine
• Zipkin http://zipkin.io/
• Opentracing http://opentracing.io/
38.
LogFlow: 문제 추적을위한 로그 트레이싱
Logiss 로그 포맷 – sender, logger
trace_id
trace_id
trace_id
Logiss 로그 포맷 로그본문에
Trace ID 추가
Trace ID 로 특정 request 에 응답한 모든 서버 로그를 묶은다음,
sender, logger 정보 이용하여 부모/전후관계를 엮으면?
Distributed queue
- Traffichandling
- Data channeling
- Buffering for system recovery
Throttling / filtering
Parsing,securingpriv.dataParsing,securingpriv.data,aggregation
API
API
Cuve: Dist. Storage Platform
Group by time
Groupbyserviceandroles
Realtime indexing
Long term storage
.lib.lib
C3 DL
Deep Learning Pl
atform
Trouble-shooting Event visualization
Logiss
Unified log format
Timeline viewer
Machine learning
research & application
NAVER Search Logs & Content
s
60.
References
• Elasticsearch innetflix
https://www.slideshare.net/g9yuayon/elasticsearch-in-netflix
• Deploying and scaling Logstash
https://www.elastic.co/guide/en/logstash/current/deploying-and-scaling.html
• Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
https://research.google.com/pubs/pub36356.html
• The Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-chow.pdf
• Zipkin
http://zipkin.io/
• Opentracing
http://opentracing.io/





![해결1,2: 로그 검색 기능 제공
많은 문서(로그)에서 특정 조건에 맞는 문서(로그)를 찾는 문제
= 검색을 제공하여 해결. 어떤 검색 엔진을 써야할까?
해결3: 로그 헤더 포맷을 정의
언제 어떤 시스템의 Custom 어떤 서버가 어떤 시스템의 Custom 어떤 서버로 보낸 어떤 포맷의 로그 내용
Sender Logger
1 12341234
12.123
naver Custom front-end blog Custom search-application accesslog [2017/09/17 11:22:33.456
+0900] GET
1 12341234
12.123
naver hostname front-end blog Container-
hash,misc-
info
search-application accesslog [2017/09/17 11:22:33.456
+0900] GET
Log header](https://image.slidesharecdn.com/deview2017logissv1-171017061012/75/slide-5-2048.jpg)
![ES를 도입한 다른 사례를 살펴보니, 사용 시나리오에 맞는 시스템을 제공해야 함을 발견!
• Elastic search
• 로그 브라우저 제공 > 문제 추적, 데이터 가시화
• ES API 제공 > 사용자 대시보드, 알림 시스템 구현, 딥러닝 등의 프로토타이핑
• 사내 분산 저장시스템 Cuve[큐브]에 넣어 제공(HBase)
• Production level big data processing.
• Long running ML training with big data.
해결+: 사용 시나리오에 맞는 시스템을 제공하자
Multiplexer
(Kafka)
For search,
prototyping
For big data
processing
ELK
Cuve (Hbase)
Aggregator
KafCuve](https://image.slidesharecdn.com/deview2017logissv1-171017061012/75/slide-6-2048.jpg)
















































![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)


![[KAIST 채용설명회] 데이터 엔지니어는 무슨 일을 하나요?](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=640&height=640&fit=bounds)














![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)

![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)

![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]open stack neutron dataplane 구현](https://cdn.slidesharecdn.com/ss_thumbnails/242openstackneutron-dataplane-171017004554-thumbnail.jpg?width=640&height=640&fit=bounds)
![[141]네이버랩스의 로보틱스 연구 소개](https://cdn.slidesharecdn.com/ss_thumbnails/41-171015225628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] 의료 ai를 위해 세상에 없는 양질의 data 만드는 도구 제작하기](https://cdn.slidesharecdn.com/ss_thumbnails/213aidata-171016104902-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)
![[246]reasoning, attention and memory toward differentiable reasoning machines](https://cdn.slidesharecdn.com/ss_thumbnails/246reasoningattentionandmemory-towarddifferentiablereasoningmachines-171017054258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[221]똑똑한 인공지능 dj 비서 clova music](https://cdn.slidesharecdn.com/ss_thumbnails/221djclovamusic-171016101800-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232]mist 고성능 iot 스트림 처리 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/232mist-iot-171017012717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]streetwise machine learning for painless parking](https://cdn.slidesharecdn.com/ss_thumbnails/215streetwisemachinelearningforpainlessparking-171017050417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213]building ai to recreate our visual world](https://cdn.slidesharecdn.com/ss_thumbnails/213buildingaitorecreateourvisualworld-171017023224-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra02-190131073314-thumbnail.jpg?width=640&height=640&fit=bounds)










![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)