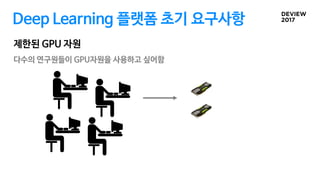
Deep Learning 플랫폼초기 요구사항
Caffe, TensorFlow, Theano, Torch
Deep Learning Frameworks
6.
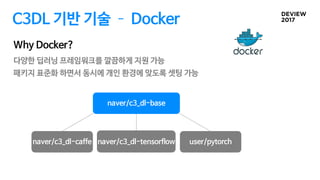
C3DL 기반 기술 Docker
다양한 딥러닝 프레임워크를 깔끔하게 지원 가능
패키지 표준화 하면서 동시에 개인 환경에 맞도록 셋팅 가능
Why Docker?
naver/c3_dl-caffe naver/c3_dl-tensorflow user/pytorch
naver/c3_dl-base
7.
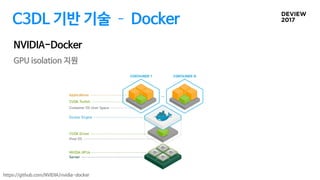
C3DL 기반 기술 Docker
GPU isolation 지원
NVIDIA-Docker
https://github.com/NVIDIA/nvidia-docker
8.
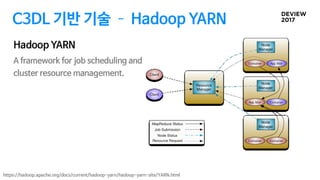
C3DL 기반 기술 Hadoop YARN
A framework for job scheduling and
cluster resource management.
Hadoop YARN
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
새로운 요구사항
Distributed inference
-training이 완료된 모델로 inference를 하고 싶다.
- 배치 작업, 오래 걸리는 작업들은 2~3개월 필요
사례: 웹 이미지 adult test
Distributed inference
를 구현했는데,
GPU할당만 해주면 돌릴께요
13.
새로운 요구사항
Distributed training
-여러 장비에서 GPU할당 받아서 training을 하고 싶다
- 사실상 Distributed tensorflow 사용하고 싶다는 문의
Distributed tensorflow
사용하고 싶어요
14.
새로운 요구사항
Serving (longlive)
웹서버를 실행해서 request, response 방식으로 처리
1000시간 넘게 실행하고 있네??
서버를 계속 실행해두면 되겠군.
15.
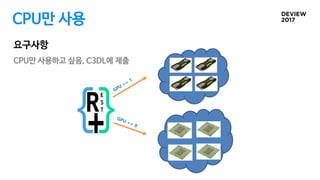
새로운 요구사항
CPU만 사용해서실행
- training이 끝난 모델을 사용해서 inference만 하고 싶은데, CPU가 가성비가 더 좋은 경
우가 있음.
- 단, 기존 C3DL와 같은 방식으로 사용하고 싶다.
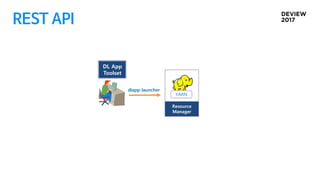
DL
Application
16.
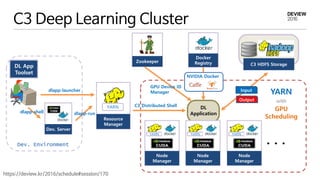
Distributed Deep Learning솔루션 검토
Tensorflow on Spark - https://github.com/yahoo/TensorFlowOnSpark
DSSTNE - https://github.com/amzn/amazon-dsstne
Caffe on Spark - https://github.com/yahoo/CaffeOnSpark
Deeplearning4j on spark - https://deeplearning4j.org/spark
torch-distlearn - https://github.com/twitter/torch-distlearn
Distributed Keras - https://github.com/cerndb/dist-keras
Apache SINGA - http://www.comp.nus.edu.sg/~dbsystem/singa/
BigDL - https://github.com/intel-analytics/BigDL
Distributed Deep Learning 솔루션
17.
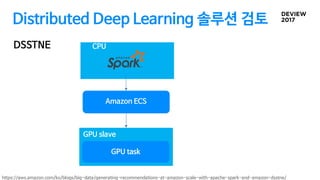
Distributed Deep Learning솔루션 검토
Tensorflow On Spark
http://yahoohadoop.tumblr.com/post/157196317141/open-sourcing-tensorflowonspark-distributed-deep
18.
Distributed Deep Learning솔루션 검토
DSSTNE
Amazon ECS
SparkAmazon ECS
GPU task
GPU slave
CPU
https://aws.amazon.com/ko/blogs/big-data/generating-recommendations-at-amazon-scale-with-apache-spark-and-amazon-dsstne/
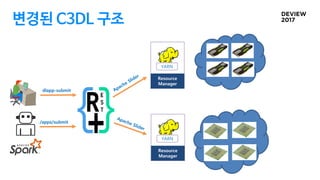
YARN application 변경
한개의JOB에 한개의 container만 실행
BATCH JOB이라고 가정하고 만들어져 있음
기존 C3DL
Distributed - 여러 container 동시 실행할때 장비 다운등 에러처리
Serving - Long-live JOB도 지원해야함
변경 & 구현 해야하는것
21.
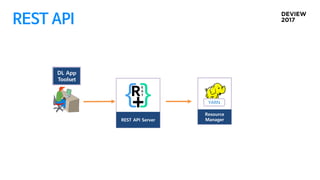
YARN application 개발
ResourceManager, Application Master, Node Manager, Container …
YARN API
예외 처리
Container가 죽었을때…, 장비가 다운되었을때..
예제 프로그램이 1000줄 이상…
Distributed Shell
22.
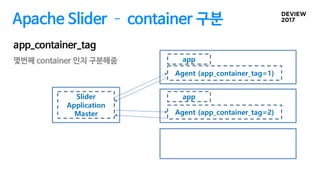
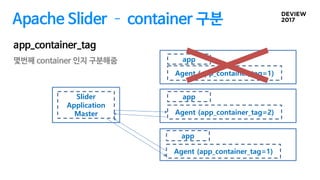
Apache Slider
Slider isa YARN application to deploy existing distributed
applications on YARN
https://deview.kr/2016/schedule#session/168
Apache Slider 를 이용한 멀티테넌트 하둡 클러스터
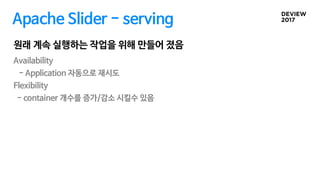
Apache Slider -serving
Availability
- Application 자동으로 재시도
Flexibility
- container 개수를 증가/감소 시킬수 있음
원래 계속 실행하는 작업을 위해 만들어 졌음
27.
Apache Slider contributor
https://issues.apache.org/jira/browse/SLIDER-1239
https://issues.apache.org/jira/browse/SLIDER-494
Batch 모드 개발
문서가 부족함
옆에 물어봄…
28.
Apache Slider contributor
https://issues.apache.org/jira/browse/SLIDER-1239
https://issues.apache.org/jira/browse/SLIDER-494
Batch 모드 개발
문서가 부족함
옆에 물어봄…
29.
Apache Slider contributor
https://issues.apache.org/jira/browse/SLIDER-1239
https://issues.apache.org/jira/browse/SLIDER-494
Batch 모드 개발
문서가 부족함
옆에 물어봄…
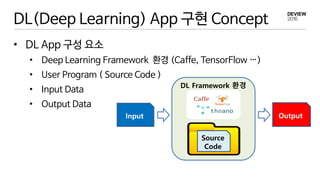
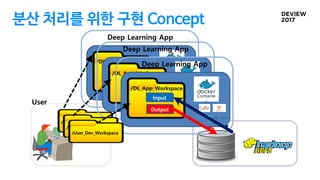
DL(Deep Learning) App구현 Concept
• DL App 구성 요소
• Deep Learning Framework 환경 (Caffe, TensorFlow …)
• User Program ( Source Code )
• Input Data
• Output Data
Input Output
DL Framework 환경
Source
Code
38.
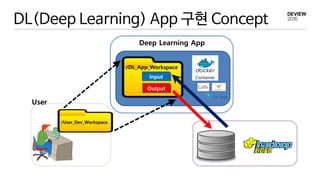
DL(Deep Learning) App구현 Concept
/User_Dev_Workspace
/DL_App_Workspace
Deep Learning App
Input
Output
User
Container
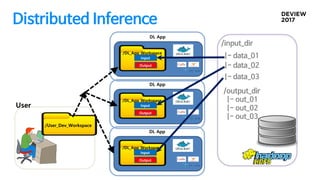
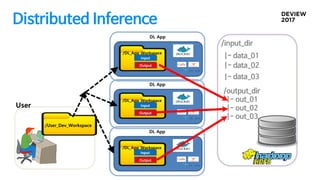
분산 처리를 위한구현 Concept
/User_Dev_Workspace
User
/DL_App_Workspace
Deep Learning App
Input
Output
Containe
r/DL_App_Workspace
Deep Learning App
Input
Output
Containe
r
/DL_App_Workspace
Deep Learning App
Input
Output
Containe
r
/User_Dev_Workspace
/User_Dev_Workspace
43.
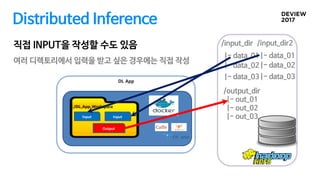
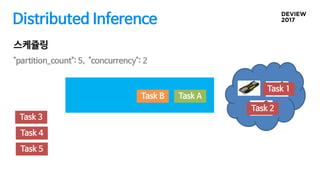
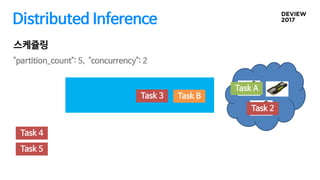
Distributed Inference
대용량 배치작업, 오래 걸리는 작업들은 2~3개월 필요
Map-reduce 처럼 input, output만 지정하면 자동으로 나누어졌으면 좋겠다
GPU자원이 남으면 최대한 사용하고 싶다
요구사항
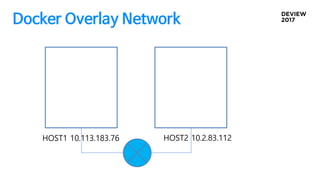
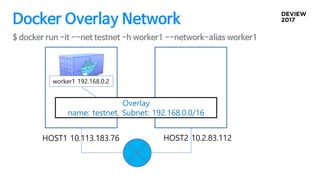
Docker Overlay Network설정 삽질..
Zookeeper 여러개 설정은 ‘,’ 를 사용해서
zk://zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:218
1
--cluster-store 설정
71.
Docker Overlay Network설정 삽질..
• --add-host --ip
• IP가 중복되면 안되서 IP관리가 필요함
• --link 옵션을
• --add-host와 비슷하게 동작하는데, deplicated 된 옵션
Docker 문서를 잘읽자
72.
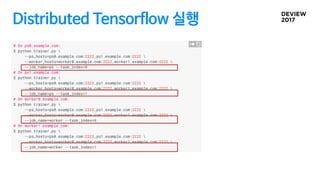
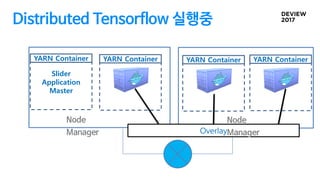
Distributed Tensorflow 삽질…
PS는자동 종료가 안되서 수동으로 종료해주어야함
SERVICE type으로 설정하면 다른 BATCH 작업 종료후에 종료
Parameter Server는 종료 안됨
인터넷에 있는 Distributed Tensorflow 예제를 실행해 볼때 버전 확인
Tensorflow 버전이 빠르게 변하기 때문에 예전 버전의 예제들도 있음
Tensorflow 예제 코드의 버전 확인
73.
Slider 개발 팁
stdout,stderr 출력 로그는 재시작할때마다 로그가 리셋됨.
{app_log_dir} 밑에 두는게 좋음
Log는 stdout, stderr 사용 안하는게 좋음
Install, start, stop, status는 모두 구현
status 무조건 0을 리턴하도록 구현해두어서 종료가 안되는 문제 있었음
74.
To Do
Resource Scheduling고도화
예약기능
짧은 시간동안 많은 GPU사용
성능 개선
Container 재활용
Tensorflow외에 다른 Distributed training 지원



















![Distributed API 설계 전략 - 자유도 높은 API
{
"username": "testuser",
"queue": "test",
"worker": {
"config": [
{
"sms": {
"employee_id": "kr00000"
},
"docker": {
"expose_tcp_port": [
6006
],
"workdir": "/root/c3_workspace",
"image": "naver/c3_dl-tensorflow",
"args": "",
"command": "./run.sh",
"registry": "dregistry.navercorp.com"
},
"user_package_uri": "hdfs://c3/user/c3dl_admin/user-package/testuser/20170918162225.651323.tar.gz",
"data": {
"to_hdfs": [
{](https://image.slidesharecdn.com/2251016final-171017052307/85/225-40-320.jpg)


![Distributed Inference example json
{ "partition_count": 12,
"data": {
"from_hdfs": [ {
"excludes": ["_complete"],
"type": "dironly",
"input_path": "data",
"hdfs": "/user/blog/blogdatal/2017"
}],
"to_hdfs": [ {
"hdfs": "/user/blog/prediction/2017/result-
{{ partition_num }}",
"output_path": "result",
"overwrite": false
}],
"auto_partition": true,
"format": "%2d"
}
}
{
"data_list": [
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/01",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-01",
"output_path": "result",
"overwrite": false }]
},
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/02",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-02",
"output_path": "result",
"overwrite": false}]
},
…](https://image.slidesharecdn.com/2251016final-171017052307/85/225-47-320.jpg)
![Distributed Inference example json
{ "partition_count": 12,
"data": {
"from_hdfs": [ {
"excludes": ["_complete"],
"type": "dironly",
"input_path": "data",
"hdfs": "/user/blog/blogdatal/2017"
}],
"to_hdfs": [ {
"hdfs": "/user/blog/prediction/2017/result-
{{ partition_num }}",
"output_path": "result",
"overwrite": false
}],
"auto_partition": true,
"format": "%2d"
}
}
{
"data_list": [
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/01",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-01",
"output_path": "result",
"overwrite": false }]
},
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/02",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-02",
"output_path": "result",
"overwrite": false}]
},
…](https://image.slidesharecdn.com/2251016final-171017052307/85/225-48-320.jpg)
![Distributed Inference example json
{ "partition_count": 12,
"data": {
"from_hdfs": [ {
"excludes": ["_complete"],
"type": "dironly",
"input_path": "data",
"hdfs": "/user/blog/blogdatal/2017"
}],
"to_hdfs": [ {
"hdfs": "/user/blog/prediction/2017/result-
{{ partition_num }}",
"output_path": "result",
"overwrite": false
}],
"auto_partition": true,
"format": "%2d"
}
}
{
"data_list": [
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/01",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-01",
"output_path": "result",
"overwrite": false }]
},
{
"from_hdfs": [{
"hdfs": "/user/blog/blogdata/2017/02",
"input_path": "data"}],
"to_hdfs": [{
"hdfs": "/user/blog/prediction/2017/result-02",
"output_path": "result",
"overwrite": false}]
},
…](https://image.slidesharecdn.com/2251016final-171017052307/85/225-49-320.jpg)







![Distributed Tensorflow 실행
{
"environment": "cloud",
"cluster": {
"worker": ["worker1.example.com:2222, "worker2.example.com:2222""],
"ps": ["ps0.example.com:2222"],
"master": ["worker0.example.com:2222"]
},
"task": {"index": 0, "type": "master"}
}
TF_CONFIG](https://image.slidesharecdn.com/2251016final-171017052307/85/225-60-320.jpg)
























![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)










![[AWS Migration Workshop] 데이터베이스를 AWS로 손쉽게 마이그레이션 하기](https://cdn.slidesharecdn.com/ss_thumbnails/fy19q2awsmigrationworkshop-yoojeongchoi-190619044742-thumbnail.jpg?width=640&height=640&fit=bounds)




![[221]똑똑한 인공지능 dj 비서 clova music](https://cdn.slidesharecdn.com/ss_thumbnails/221djclovamusic-171016101800-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)

![[213] 의료 ai를 위해 세상에 없는 양질의 data 만드는 도구 제작하기](https://cdn.slidesharecdn.com/ss_thumbnails/213aidata-171016104902-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232]mist 고성능 iot 스트림 처리 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/232mist-iot-171017012717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[246]reasoning, attention and memory toward differentiable reasoning machines](https://cdn.slidesharecdn.com/ss_thumbnails/246reasoningattentionandmemory-towarddifferentiablereasoningmachines-171017054258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]streetwise machine learning for painless parking](https://cdn.slidesharecdn.com/ss_thumbnails/215streetwisemachinelearningforpainlessparking-171017050417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]open stack neutron dataplane 구현](https://cdn.slidesharecdn.com/ss_thumbnails/242openstackneutron-dataplane-171017004554-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213]building ai to recreate our visual world](https://cdn.slidesharecdn.com/ss_thumbnails/213buildingaitorecreateourvisualworld-171017023224-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)



![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS Innovate 온라인 컨퍼런스] 수백만 사용자 대상 기계 학습 서비스를 위한 확장 비법 - 윤석찬, AWS 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session1channyyun-200319071657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)

![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![[OpenInfra Days Korea 2018] Day 2 - E5: Mesos to Kubernetes, Cloud Native 서비스...](https://cdn.slidesharecdn.com/ss_thumbnails/e60930openinfraday2018dennis-180705030830-thumbnail.jpg?width=640&height=640&fit=bounds)





![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)