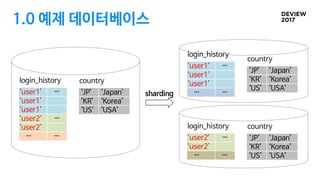
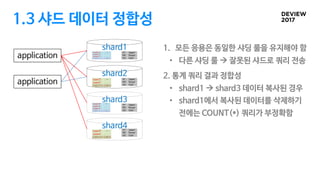
1.3 샤드 데이터정합성
1. 모든 응용은 동일한 샤딩 룰을 유지해야 함
• 다른 샤딩 룰 à 잘못된 샤드로 쿼리 전송
application
application
shard2
shard1
shard3
shard4
2. 통계 쿼리 결과 정합성
• shard1 à shard3 데이터 복사된 경우
• shard1에서 복사된 데이터를 삭제하기
전에는 COUNT(*) 쿼리가 부정확함
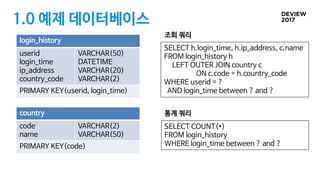
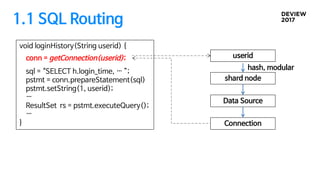
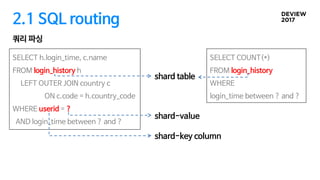
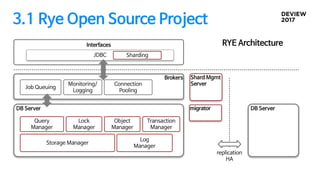
2.1 SQL routing
응용에서샤드 키 정보를 인식하는 방법
ü 샤드를 결정하기 위한 별도의 API
ü SQL에서 추출
void loginHistory(String userid) {
sql = “SELECT h.login_time, … ”;
pstmt = conn.prepareStatement(sql)
pstmt.setString(1, userid);
pstmt.setTimestamp(2, startTime);
pstmt.setTimestamp(3, endTime);
ResultSet rs = pstmt.executeQuery();
…
}
12.
2.1 SQL routing
테이블정의
CREATE TABLE
login_history
(
userid VARCHAR(50),
login_time DATETIME,
ip_address VARCHAR(20),
country_code VARCHAR(2),
PRIMARY KEY(userid, login_time)
)
CREATE TABLE
country
(
code VARCHAR(2),
name VARCHAR(50),
PRIMARY KEY (code)
);
테이블 타입과 샤드키 컬럼 정보를
DB 카탈로그에 저장
GLOBALSHARD
SHARD BY userid;
13.
2.1 SQL routing
SELECTh.login_time, c.name
FROM login_history h
LEFT OUTER JOIN country c
ON c.code = h.country_code
WHERE userid = ?
AND login_time between ? and ?
쿼리 파싱
SELECT COUNT(*)
FROM login_history
WHERE
login_time between ? and ?
14.
2.1 SQL routing
SELECTh.login_time, c.name
FROM login_history h
LEFT OUTER JOIN country c
ON c.code = h.country_code
WHERE userid = ?
AND login_time between ? and ?
쿼리 파싱
shard table
shard-key column
shard-value
SELECT COUNT(*)
FROM login_history
WHERE
login_time between ? and ?
15.
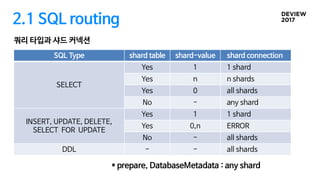
2.1 SQL routing
쿼리타입과 샤드 커넥션
SQL Type shard table shard-value shard connection
SELECT
Yes 1 1 shard
Yes n n shards
Yes 0 all shards
No - any shard
INSERT, UPDATE, DELETE,
SELECT FOR UPDATE
Yes 1 1 shard
Yes 0,n ERROR
No - all shards
DDL - - all shards
* prepare, DatabaseMetadata : any shard
16.
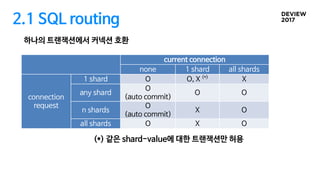
2.1 SQL routing
하나의트랜잭션에서 커넥션 호환
current connection
none 1 shard all shards
connection
request
1 shard O O, X (*)
X
any shard
O
(auto commit)
O O
n shards
O
(auto commit)
X O
all shards O X O
(*) 같은 shard-value에 대한 트랜잭션만 허용
17.
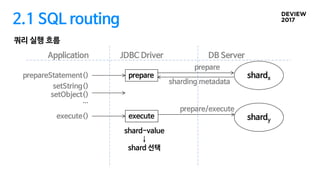
2.1 SQL routing
prepare
prepare
shardingmetadata
prepareStatement()
setString()
setObject()
…
execute() execute
shard-value
↓
shard 선택
prepare/execute
shardx
Application JDBC Driver DB Server
shardy
쿼리 실행 흐름
18.
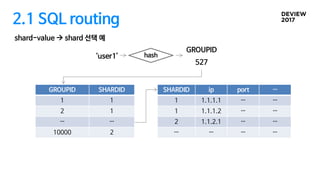
2.1 SQL routing
샤딩그룹
• shard-value는 개수가 많기 때문에 관리를 위한 데이터 단위가 필요
• 같은 샤드에 저장되는 shard-value의 그룹
• GROUPID = Hash(shard-value) % N + 1 (N = 샤딩 그룹의 개수)
• 샤드 리밸런스시 마이그레이션 단위. 데이터 정합성 판단에 활용.
Sharding catalog
• (GROUPID, SHARDID) mapping table
• shard node table - DB 접속을 위한 정보. ip, port, …
shard-value à shard 선택
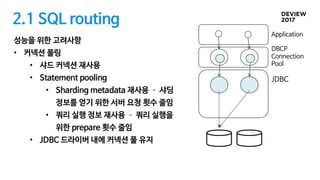
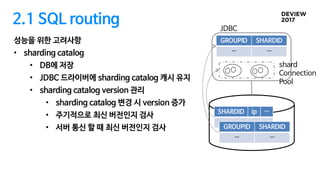
2.1 SQL routing
성능을위한 고려사항
• 커넥션 풀링
• 샤드 커넥션 재사용
• Statement pooling
• Sharding metadata 재사용 샤딩
정보를 얻기 위한 서버 요청 횟수 줄임
• 쿼리 실행 정보 재사용 쿼리 실행을
위한 prepare 횟수 줄임
• JDBC 드라이버 내에 커넥션 풀 유지
DBCP
Connection
Pool
JDBC
Application
21.
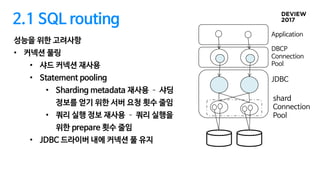
2.1 SQL routing
성능을위한 고려사항
• 커넥션 풀링
• 샤드 커넥션 재사용
• Statement pooling
• Sharding metadata 재사용 샤딩
정보를 얻기 위한 서버 요청 횟수 줄임
• 쿼리 실행 정보 재사용 쿼리 실행을
위한 prepare 횟수 줄임
• JDBC 드라이버 내에 커넥션 풀 유지
DBCP
Connection
Pool
JDBC
shard
Connection
Pool
Application
22.
2.1 SQL routing
성능을위한 고려사항
• sharding catalog
• DB에 저장
• JDBC 드라이버에 sharding catalog 캐시 유지
• sharding catalog version 관리
• sharding catalog 변경 시 version 증가
• 주기적으로 최신 버전인지 검사
• 서버 통신 할 때 최신 버전인지 검사
SHARDID ip …
… … …
GROUPID SHARDID
… …
GROUPID SHARDID
… …
shard
Connection
Pool
JDBC
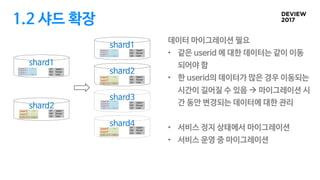
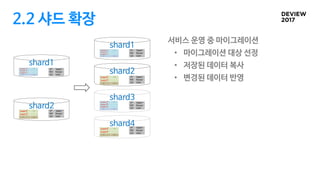
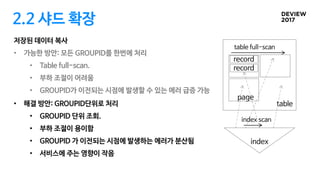
2.2 샤드 확장
저장된데이터 복사
• 가능한 방안: 모든 GROUPID를 한번에 처리
• Table full-scan.
• 부하 조절이 어려움
• GROUPID가 이전되는 시점에 발생할 수 있는 에러 급증 가능
table
record
record
page
table full-scan
index
index scan
• 해결 방안: GROUPID단위로 처리
• GROUPID 단위 조회.
• 부하 조절이 용이함
• GROUPID 가 이전되는 시점에 발생하는 에러가 분산됨
• 서비스에 주는 영향이 작음
26.
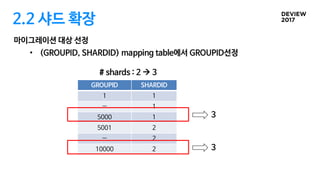
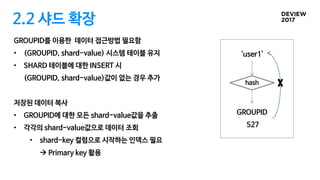
2.2 샤드 확장
GROUPID를이용한 데이터 접근방법 필요함
• (GROUPID, shard-value) 시스템 테이블 유지
• SHARD 테이블에 대한 INSERT 시
(GROUPID, shard-value)값이 없는 경우 추가
저장된 데이터 복사
• GROUPID에 대한 모든 shard-value값을 추출
• 각각의 shard-value값으로 데이터 조회
• shard-key 컬럼으로 시작하는 인덱스 필요
à Primary key 활용
‘user1’
GROUPID
527
hash
27.
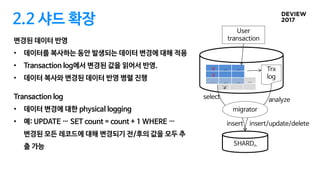
2.2 샤드 확장
변경된데이터 반영
• 데이터를 복사하는 동안 발생되는 데이터 변경에 대해 적용
• Transaction log에서 변경된 값을 읽어서 반영.
• 데이터 복사와 변경된 데이터 반영 병렬 진행
Transaction log
• 데이터 변경에 대한 physical logging
• 예: UPDATE … SET count = count + 1 WHERE …
변경된 모든 레코드에 대해 변경되기 전/후의 값을 모두 추
출 가능
‘a’ … …
‘a’
‘a’ … …
‘a’
… … …
Trx
log
SHARDn
select
insert
migrator
analyze
insert/update/delete
User
transaction
28.
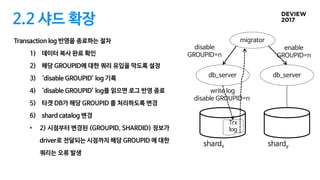
2.2 샤드 확장
Transactionlog 반영을 종료하는 절차
1) 데이터 복사 완료 확인
2) 해당 GROUPID에 대한 쿼리 유입을 막도록 설정
3) ‘disable GROUPID’ log 기록
4) ‘disable GROUPID’ log를 읽으면 로그 반영 종료
5) 타겟 DB가 해당 GROUPID 를 처리하도록 변경
6) shard catalog 변경
• 2) 시점부터 변경된 (GROUPID, SHARDID) 정보가
driver로 전달되는 시점까지 해당 GROUPID 에 대한
쿼리는 오류 발생
migrator
db_server
Trx
log
disable
GROUPID=n
write log
disable GROUPID=n
db_server
enable
GROUPID=n
shardx shardy
29.
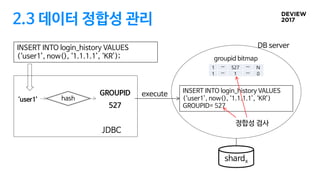
2.3 데이터 정합성관리
GROUPID기반 정합성 검사
• DB 서버에서 GROUPID bitmap 관리
• DB 서버는 관리하는 GROUPID인지 검사
• 모든 레코드, 인덱스에 GROUPID를 저장함
shardx
1 2 … N-1 N
1 1 … 0 0
GROUPID bitmap
DB server
30.
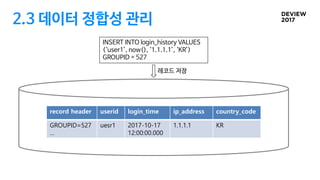
2.3 데이터 정합성관리
INSERT INTO login_history VALUES
(‘user1’, now(), ‘1.1.1.1’, ‘KR’);
shardx
JDBC
1 … 527 … N
1 … 1 … 0
groupid bitmap
INSERT INTO login_history VALUES
(‘user1’, now(), ‘1.1.1.1’, ‘KR’)
GROUPID= 527
정합성 검사
execute
DB server
‘user1’
GROUPID
527
hash
31.
2.3 데이터 정합성관리
INSERT INTO login_history VALUES
(‘user1’, now(), ‘1.1.1.1’, ‘KR’)
GROUPID = 527
record header userid login_time ip_address country_code
GROUPID=527
…
uesr1 2017-10-17
12:00:00.000
1.1.1.1 KR
레코드 저장
32.
2.3 데이터 정합성관리
저장된 GROUPID 용도
• 마이그레이션
• transaction log 반영 시 마이그레이션 대상 GROUPID인지 판단
• shard key가 지정되지 않은 쿼리의 데이터 정합성
• secondary index scan
• table full-scan
33.
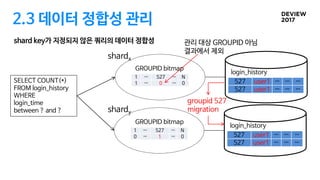
2.3 데이터 정합성관리
shard key가 지정되지 않은 쿼리의 데이터 정합성
SELECT COUNT(*)
FROM login_history
WHERE
login_time
between ? and ?
shardx
527 user1 … … …
527 user1 … … …
1 … 527 … N
1 … 0 … 0
GROUPID bitmap
login_history
shardy
527 user1 … … …
527 user1 … … …
1 … 527 … N
0 … 1 … 0
GROUPID bitmap
login_history
groupid 527
migration
관리 대상 GROUPID 아님
결과에서 제외
34.
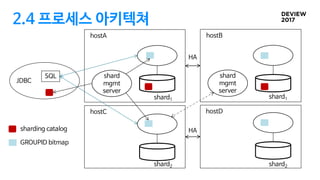
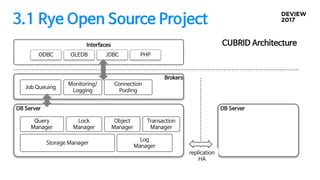
2.4 프로세스 아키텍쳐
shardingcatalog
shard1
hostA
shard
mgmt
server
shard1
hostB
shard
mgmt
server
shard2
hostC
shard2
hostD
GROUPID bitmap
HA
HA
JDBC
SQL
35.
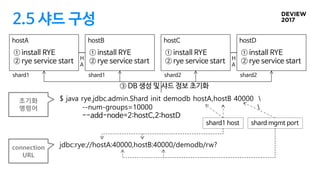
2.5 샤드 구성
hostA
①install RYE
② rye service start
hostB
① install RYE
② rye service start
hostC
① install RYE
② rye service start
hostD
① install RYE
② rye service start
$ java rye.jdbc.admin.Shard init demodb hostA,hostB 40000
--num-groups=10000
--add-node=2:hostC,2:hostD
jdbc:rye://hostA:40000,hostB:40000/demodb/rw?
초기화
명령어
connection
URL
shard1 host shard mgmt port
③ DB 생성 및 샤드 정보 초기화
shard1 shard1 shard2 shard2
H
A
H
A




![1.1 SQL Routing
void loginStatistics() {
sql = “SELECT COUNT(*) … “;
pstmt = conn.prepareStatement(sql)
…
ResultSet rs = pstmt.executeQuery();
…
}
모든 샤드에 대한
DB 커넥션 배열 반환
void loginStatistics() {
Connection[] conn = getAllShardConns();
for (int i=0 ; i < conn.length ; i++ ) {
sql = “SELECT COUNT(*) … “;
pstmt = conn[i].prepareStatement(sql)
…
ResultSet rs = pstmt.executeQuery();
…
}
}](https://image.slidesharecdn.com/223ryedbms-171016104435/85/223-rye-dbms-7-320.jpg)












![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)

![[244] 분산 환경에서 스트림과 배치 처리 통합 모델](https://cdn.slidesharecdn.com/ss_thumbnails/244-150915025618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)
![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[243]kaleido 노현걸](https://cdn.slidesharecdn.com/ss_thumbnails/243kaleido-161025011559-thumbnail.jpg?width=640&height=640&fit=bounds)


![[164] pinpoint](https://cdn.slidesharecdn.com/ss_thumbnails/164pinpoint-150914054628-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2]thread dump 분석기법과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/d2threaddump-150522063949-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)

![[232] 수퍼컴퓨팅과 데이터 어낼리틱스](https://cdn.slidesharecdn.com/ss_thumbnails/223-150915022242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]루빅스개발이야기 황지수](https://cdn.slidesharecdn.com/ss_thumbnails/235-161025031044-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)

![[221]똑똑한 인공지능 dj 비서 clova music](https://cdn.slidesharecdn.com/ss_thumbnails/221djclovamusic-171016101800-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213]building ai to recreate our visual world](https://cdn.slidesharecdn.com/ss_thumbnails/213buildingaitorecreateourvisualworld-171017023224-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]open stack neutron dataplane 구현](https://cdn.slidesharecdn.com/ss_thumbnails/242openstackneutron-dataplane-171017004554-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]neural machine translation (nmt) 동작의 시각화 및 분석 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222neuralmachinetranslationnmt-171016102621-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]streetwise machine learning for painless parking](https://cdn.slidesharecdn.com/ss_thumbnails/215streetwisemachinelearningforpainlessparking-171017050417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)
![[246]reasoning, attention and memory toward differentiable reasoning machines](https://cdn.slidesharecdn.com/ss_thumbnails/246reasoningattentionandmemory-towarddifferentiablereasoningmachines-171017054258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232]mist 고성능 iot 스트림 처리 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/232mist-iot-171017012717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] 의료 ai를 위해 세상에 없는 양질의 data 만드는 도구 제작하기](https://cdn.slidesharecdn.com/ss_thumbnails/213aidata-171016104902-thumbnail.jpg?width=640&height=640&fit=bounds)

![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[141]네이버랩스의 로보틱스 연구 소개](https://cdn.slidesharecdn.com/ss_thumbnails/41-171015225628-thumbnail.jpg?width=640&height=640&fit=bounds)

![[111]open, share, enjoy 네이버의 오픈소스 활동](https://cdn.slidesharecdn.com/ss_thumbnails/11openshareenjoy-171016004935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[131]chromium binging 기술을 node.js에 적용해보자](https://cdn.slidesharecdn.com/ss_thumbnails/31chromiumbingdingfinal-171015225736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[124]자율주행과 기계학습](https://cdn.slidesharecdn.com/ss_thumbnails/124-171016052833-thumbnail.jpg?width=640&height=640&fit=bounds)








![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2D7]레기온즈로 살펴보는 확장 가능한 게임서버의 구현](https://cdn.slidesharecdn.com/ss_thumbnails/2d7-140930023650-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)