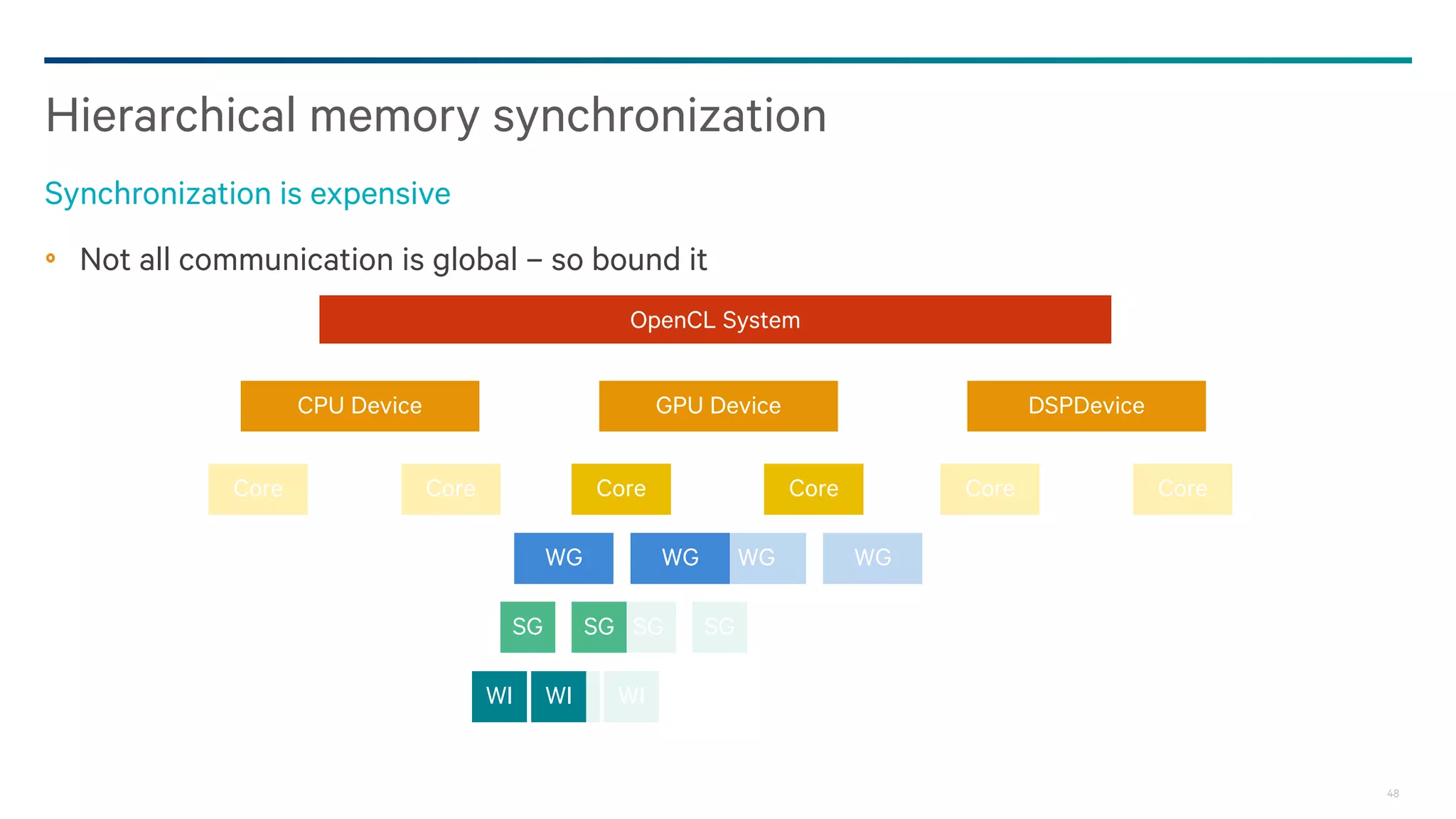
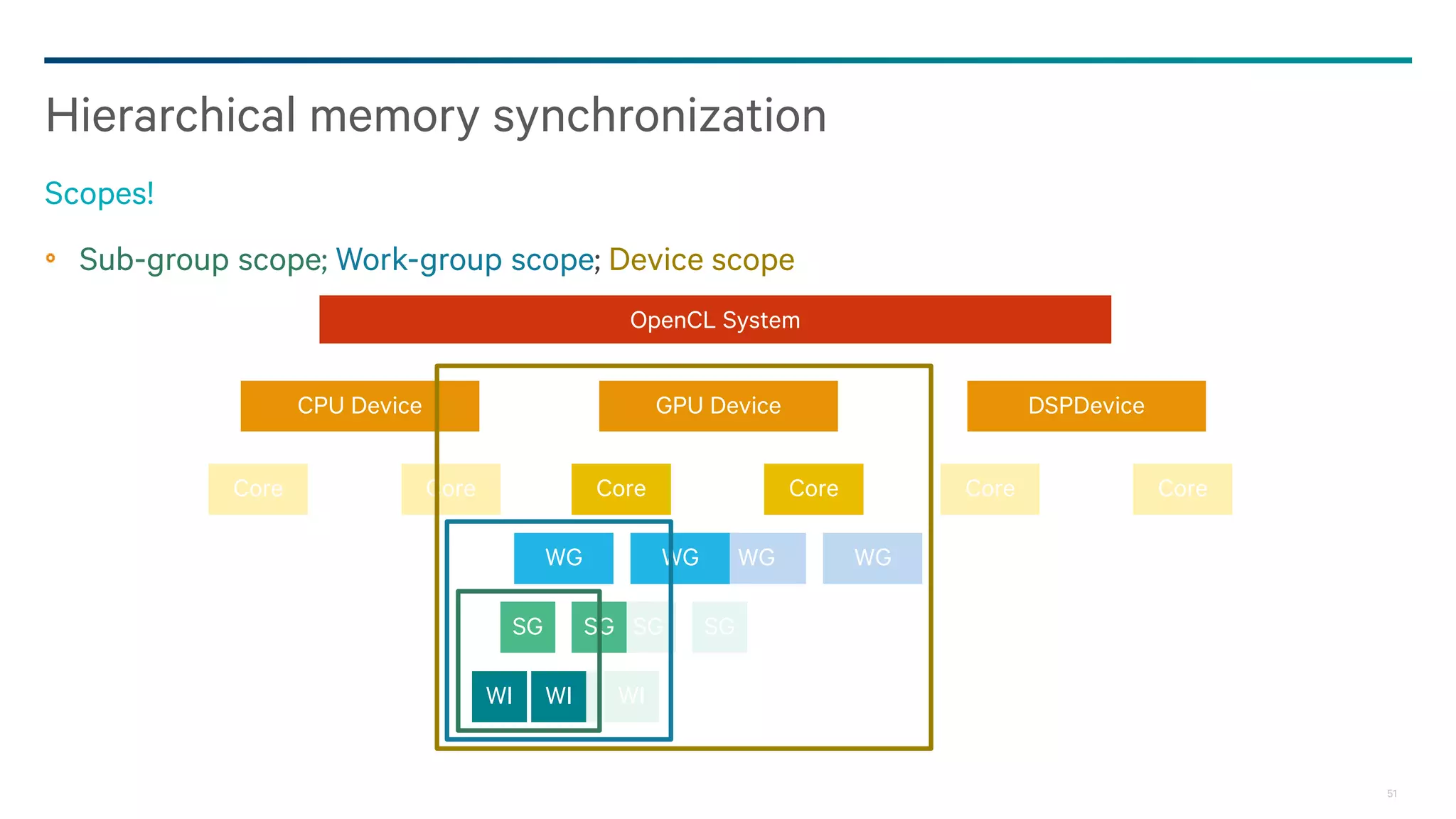
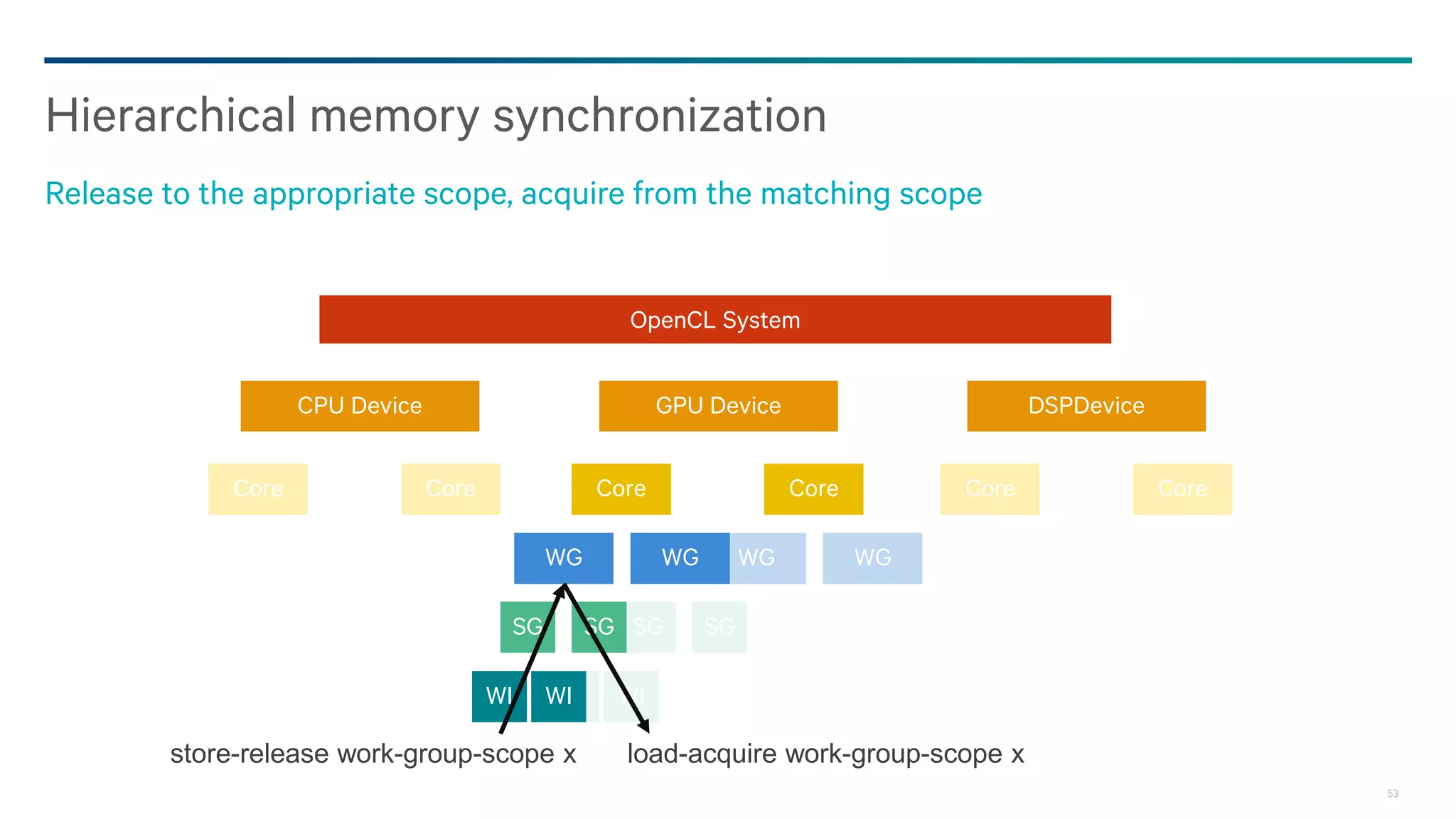
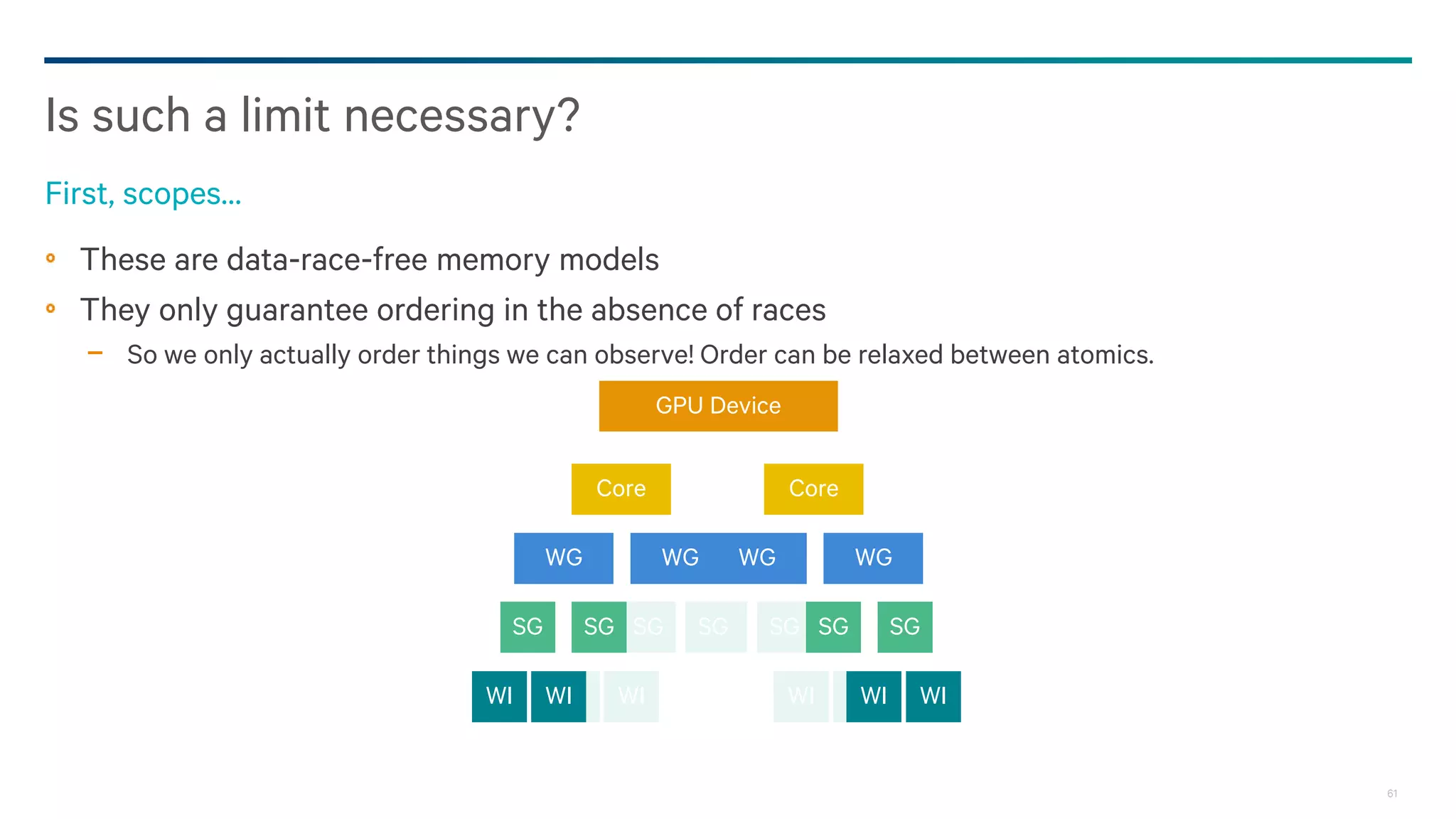
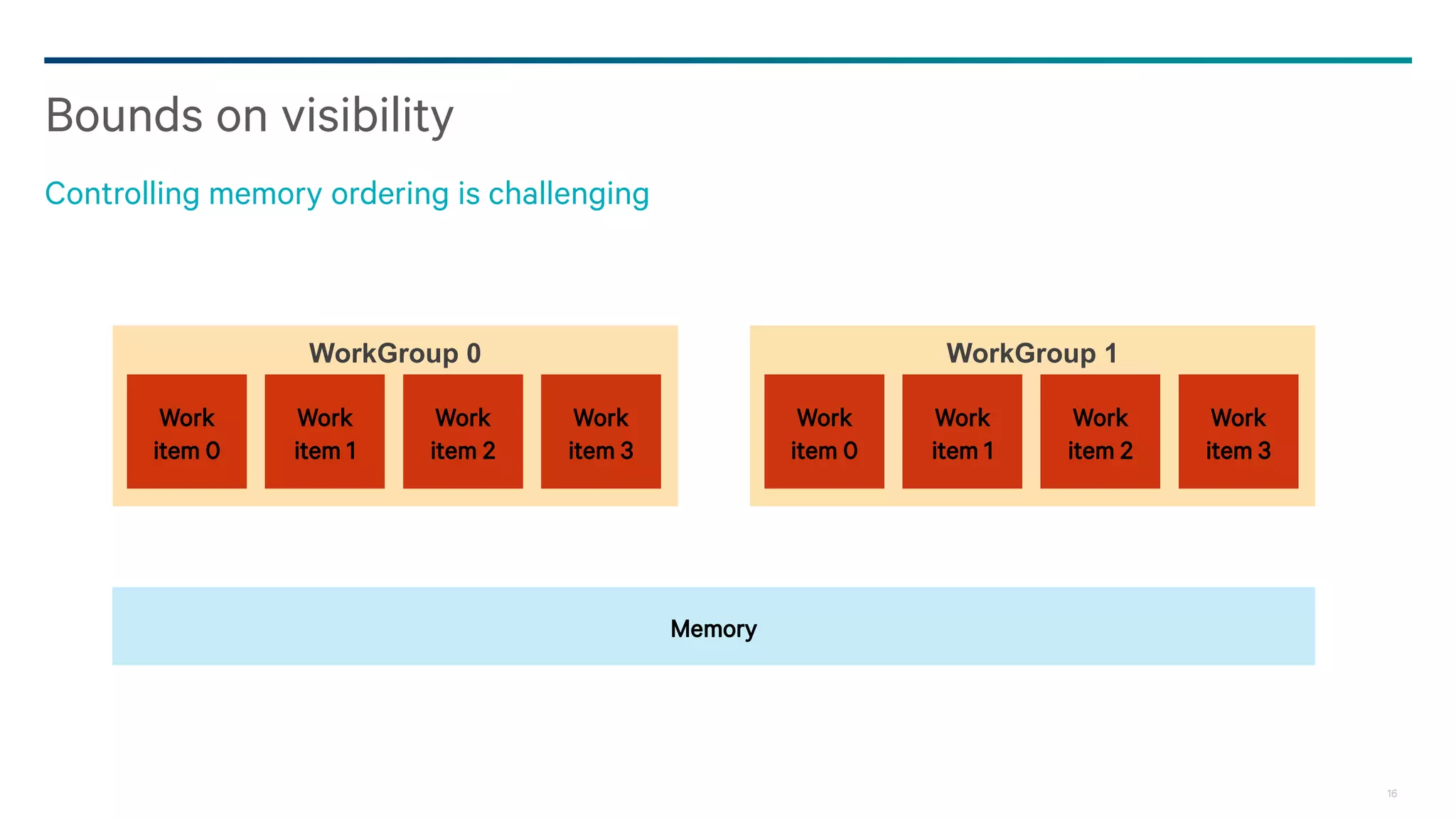
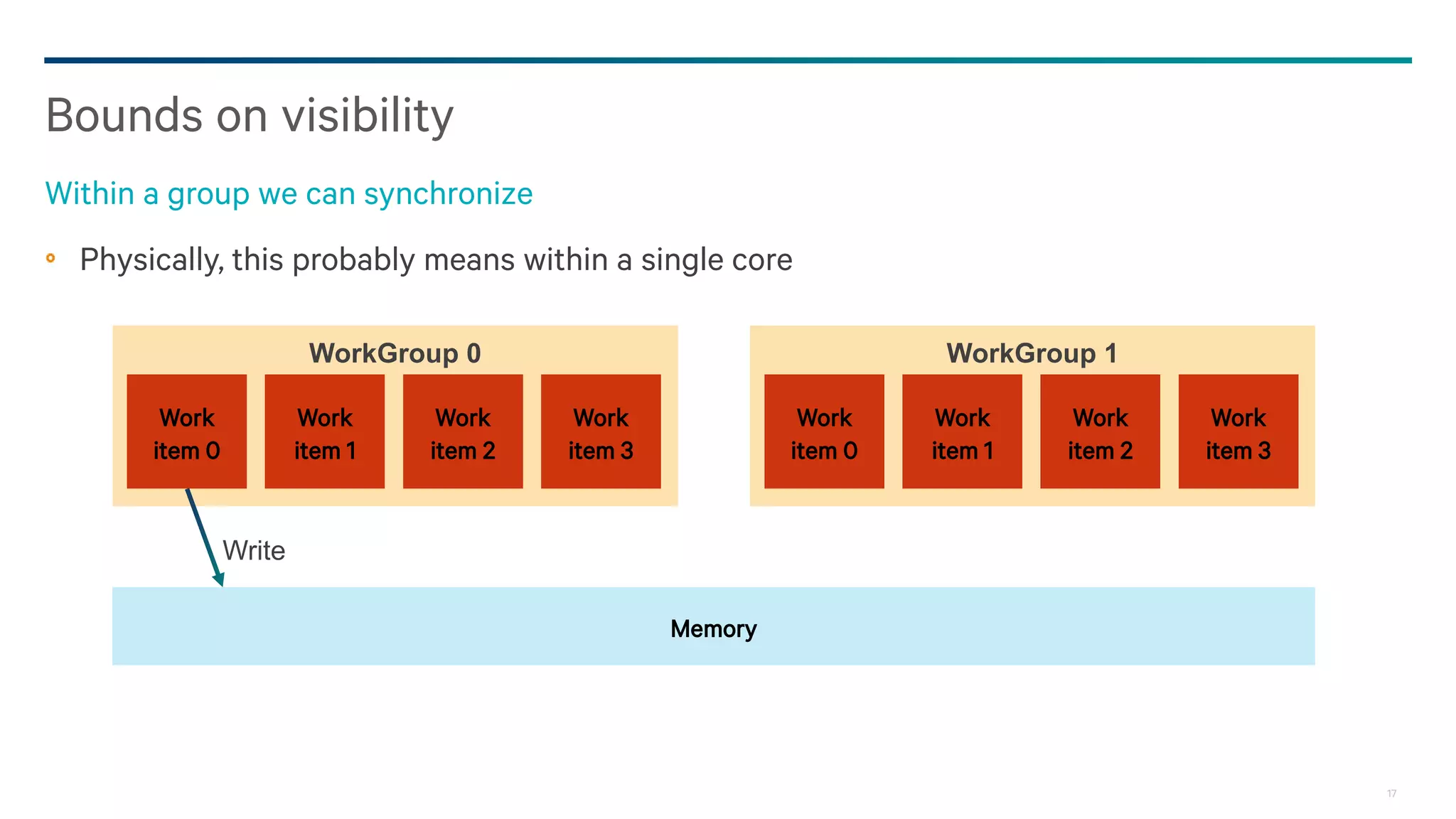
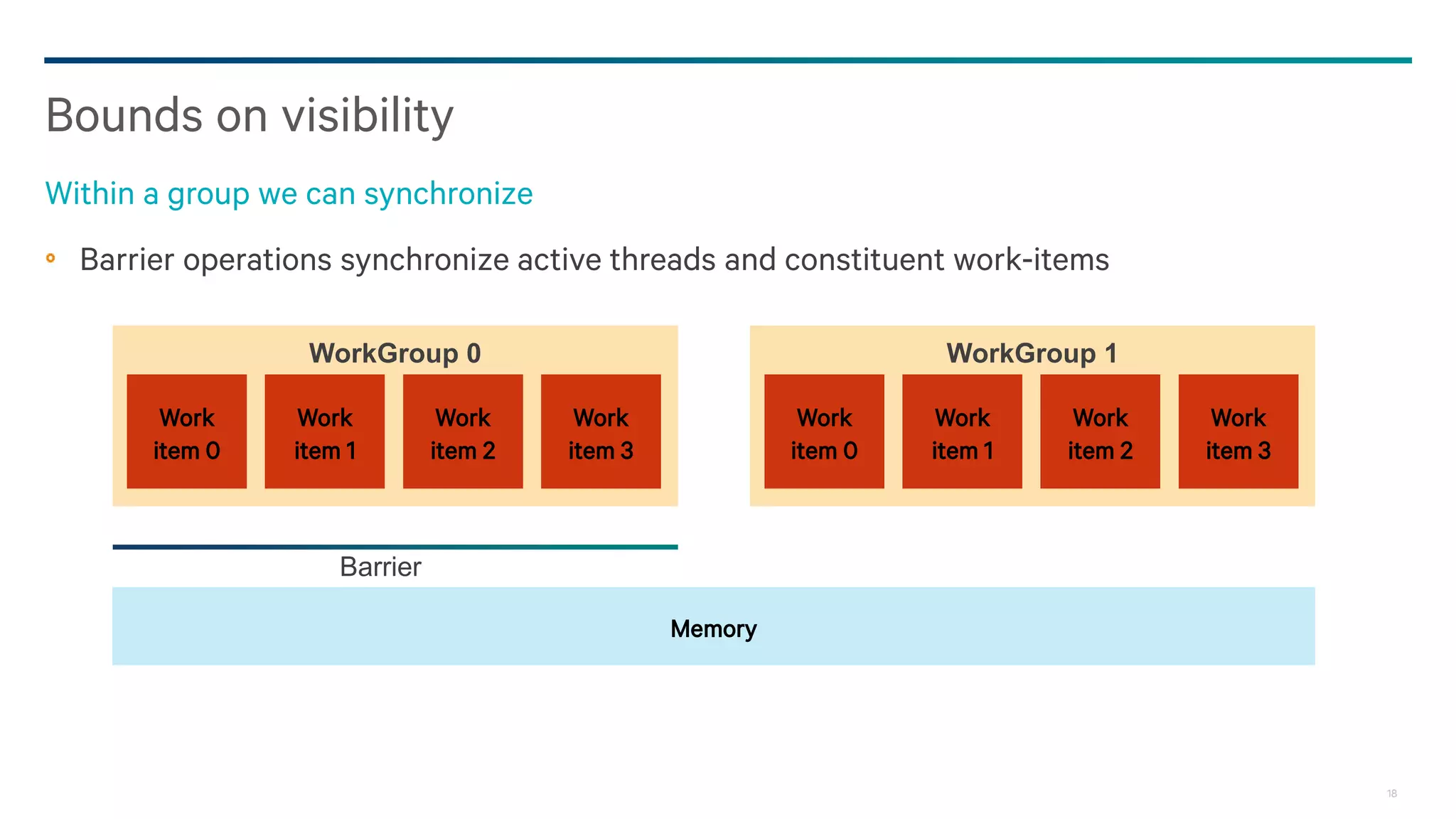
Dark Secrets: Heterogeneous Memory Models is a document about the challenges of memory consistency models across heterogeneous systems like OpenCL. It discusses three main issues with current models: coarse-grained access to data, separate addressing between devices and hosts, and weak/undefined ordering controls. It also covers basics of the OpenCL 2.0 memory model, which aims to address these issues by allowing shared virtual addressing between devices and hosts, finer-grained synchronization using events, and atomic operations for ordering. However, memory models still have limitations around data races and forward progress that require careful programming.







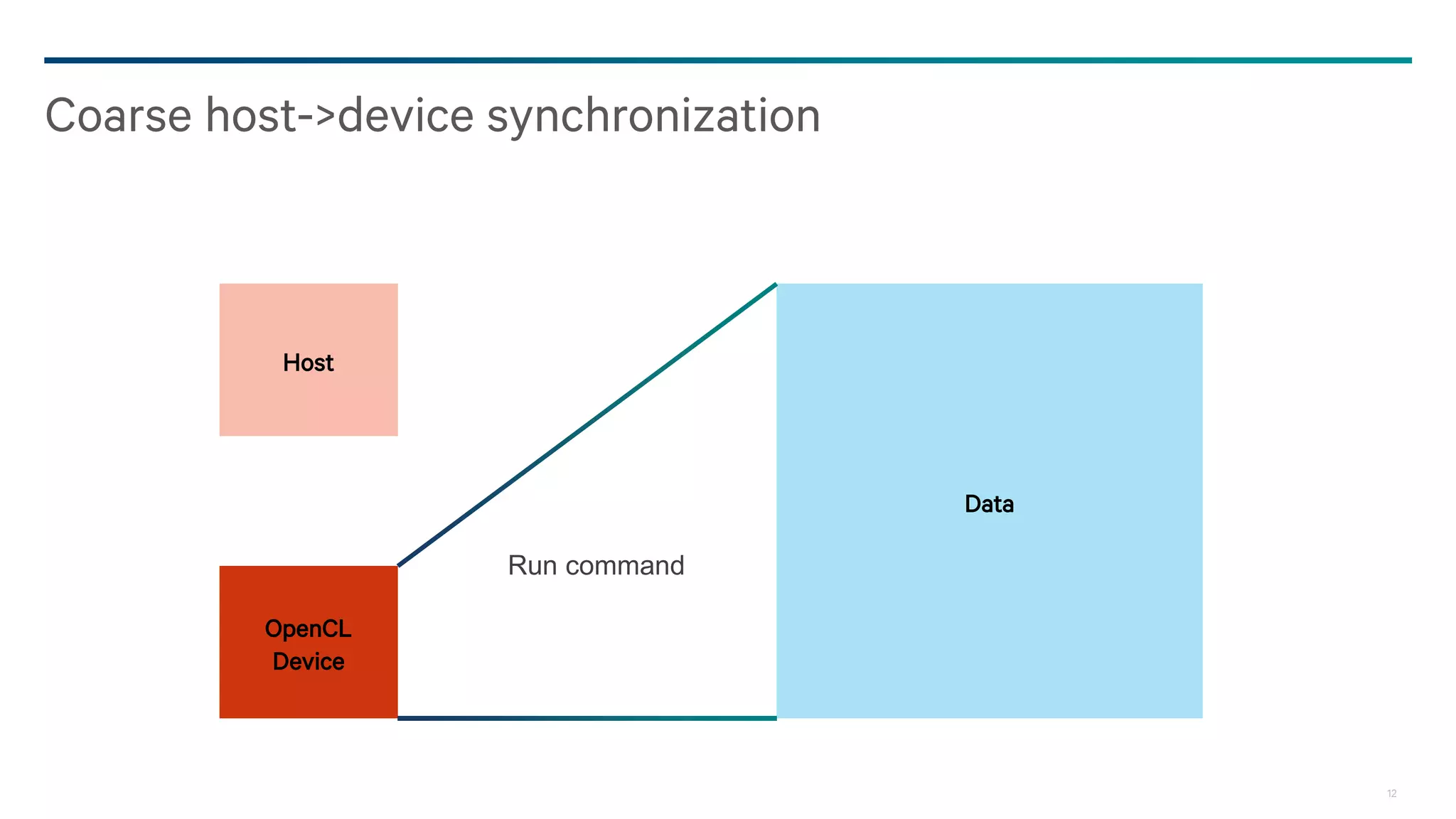
![13
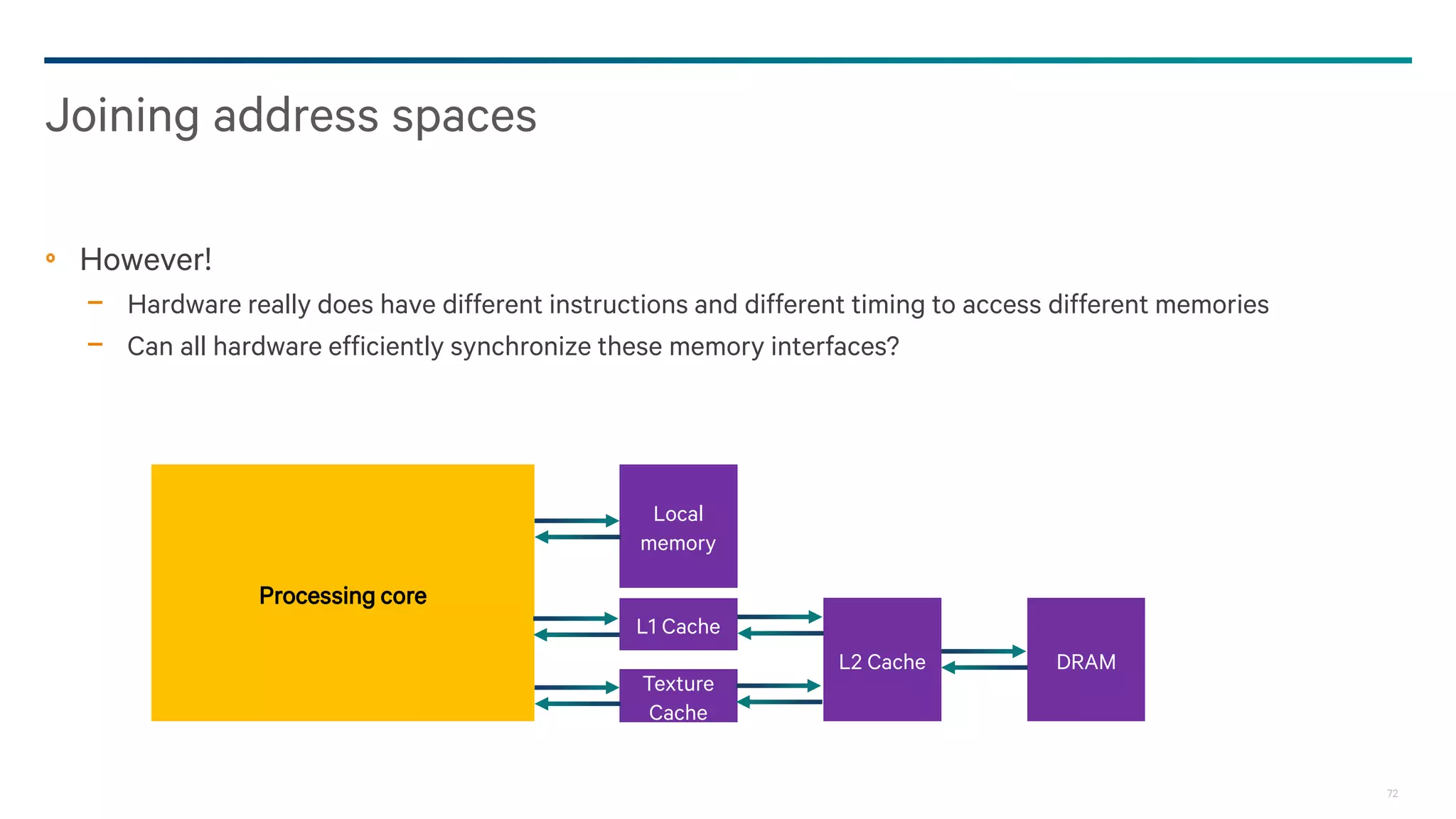
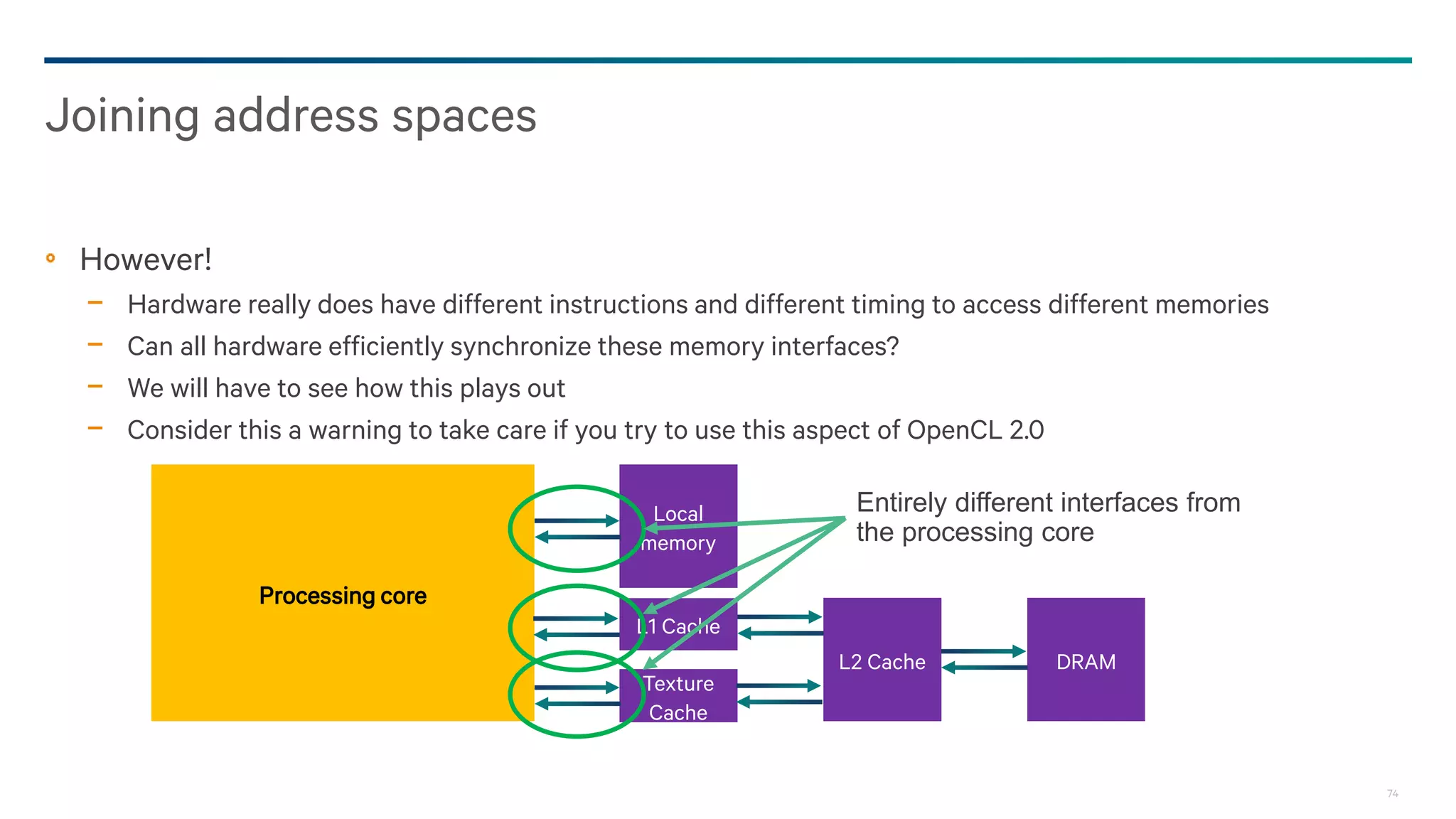
Separate addressing
We can update memory with a pointer
Host
OpenCL
Device
data[n].ptr = &data[n+1];
data[n+1].val = 3;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-13-2048.jpg)
![14
Separate addressing
We try to read it – but what is the value of a?
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-14-2048.jpg)
![15
Separate addressing
Unfortunately, the address of data may change
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-15-2048.jpg)
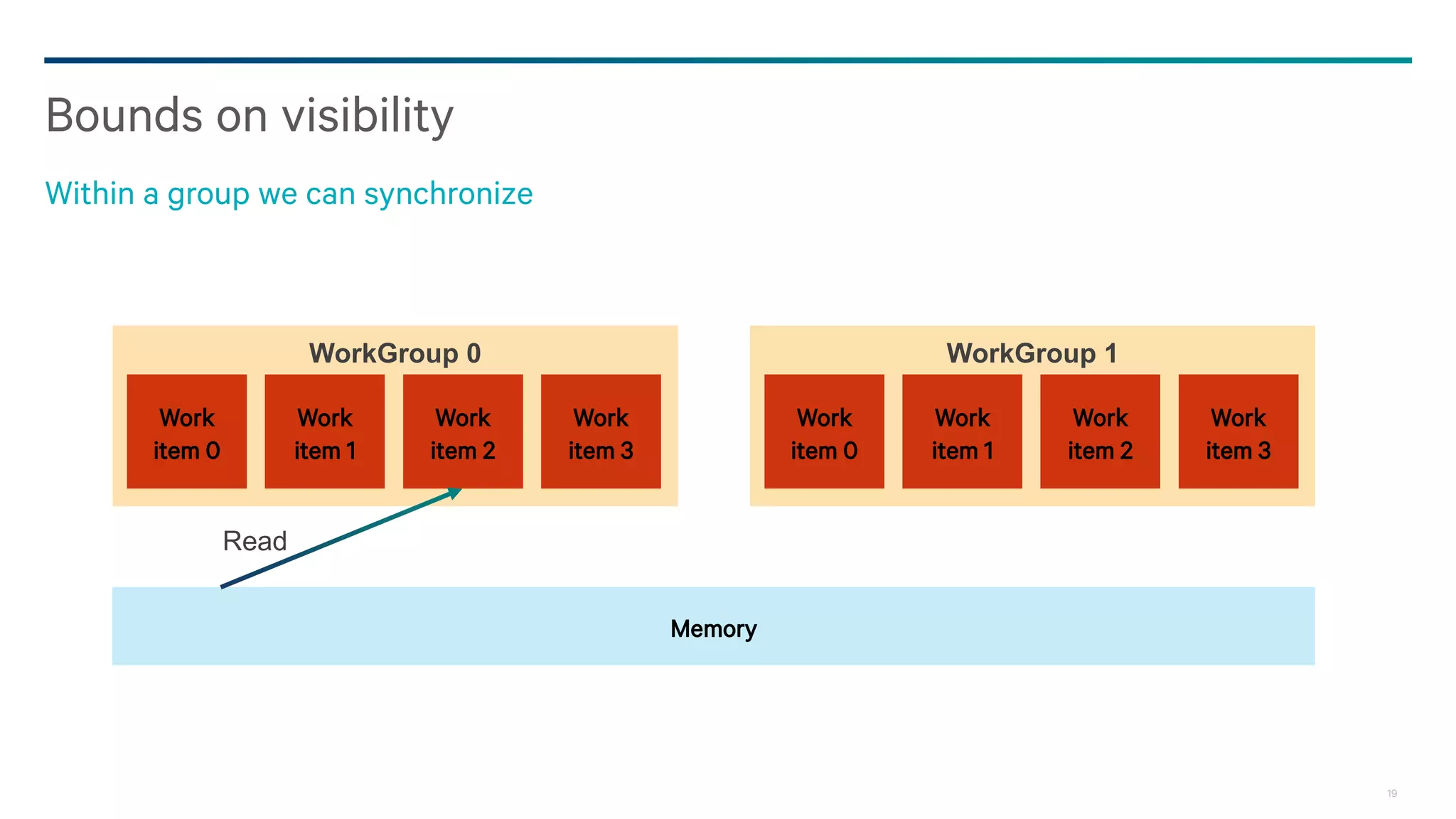
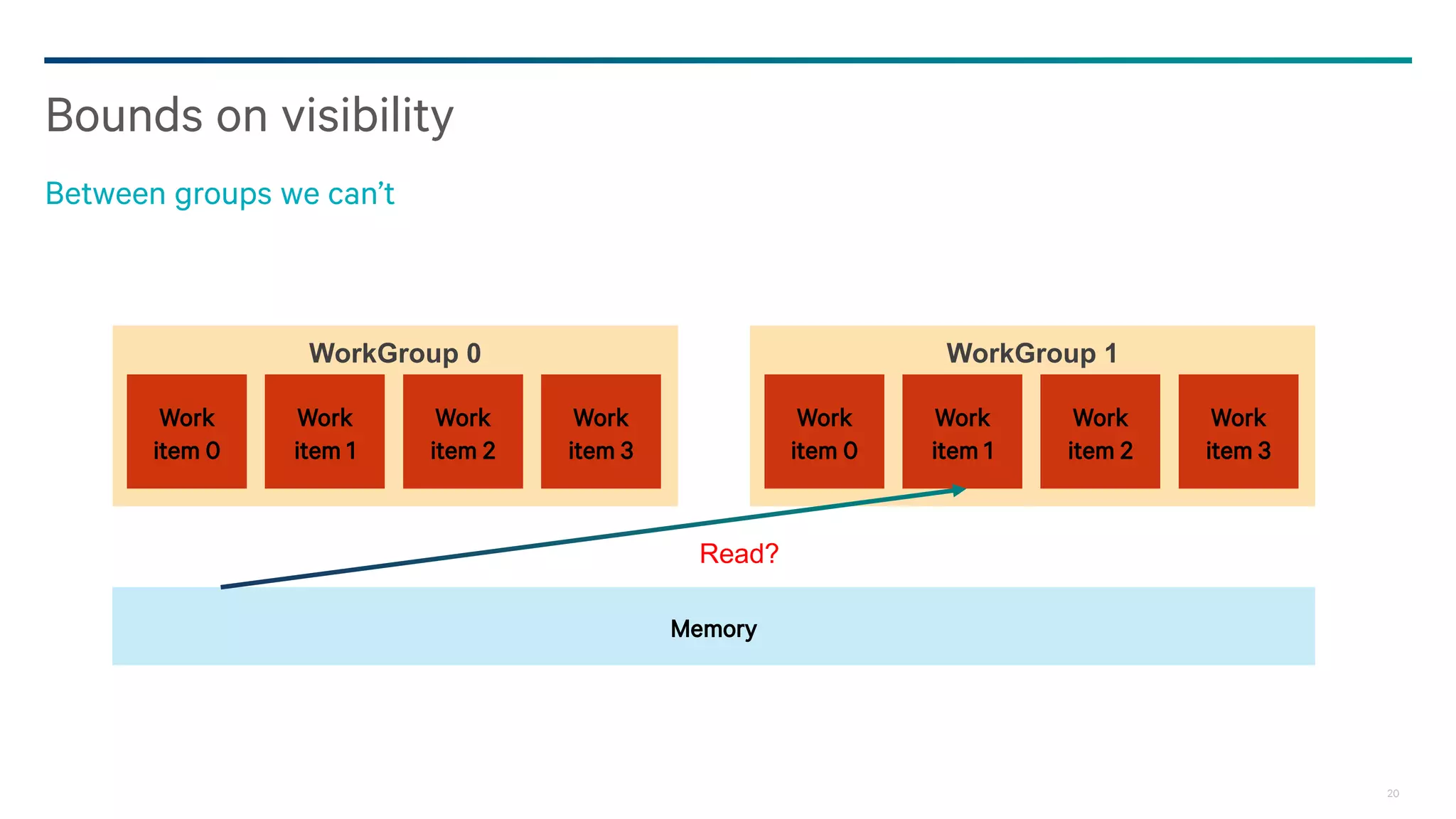
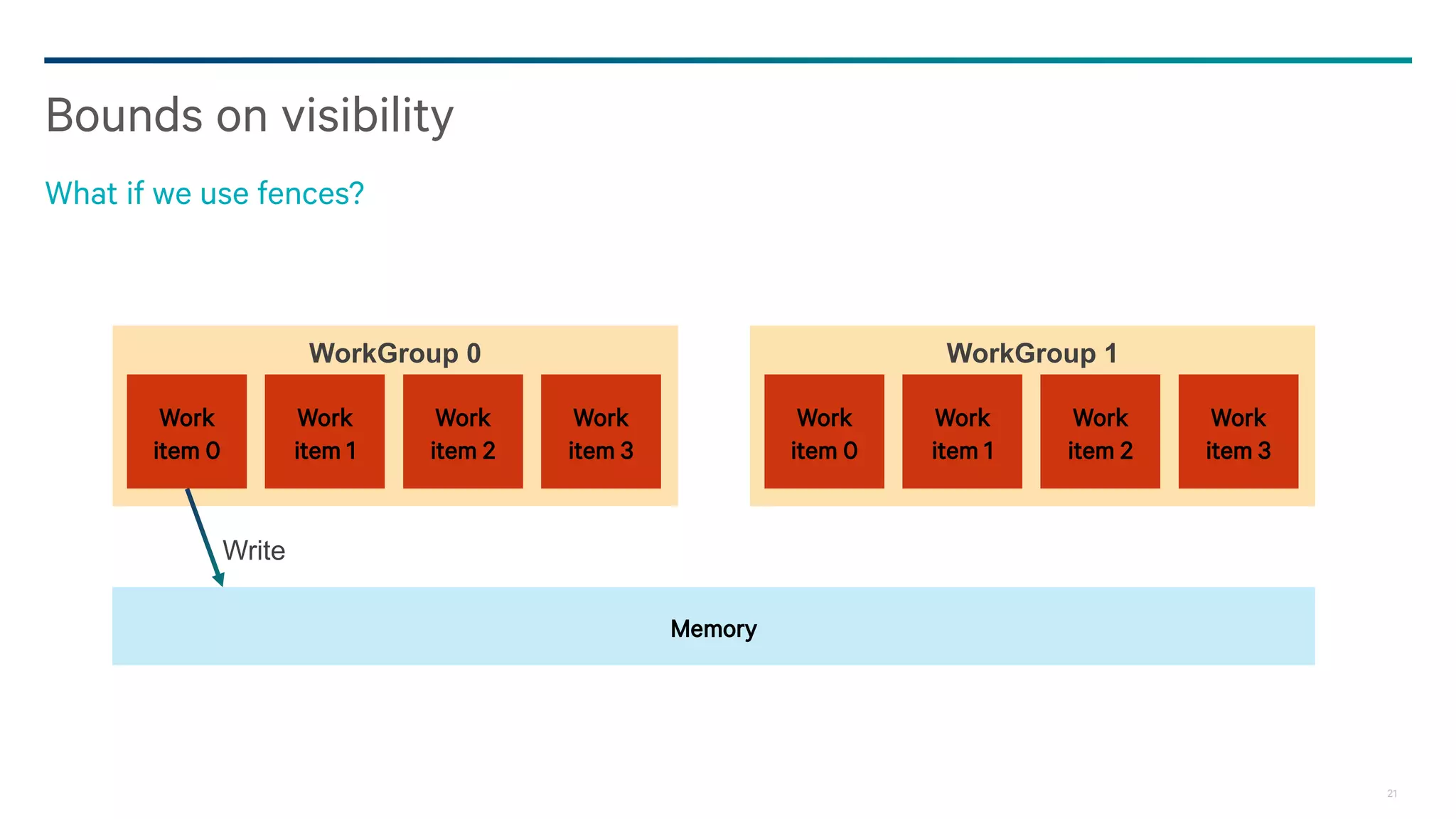
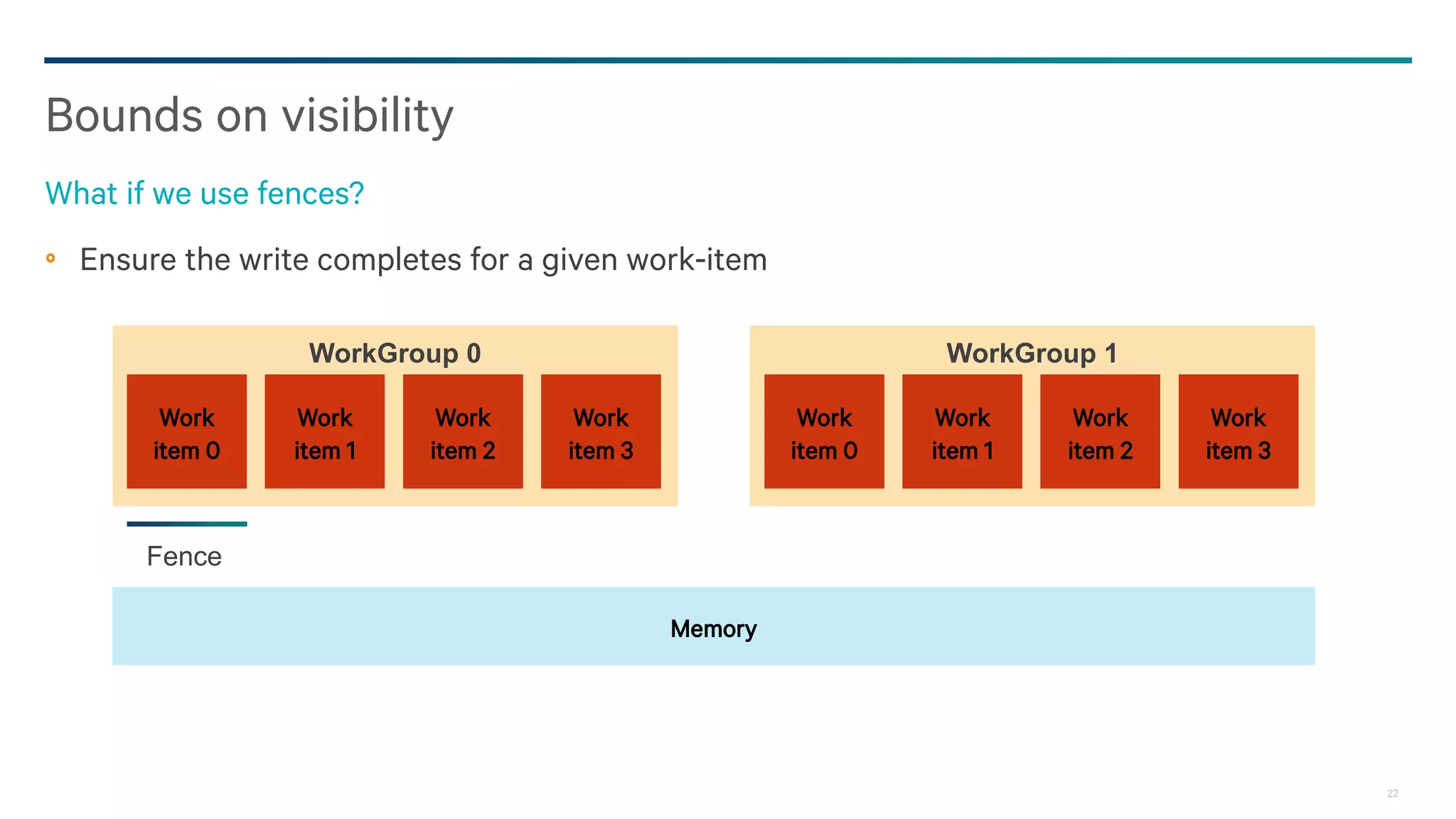

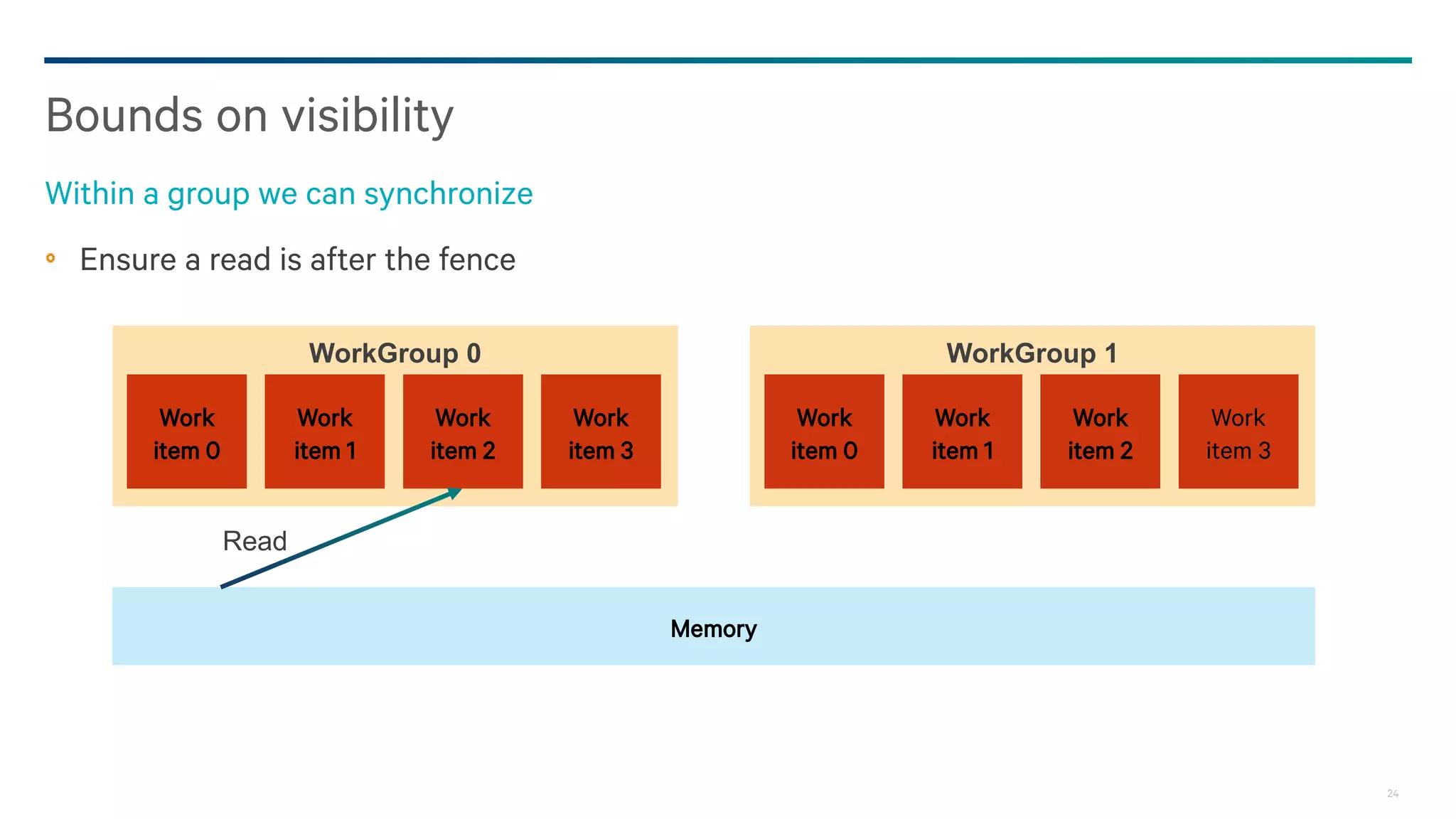
![25
Probably seeing a write that was written after a fence guarantees that the fence completed
− The spec is not very clear on this
There is no coherence guarantee
− Need the write ever complete?
− If it doesn’t complete, who can see it, who can know that the fence happened?
Can the flag be updated without a race?
− For that matter, what is a race?
Spliet et al: KMA.
− Weak ordering differences between platforms due to poorly defined model.
Meaning of fences
When did the fence happen?
{{
data[n] = value;
fence(…);
flag = trigger;
||
if(flag) {
fence(…);
value = data[n];
}}](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-25-2048.jpg)

![27
Sharing virtual addresses
We can update memory with a pointer
Host
OpenCL
Device
data[n].ptr = &data[n+1];
data[n+1].val = 3;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-27-2048.jpg)
![28
Sharing virtual addresses
We try to read it – but what is the value of a?
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-28-2048.jpg)
![29
Sharing virtual addresses
Now the address does not change!
Host
OpenCL
Device
int a = data[n].ptr->val;
assert(a == 3);
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-29-2048.jpg)
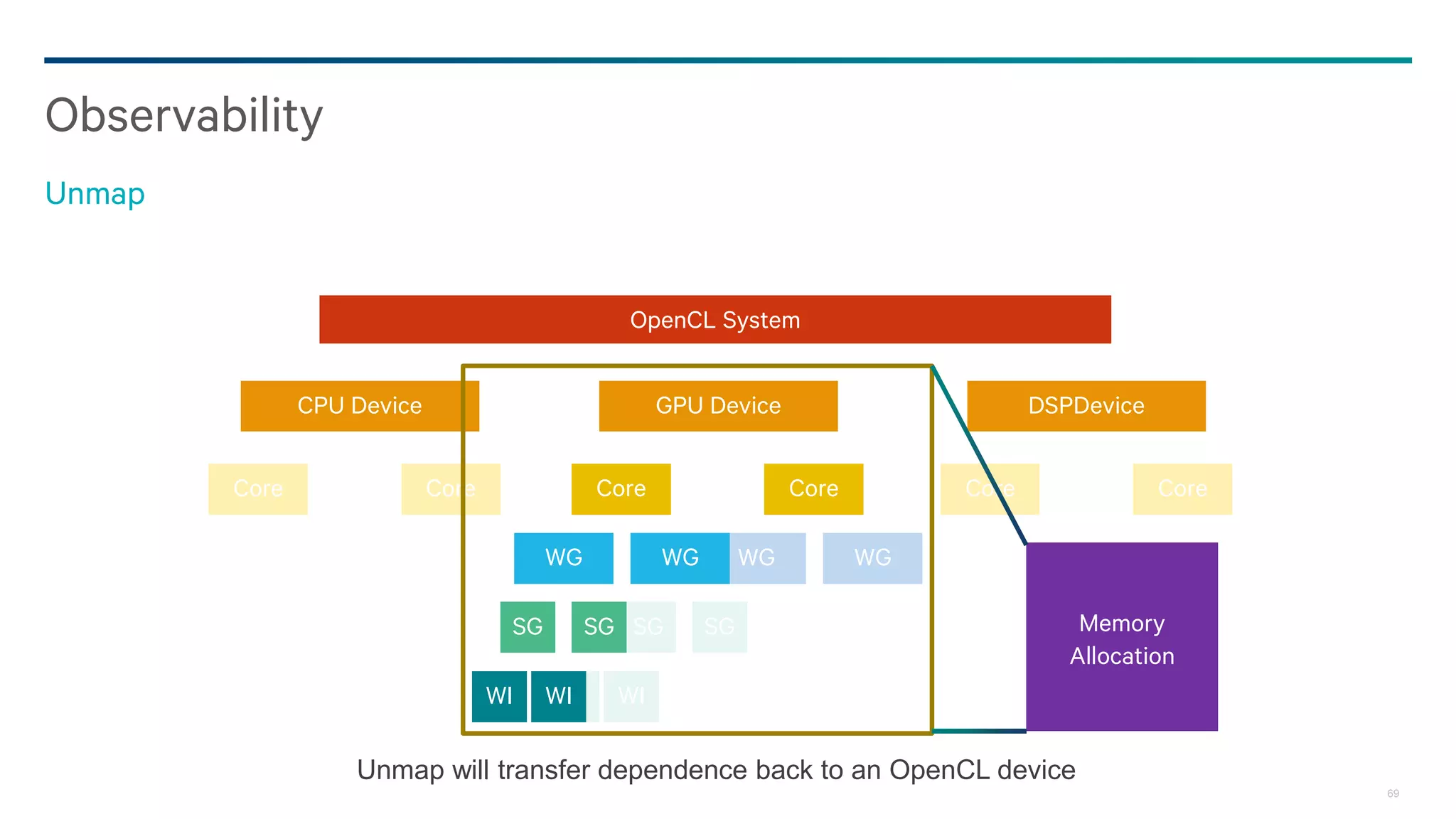
![30
Unmap on the host, event dependency on device
Sharing data – when does the value change?
Coarse grained
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
data[n].ptr = &data[n+1];
data[n+1].val = 3;
clUnmapMemObject
Event e](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-30-2048.jpg)
![31
Granularity of data race covers the whole buffer
Sharing data – when does the value change?
Coarse grained
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
data[n].ptr = &data[n+1];
data[n+1].val = 3;
clUnmapMemObject
Event e](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-31-2048.jpg)
![32
Event dependency on device – caches will flush as necessary
Sharing data – when does the value change?
Fine grained
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
data[n].ptr = &data[n+1];
data[n+1].val = 3;
Event e](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-32-2048.jpg)
![33
Data will be merged – data race at byte granularity
Sharing data – when does the value change?
Fine grained
Host
OpenCL
Device
int a = data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
data[n].ptr = &data[n+1];
data[n+1].val = 3;
Event e](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-33-2048.jpg)
![34
No dispatch-level ordering necessary
Sharing data – when does the value change?
Fine grained with atomic support
Host
OpenCL
Device
int a = atomic-load data[n].ptr->val;
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
data[n].ptr = &data[n+1];
Atomic-store data[n+1].val = 3;](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-34-2048.jpg)
![35
Races at byte level – avoided using the atomics in the memory model
Sharing data – when does the value change?
Fine grained with atomic support
Host
OpenCL
Device
struct Foo {
Foo *ptr;
int val;
};
struct Foo {
Foo *ptr;
int val;
};
Data[n]
Data[n+1]
int a = atomic-load data[n].ptr->val;
data[n].ptr = &data[n+1];
Atomic-store data[n+1].val = 3;](https://image.slidesharecdn.com/20150207-howes-gpgpu8-darksecrets-150829002739-lva1-app6892/75/20150207-howes-gpgpu8-dark-secrets-35-2048.jpg)