Download to read offline









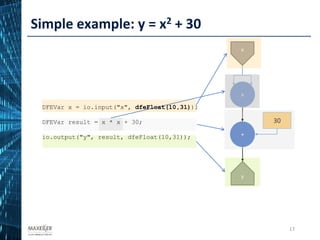
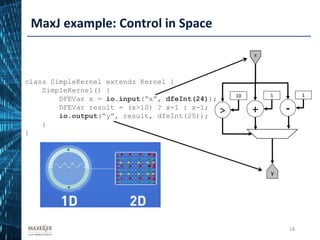





![Problem
(Small/Large)
System (composition) (size) TTS
[sec]
ETS
[kWh]
DTS
(F1)
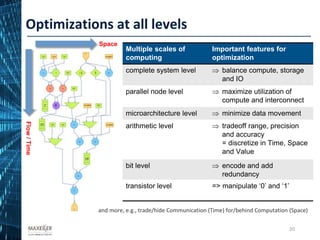
BQCD 32x32x32x32 PRACE pilot (8 DFEs, 64 EPYC cores) (2U) 1,054 0.44 -
64x64x64x64 1PF equivalent (48 DFEs, 512 EPYC cores) (14U) 1,703.8 4.26 $39.93
NEMO GYRE6 PRACE pilot (8 DFEs, 64 EPYC cores) (2U) 388 0.164 -
GYRE144 1PF equivalent (48 DFEs, 92 EPYC cores) (8U) 1,942 3.77 $42.72
SFM3D 1 chunk x64x64 PRACE pilot (8 DFEs, 64 EPYC cores) (2U) 232 0.096 -
6 chunks x1,440x1,440 1PF equivalent (384 DFEs, 768 EPYC cores) (60U) 5,150 70.1 $1,267.2
QE Al2O3 PRACE pilot (8 DFEs, 64 EPYC cores) (2U) 32 0.013 -
Ta2O5 1PF equivalent (64 DFEs, 64 EPYC cores) (9U) 3,210 7.58 $94.16
Achieved Performance PRACE workloads
30](https://image.slidesharecdn.com/maxelerapril2019v2-190429113911/85/Programmable-Exascale-Supercomputer-30-320.jpg)









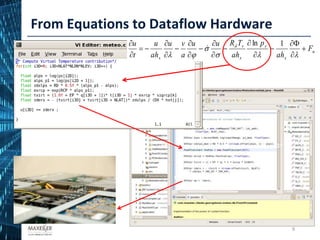
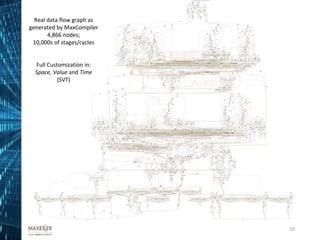
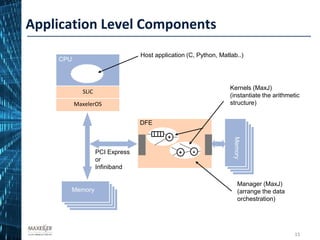
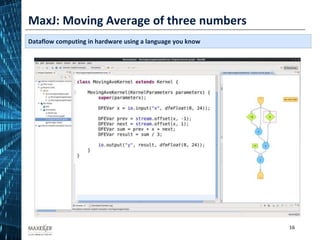
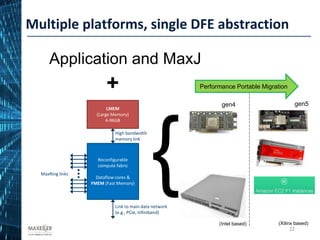
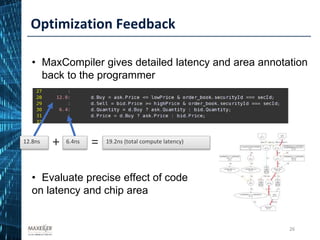
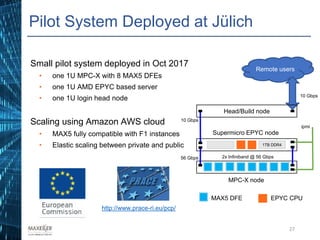
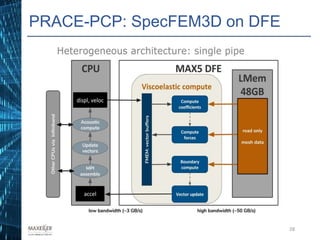
The document discusses the development of affordable and programmable exascale computers, emphasizing the significance of efficient data movement to address energy consumption and performance challenges. It outlines the need for custom hardware and software co-design to optimize performance-critical applications and presents methodologies for dataflow computing using the Maxeler dataflow engine. Additionally, it highlights recent accomplishments in workload performance improvements through advanced computing techniques and scalable design implementations.

















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















