Downloaded 19 times



![© 2016 Cake Solutions Limited CC BY-NC-SA 4.0
The technologies—iOS
• Learns the users’ behaviour
• Exercise sessions
• Exercises within exercise session
• Short–term prediction of [scalar] labels for the exercises
• Performs the real–time analysis of the incoming sensor
data
• Advised by the expected behaviour
• Signal processing to compute repetitions / strokes
• Forward–propagation to label the exercise
• Submits all recorded sensor data and confirmed (!) labels
per session
• Handles offline / travel modes
• Synchronises the data across the user’s devices using iCloud](https://image.slidesharecdn.com/datastax-summit-2016-smack-stack-160419140304/85/Real-time-personal-trainer-on-the-SMACK-stack-5-320.jpg)




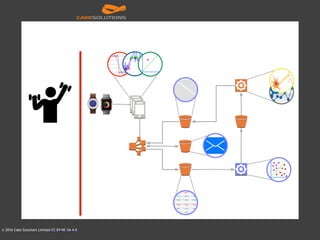









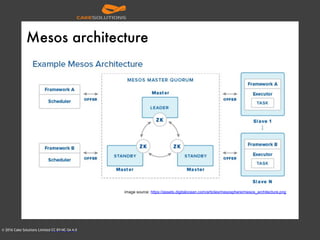
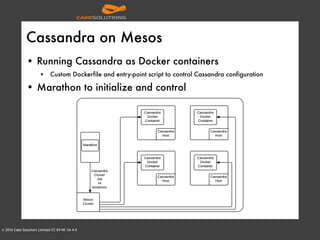

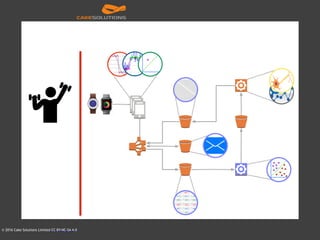


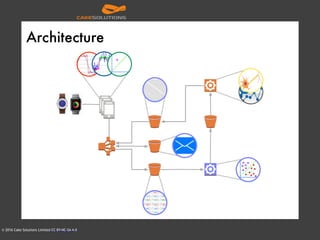
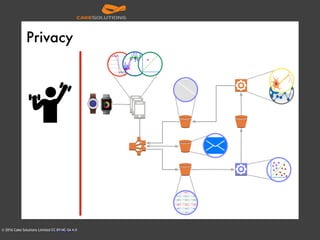
The document outlines the architecture of an automated personal training system called Muvr, which uses various technologies including iOS, Akka, Spark, Neon, and Cassandra to deliver real-time personalized exercise recommendations and monitor user performance. It details the system's capabilities, such as exercise session suggestions, proper form tips, and machine learning applications for continuous improvement. It also discusses deployment strategies using Docker and resource management on AWS for cost-effectiveness.