Downloaded 57 times




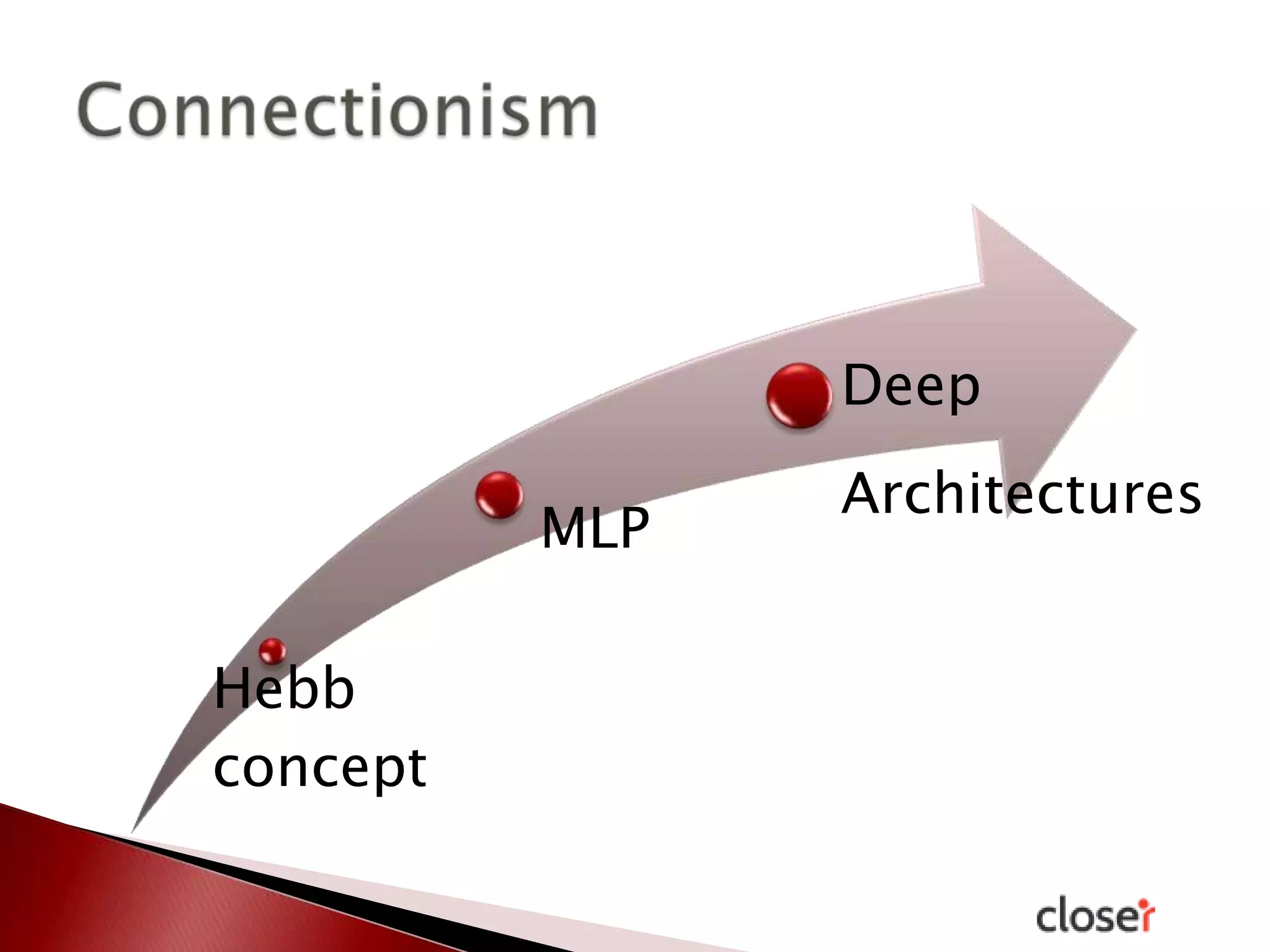



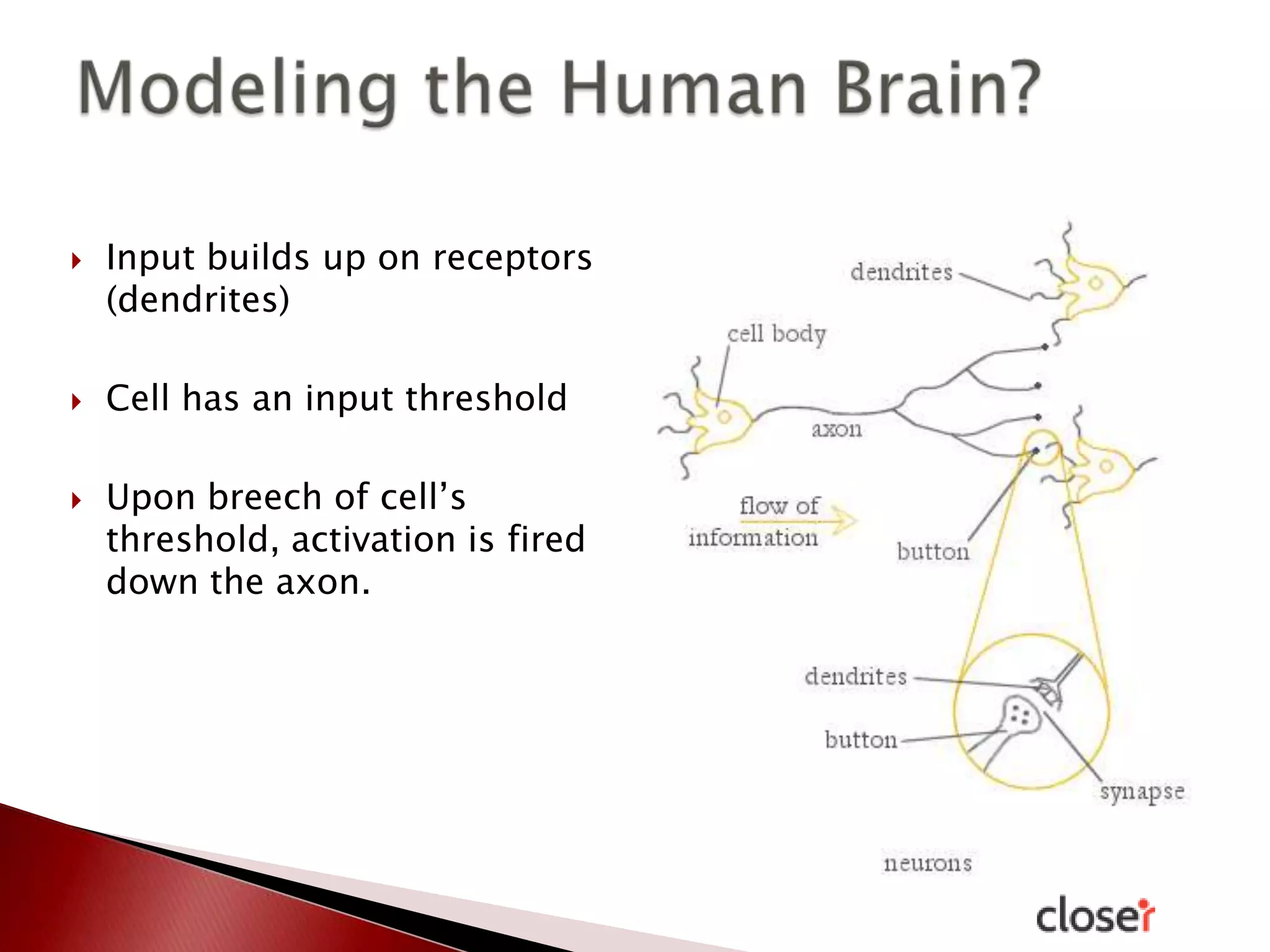
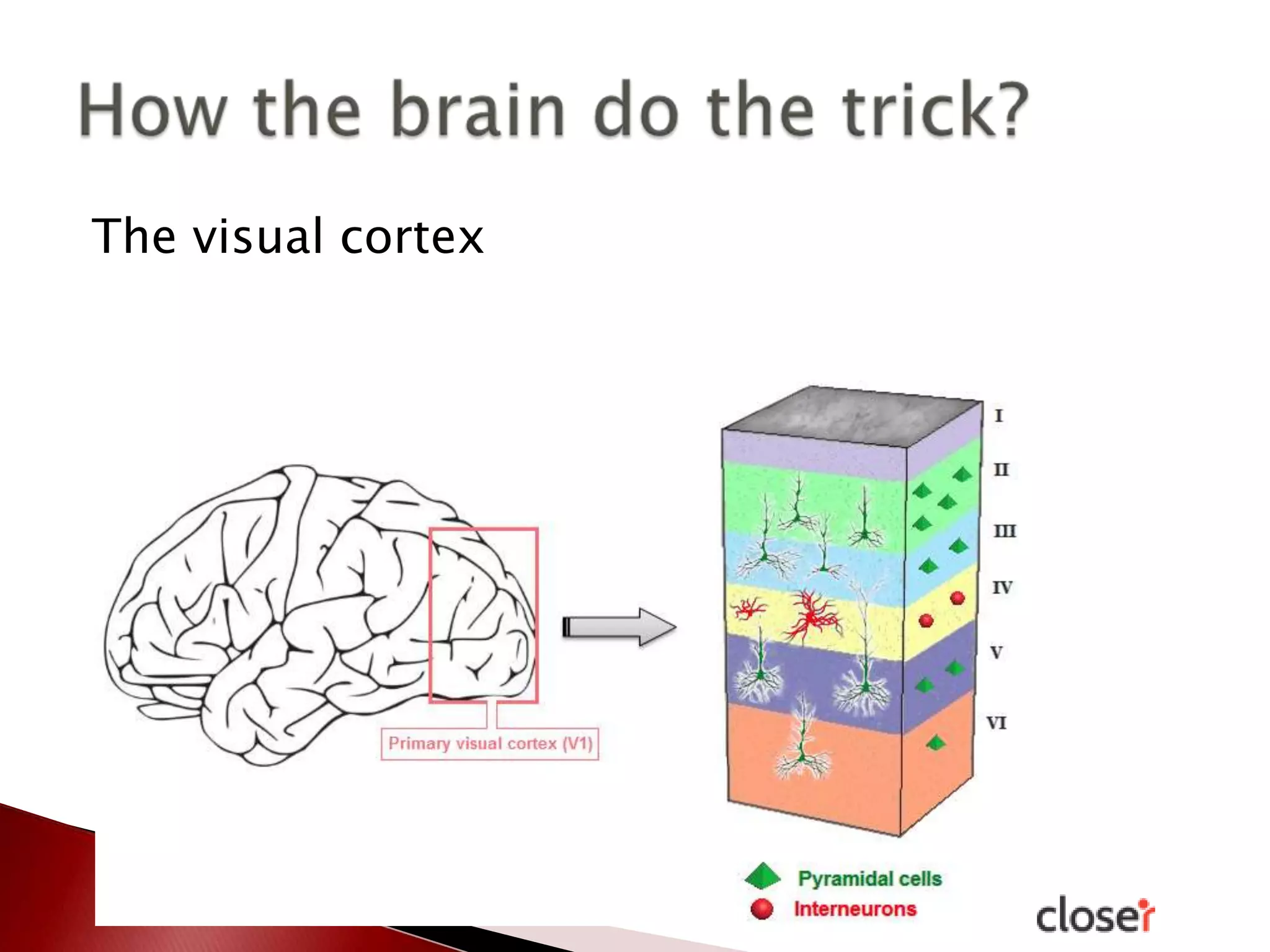
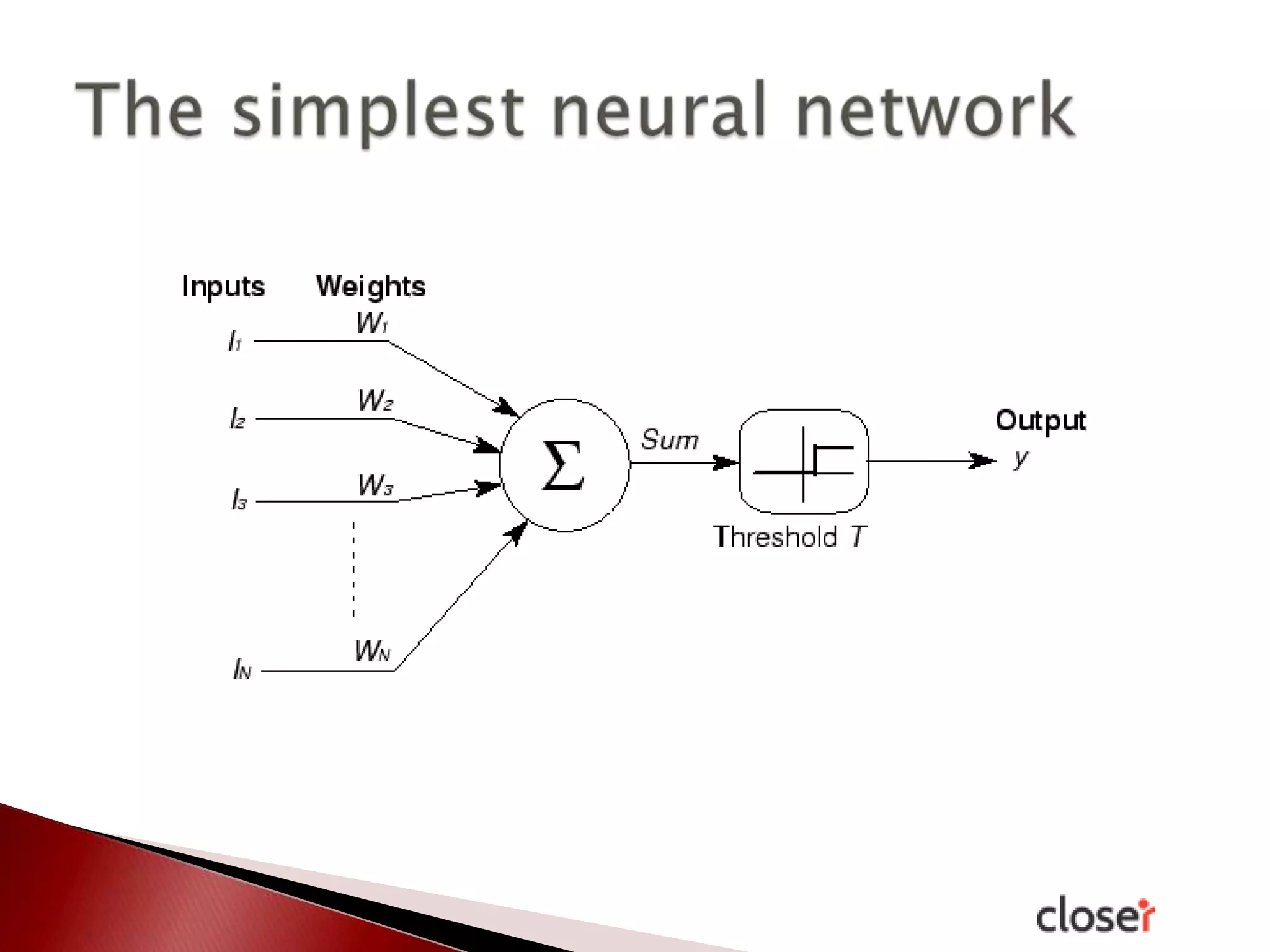
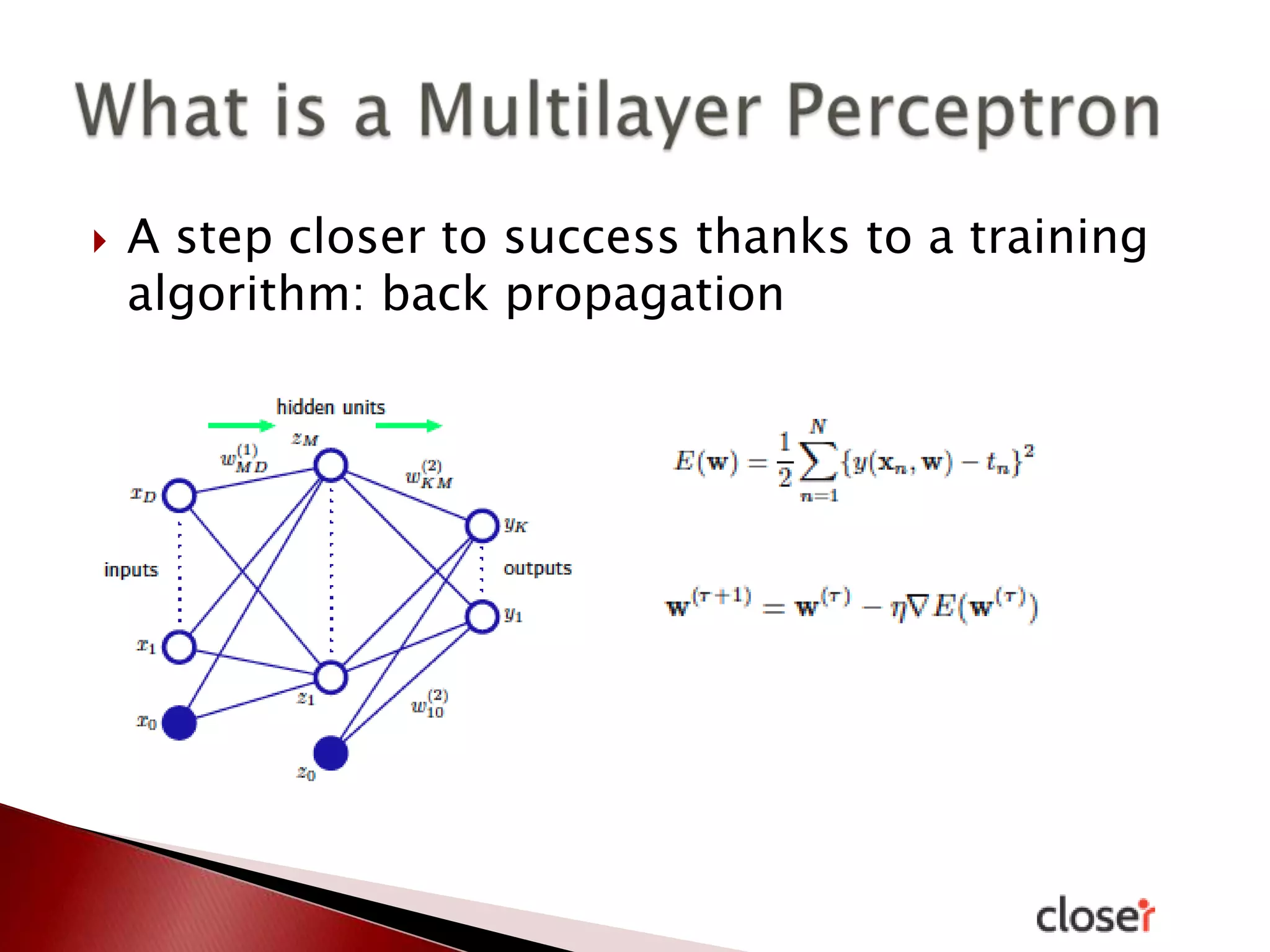

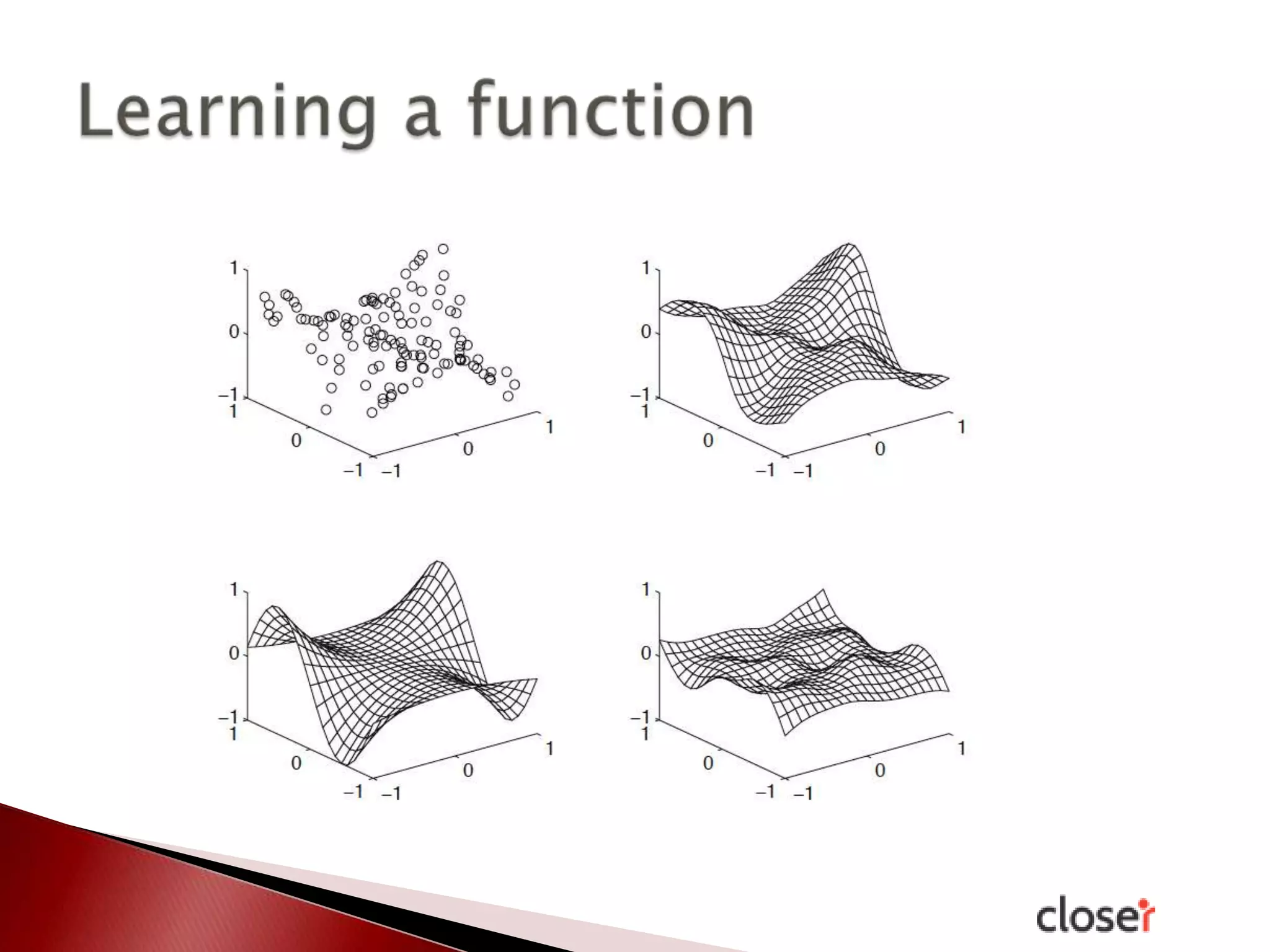


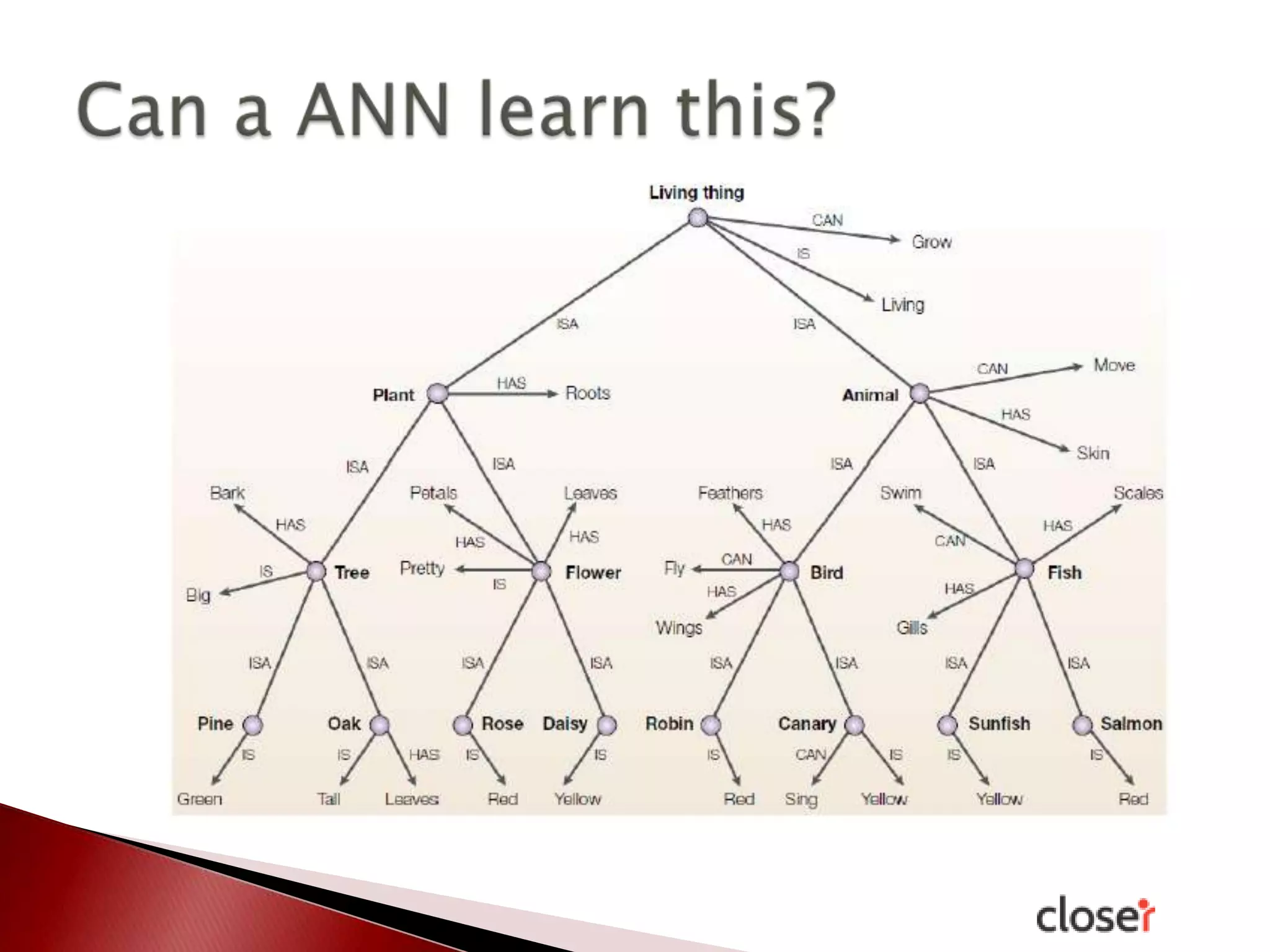
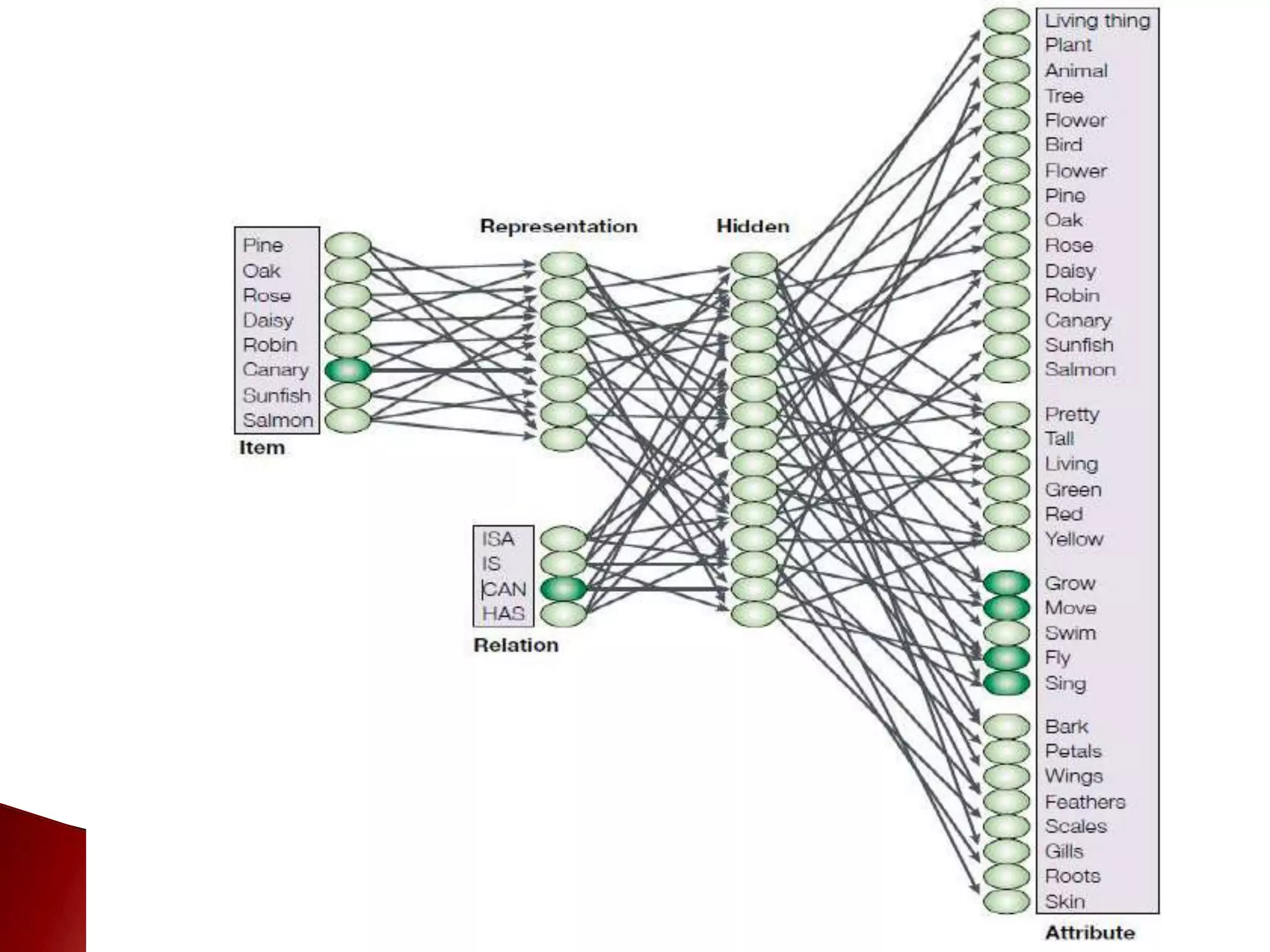
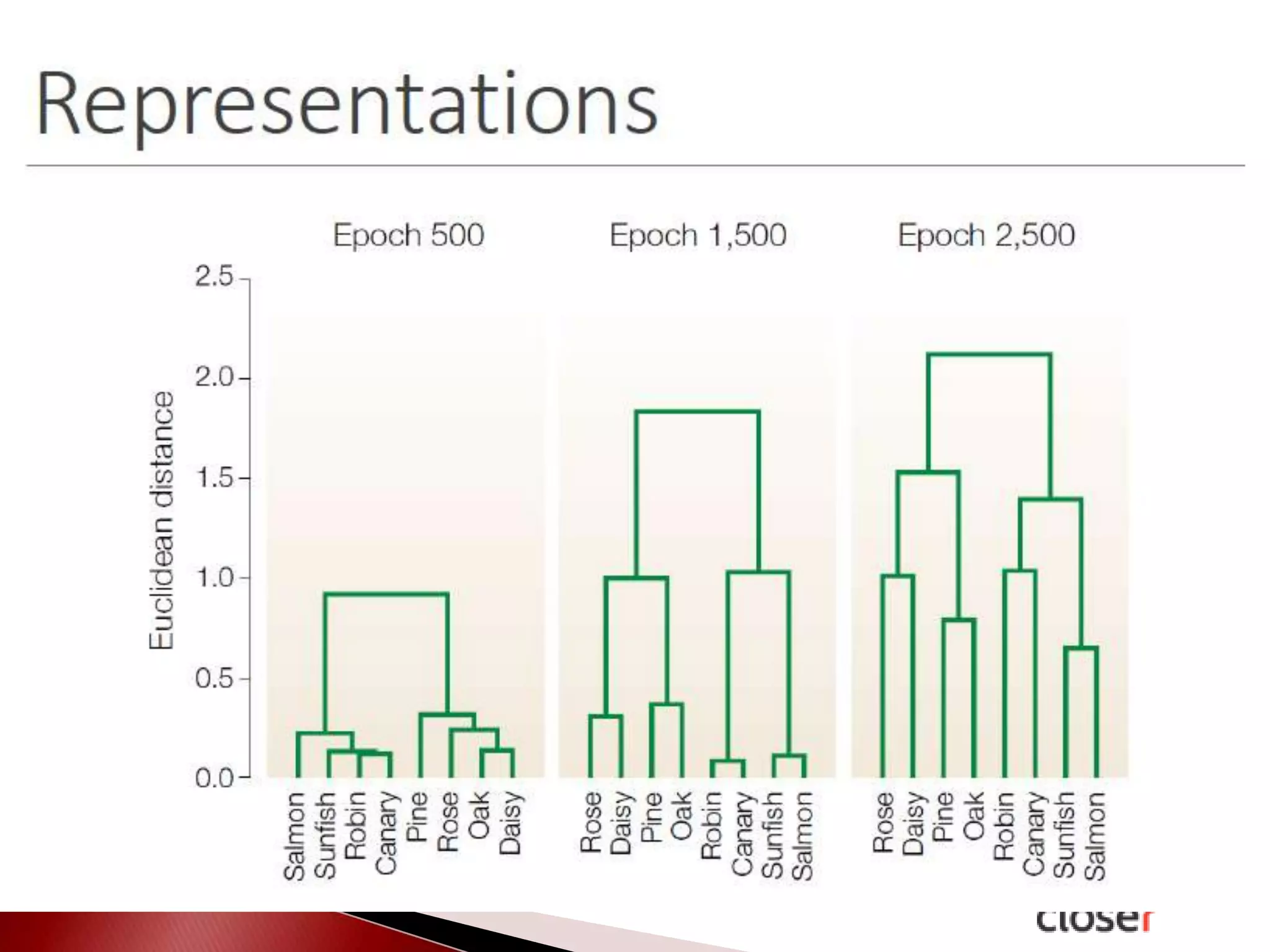
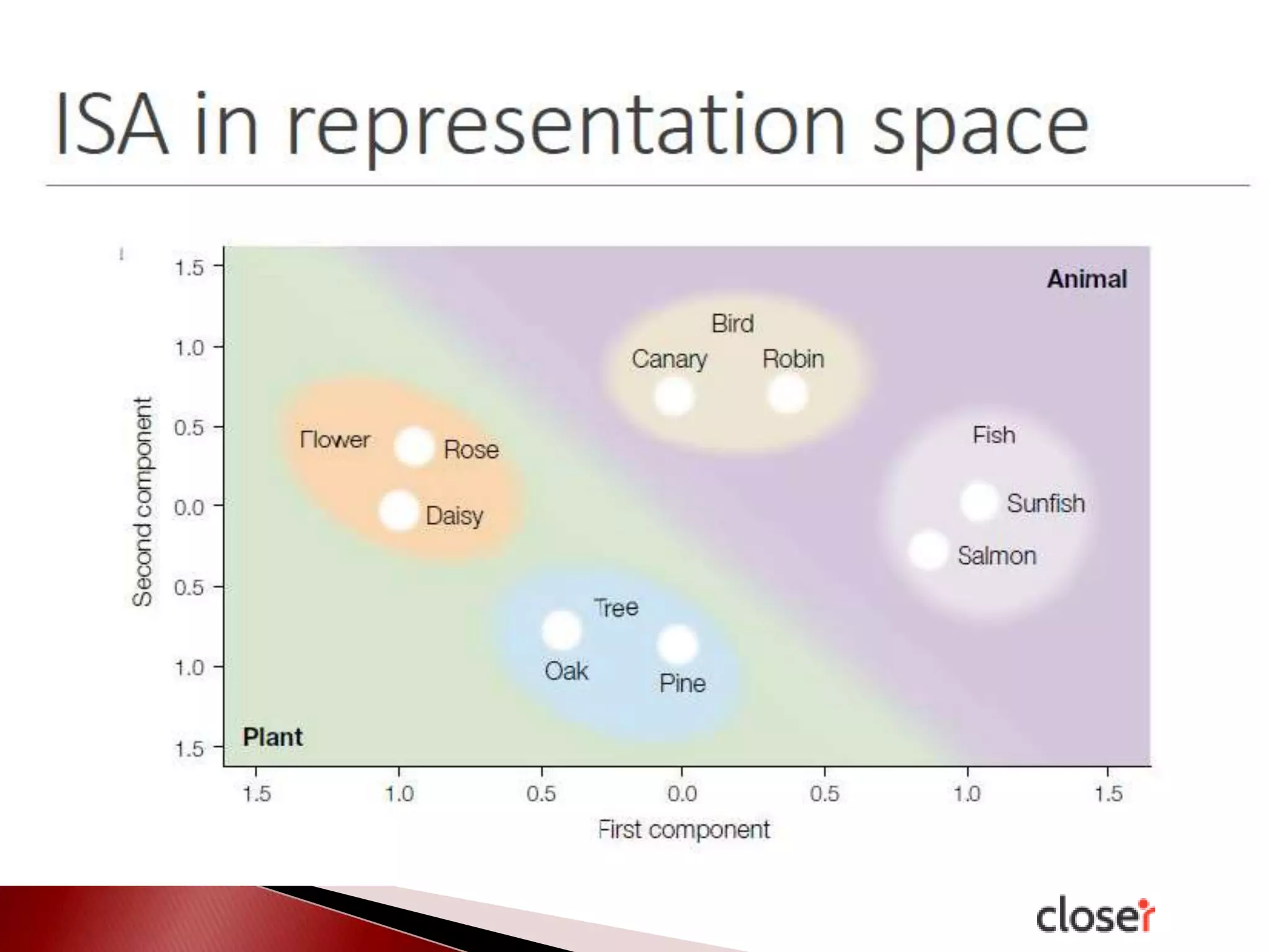
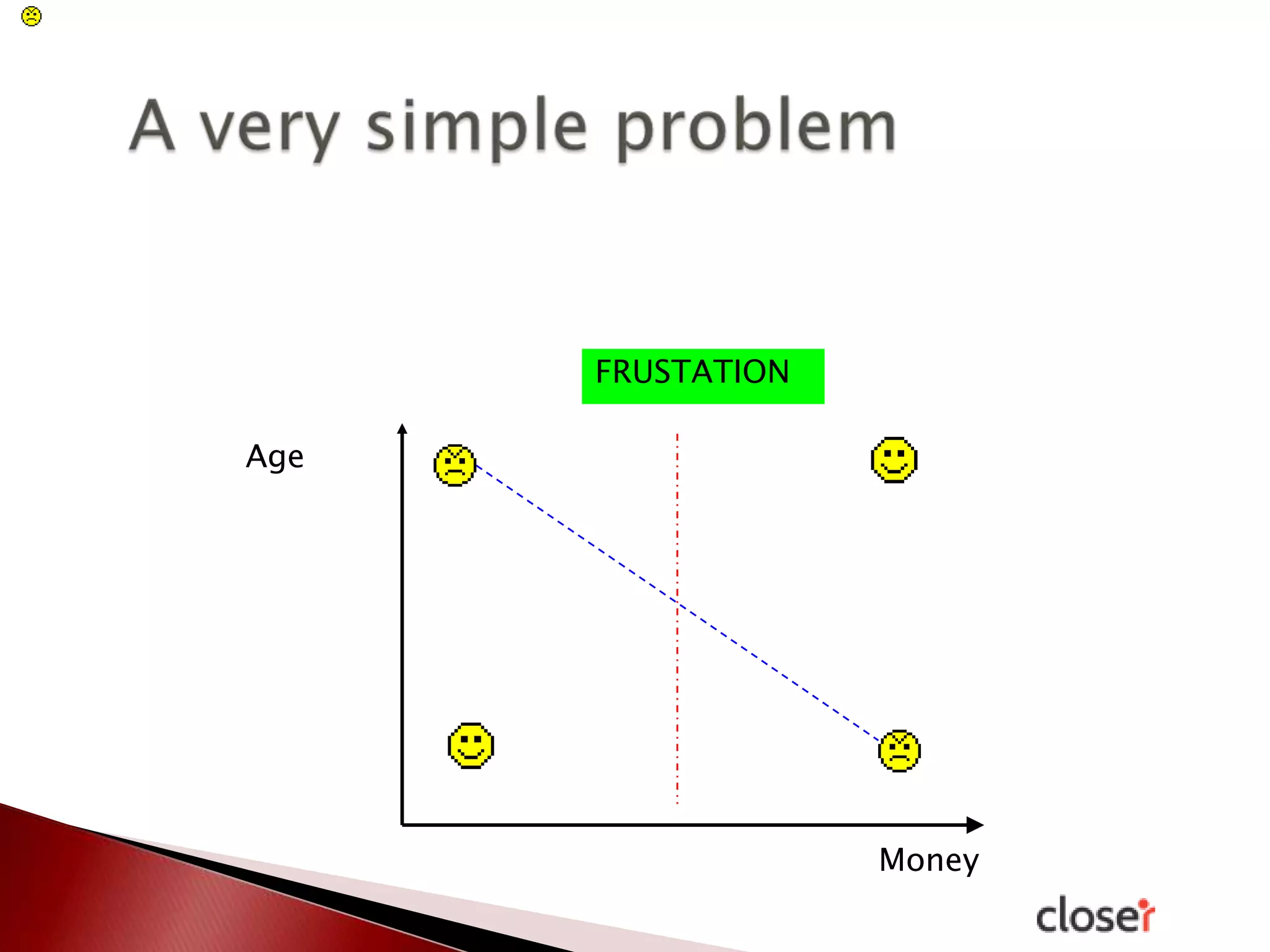
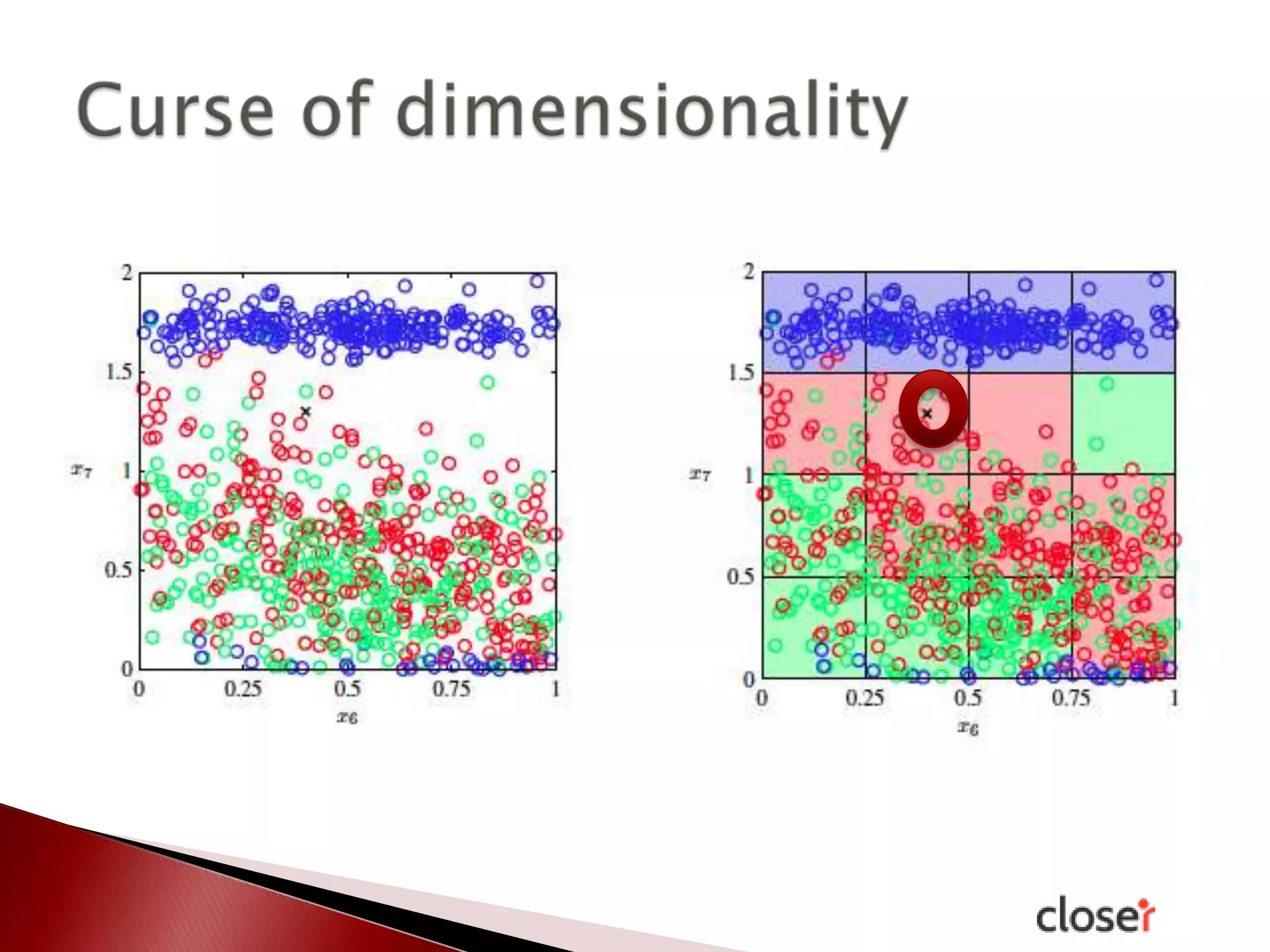
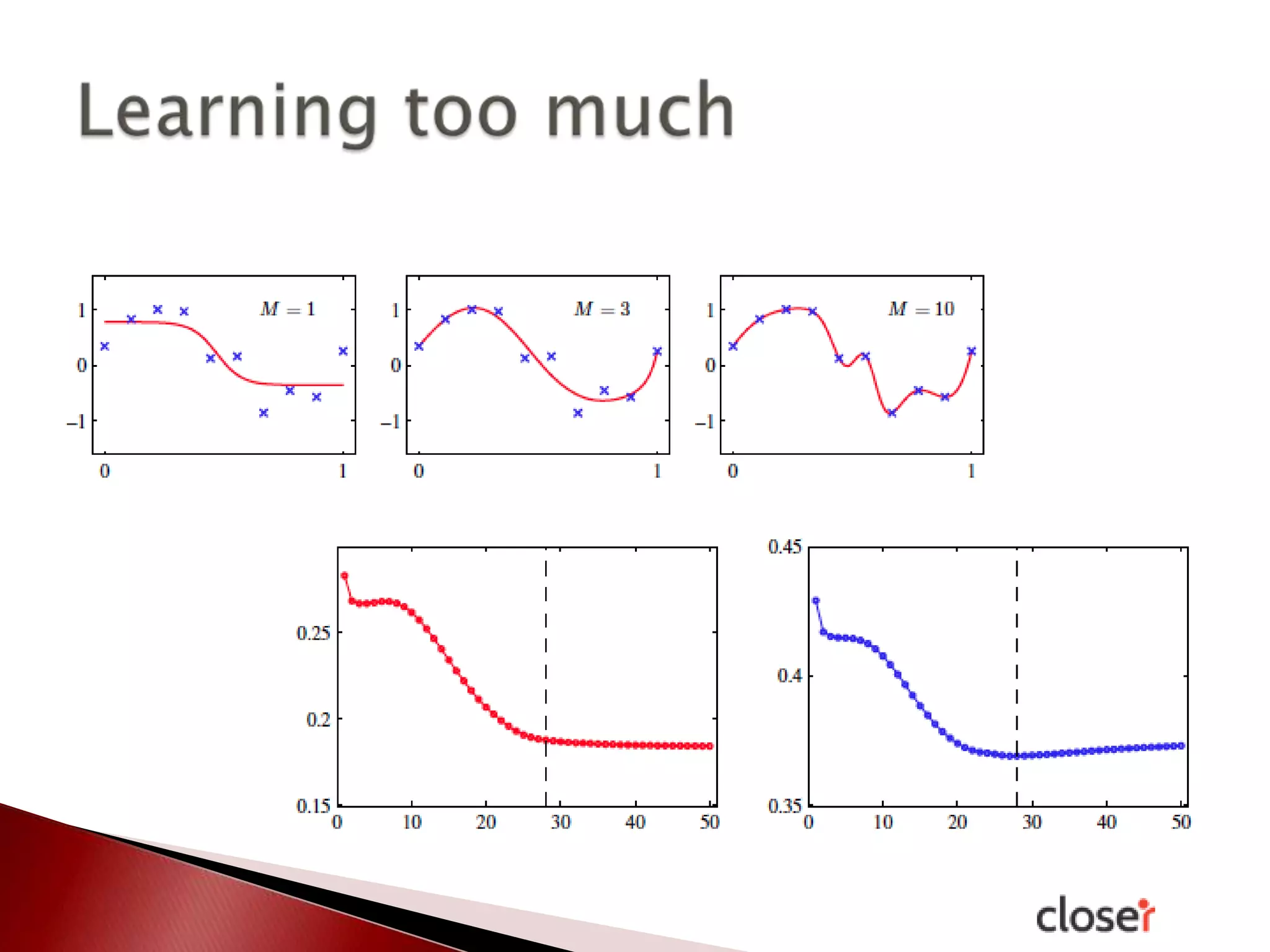
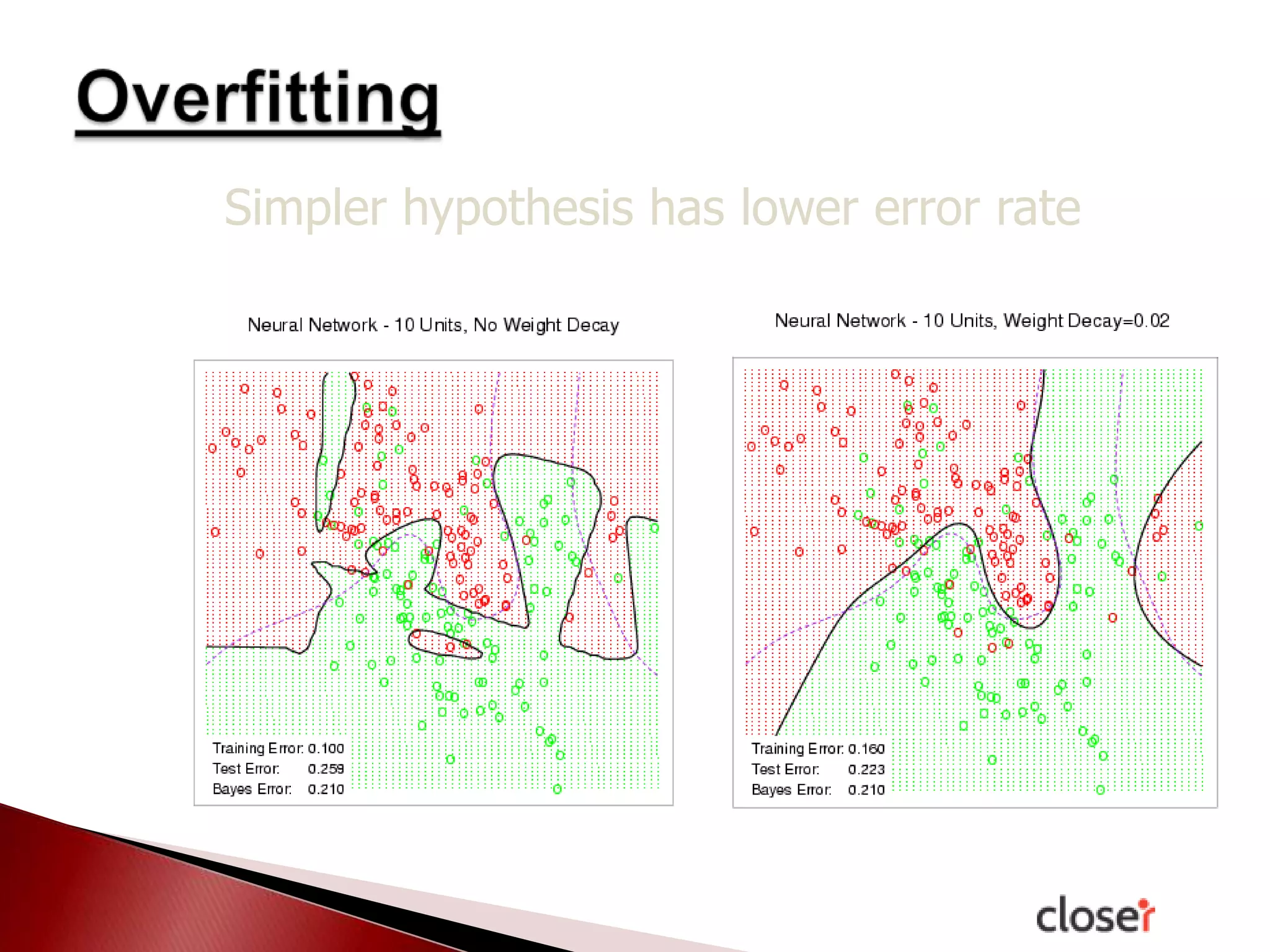

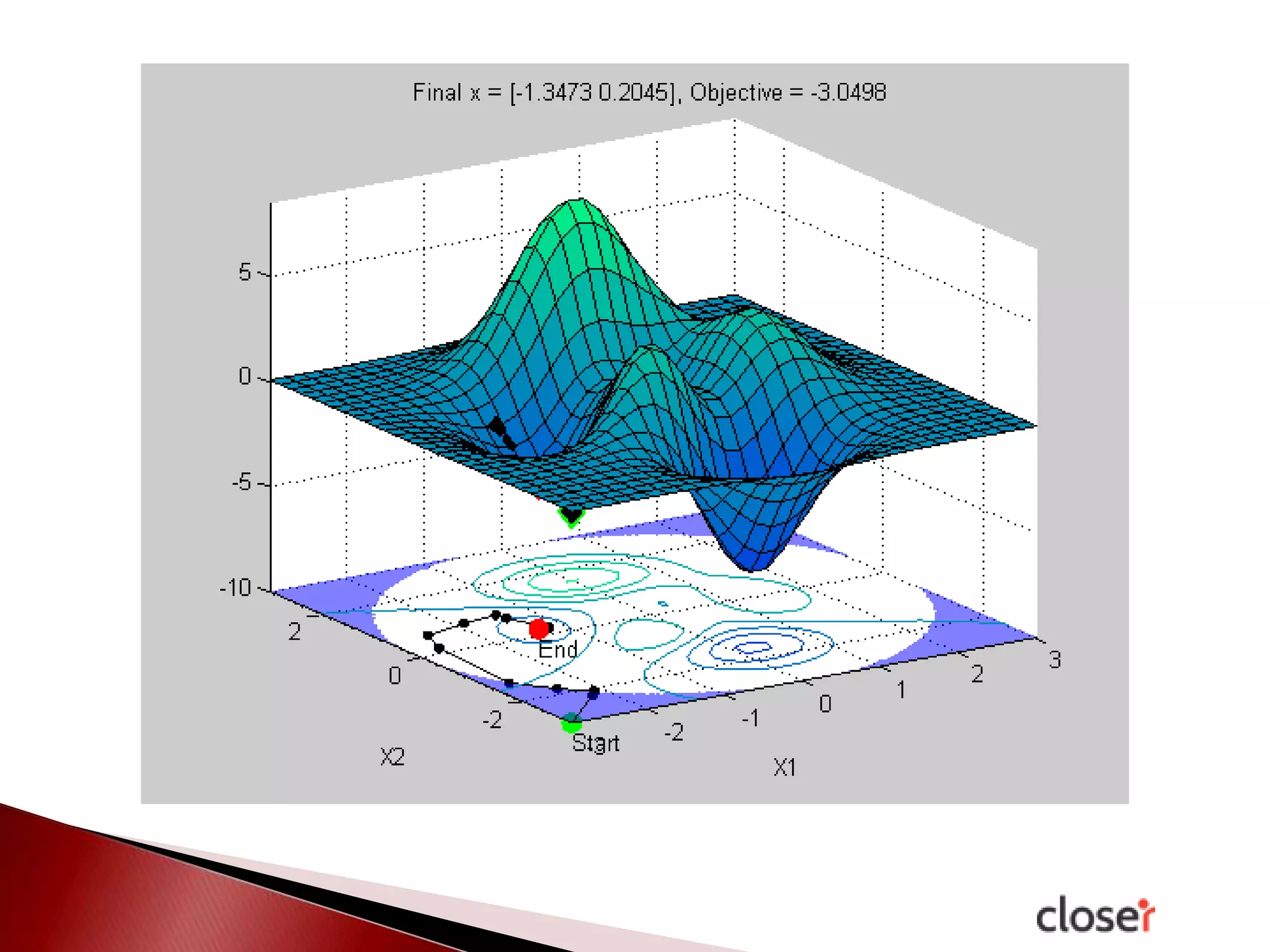





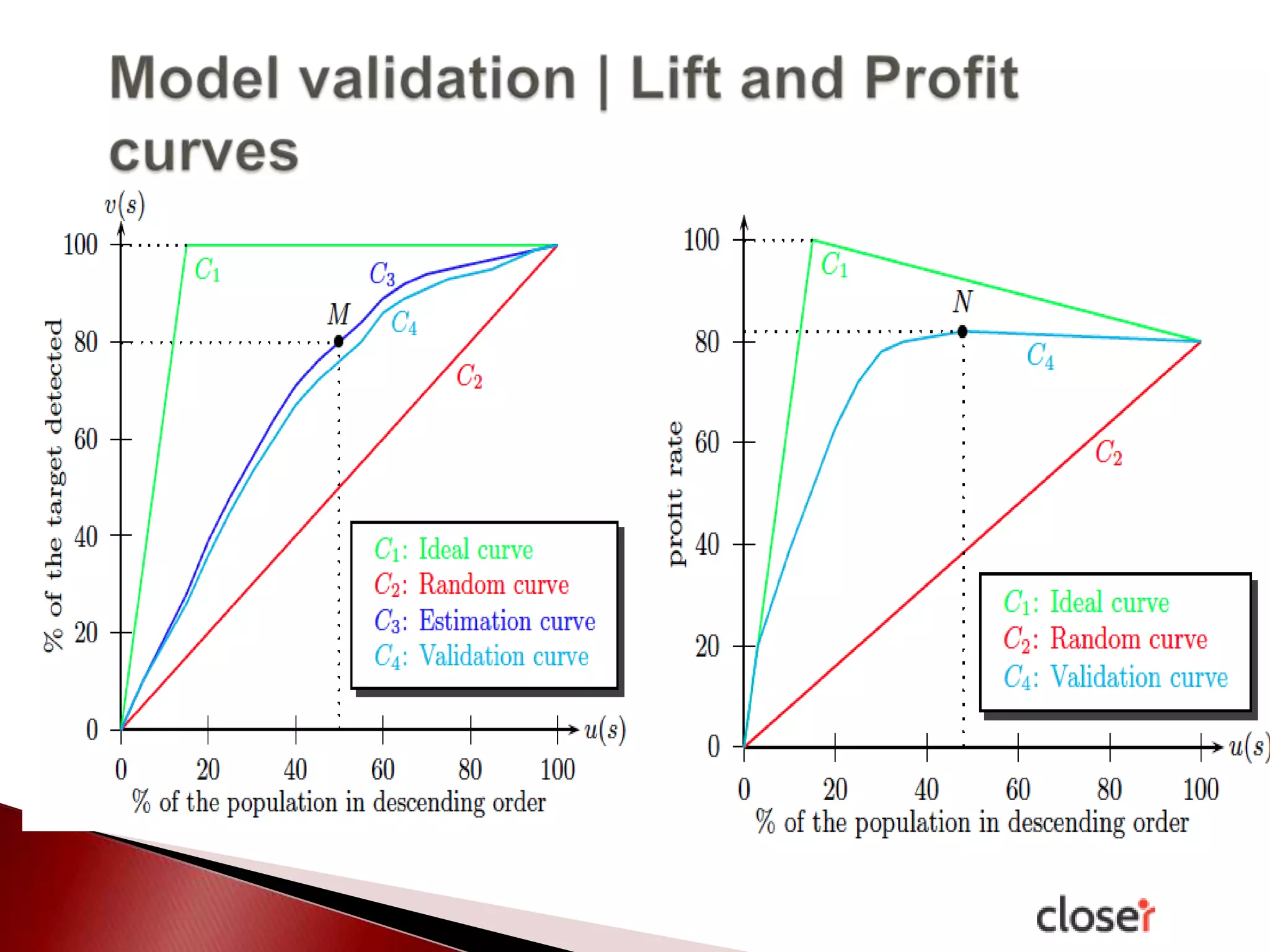
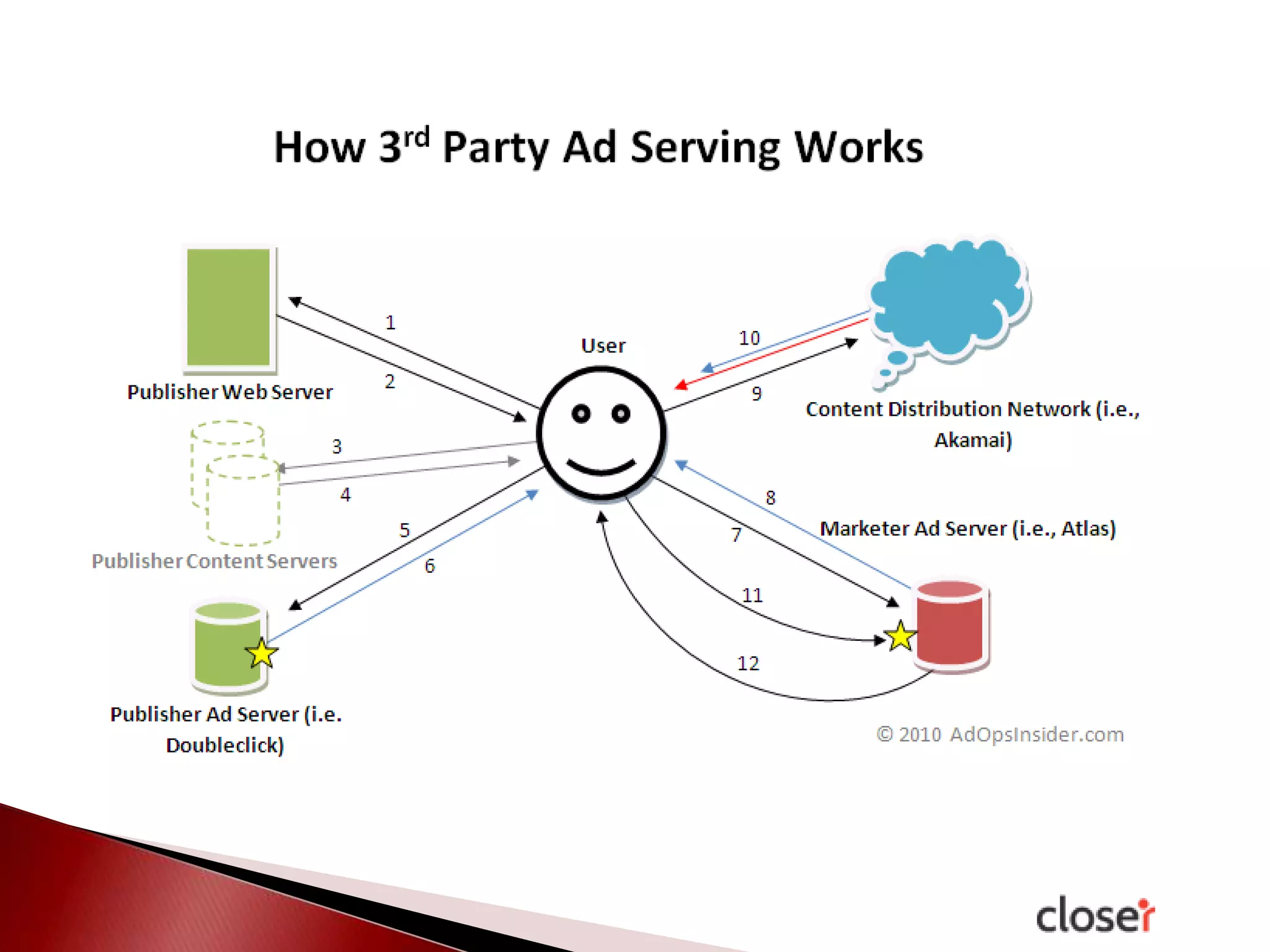

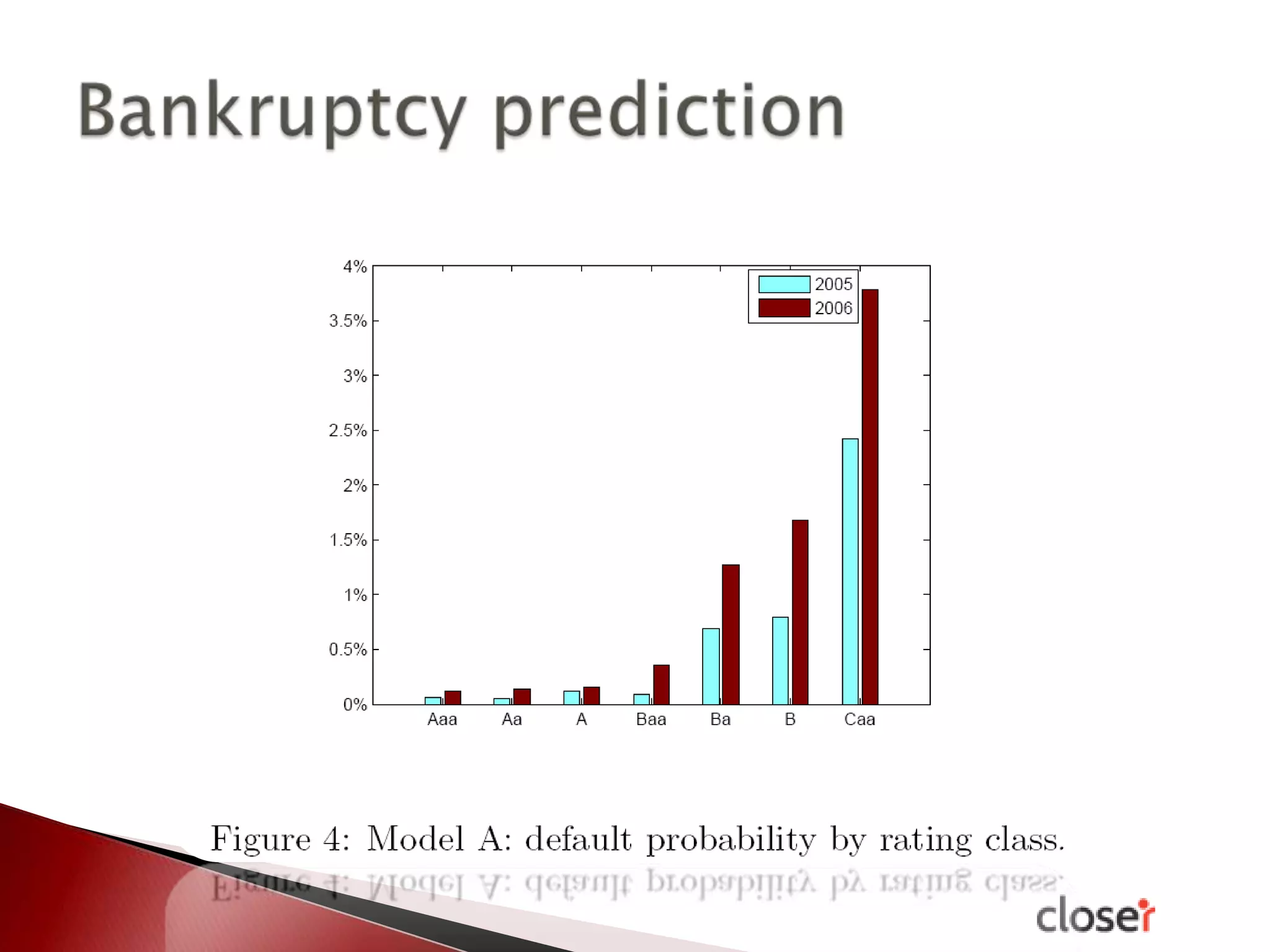
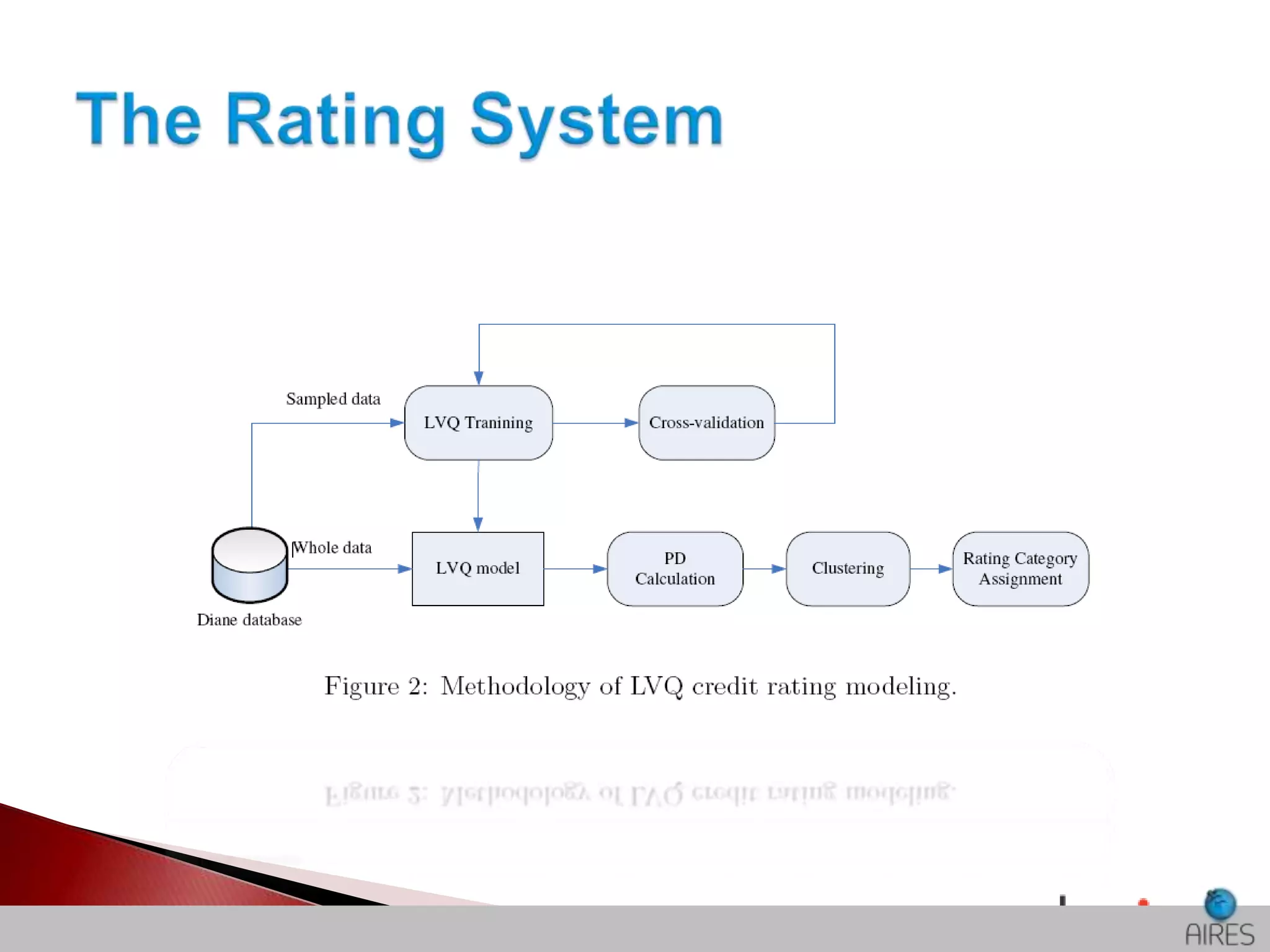
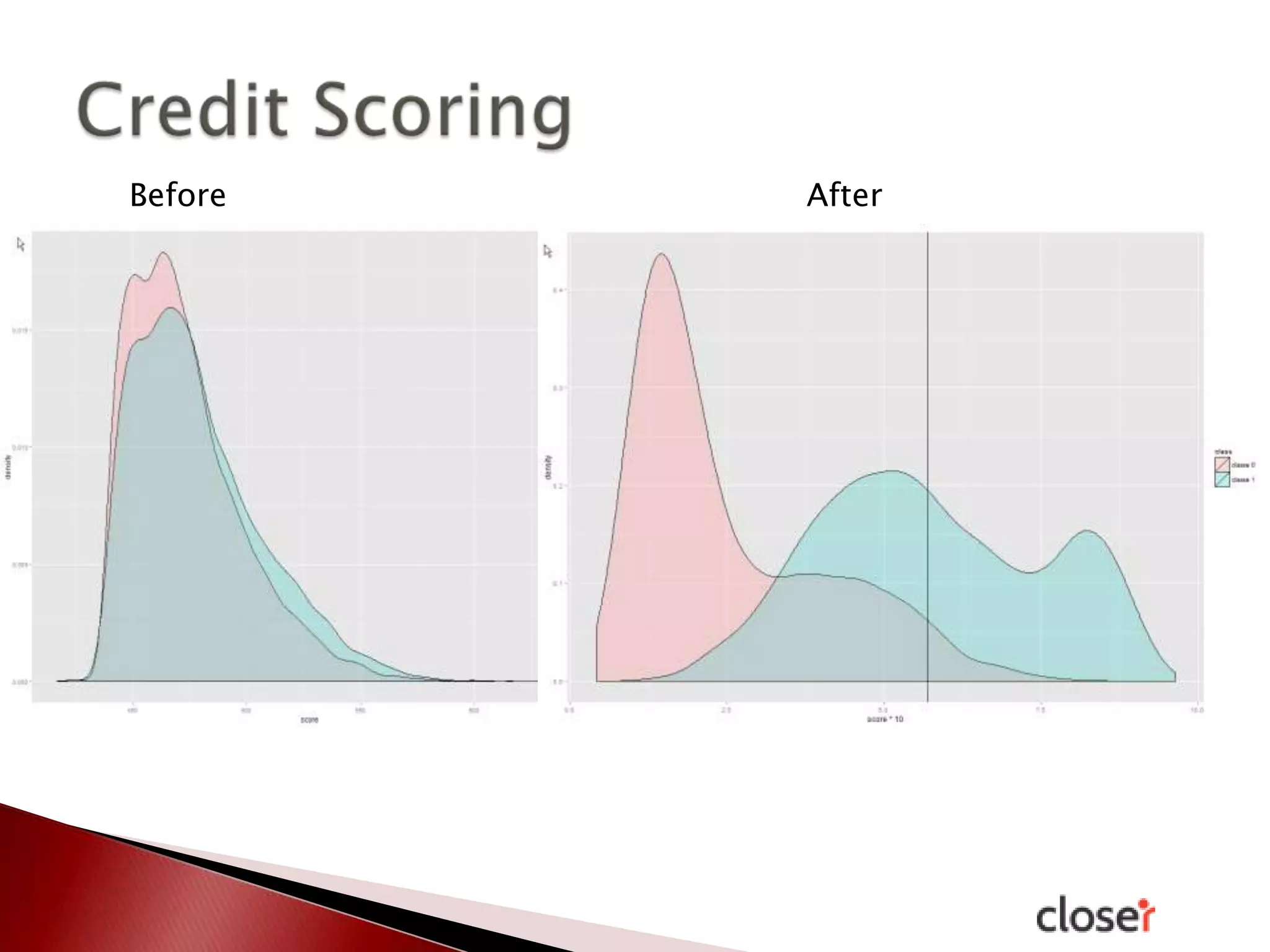





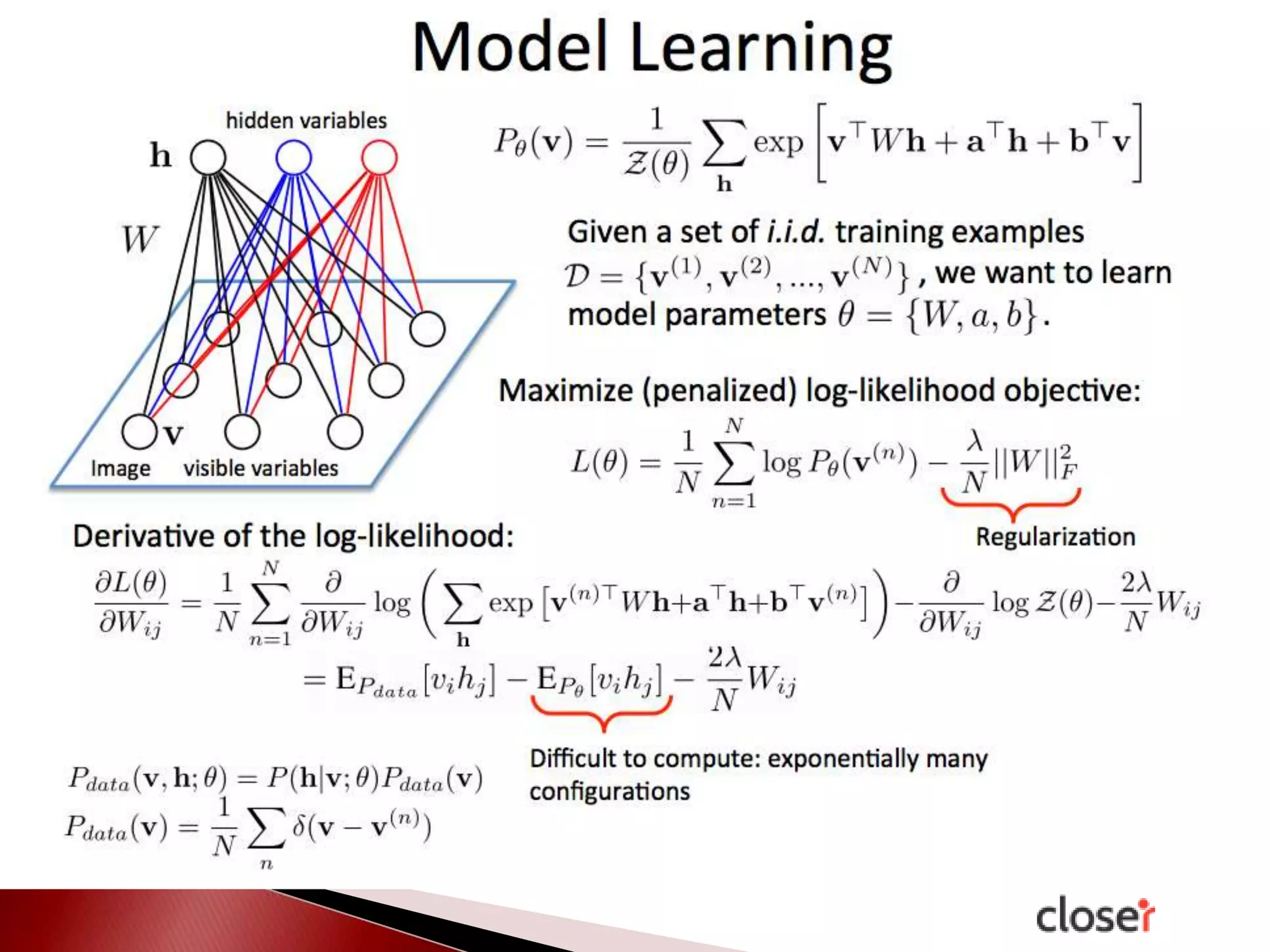
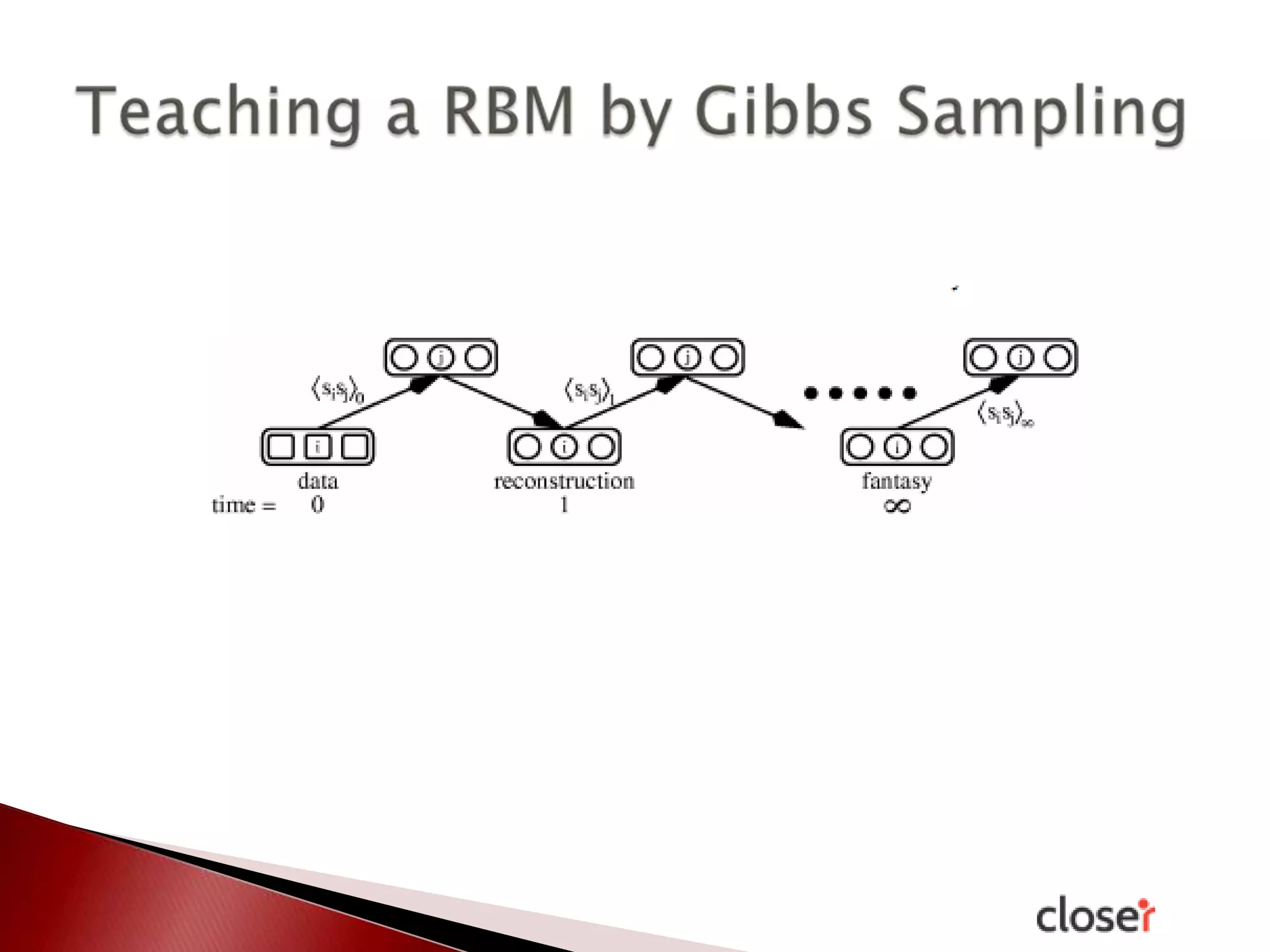

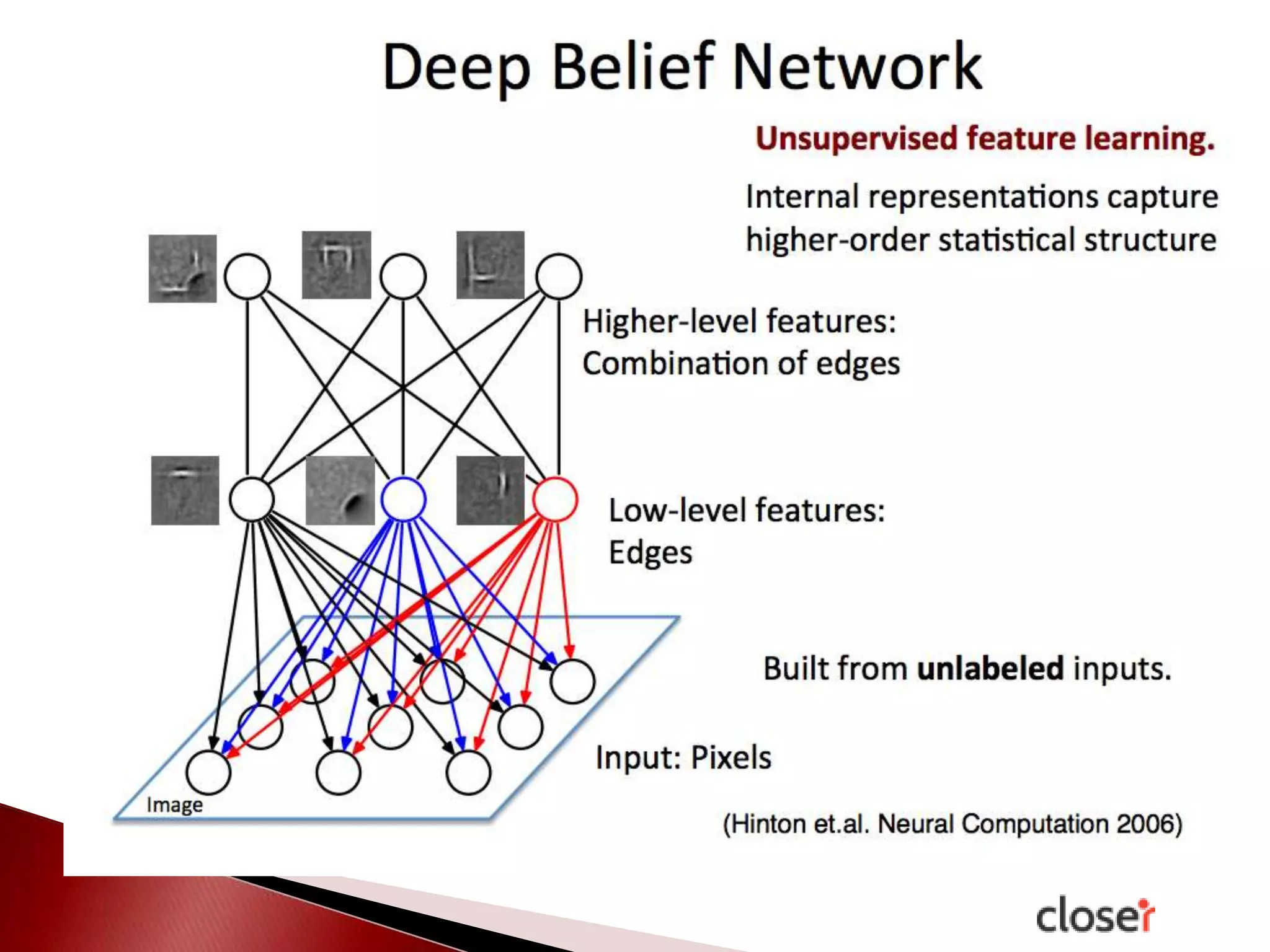
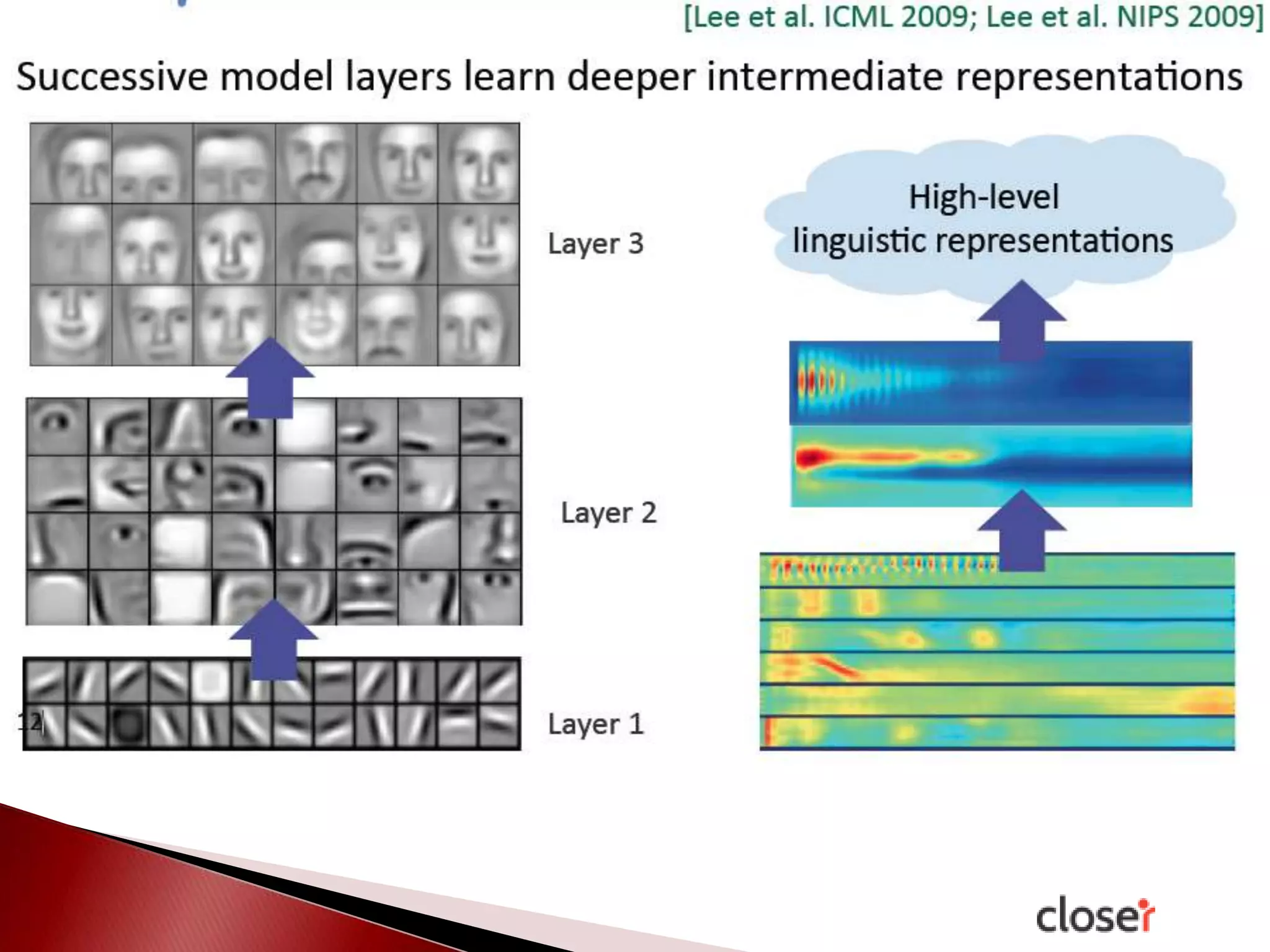
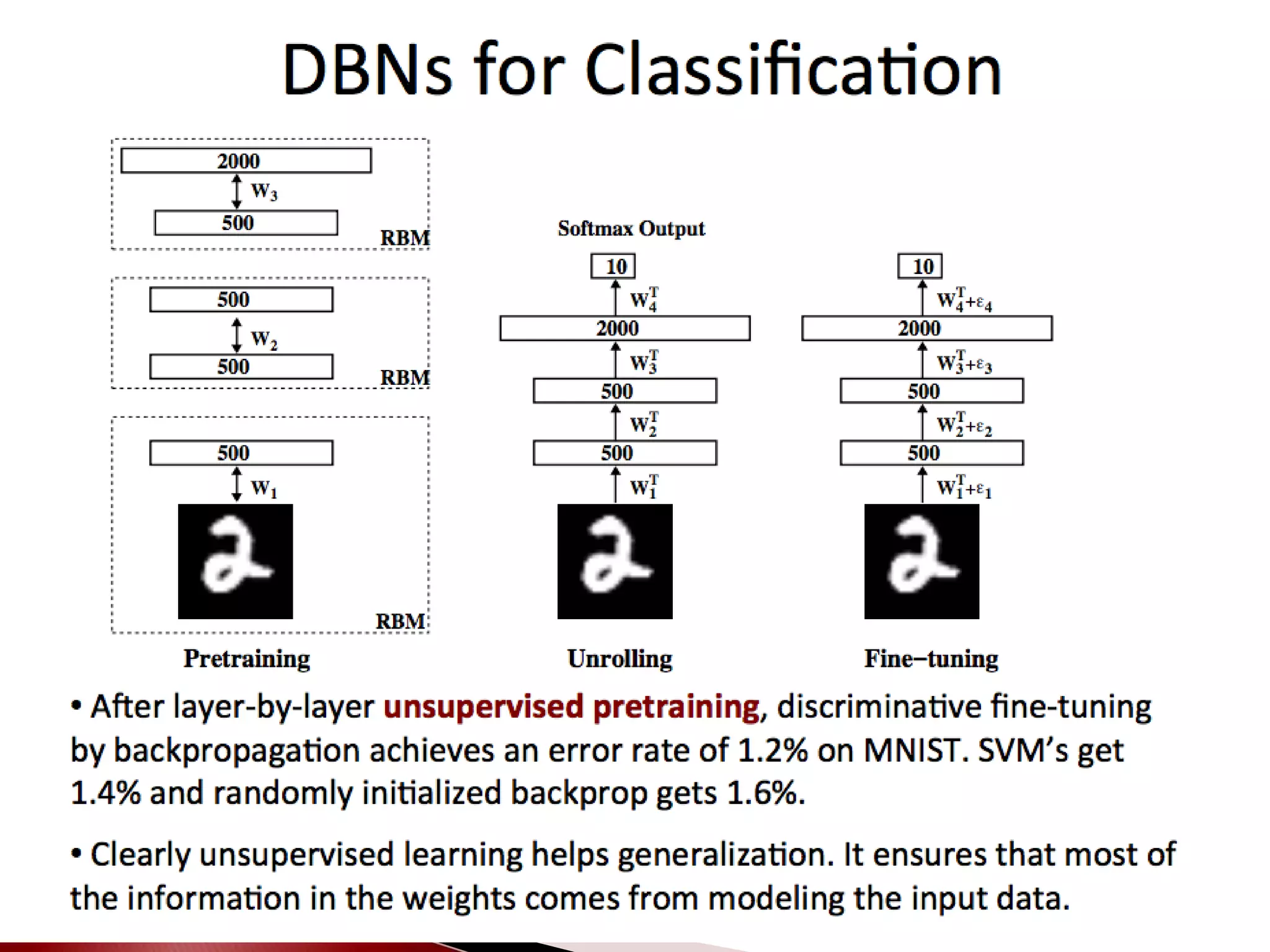
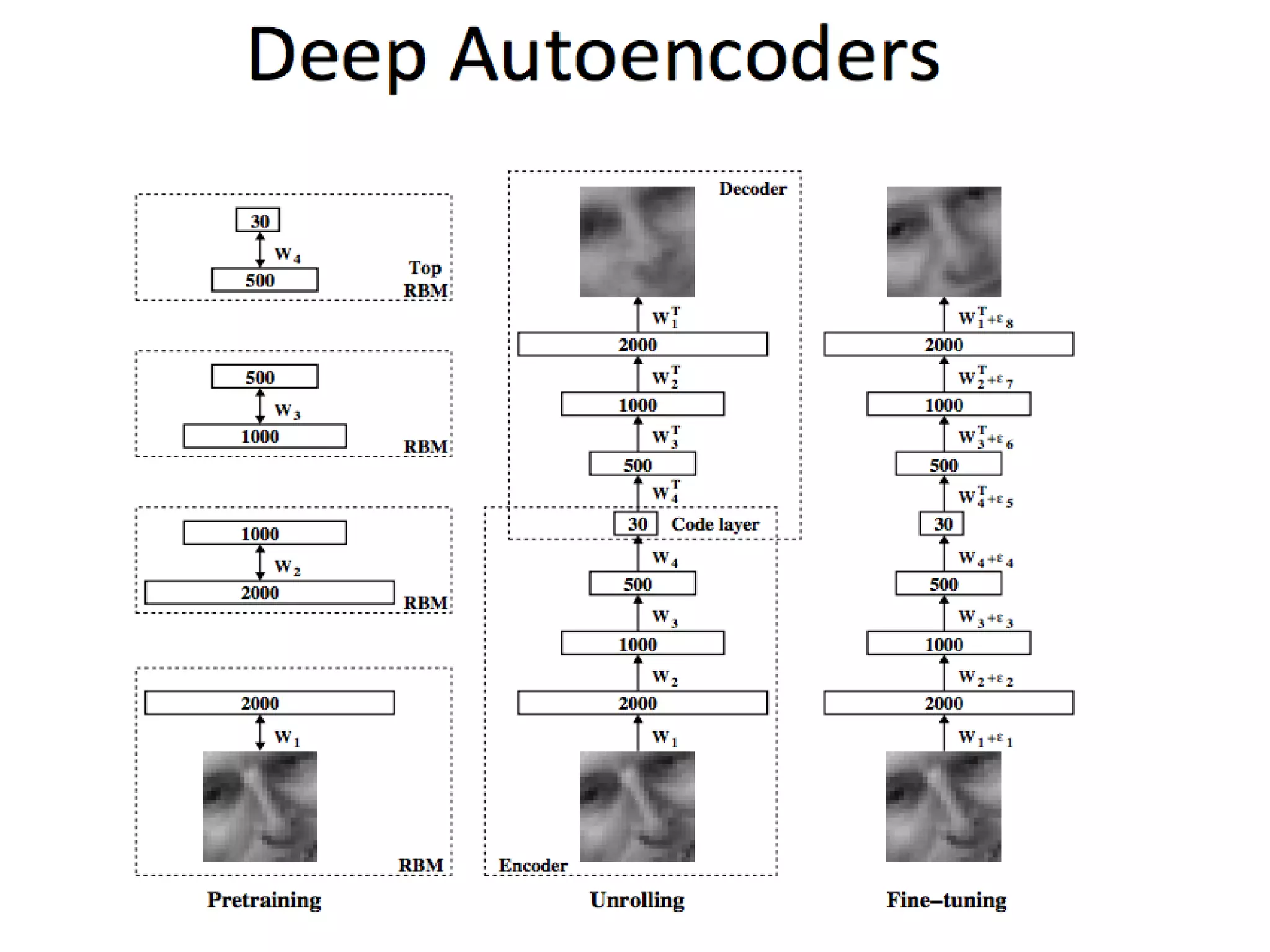


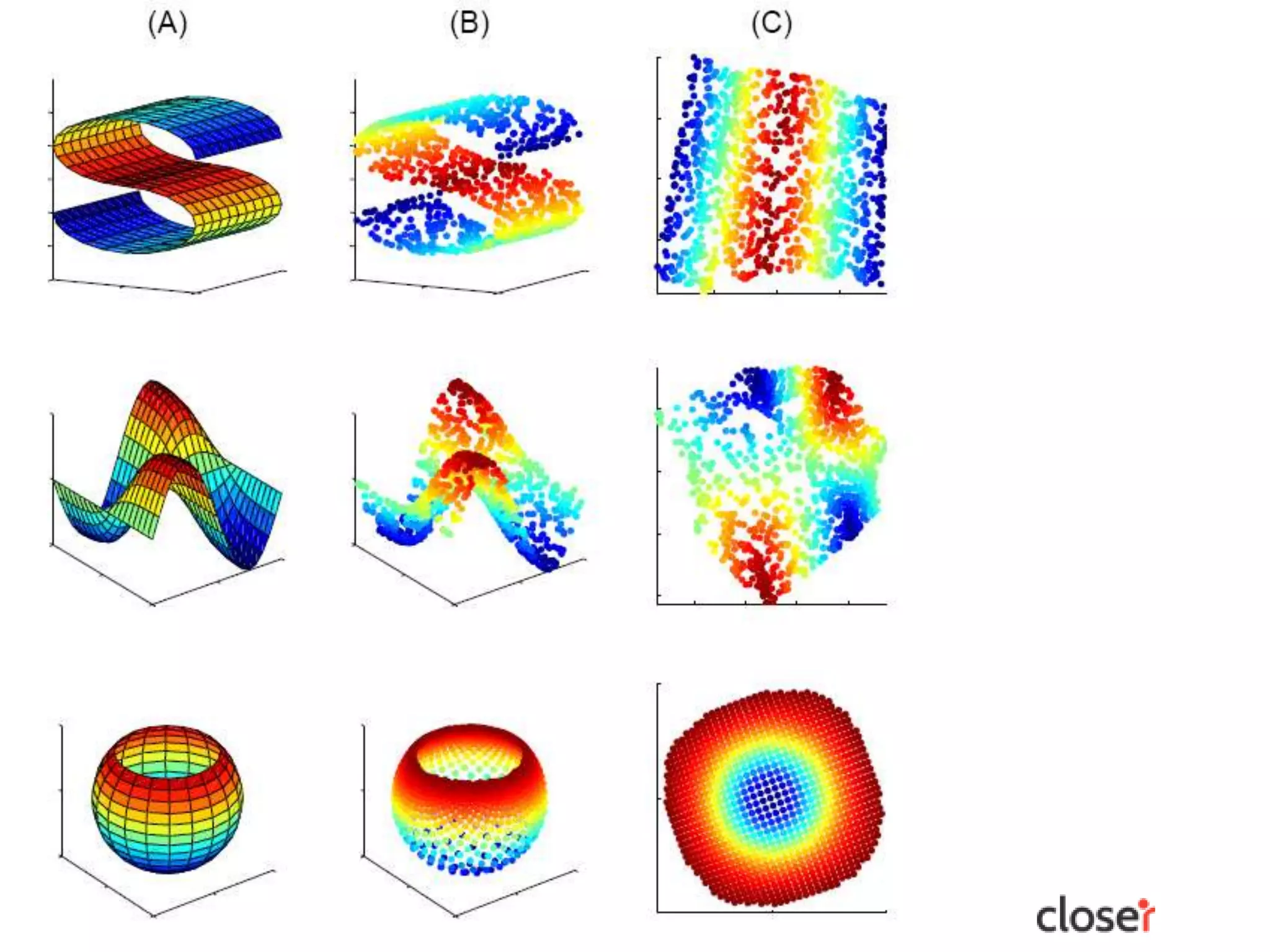




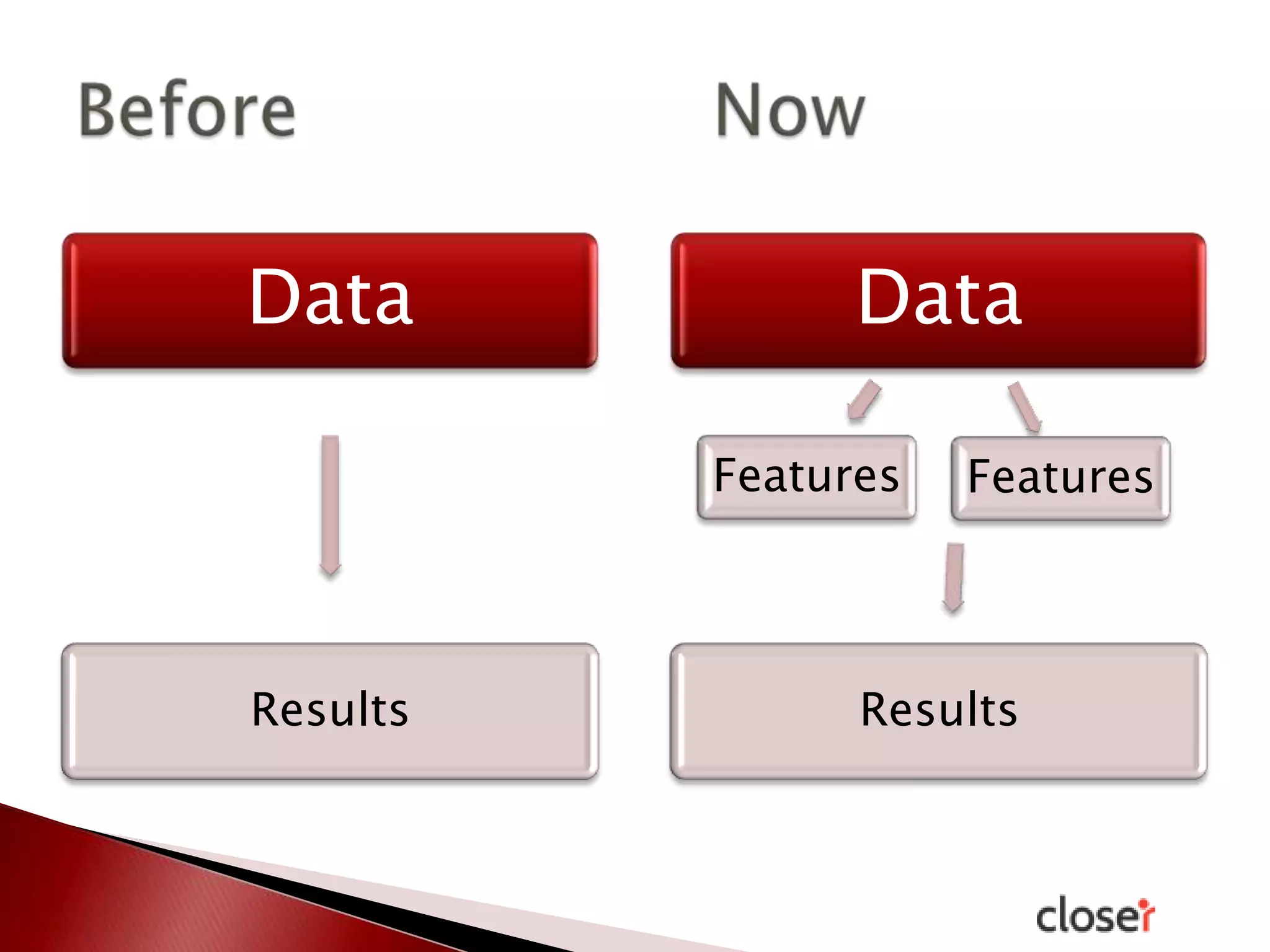

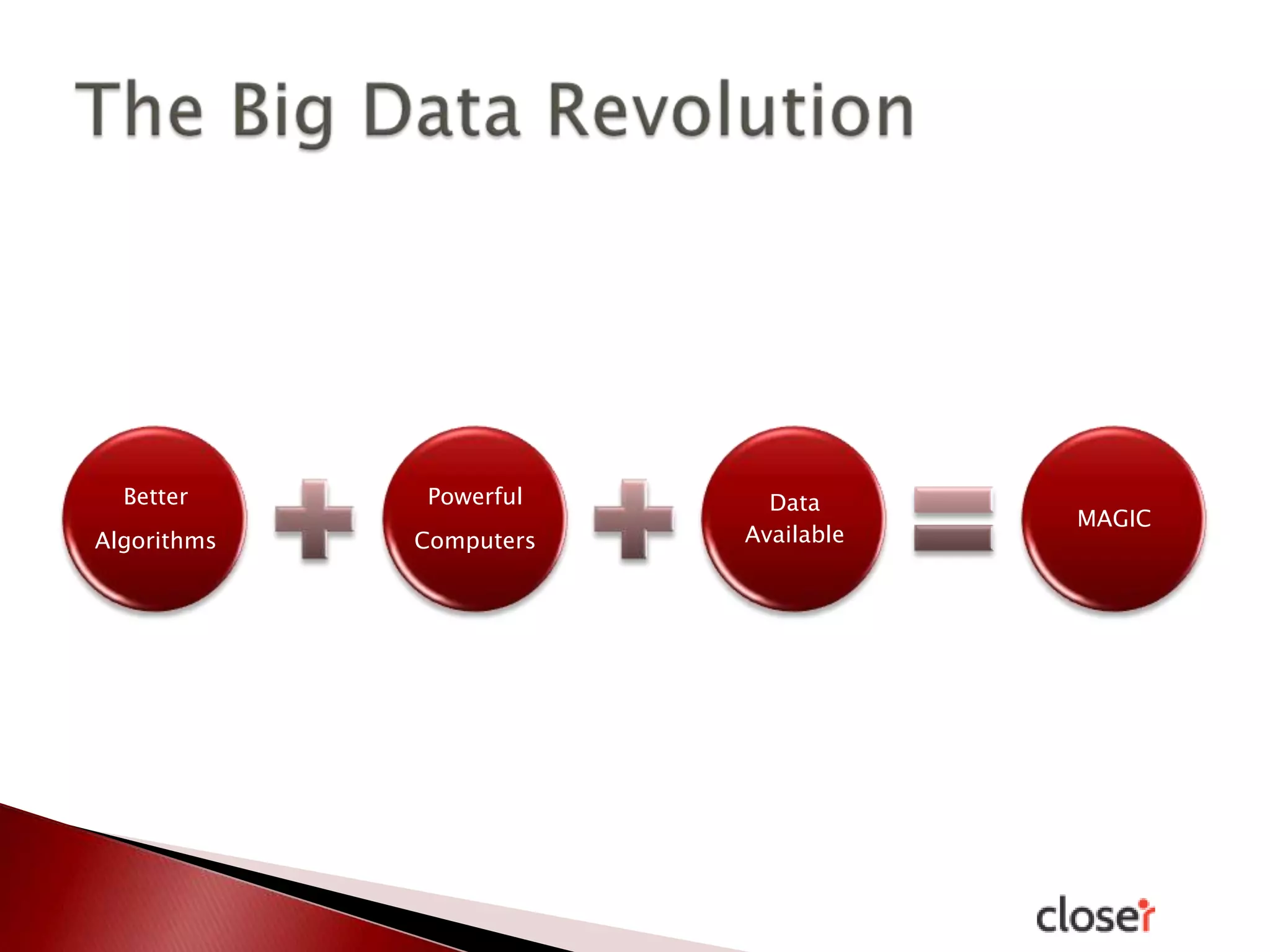

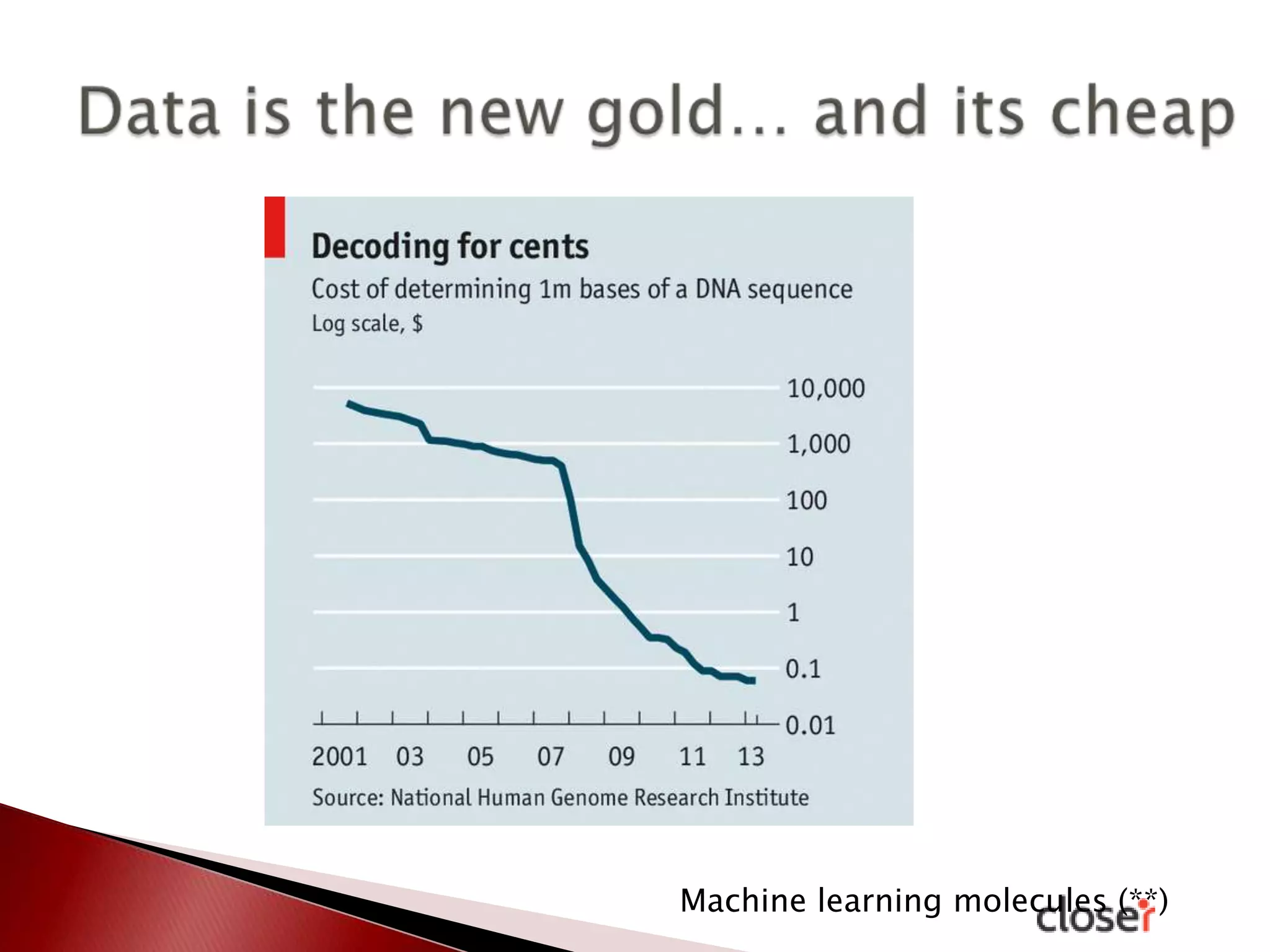








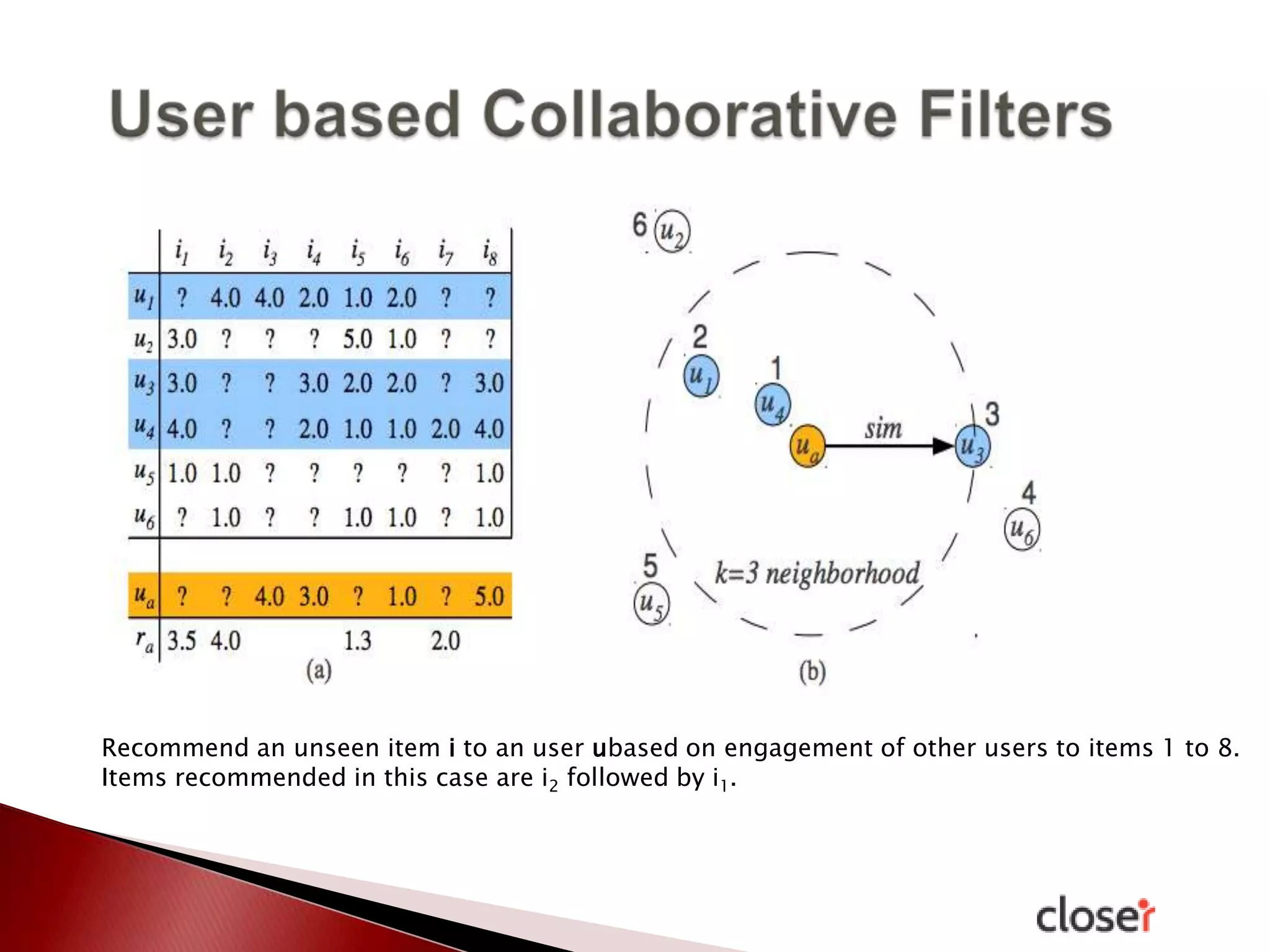


The document discusses the development and applications of machine learning, particularly focusing on neural networks and deep learning. It addresses challenges associated with neural networks, the importance of data in training models, and the capabilities and limitations of these algorithms. The text emphasizes the role of big data in transforming industries and highlights the need for careful interpretation of machine learning outputs.








![[Webinar] How Big Data and Machine Learning Are Transforming ITSM](https://cdn.slidesharecdn.com/ss_thumbnails/webinarhowbigdataandmachinelearningaretransformingitsm-160602174503-thumbnail.jpg?width=640&height=640&fit=bounds)


































































































