Download as PDF, PPTX








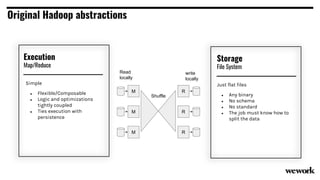

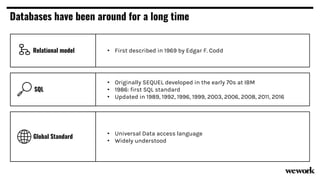

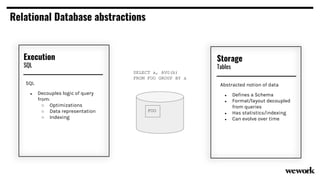
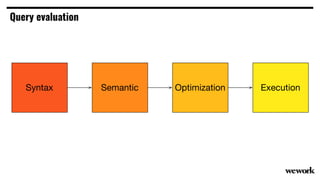
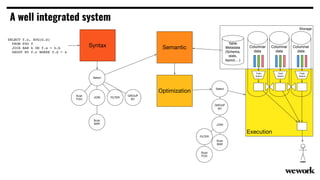


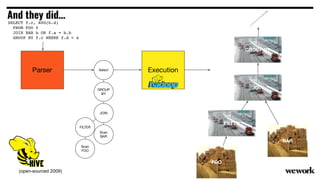


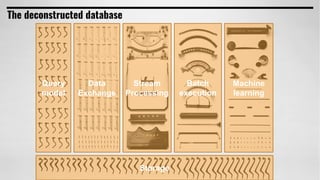
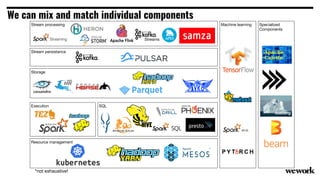
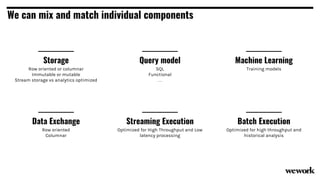


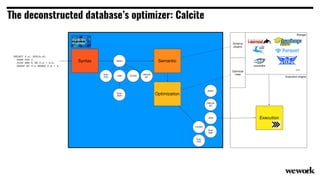

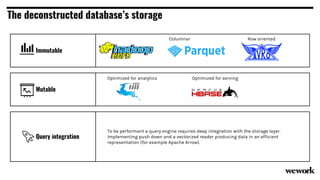




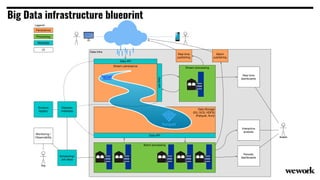

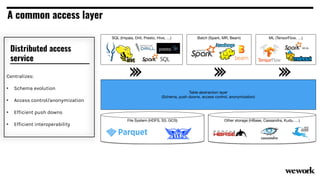
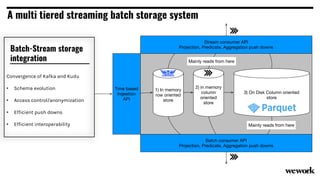




From flat files to deconstructed databases: - Originally, Hadoop used flat files and MapReduce which was flexible but inefficient for queries. - The database world used SQL and relational models with optimizations but were inflexible. - Now components like storage, processing, and machine learning can be mixed and matched more efficiently with standards like Apache Calcite, Parquet, Avro and Arrow.























































































