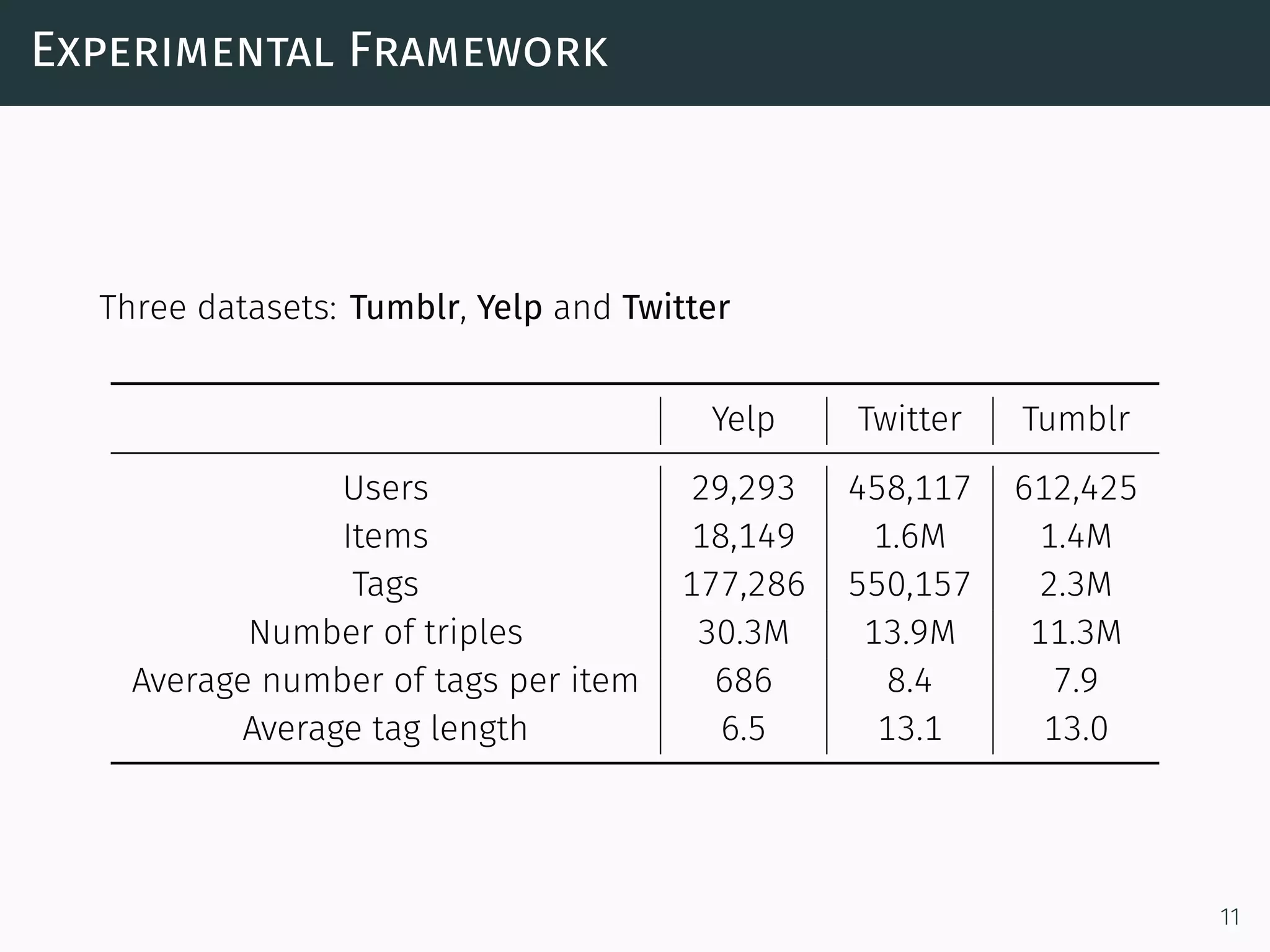
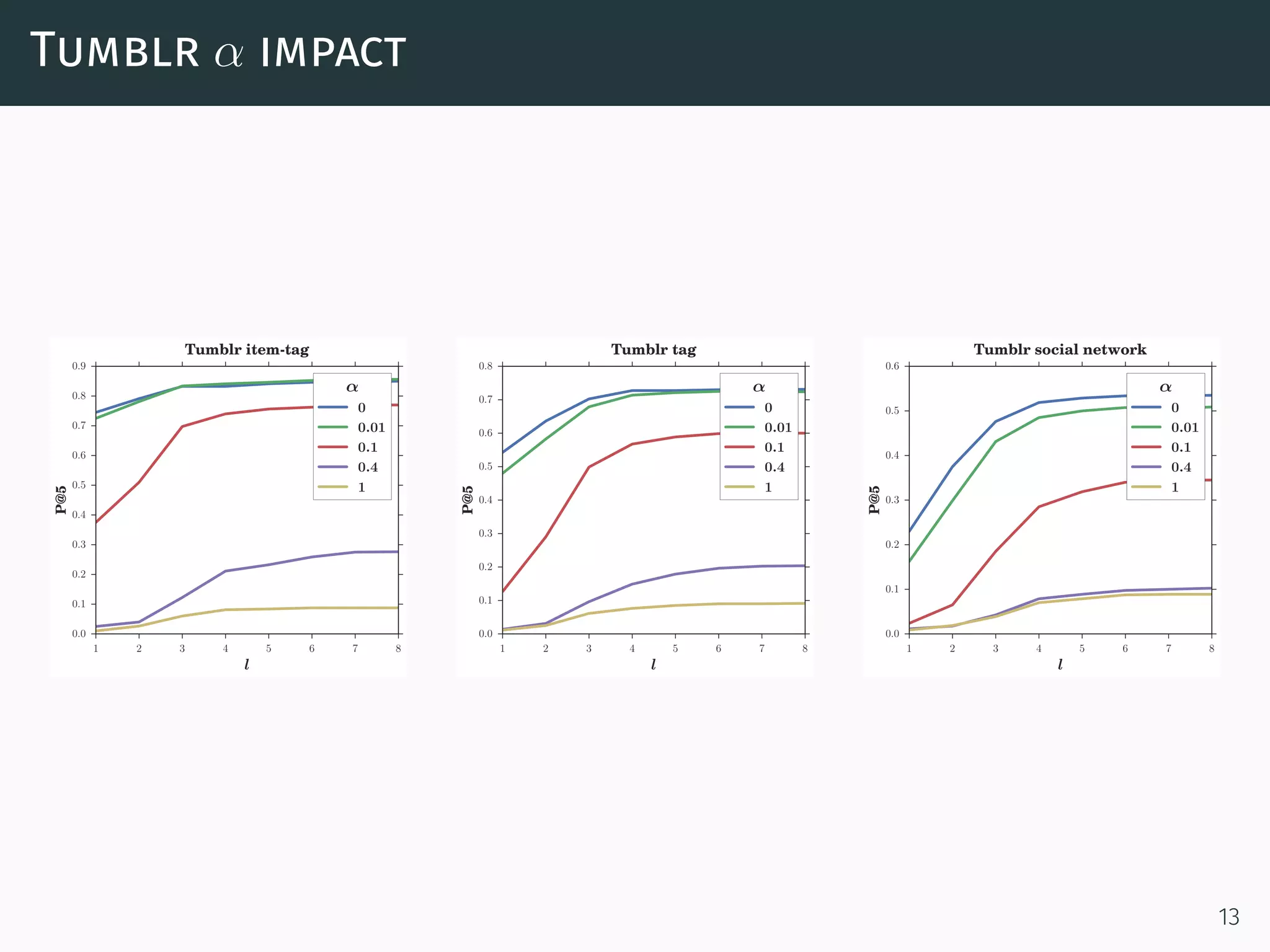
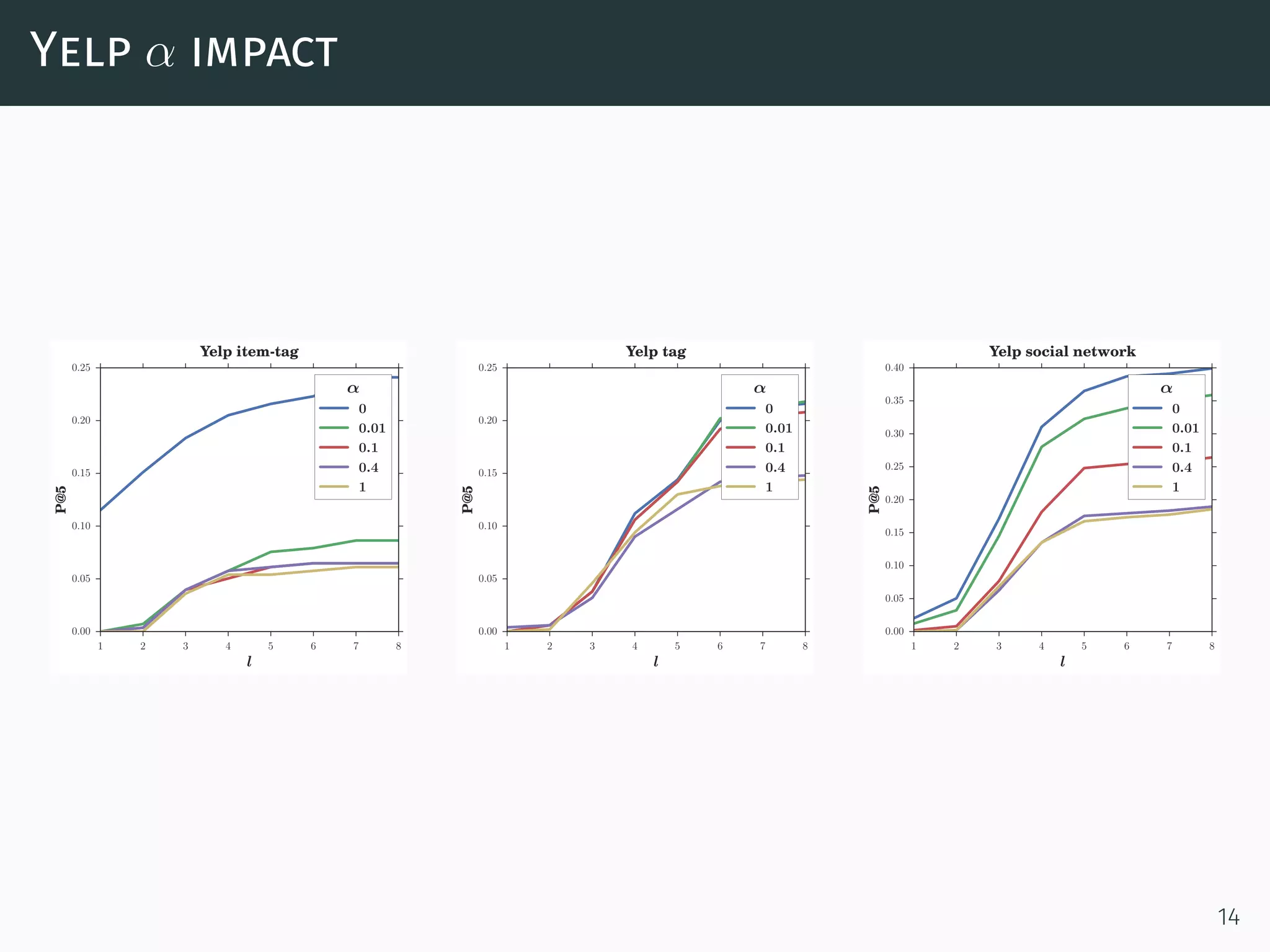
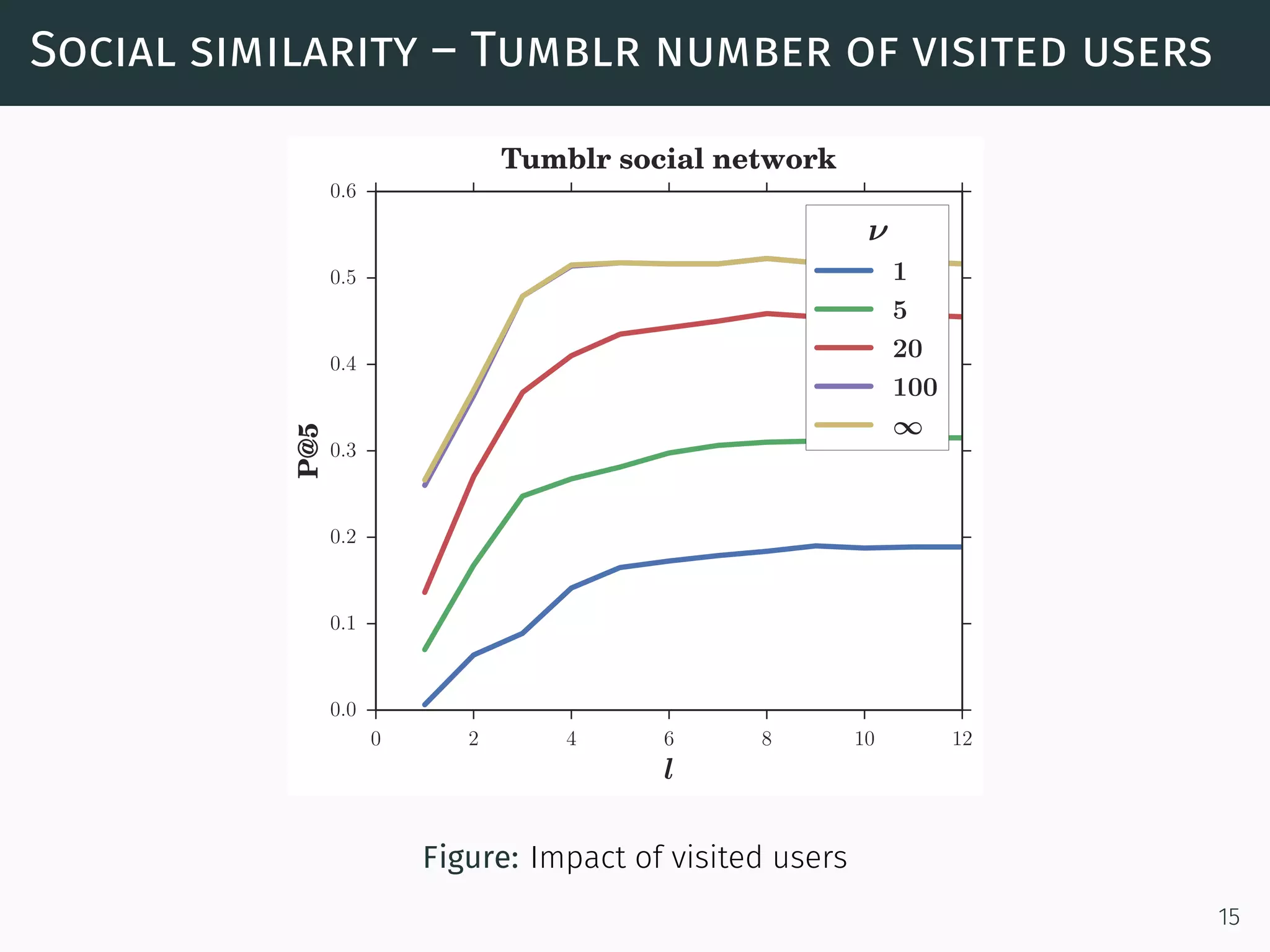
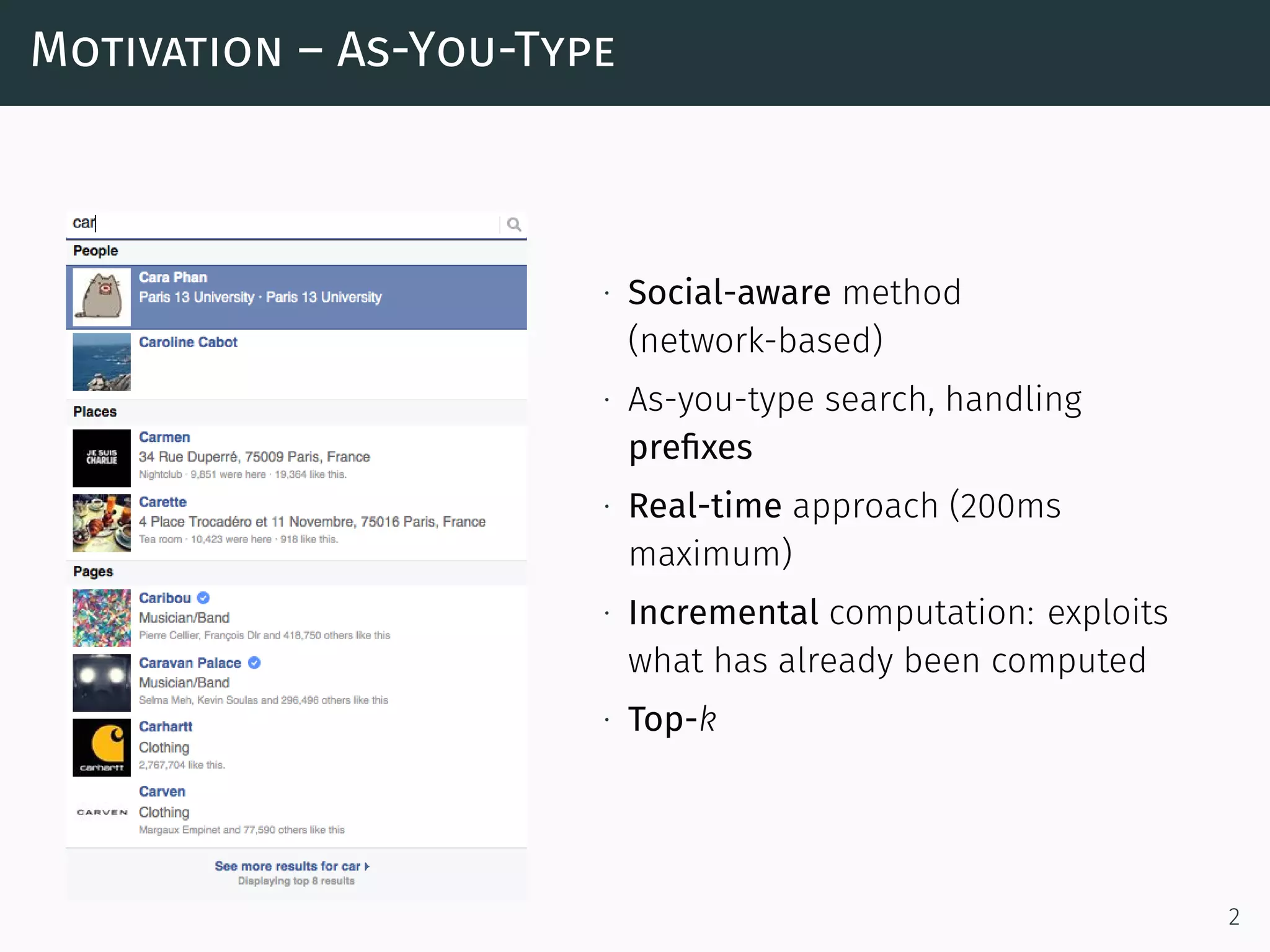
The document discusses a network-aware method for real-time as-you-type search in social media that leverages a social tagging context and a weighted graph representation of user connections. It introduces a scoring model that integrates both textual and social data for ranking search results, and describes an algorithm for efficiently retrieving top-k items based on user proximity and tagging. The approach aims to enhance search accuracy and speed by incrementally computing results and utilizing a completion trie index.



![Example
∙ Triples (user, item, tag)
∙ Weighted similarity network
between users (reflects
proximity, friendship,
similarity and can be
computed using tags,
item-tags, social links). Each
edge σ(u, v) ∈]0, 1]
4](https://image.slidesharecdn.com/slideslagreeoak-151113105816-lva1-app6891/75/A-Network-Aware-Approach-for-Searching-As-You-Type-in-Social-Media-5-2048.jpg)
![Score Model
For a given tag t and seeker s, the score is
score(item|s, t) = α × textual(t, item) + (1 − α) × social(item|s, t)
where α ∈ [0, 1] gives how much we want the answer to be social.
5](https://image.slidesharecdn.com/slideslagreeoak-151113105816-lva1-app6891/75/A-Network-Aware-Approach-for-Searching-As-You-Type-in-Social-Media-6-2048.jpg)
![Score Model
For a given tag t and seeker s, the score is
score(item|s, t) = α × textual(t, item) + (1 − α) × social(item|s, t)
where α ∈ [0, 1] gives how much we want the answer to be social.
∙ α = 1, we come back to the classical web search
∙ α = 0, exclusively social search.
5](https://image.slidesharecdn.com/slideslagreeoak-151113105816-lva1-app6891/75/A-Network-Aware-Approach-for-Searching-As-You-Type-in-Social-Media-7-2048.jpg)

![Completion trie index
[4] ε
[1] ε [2] ip
[2] h
[3] g
[2] l
[1] oomy
[2] ster [2] pie
[2] asses
[2] oth
[1] allow
[4] st
[3] y
[2] lish [3] le
[3] runge
[4] reet
(i4, 2)
(i2, 1)
(i6, 1)
(i3, 1)
(i2, 4)
(i4, 2)
(i2, 1)
(i3, 1)
(i5, 1) (i1, 2)
(i3, 1)
(i4, 1)
(i5,1)
(i1, 1)
(i4, 1)
(i6, 2)
(i4, 1)
(i2,2)
(i4, 1)
(i2, 3)
(i1,2)
(i4, 1)
(i5,1)
(i6,1) (i1, 2)
(i5, 1)
(i4, 3)
(i2, 1)
(i6, 1)
IL(hipster)
(i2, street, 4)
(i4, style, 3)
(i1, stylish, 2)
(i5, stylish, 1)
(i6, style, 1)
virtual IL(st) ∙ Leaf nodes in the
trie correspond to
concrete inverted
lists
∙ Internal nodes
match a keyword
prefix and
represent a
”virtual list”.
7](https://image.slidesharecdn.com/slideslagreeoak-151113105816-lva1-app6891/75/A-Network-Aware-Approach-for-Searching-As-You-Type-in-Social-Media-9-2048.jpg)