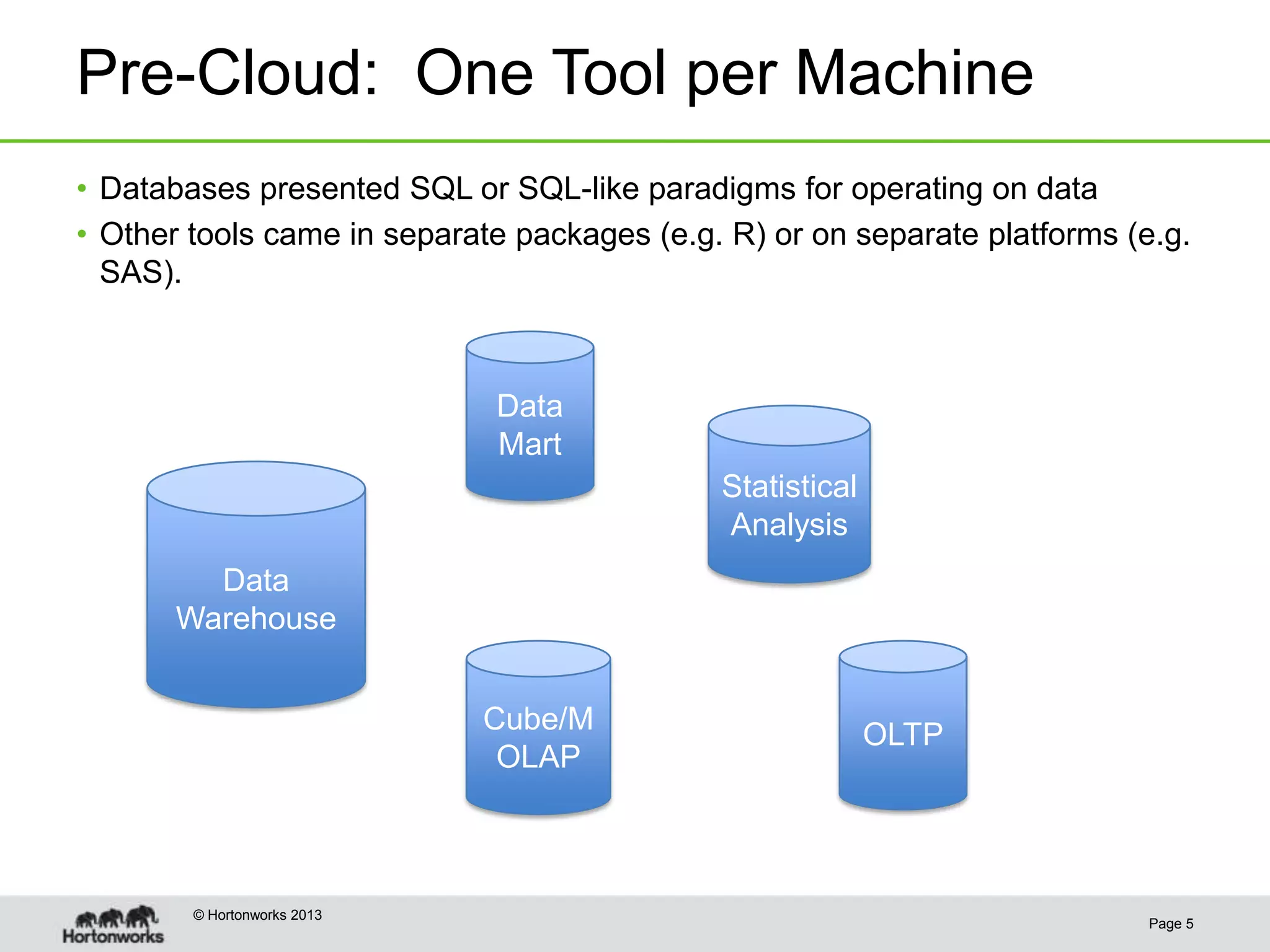
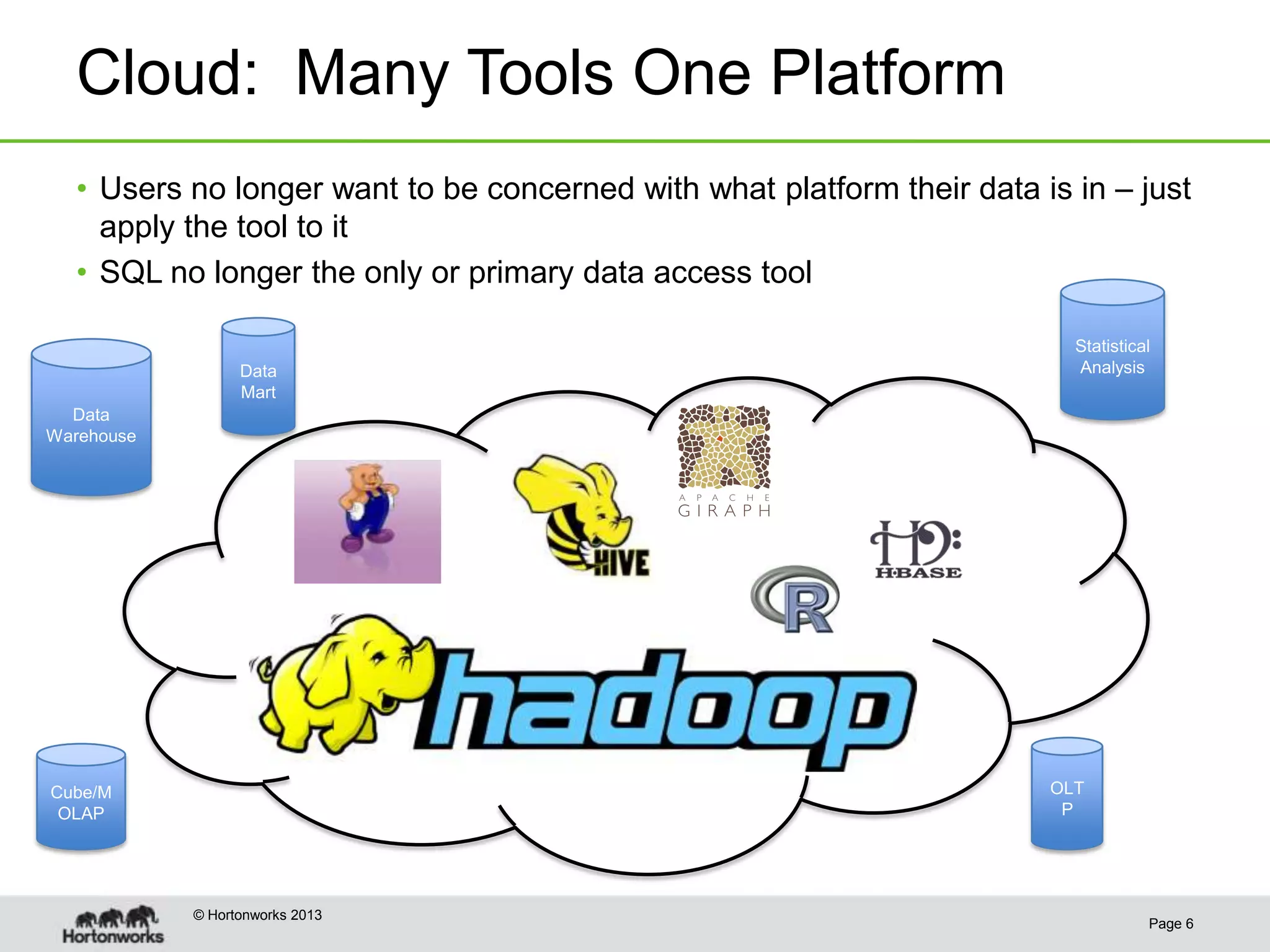
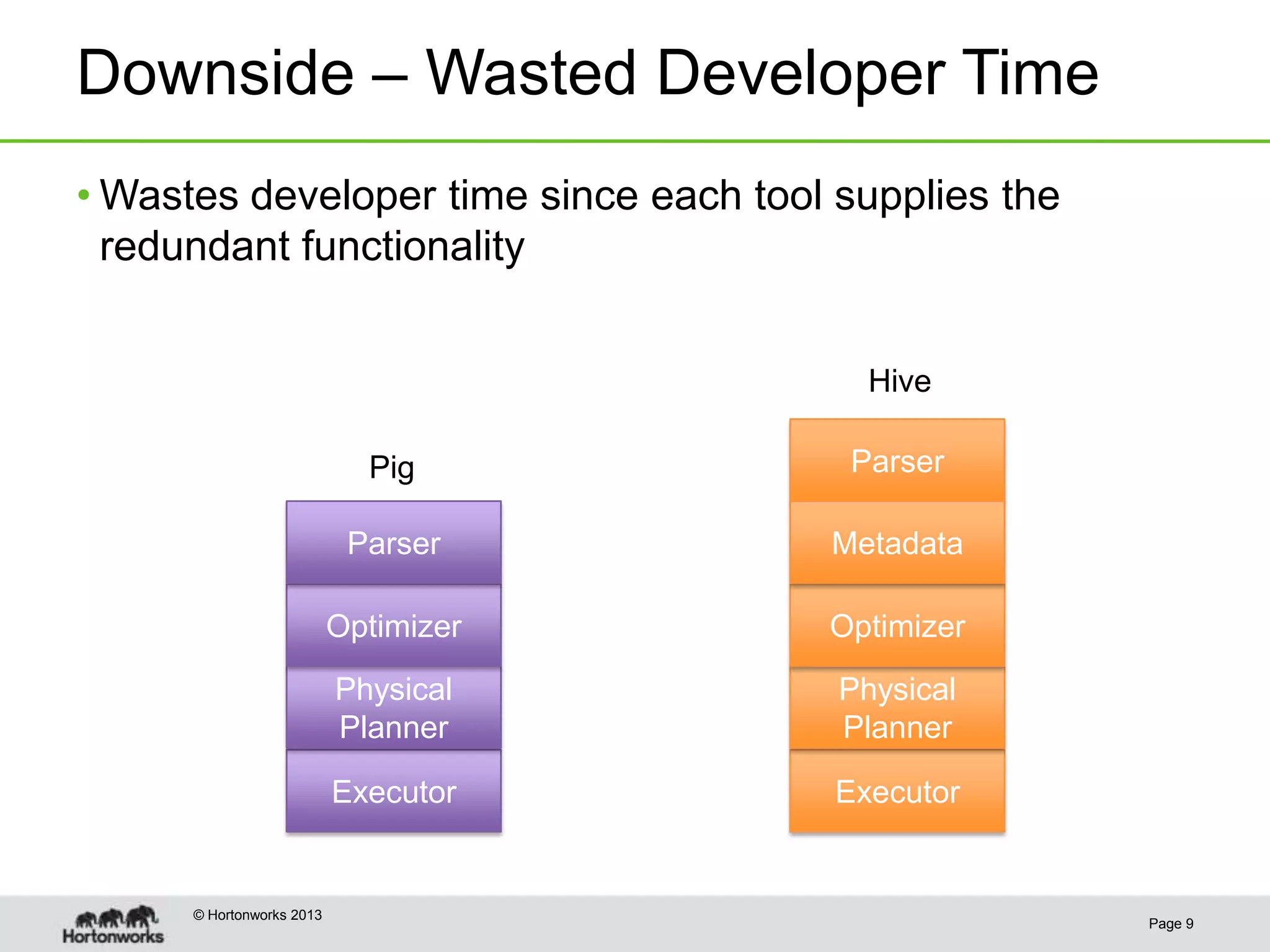
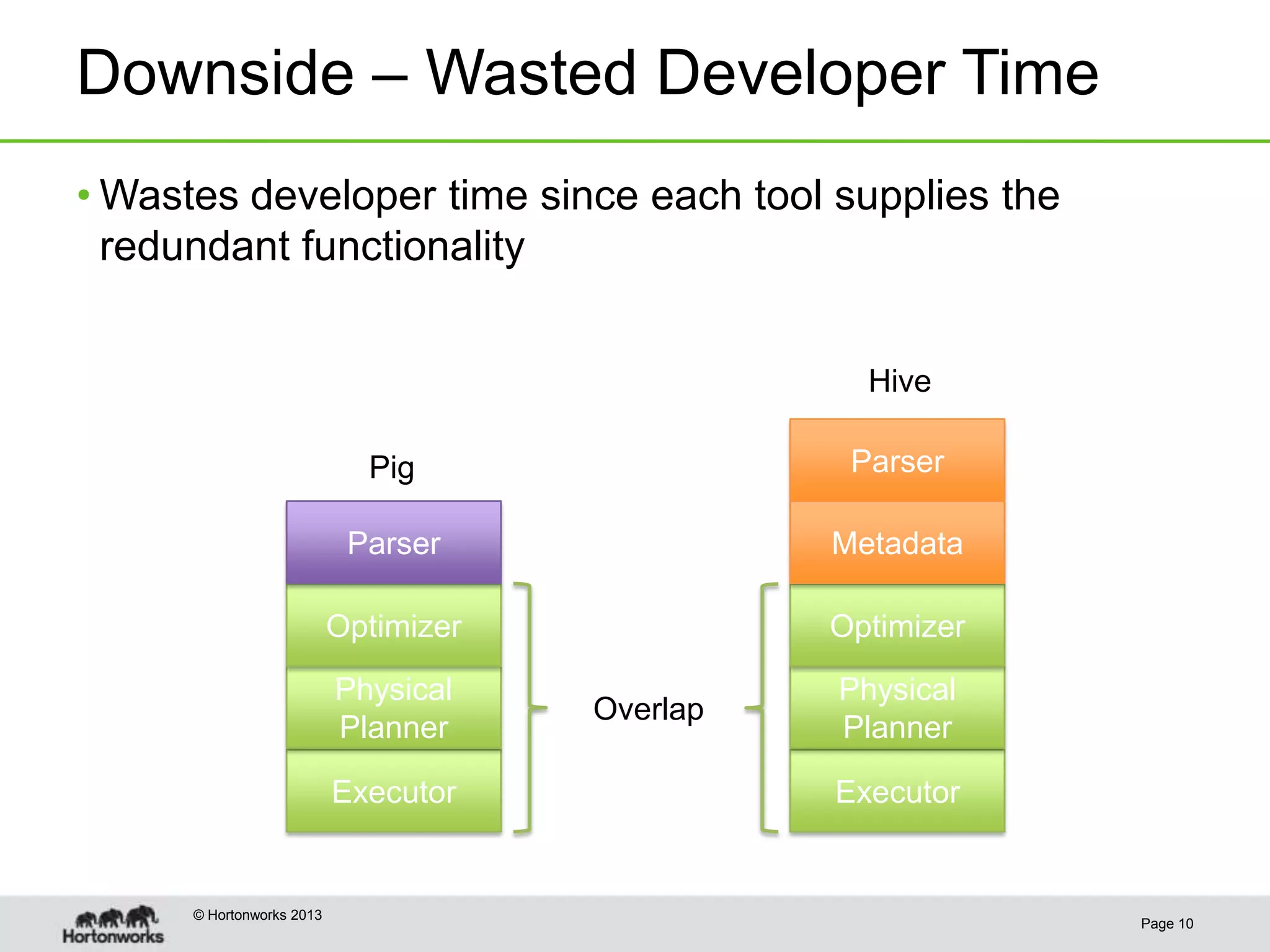
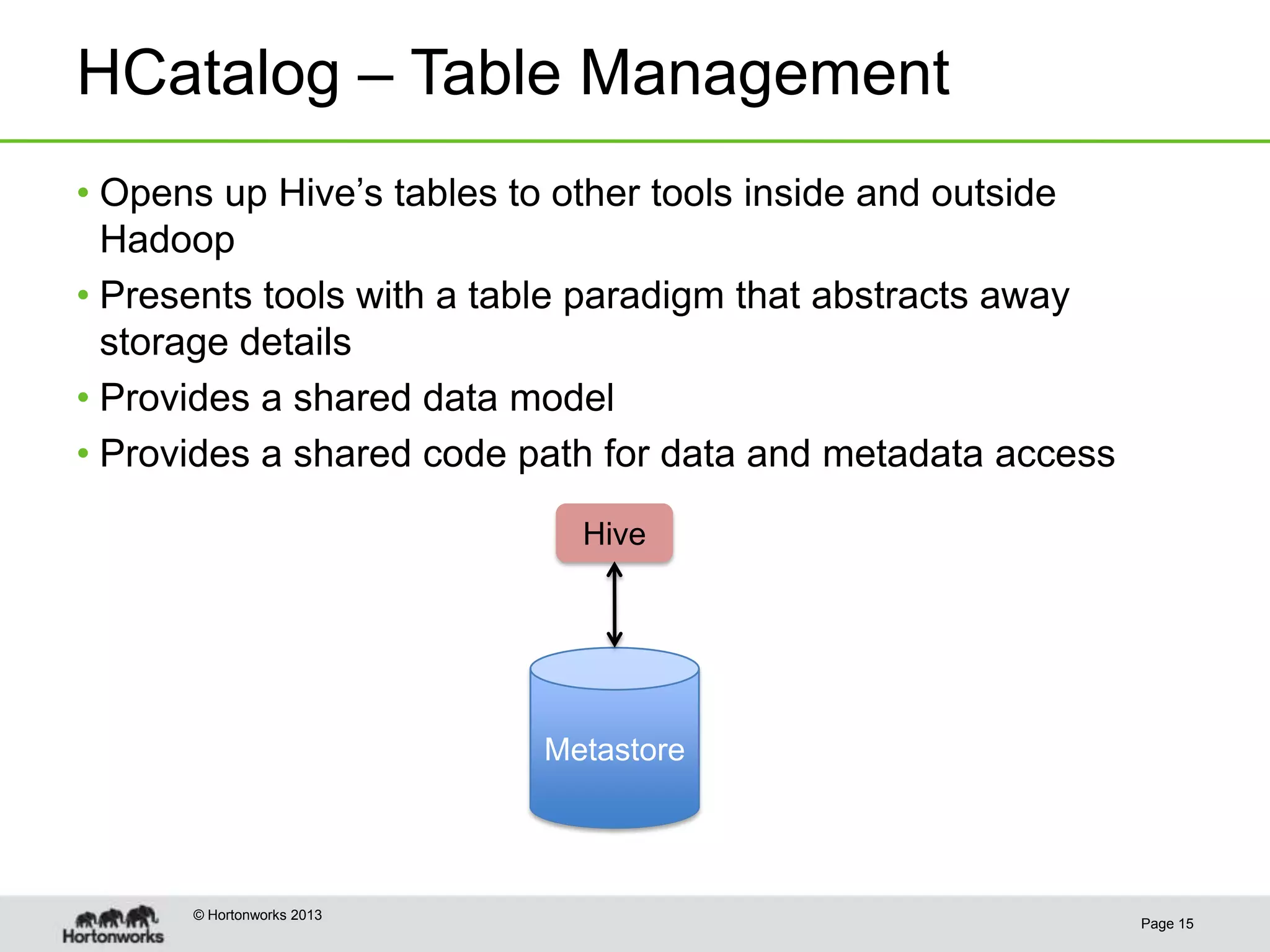
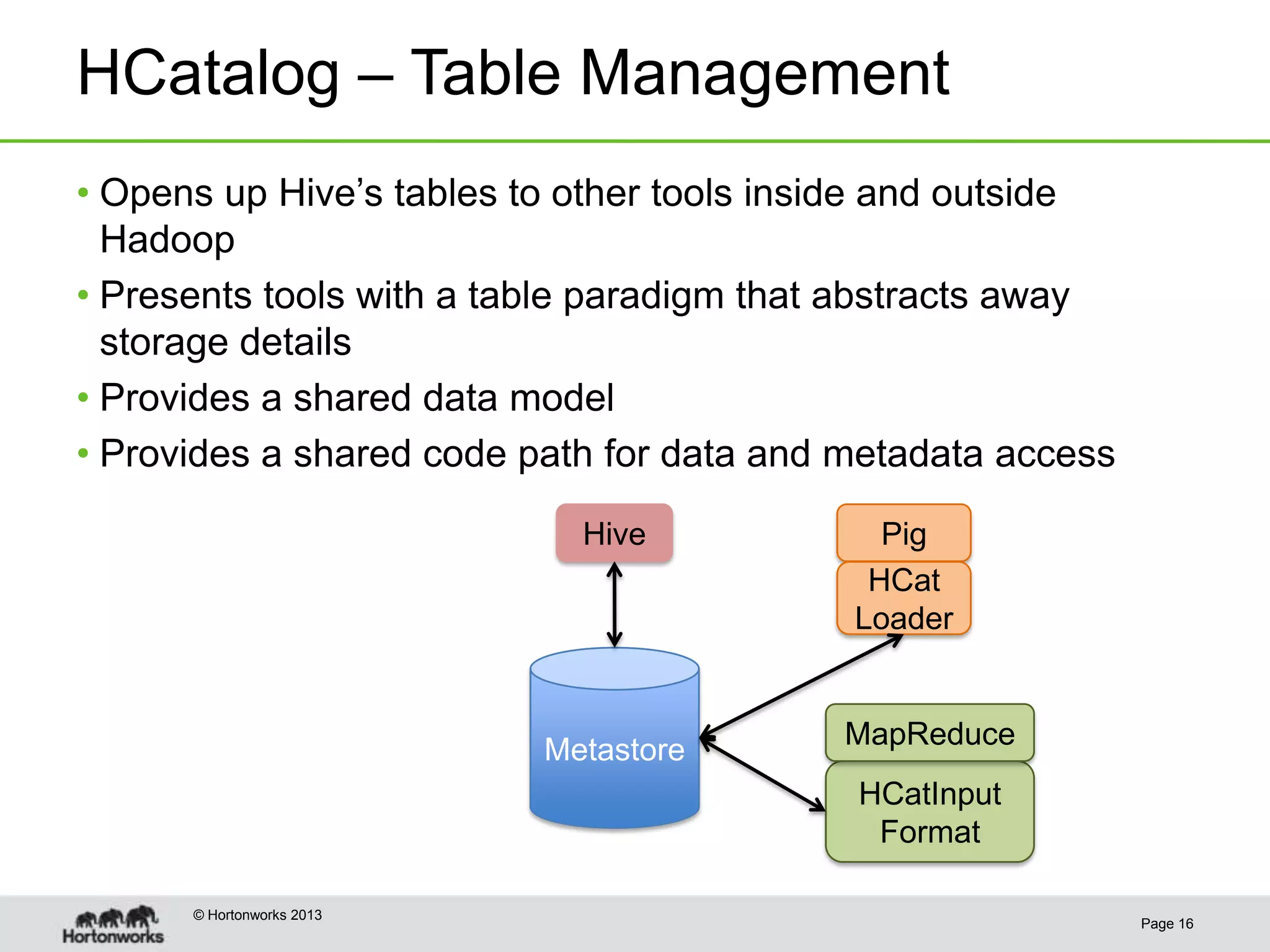
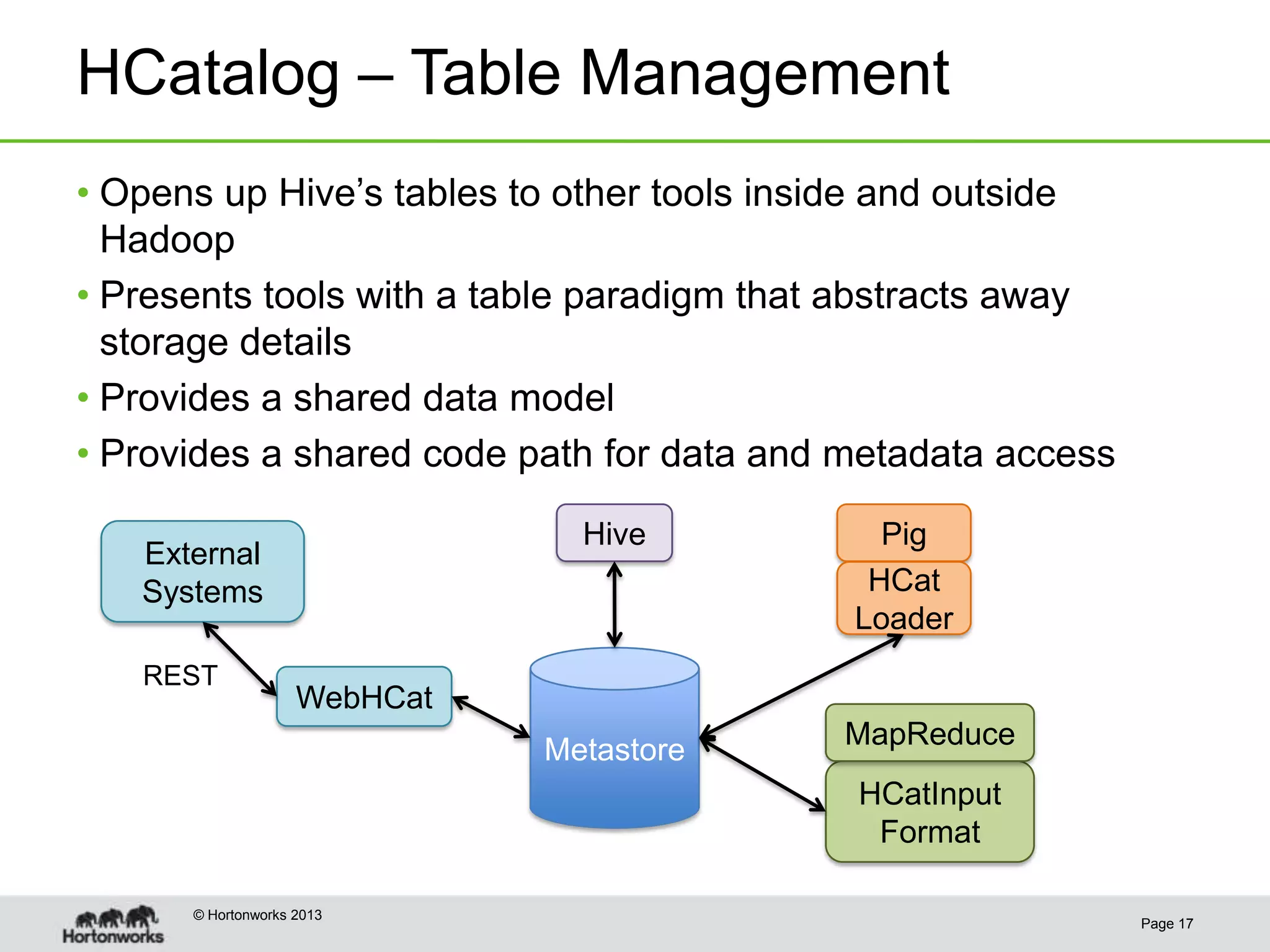
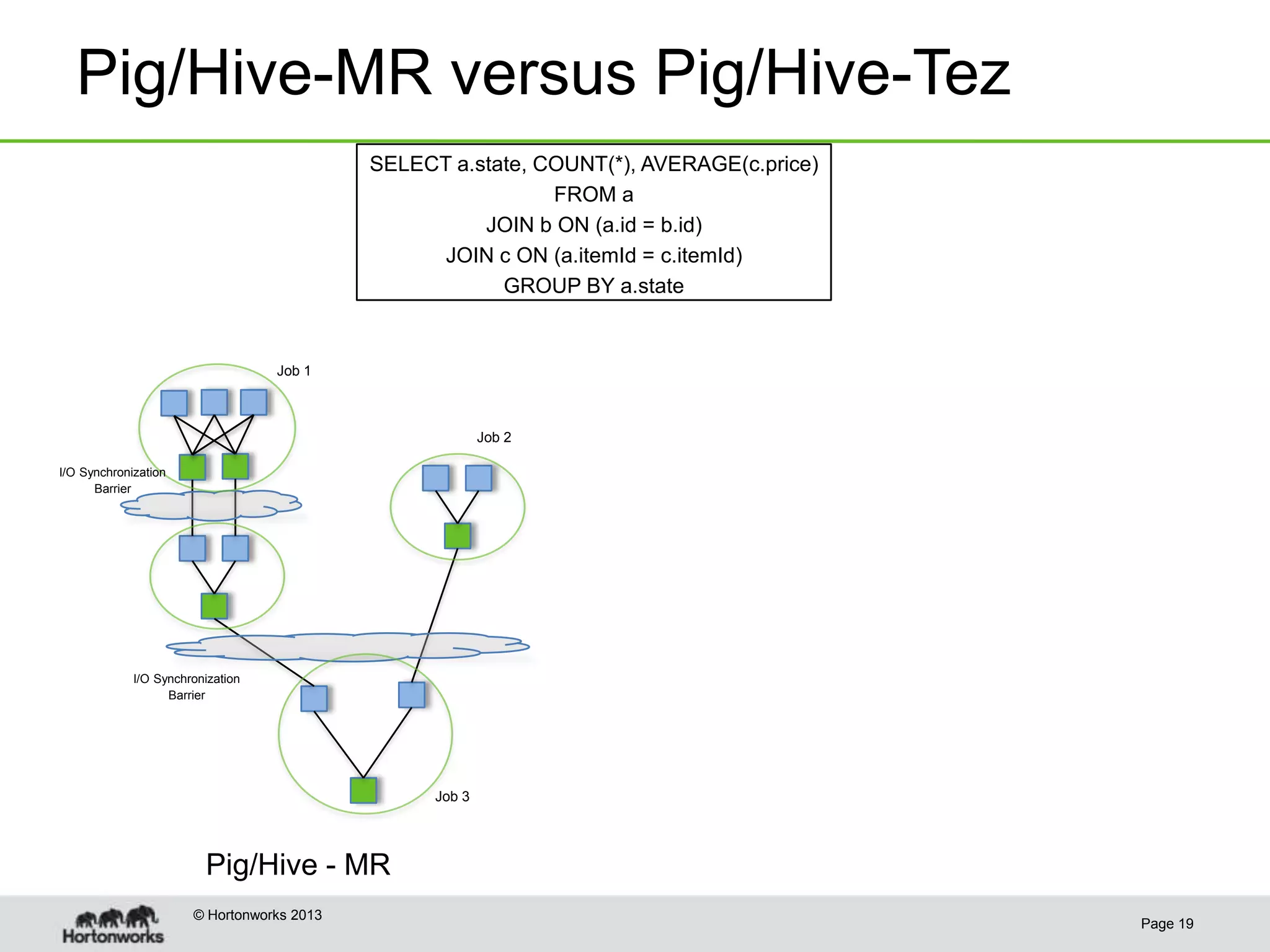
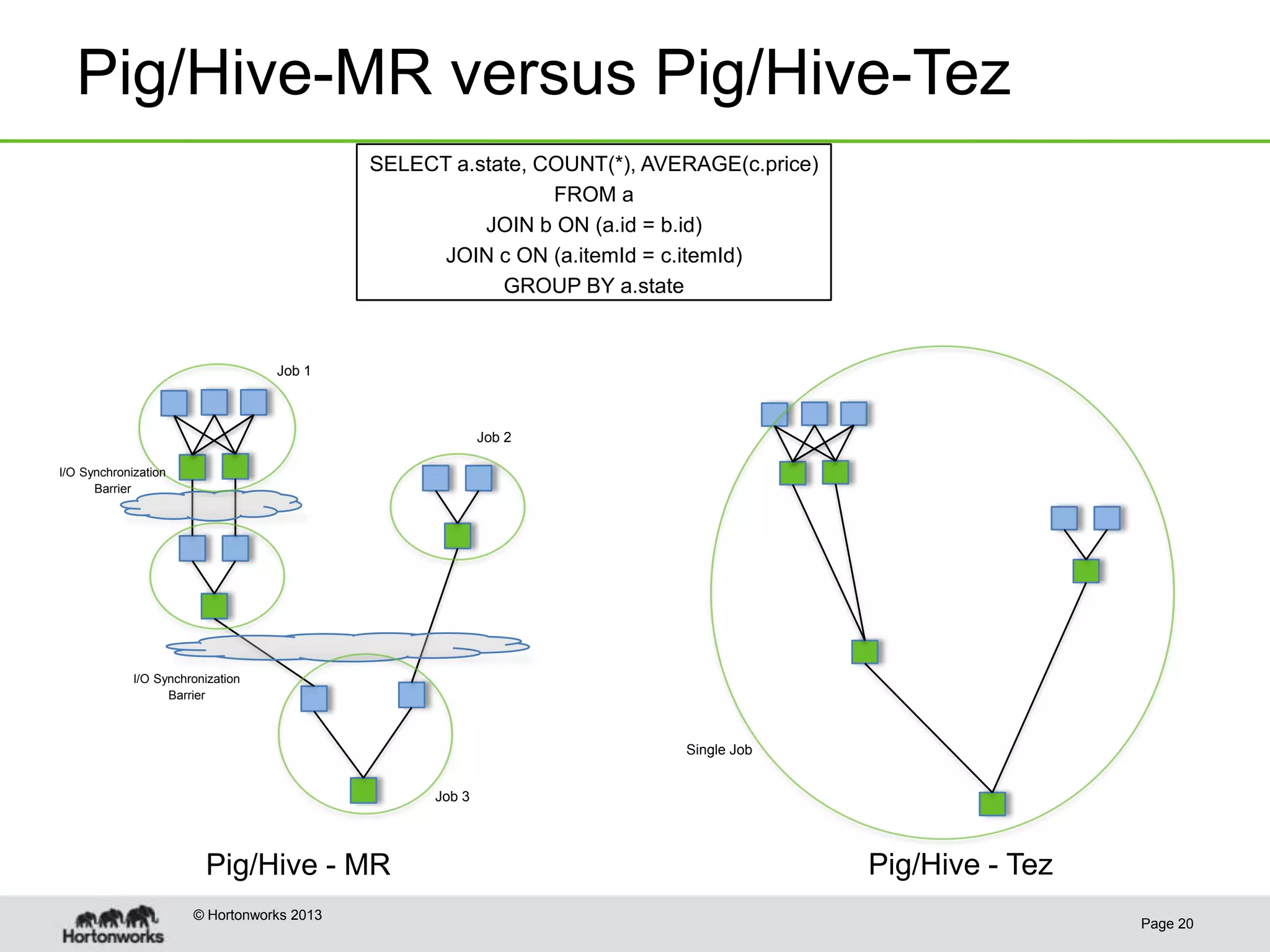
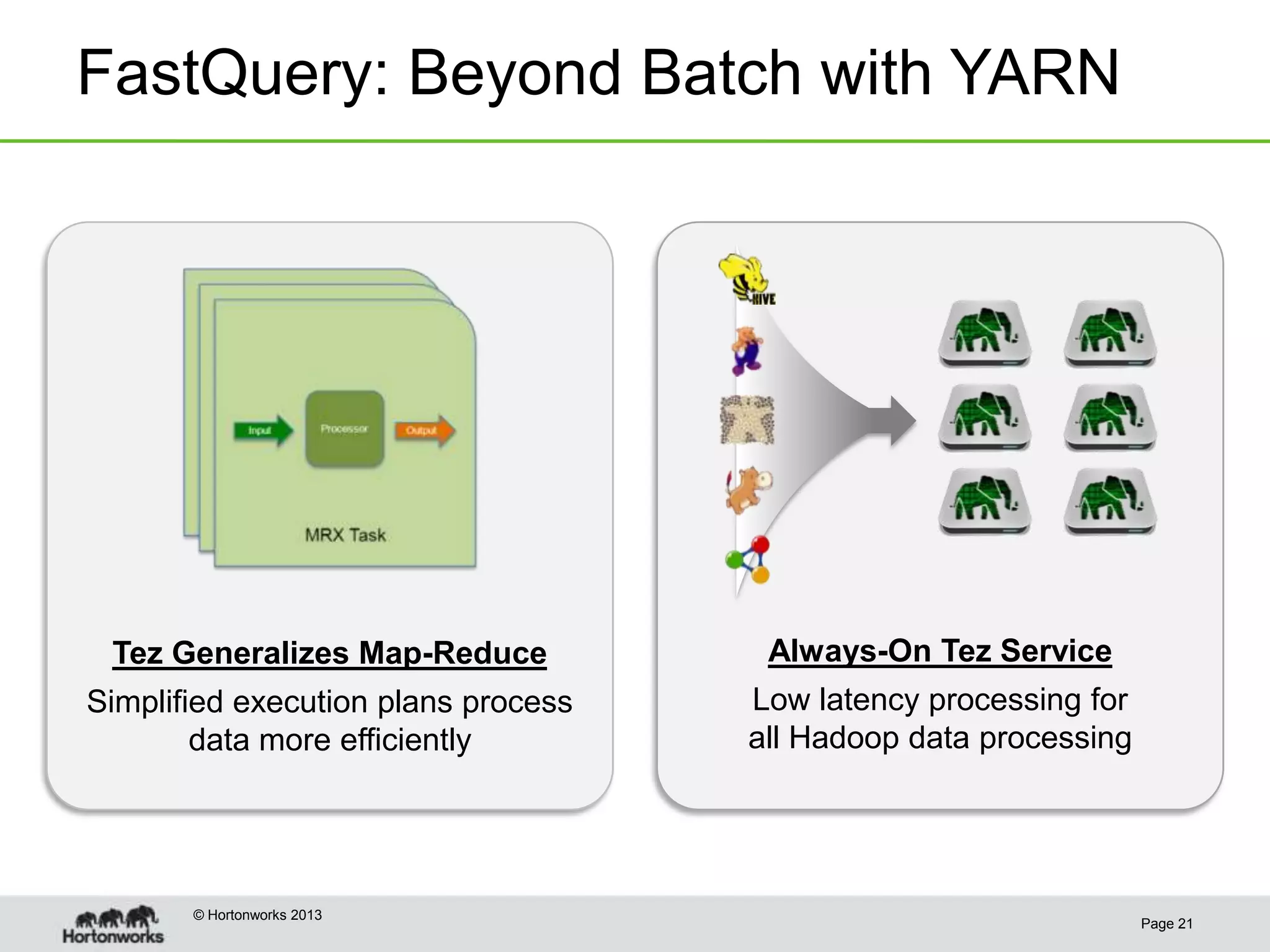
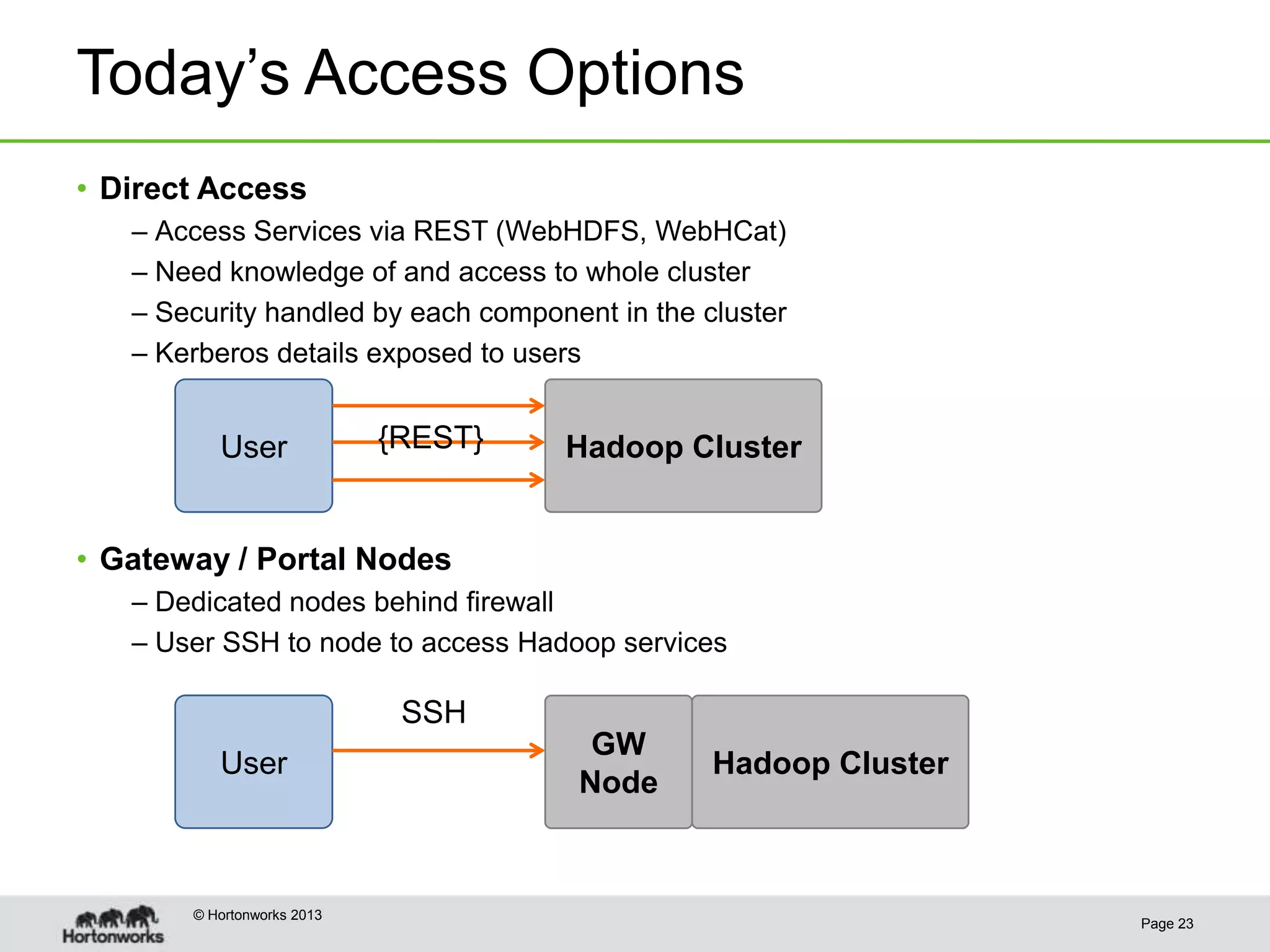
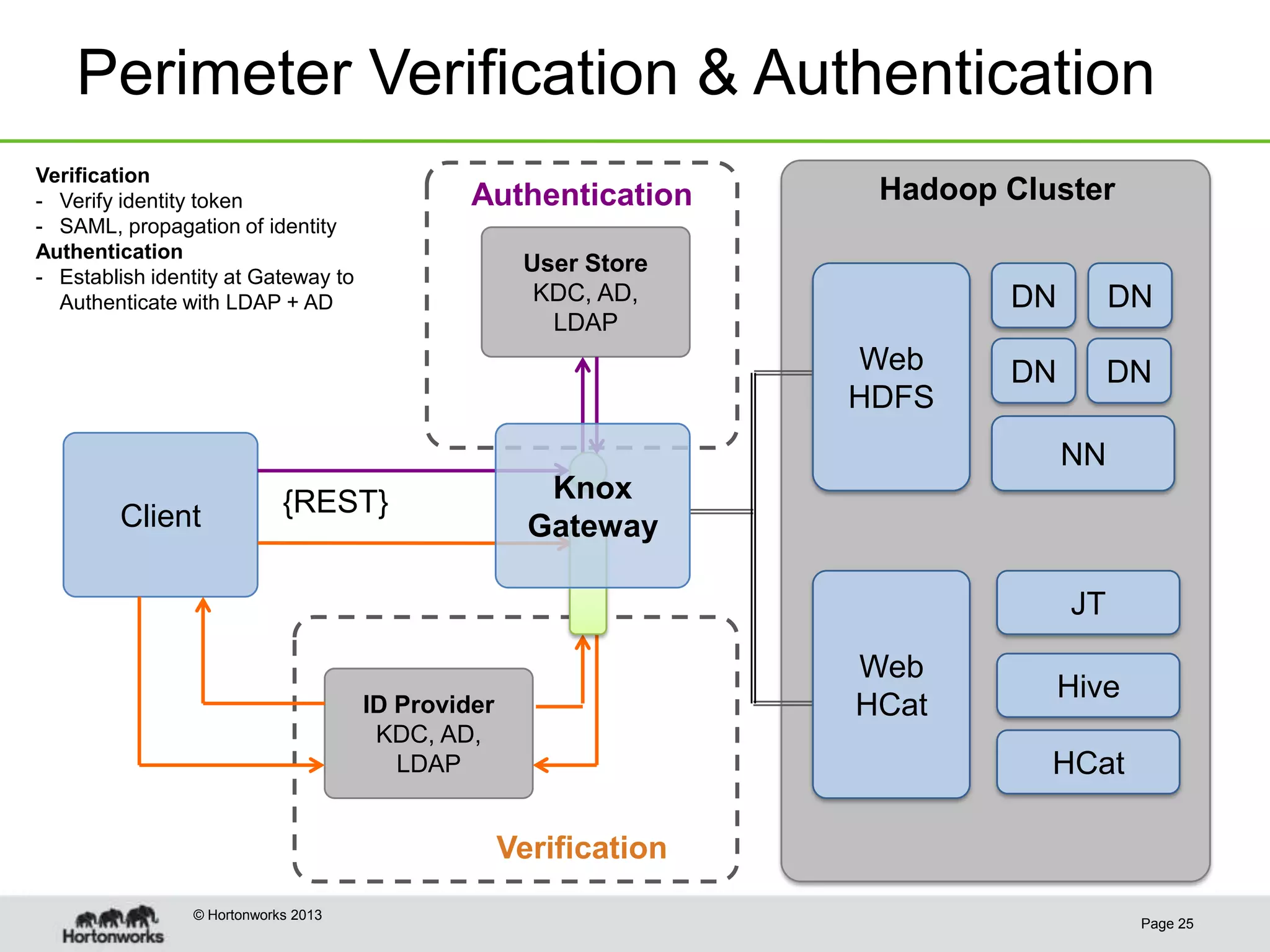
This document discusses how coordinating the many tools of big data has become more complex with the rise of cloud computing and large datasets. It argues that while having many tools provides flexibility, it also leads to inefficiencies as tools do not integrate well and developers end up duplicating work. The document proposes that Hadoop can help address these issues by providing shared services that tools can leverage, such as common table management, metadata access, and a new execution engine called Tez that allows for more efficient pipelining of jobs compared to the traditional MapReduce approach. Coordinating tools through shared services allows users to focus on selecting the right tool for a task while reducing redundant development work.