







![Oozie
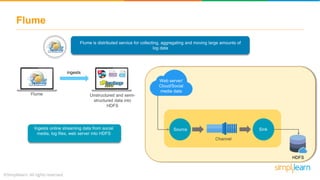
Oozie is a workflow scheduler system to manage Hadoop jobs
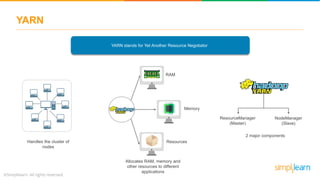
Workflow
engine
Coordinator
engine
Consists of 2 parts
1 2
1
2
Directed Acyclic Graphs (DAGs) which
specifies a sequence of actions to be
executed
These consist of workflow jobs triggered by
time and data
availability
Start
MapReduce
Program [Action
Node]
Notify client of
success [Email
Action Node]
Notify Client of
Error [Email Action
Node]
Kill
(unsuccessful
termination)
Begin Success
Error
End
(successful
completion)](https://image.slidesharecdn.com/hadoopecosystem-190201064444/85/Hadoop-Ecosystem-Hadoop-Ecosystem-Tutorial-Hadoop-Tutorial-For-Beginners-Simplilearn-28-320.jpg)


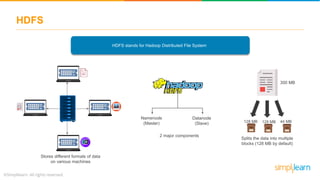
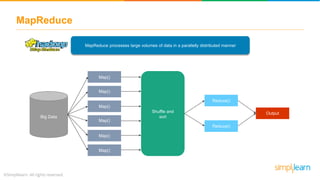
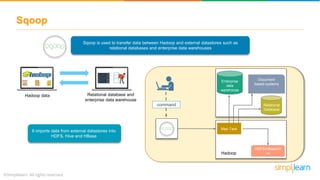
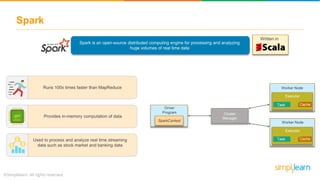
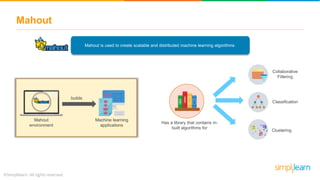
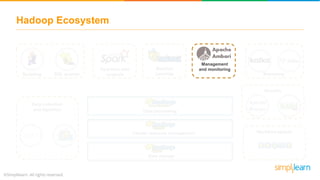
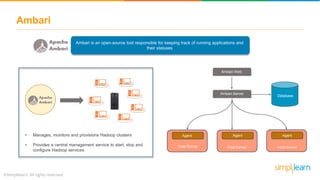
The document provides an overview of the Hadoop ecosystem, detailing various components such as HDFS for data storage, YARN for resource management, and MapReduce for data processing. It highlights tools like Sqoop for data transfer, Flume for log data ingestion, and Spark for real-time analytics, among others. Additionally, it discusses security and management features through frameworks like Ranger and Ambari, along with workflow management via Oozie.























































































