

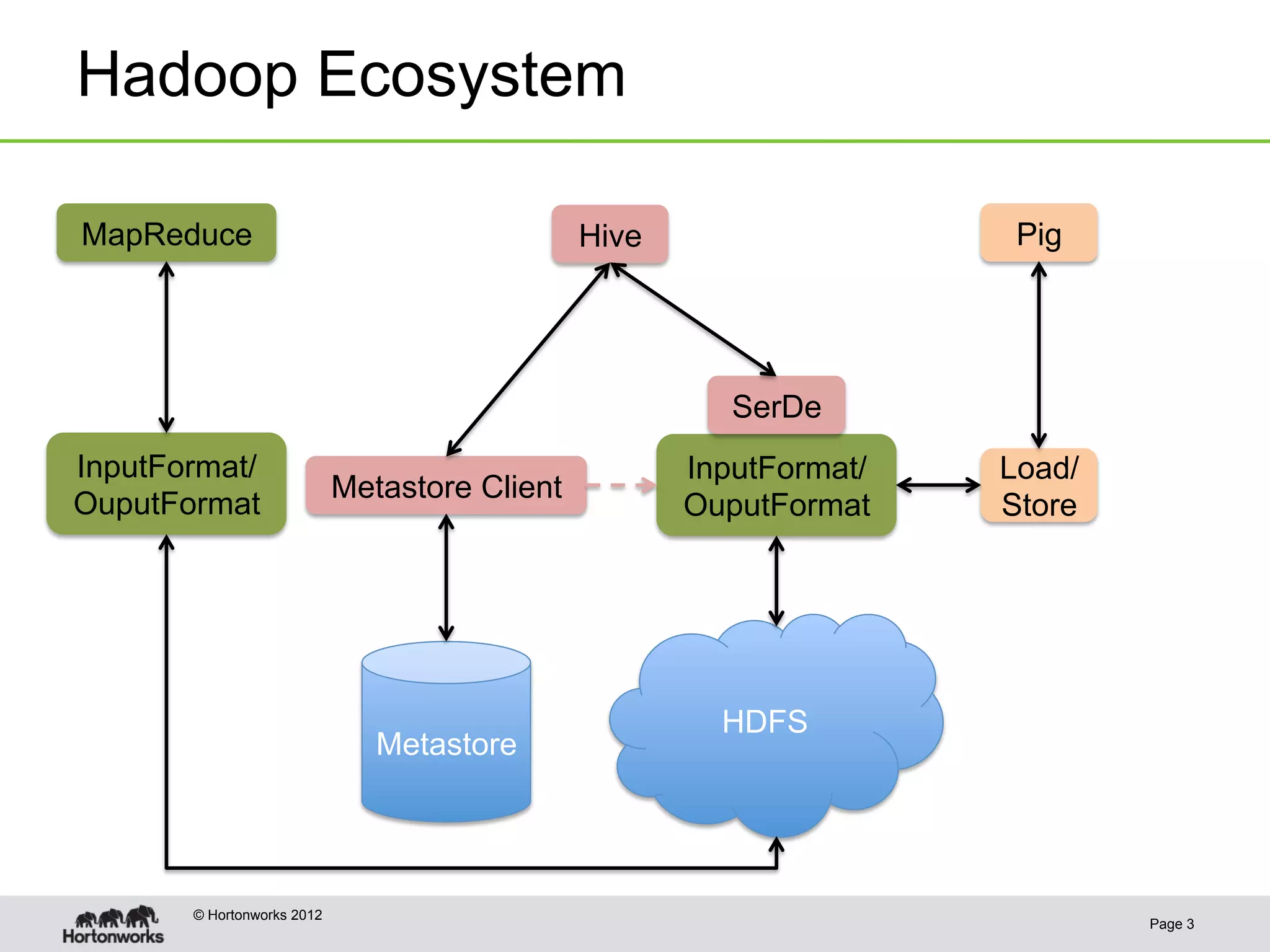
![Templeton - REST API
• REST endpoints: databases, tables, partitions, columns, table properties
• PUT to create/update, GET to list or describe, DELETE to drop
Get a list of all tables in the default database:
GET
http://…/v1/ddl/database/default/table
Hadoop/
HCatalog
{
"tables": ["counted","processed",],
"database": "default"
}
© Hortonworks 2012
Page 5](https://image.slidesharecdn.com/futureofhcatalog-120619195442-phpapp02/75/Future-of-HCatalog-5-2048.jpg)
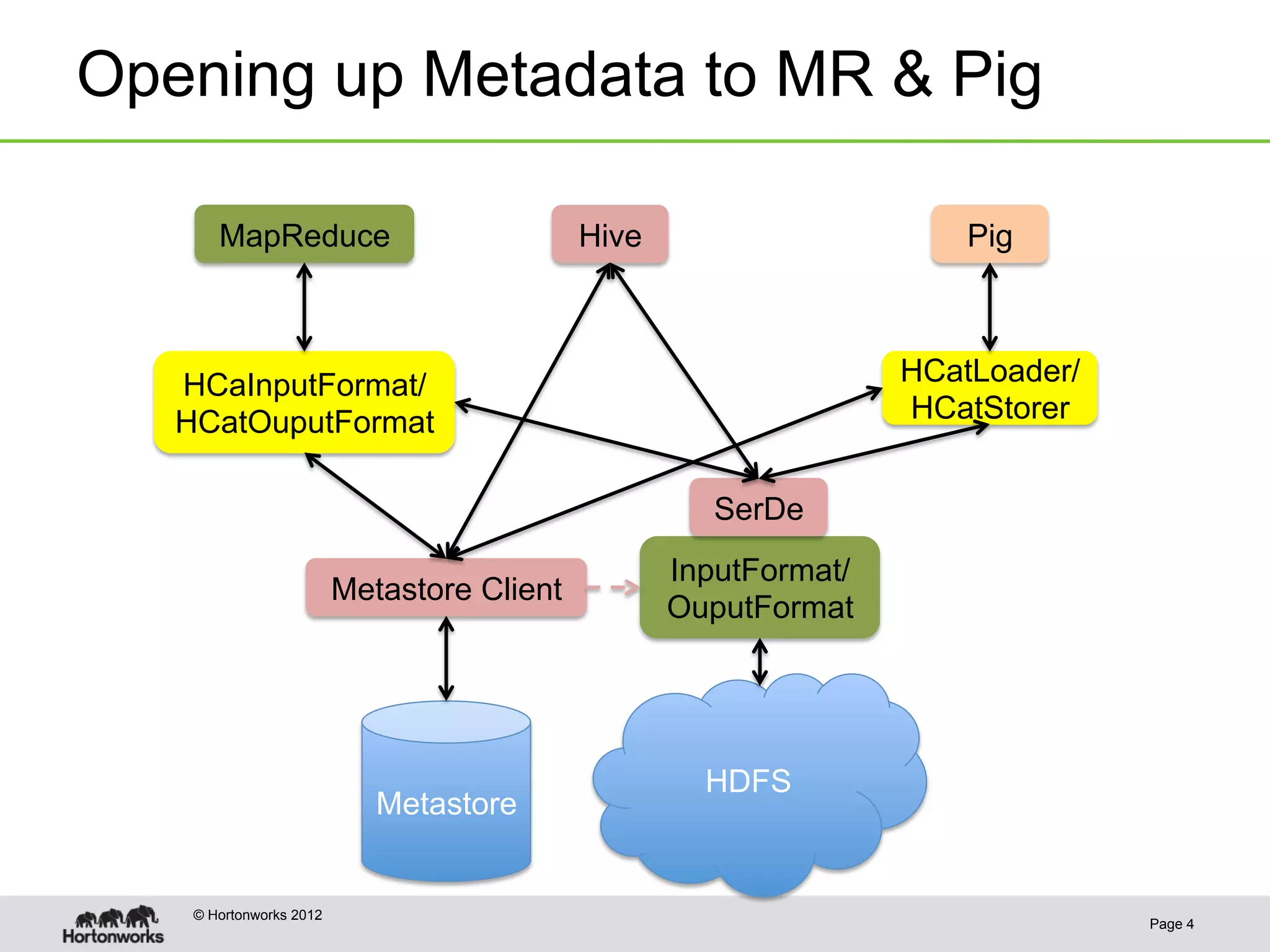
![Templeton - REST API
• REST endpoints: databases, tables, partitions, columns, table properties
• PUT to create/update, GET to list or describe, DELETE to drop
Create new table “rawevents”
PUT
{"columns": [{ "name": "url", "type": "string" },
{ "name": "user", "type": "string"}],
"partitionedBy": [{ "name": "ds", "type": "string" }]}
http://…/v1/ddl/database/default/table/rawevents
Hadoop/
HCatalog
{
"table": "rawevents",
"database": "default”
}
© Hortonworks 2012
Page 6](https://image.slidesharecdn.com/futureofhcatalog-120619195442-phpapp02/75/Future-of-HCatalog-6-2048.jpg)
![Templeton - REST API
• REST endpoints: databases, tables, partitions, columns, table properties
• PUT to create/update, GET to list or describe, DELETE to drop
Describe table “rawevents”
GET
http://…/v1/ddl/database/default/table/rawevents
Hadoop/
HCatalog
{
"columns": [{"name": "url","type": "string"},
{"name": "user","type": "string"}],
"database": "default",
"table": "rawevents"
}
• Included in HDP
• Not yet checked in, but you can find the code on Apache’s JIRA HCATALOG-182
© Hortonworks 2012
Page 7](https://image.slidesharecdn.com/futureofhcatalog-120619195442-phpapp02/75/Future-of-HCatalog-7-2048.jpg)

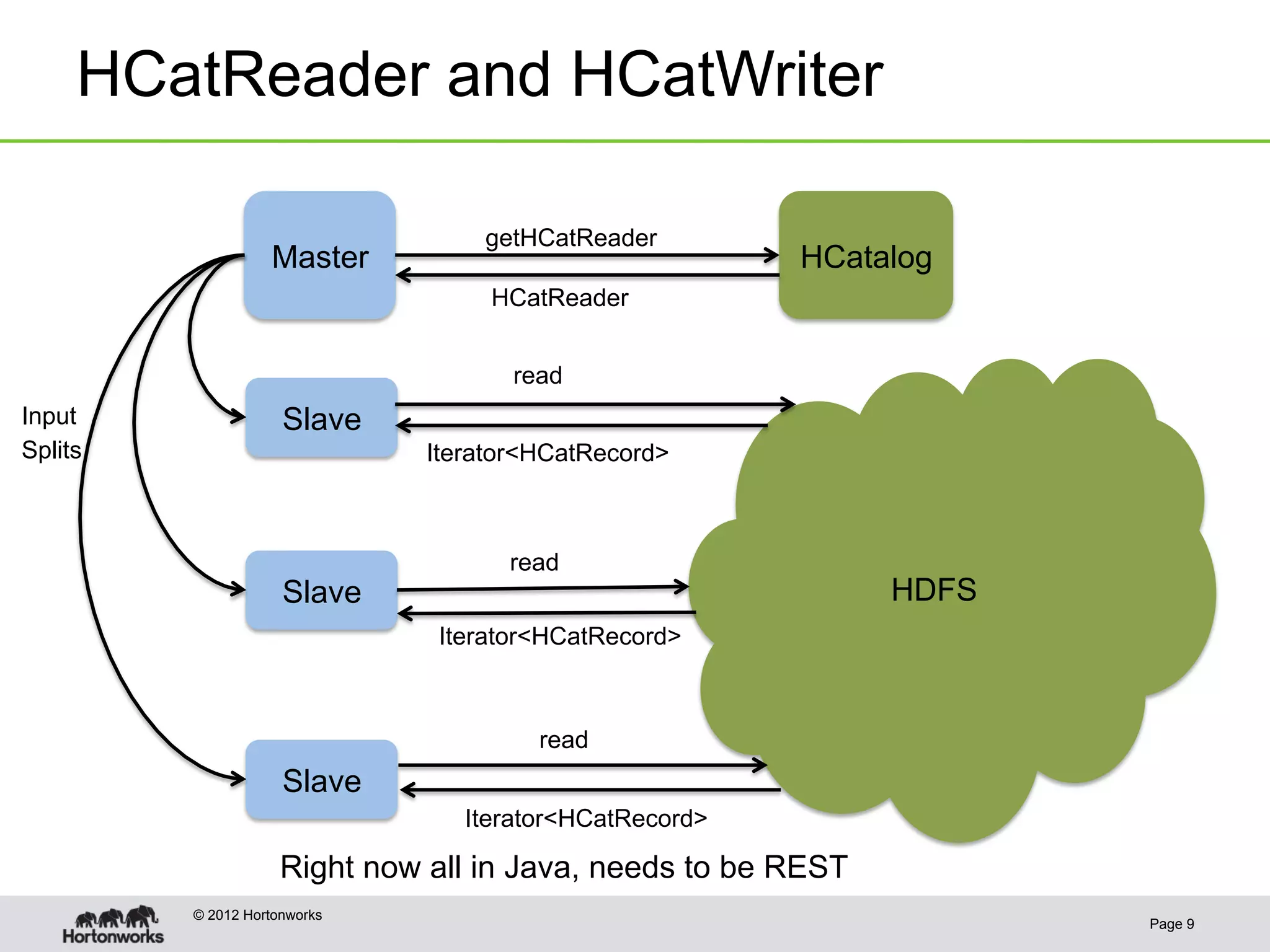
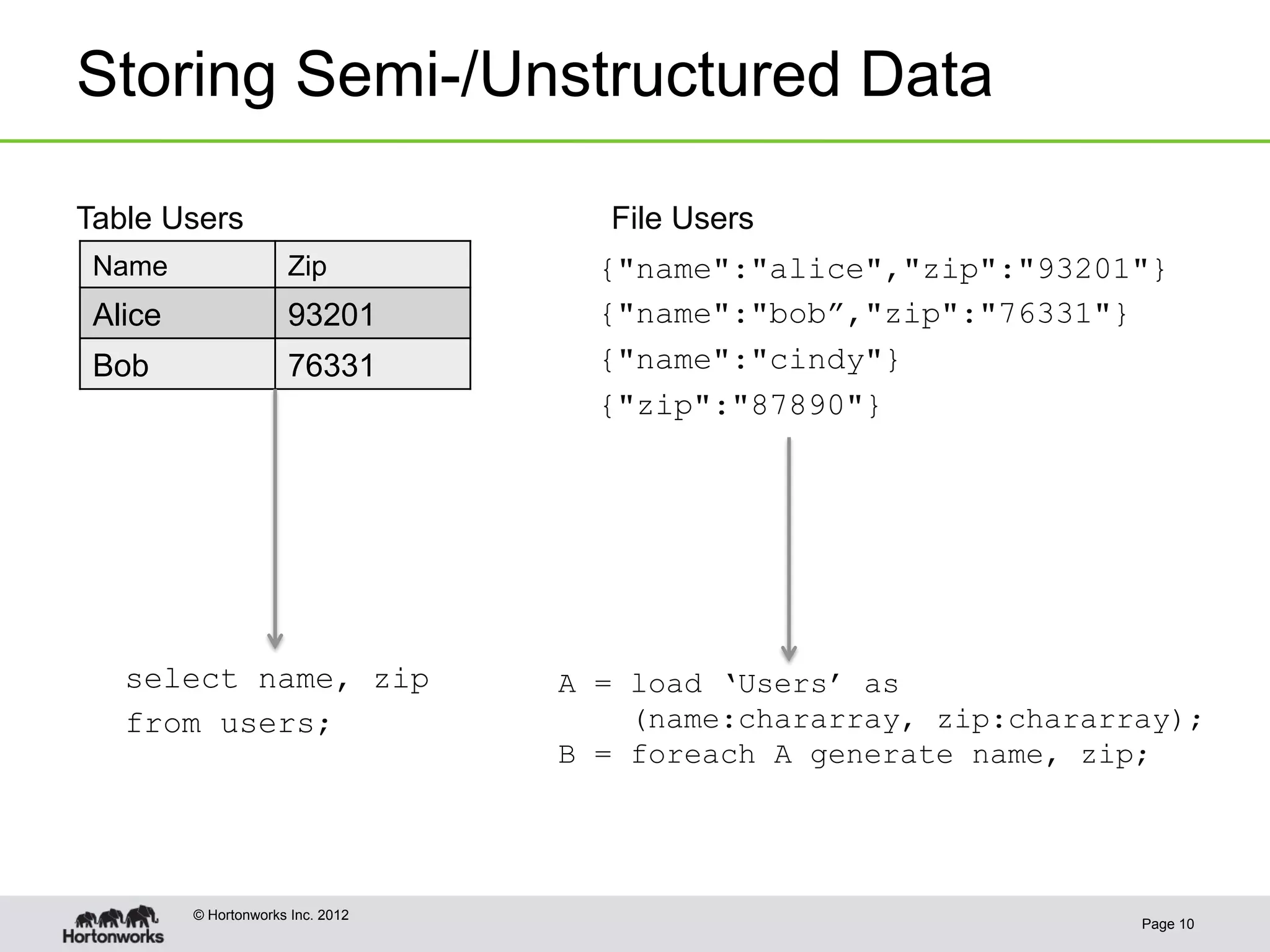
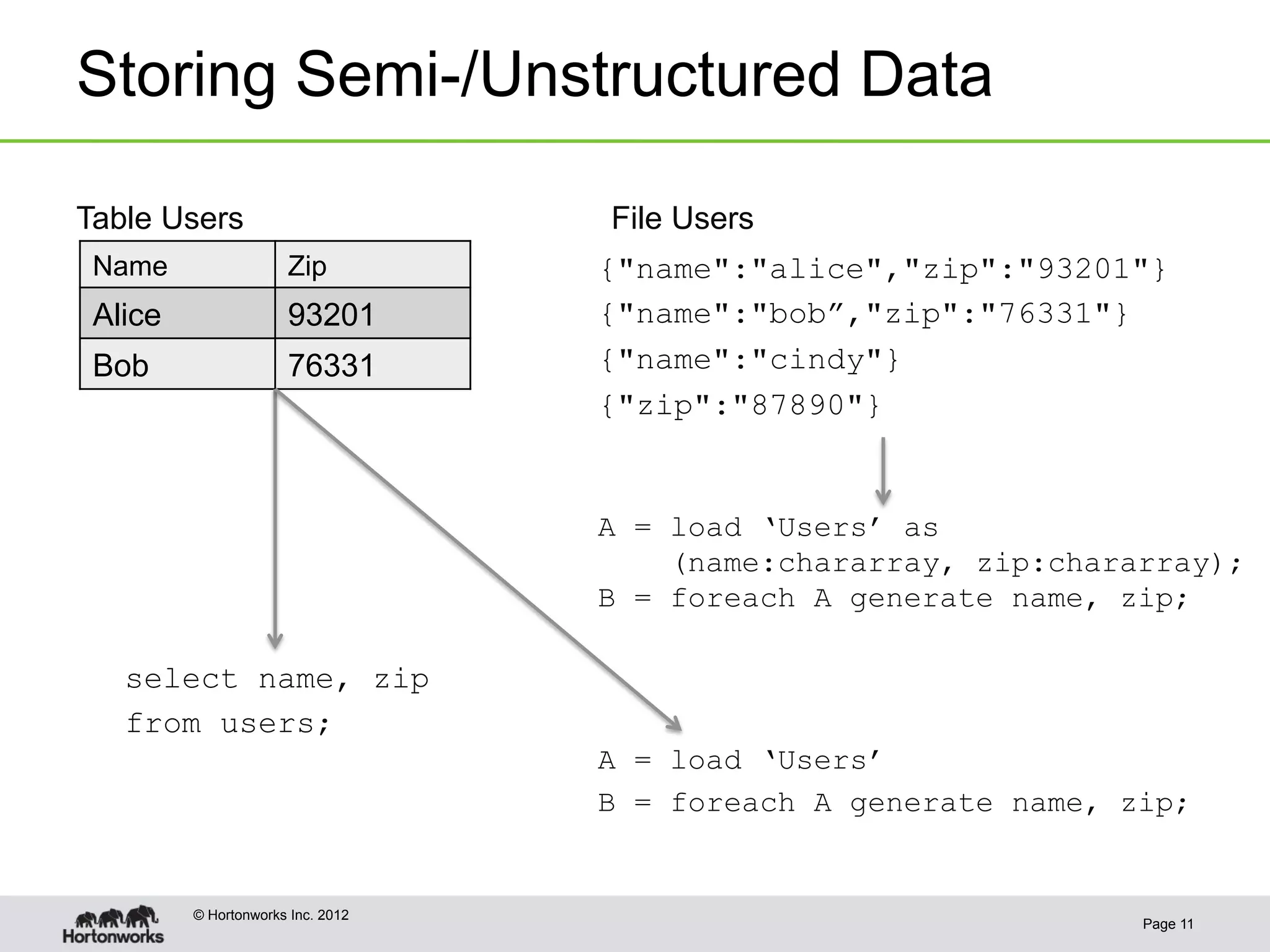
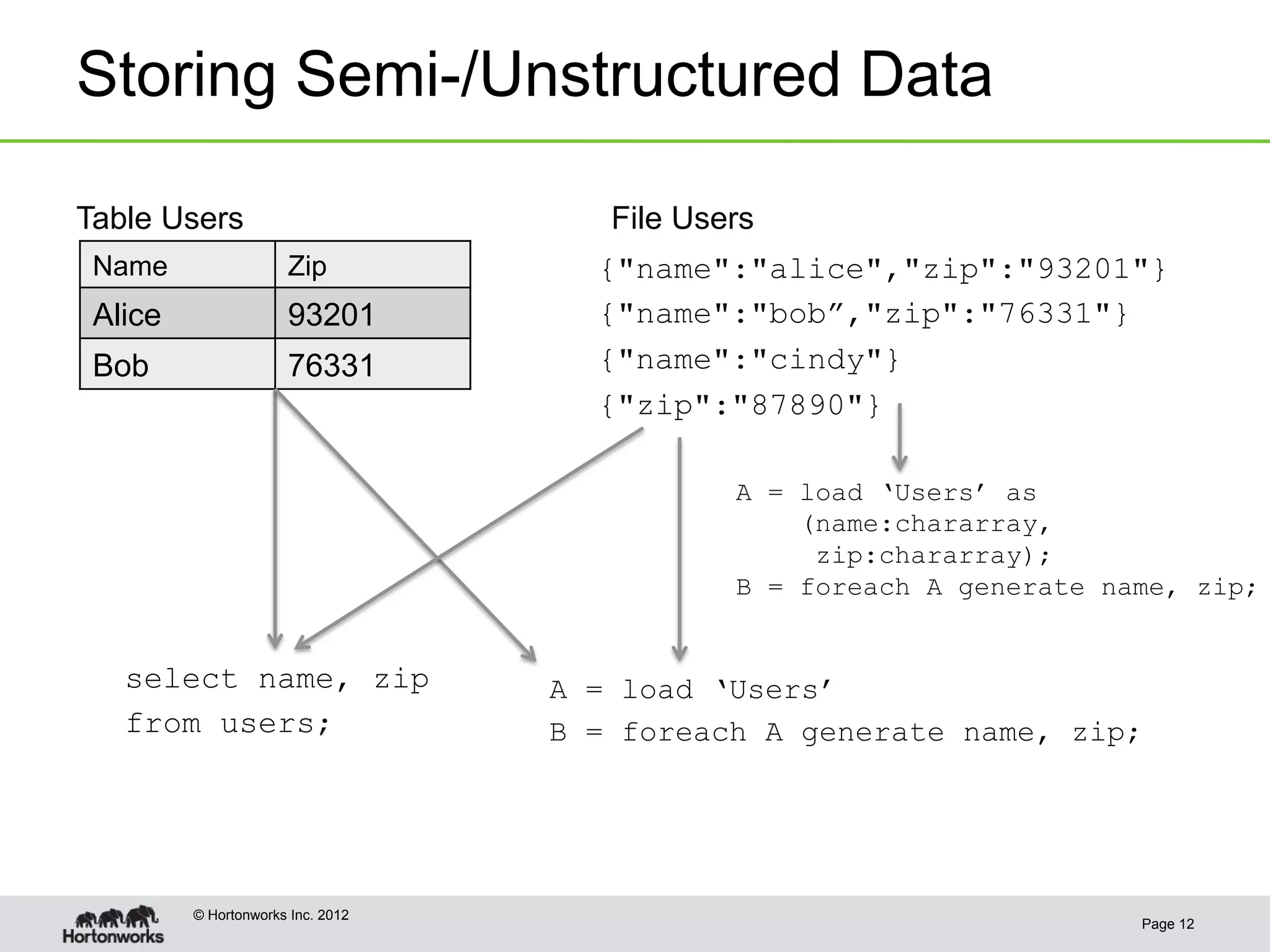
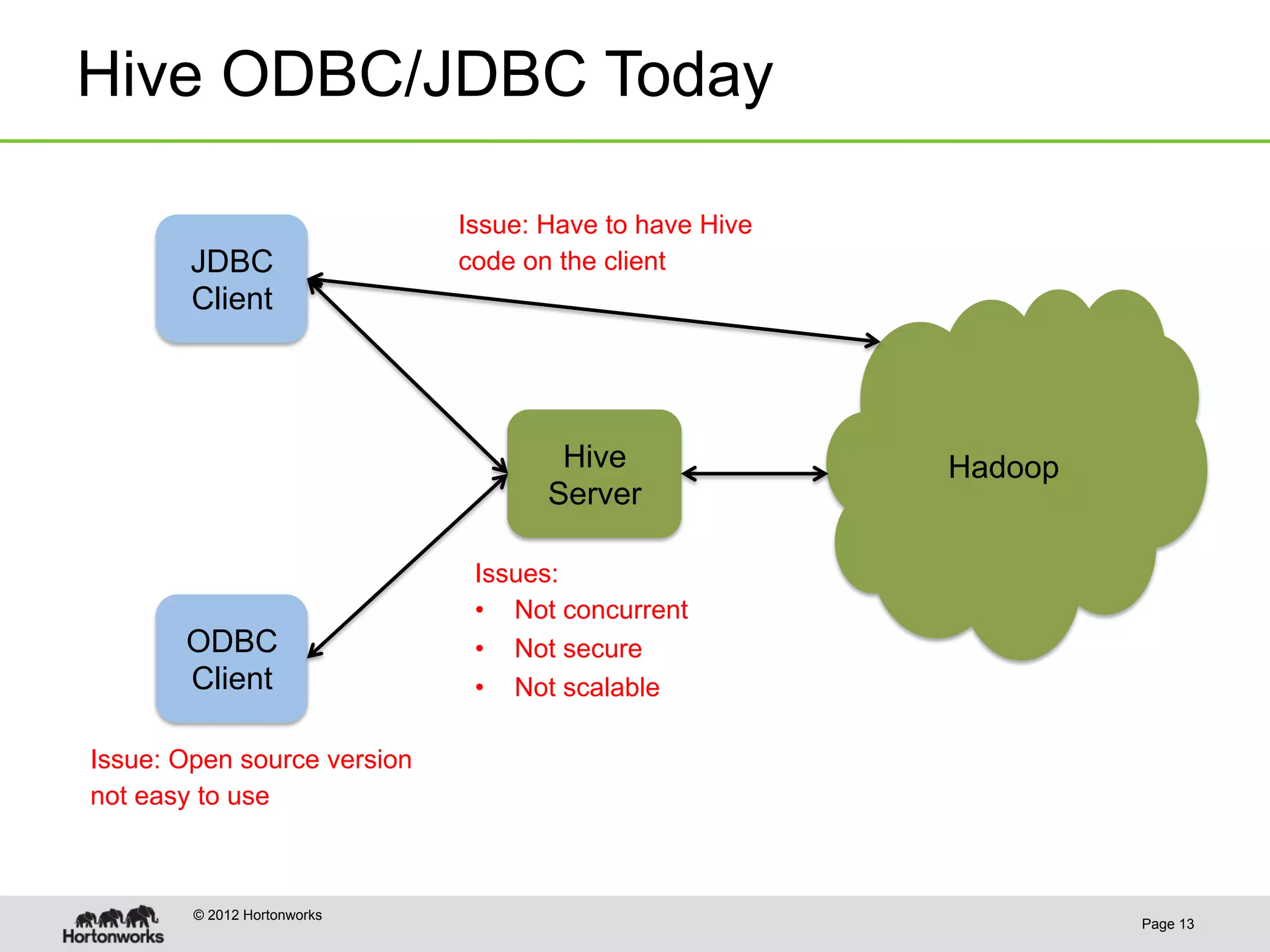
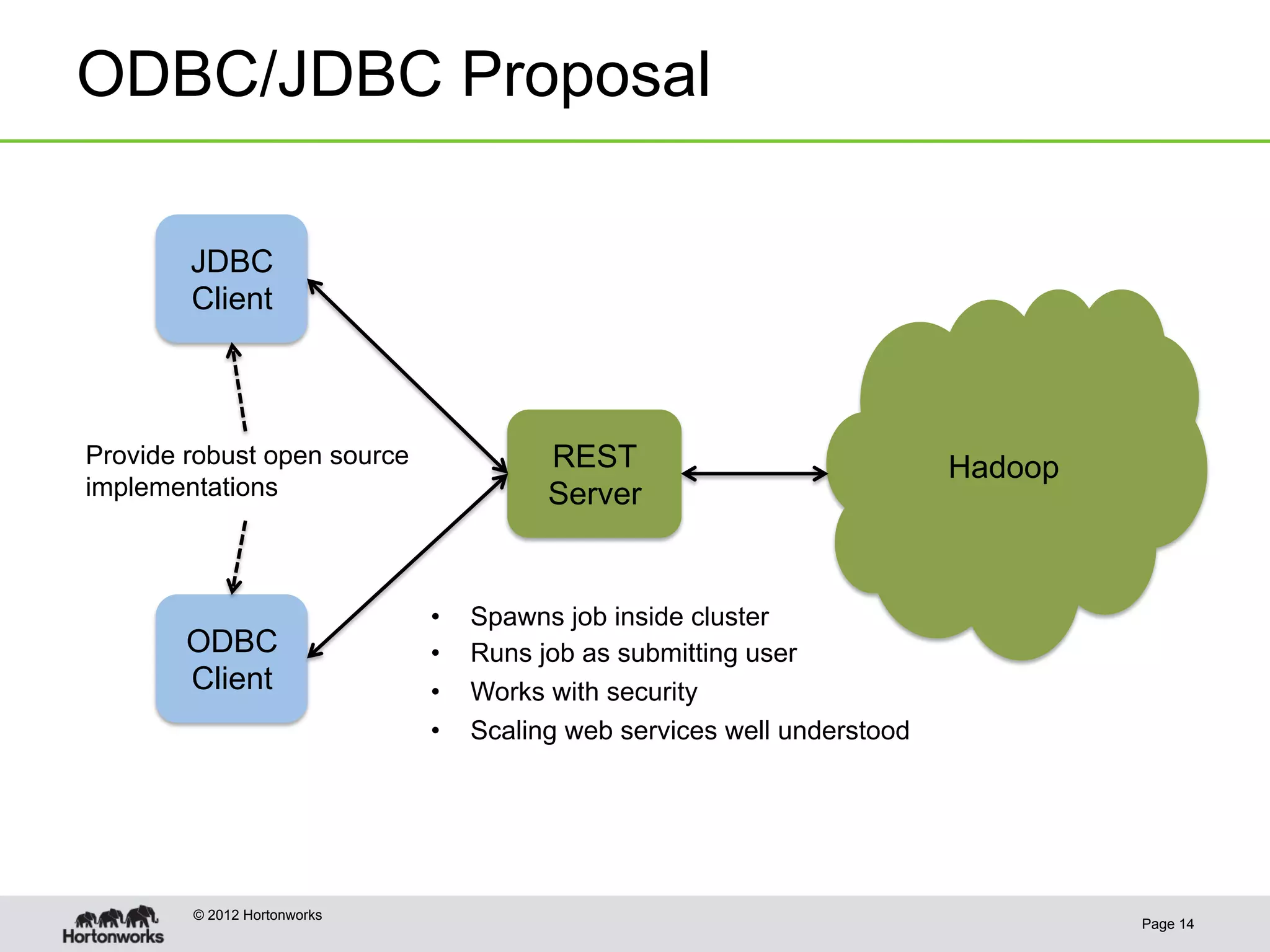


The document discusses the future of HCatalog, focusing on features like the Templeton REST API for managing databases, tables, and partitions. It highlights use cases for reading and writing data in parallel between Hadoop and various systems. Additionally, it addresses issues with current ODBC/JDBC implementations and proposes robust open-source alternatives for better scalability and security.






















































































