Downloaded 13 times


















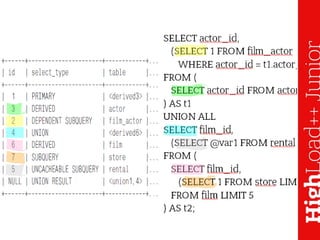












![SHOW EXPLAIN
show processlist;
SHOW EXPLAIN FOR <thread_id>;
show warnings; -- показывает запрос
возможность сохранить в лог медленных запросов
[mysqld]
log-slow-verbosity=query_plan,explain](https://image.slidesharecdn.com/explainmysql-160127203205/85/EXPLAIN-MySQL-38-320.jpg)



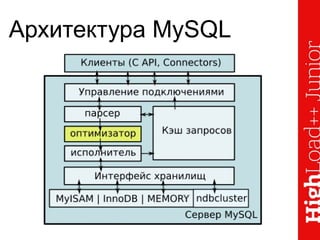
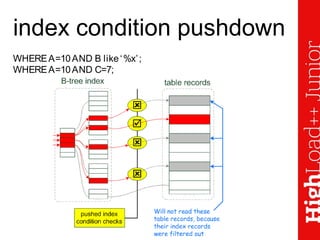
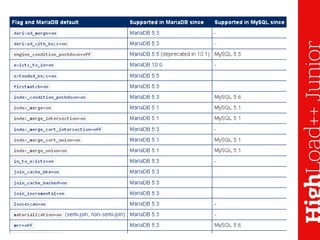
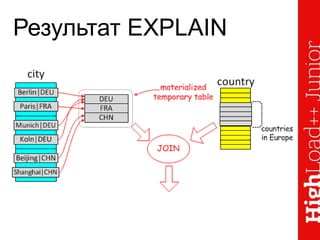
Документ описывает основы индексирования и возможности инструмента explain в MySQL, включая архитектуру, создание индексов и их применение в запросах. Он освещает методы оптимизации, ограничения оптимизатора и различные типы доступов к таблицам, а также демонстрирует примеры использования explain для анализа запросов. Также рассматриваются методы профилирования и секционирования данных для улучшения производительности.















































































