Download as PDF, PPTX





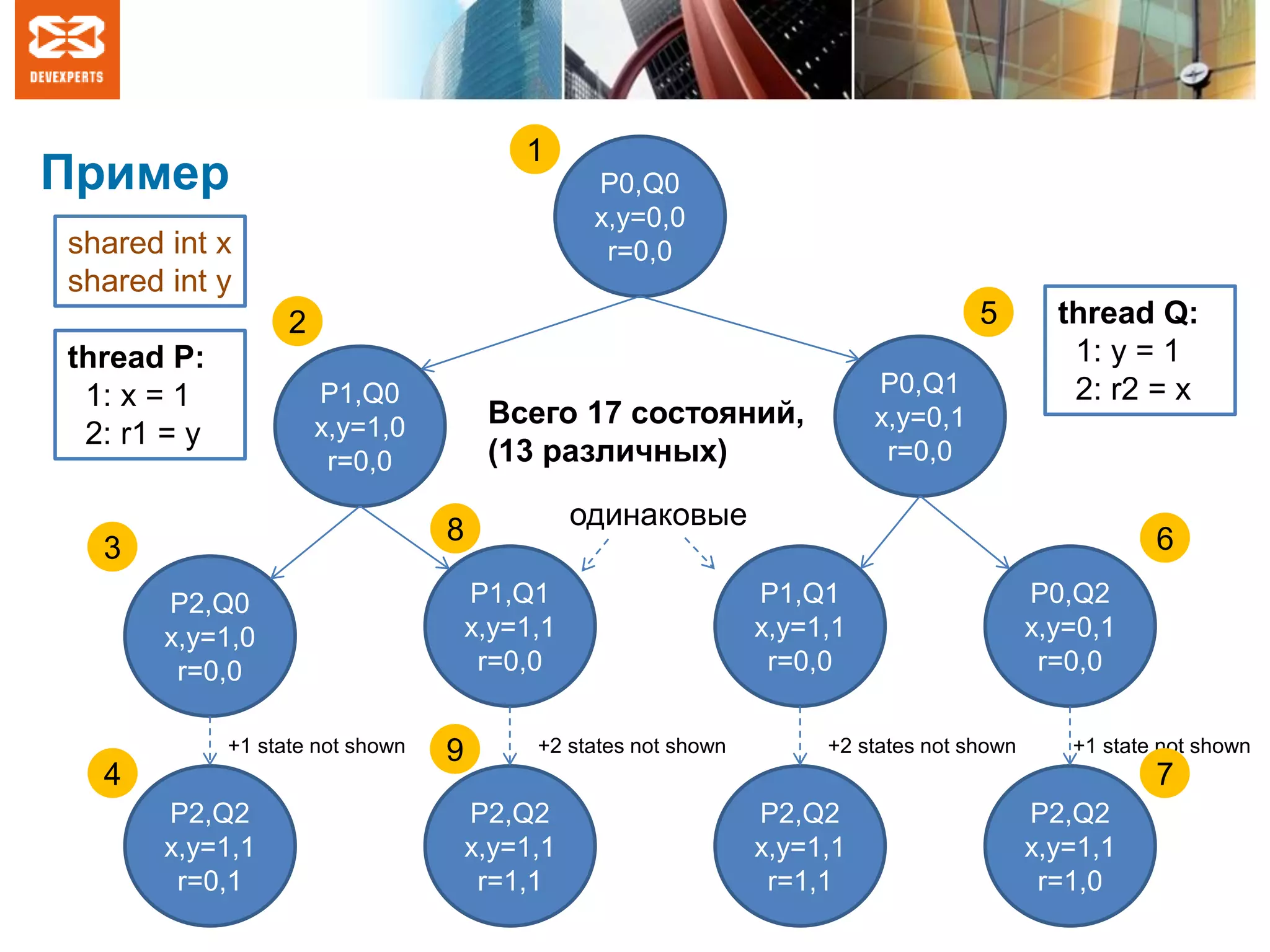
![Попробуем на практике (1)
• Какие пары [r1, r2]
будут наблюдаться?
• Как же так? Ведь пары
[0, 0] вообще не
должно было быть!](https://image.slidesharecdn.com/jpoint2016-160427124558/75/slide-9-2048.jpg)




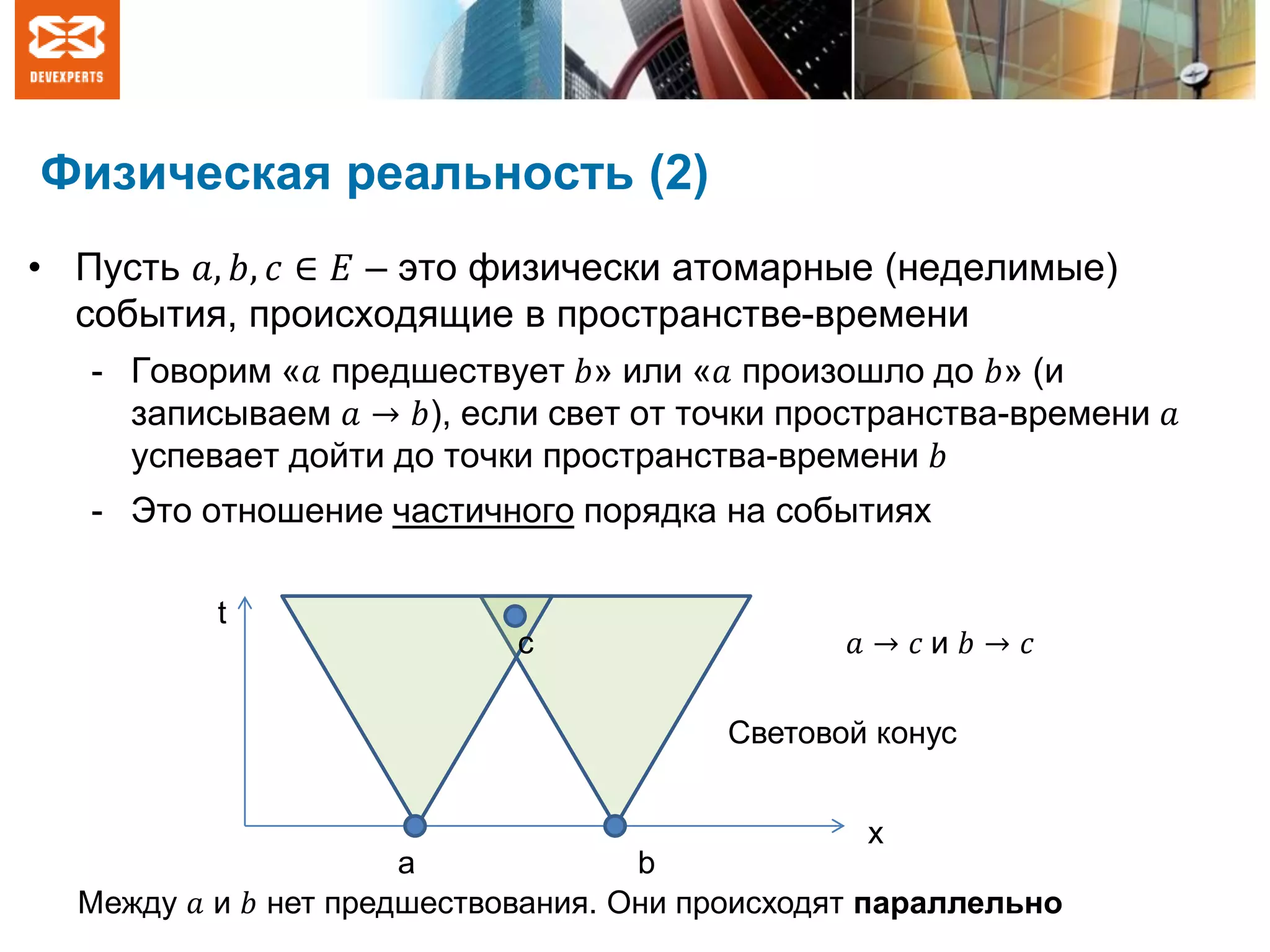


![Обсуждение глобального времени
• Это всего лишь механизм, позволяющий визуализировать факт
существования параллельных операций
• При доказательстве различных фактов и анализе свойств
[исполнений] системы время не используется
- Анализируются только операции и отношения «произошло до»
На самом деле, никакого глобального
времени нет и не может быть из-за
физических ограничений](https://image.slidesharecdn.com/jpoint2016-160427124558/75/slide-17-2048.jpg)













![Попробуем на практике (2)
• Какие пары [r1, r2]
будут наблюдаться?
• Что мы и ожидали
исходя из модели
чередования
операций!](https://image.slidesharecdn.com/jpoint2016-160427124558/75/slide-32-2048.jpg)





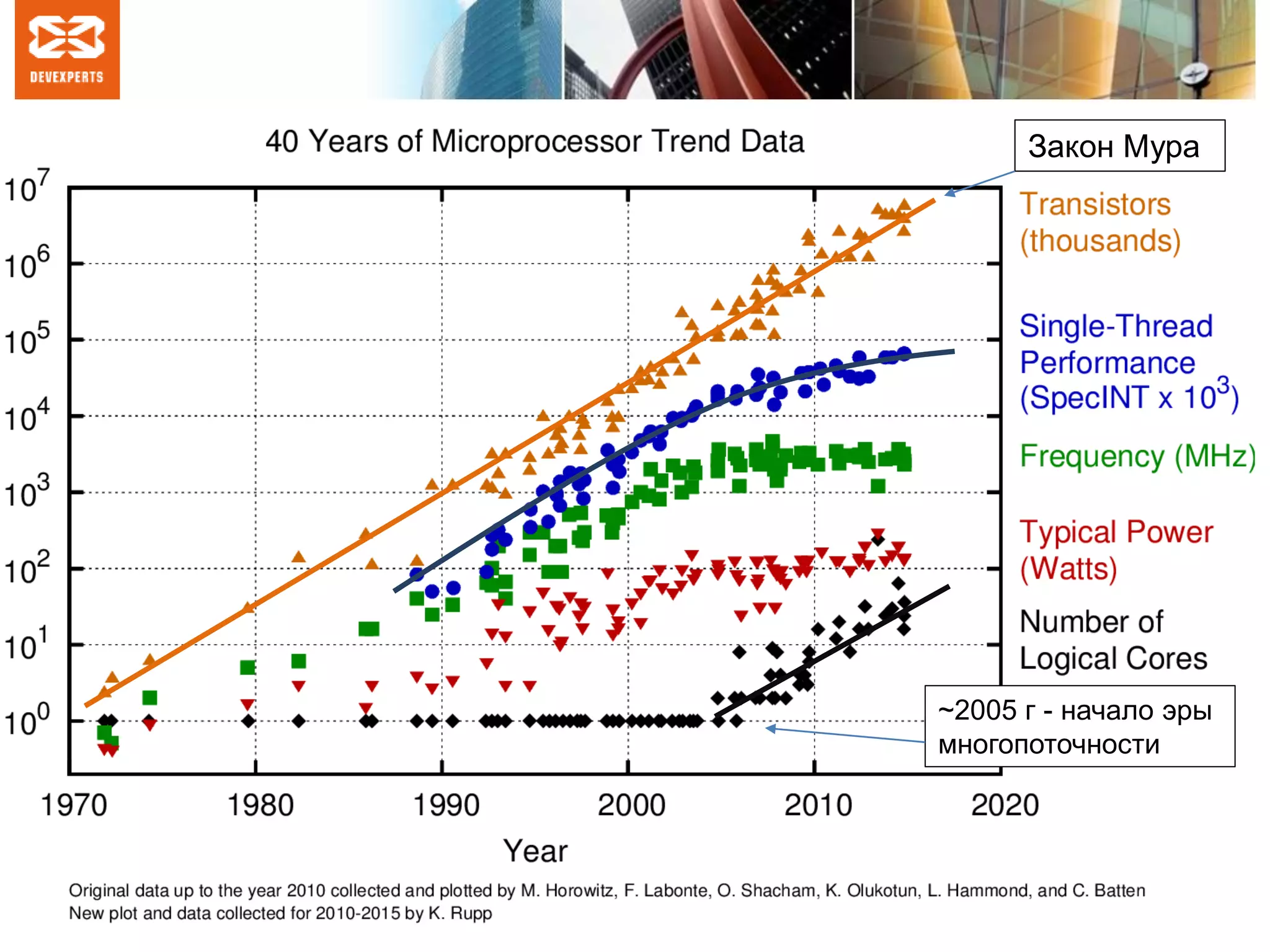
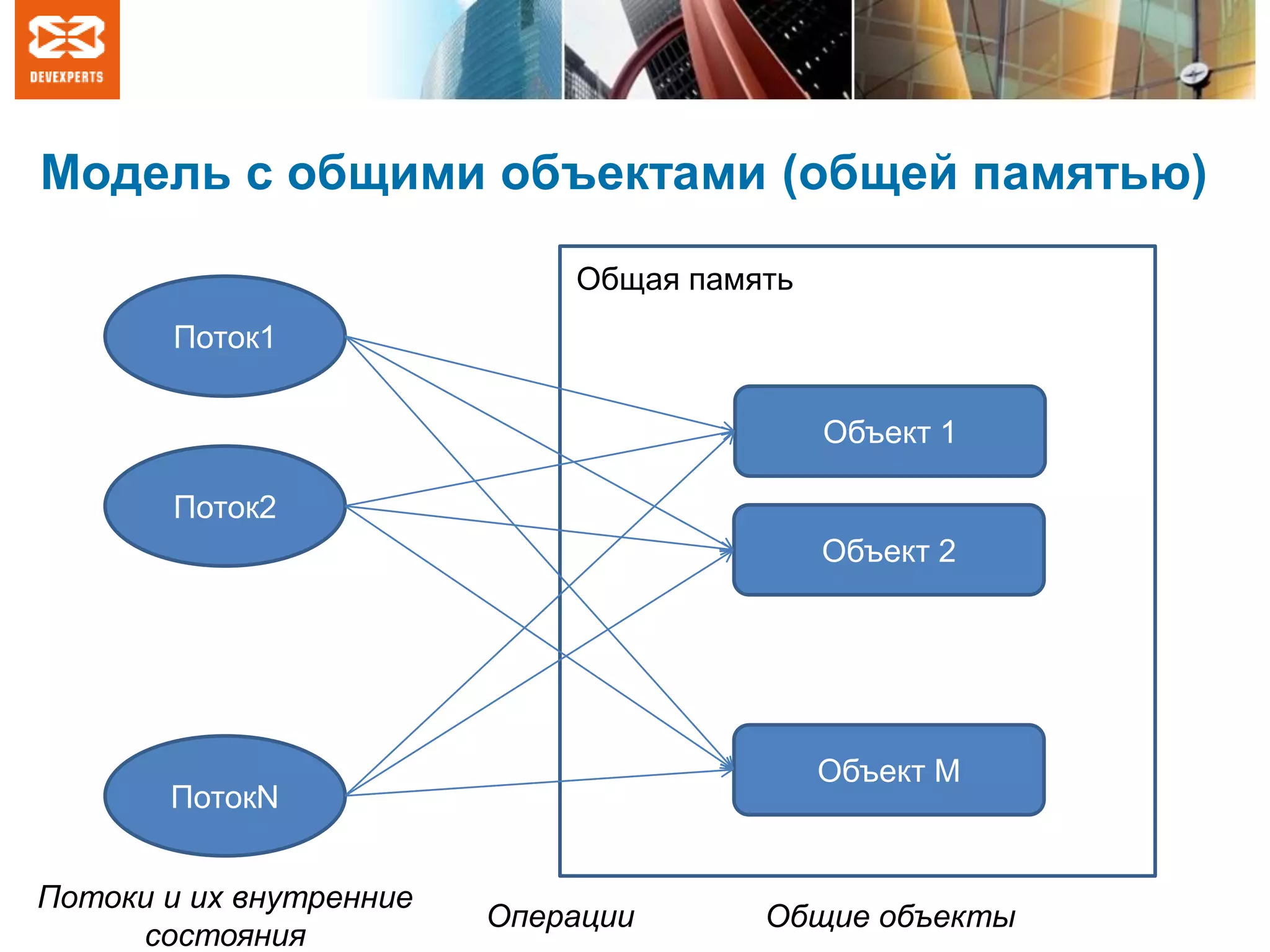
Документ обсуждает теорию и практику многопоточности, включая закон Мура, формальные модели параллельных вычислений и важность корректности алгоритмов. Рассматриваются общие переменные как основы параллельных алгоритмов, а также модели чередования и глобального времени, их применение и ограничения. Обсуждаются проблемы линеаризуемости и порядок операций в контексте синхронизации потоков в современных языках программирования.



































































