Download to read offline




![● Isolation — выполнение параллельных транзакций имеет
тот же эффект что и их последовательное применение
● Consistency без isolation не достижим
● Пусть есть x, y, z – данные к которым осуществляется
совместный доступ
● Расписание (schedule) — возможная история
выполнения транзакций, конкретный порядок операций
чтения и записи относительно друг друга
E = r1[x] w1[x] w2[y] r2[z]
Isolation](https://image.slidesharecdn.com/osipov2016-160328131408/85/slide-5-320.jpg)







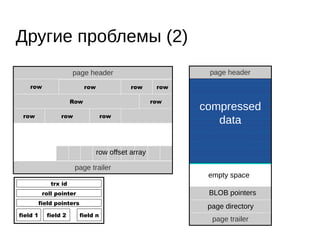





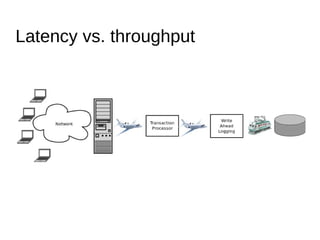







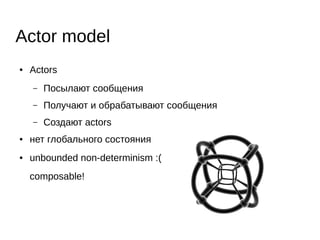
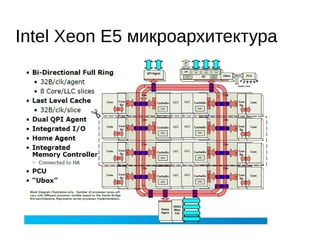






Документ охватывает современные алгоритмы и структуры данных для систем управления базами данных в оперативной памяти, подчеркнув важность атомарности, совместимости, изоляции и долговечности транзакций. Рассматриваются проблемы блокировок и подходы к параллелизму, такие как модель актеров и алгоритмы wait-free. Важное внимание уделяется специализированным аллокаторам памяти и структурам данных, обеспечивающим высокую производительность и низкую задержку.






















































































