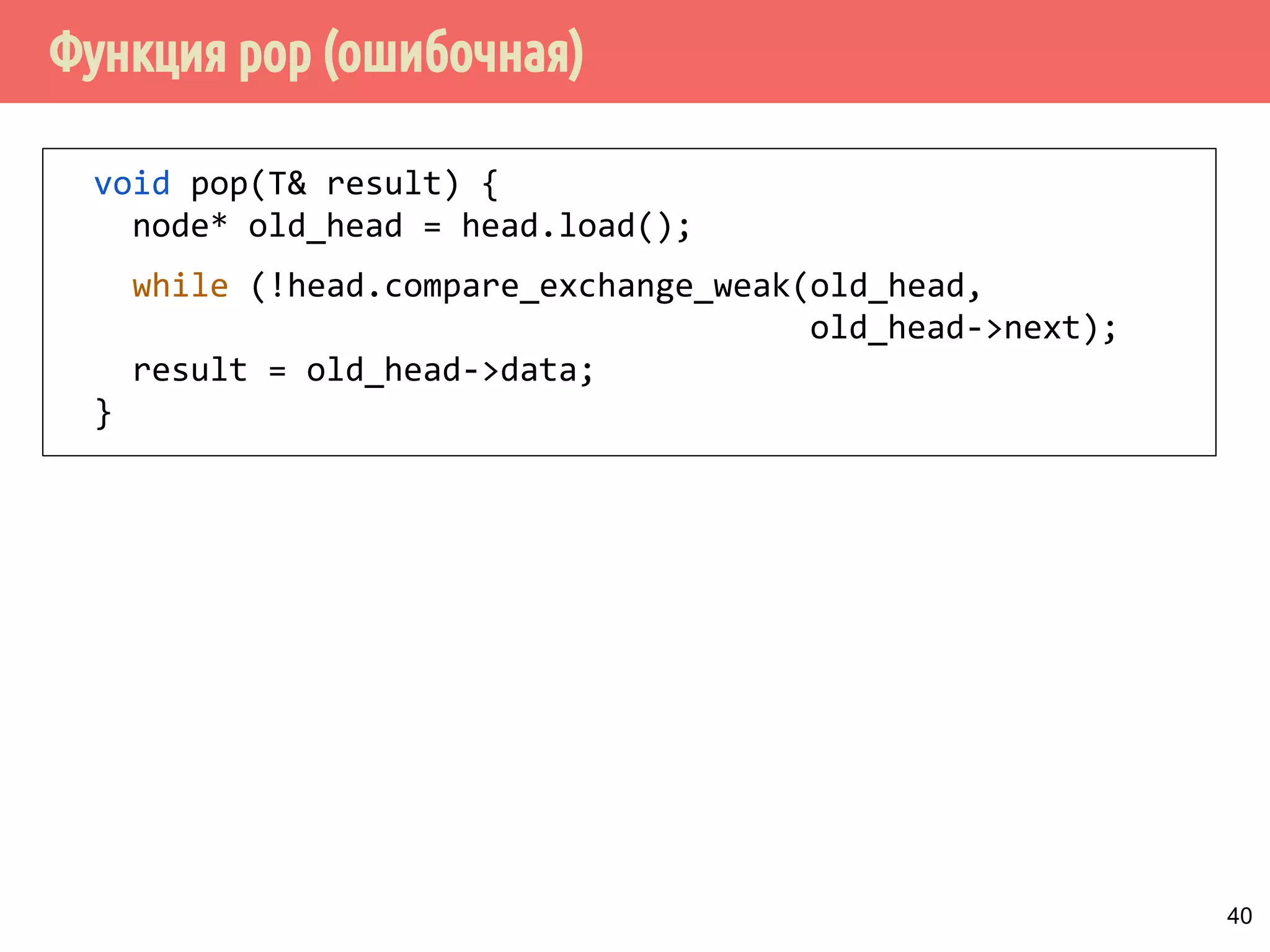
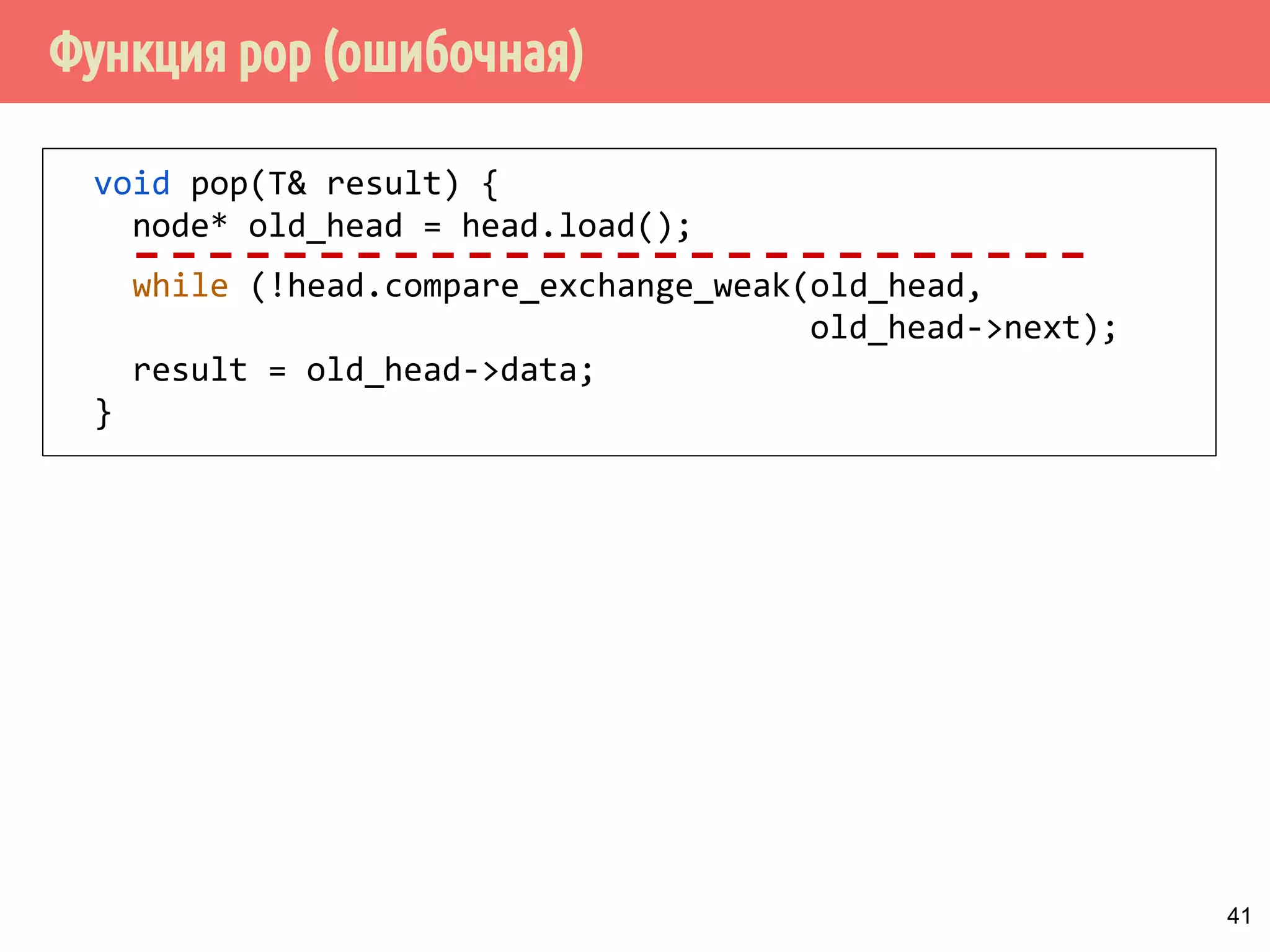
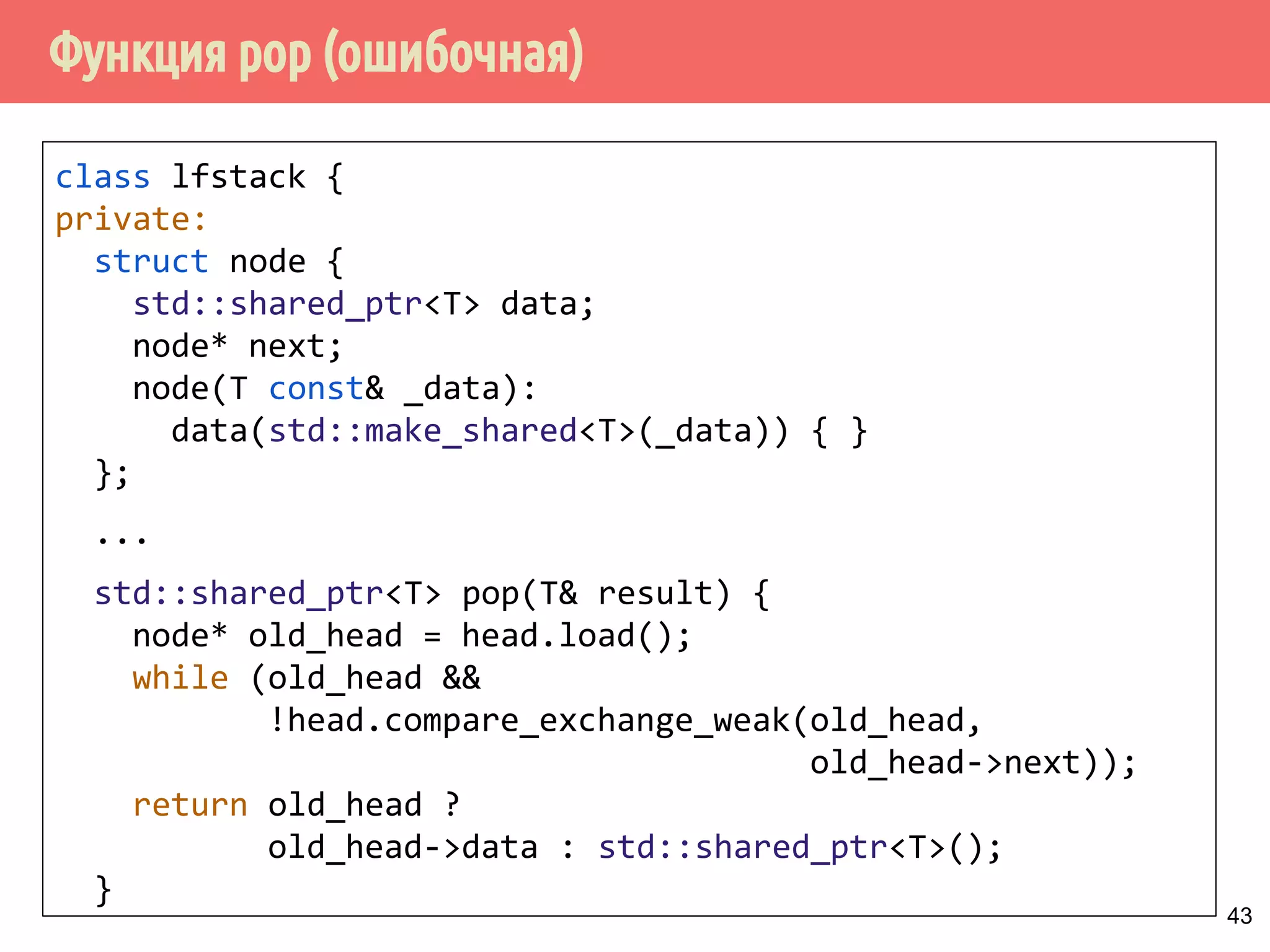
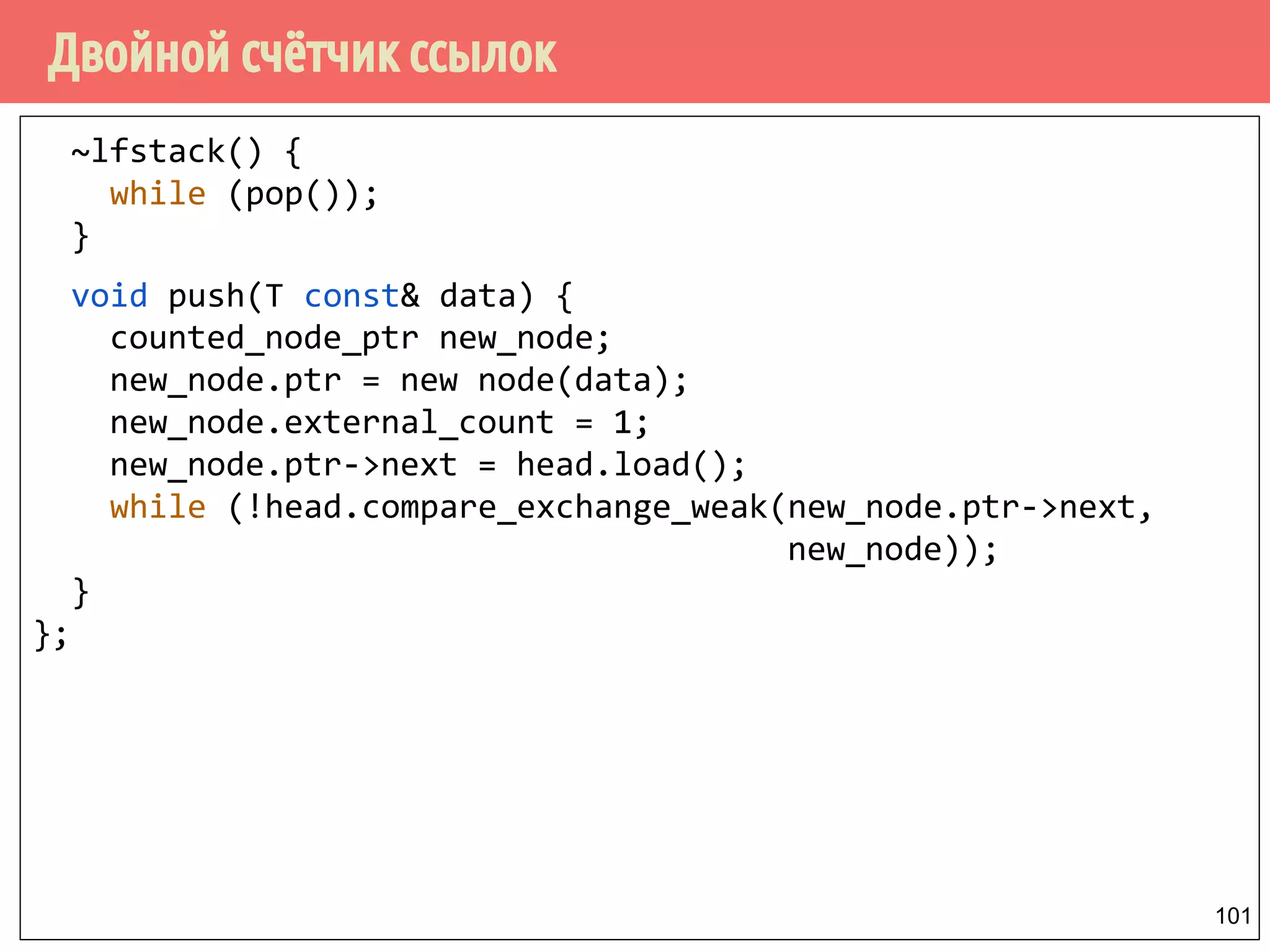
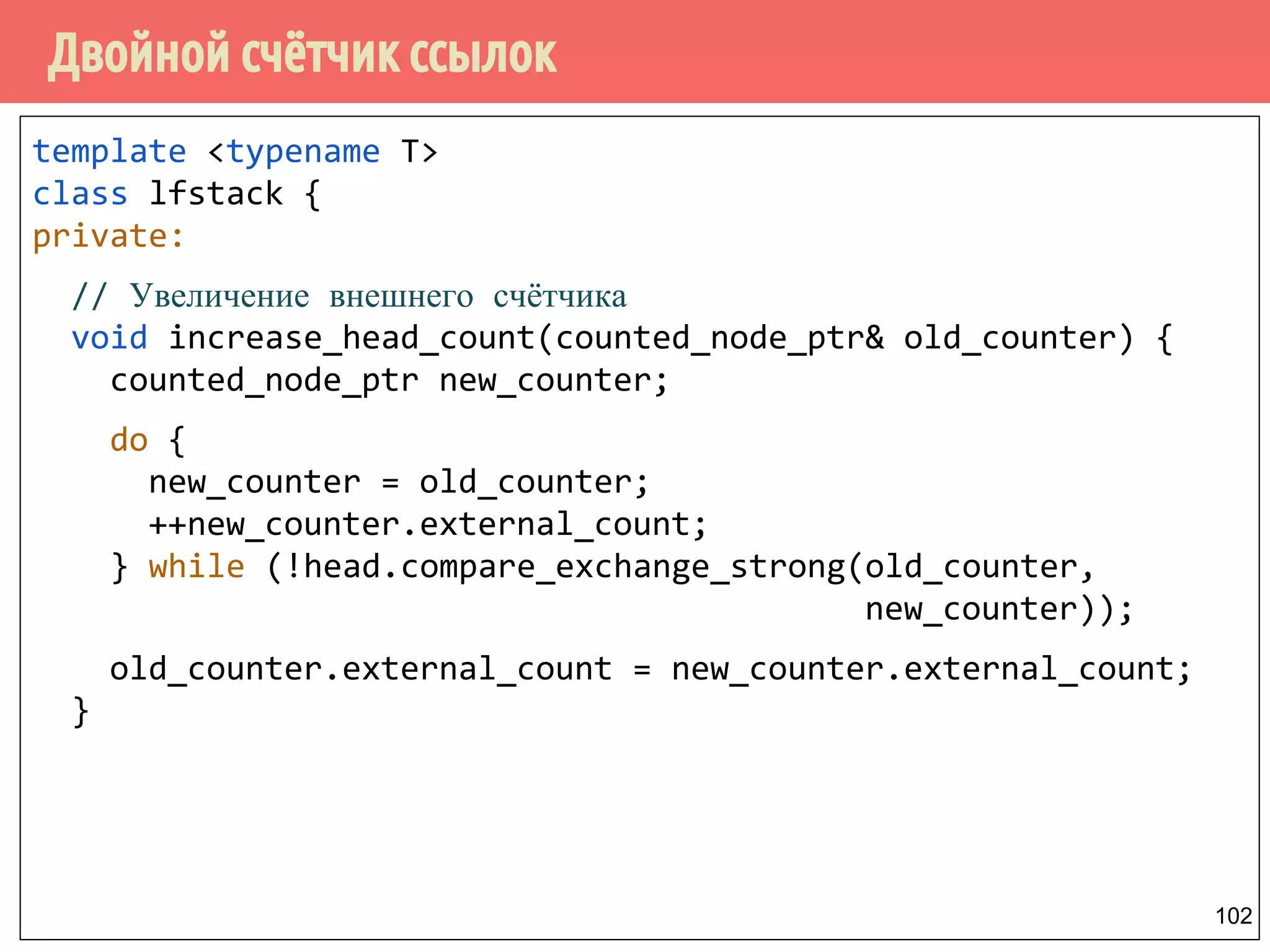
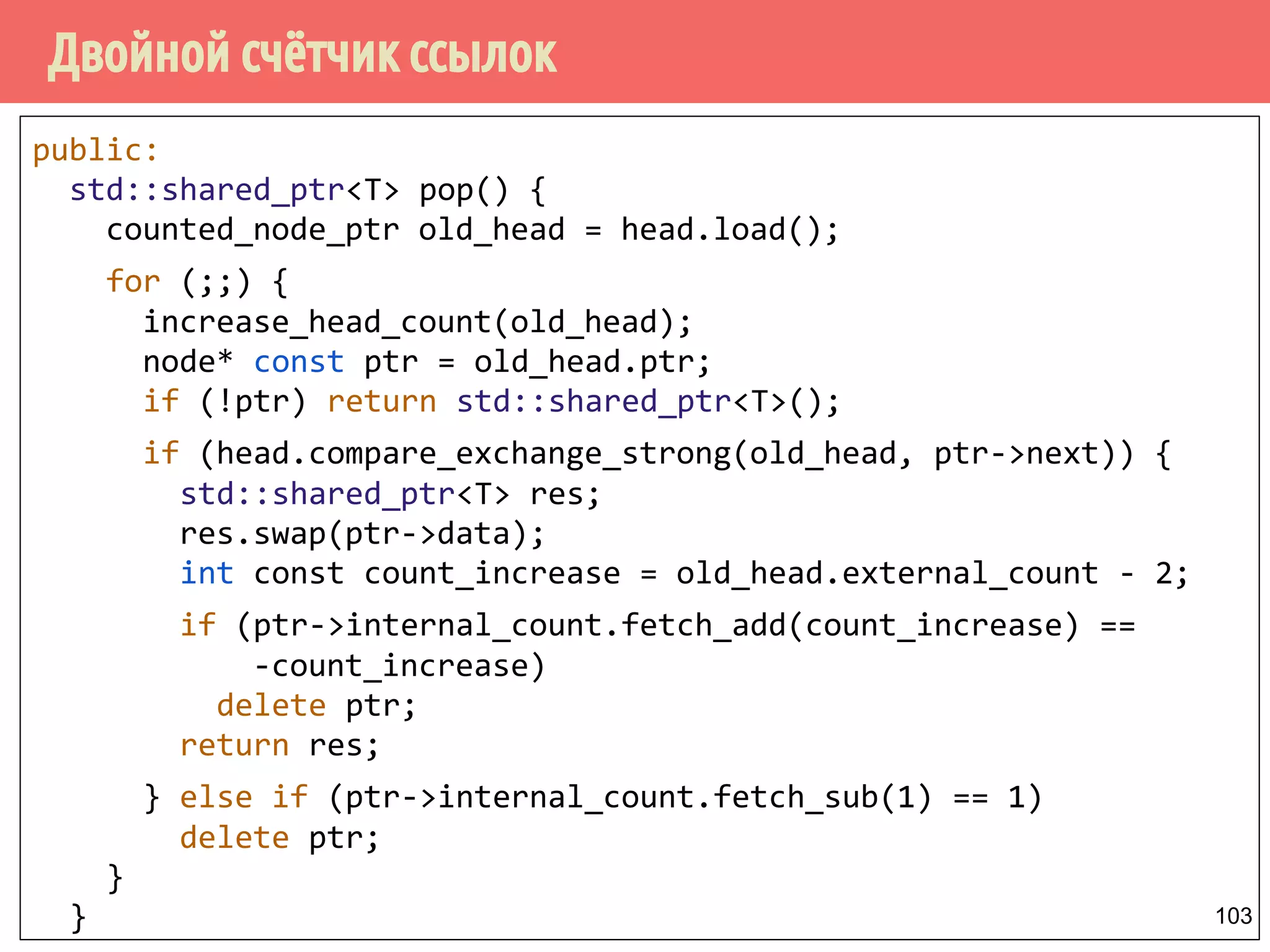
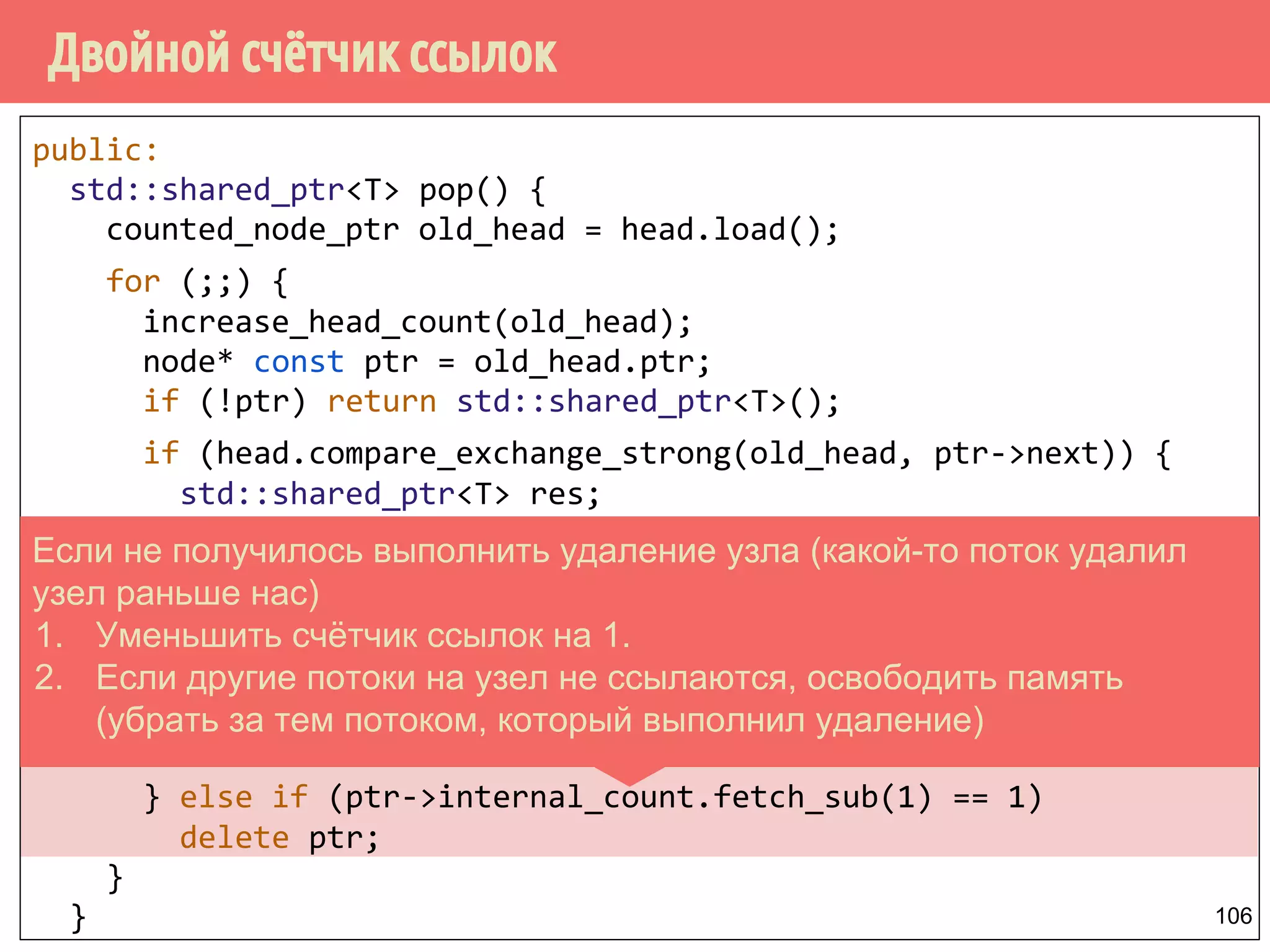
Download as PDF, PPTX







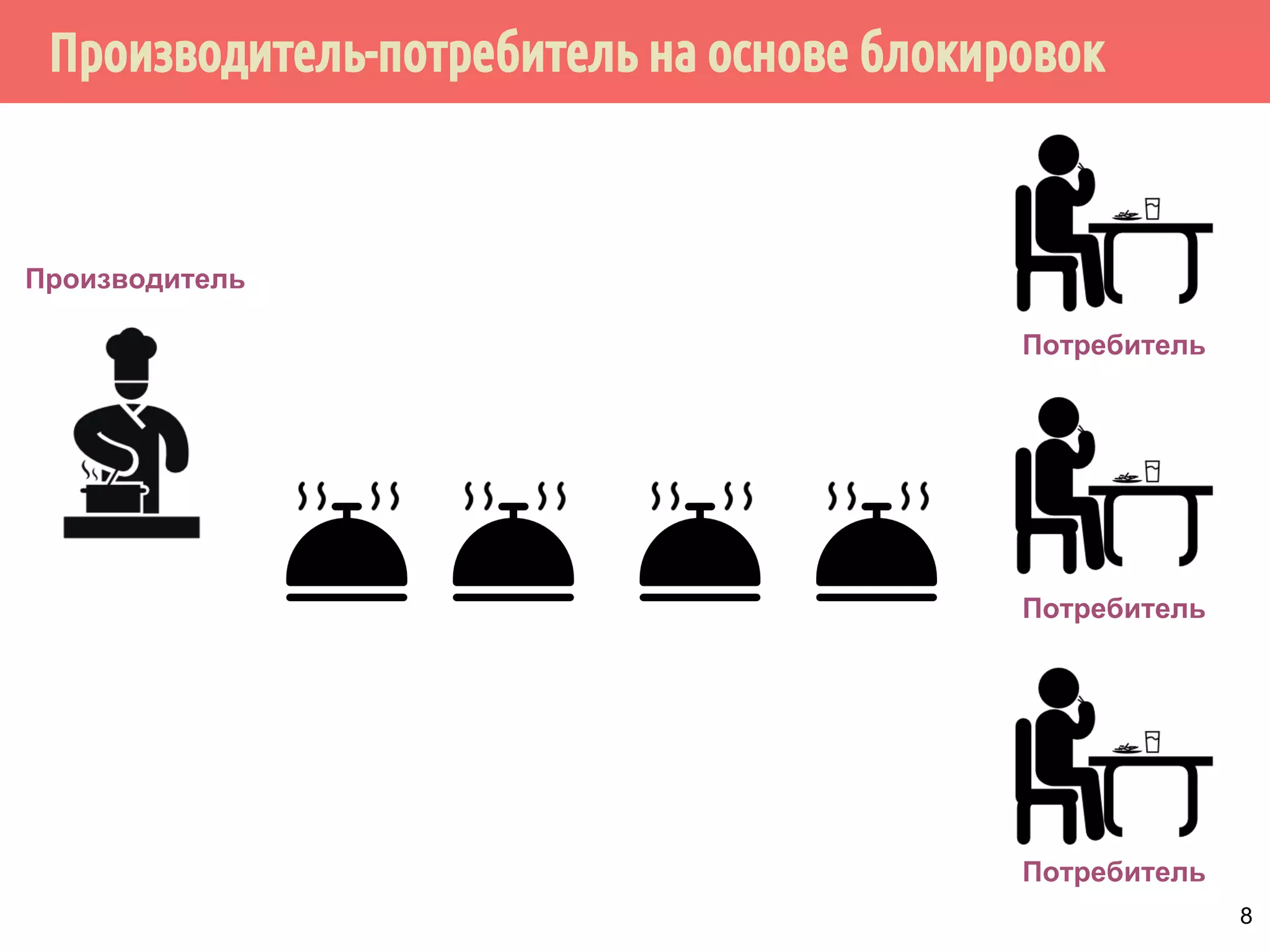

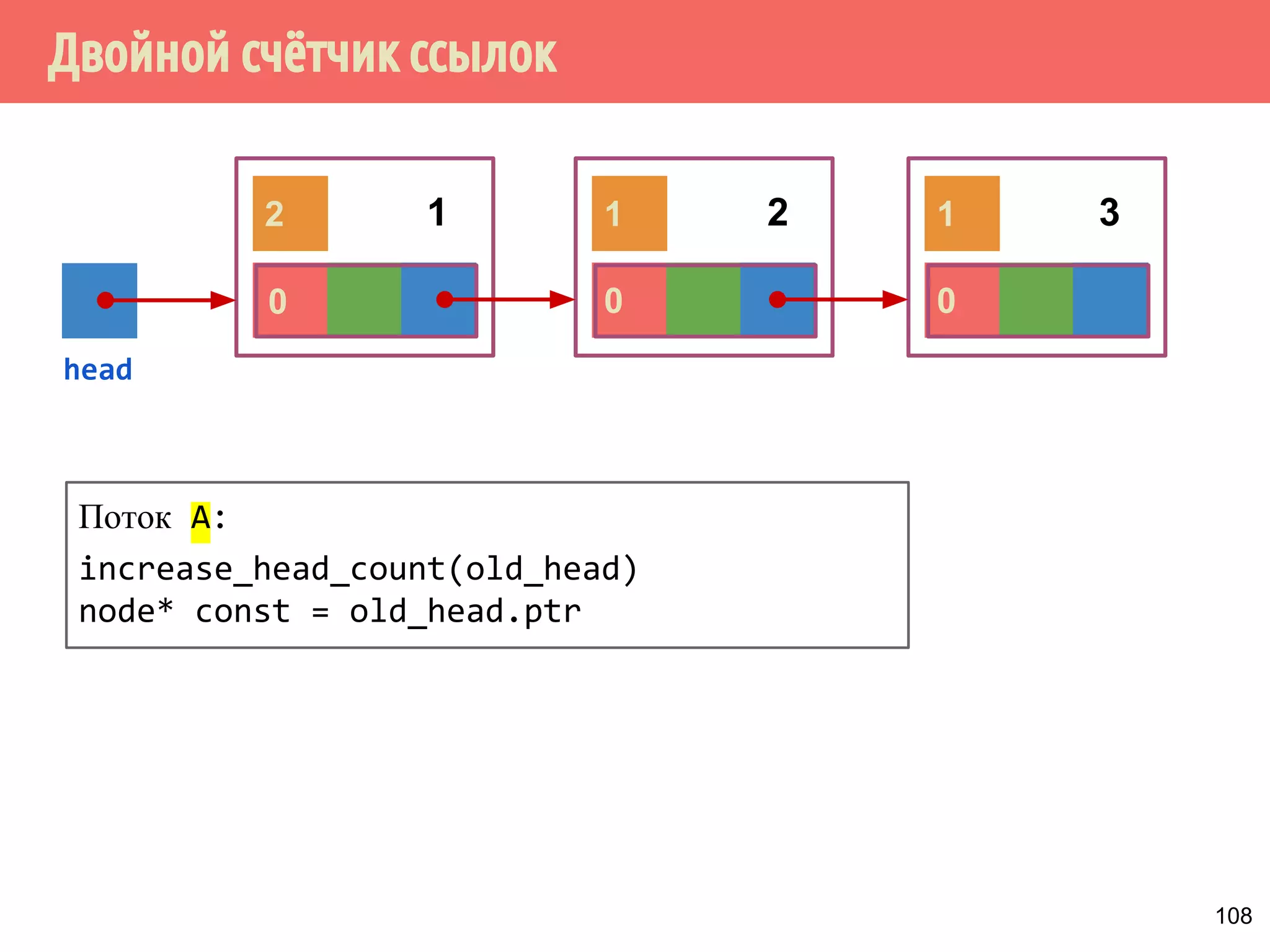
![Производитель-потребитель на основе блокировок
void consumer() {
task = nullptr;
while (task != done) {
std::unique_lock<std::mutex> lock{mut};
cv.wait(mut, []{ return queue.empty(); });
task = queue.first();
if (task != done)
queue.pop();
}
if (task != done)
DoWork(task);
}
10](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-10-2048.jpg)
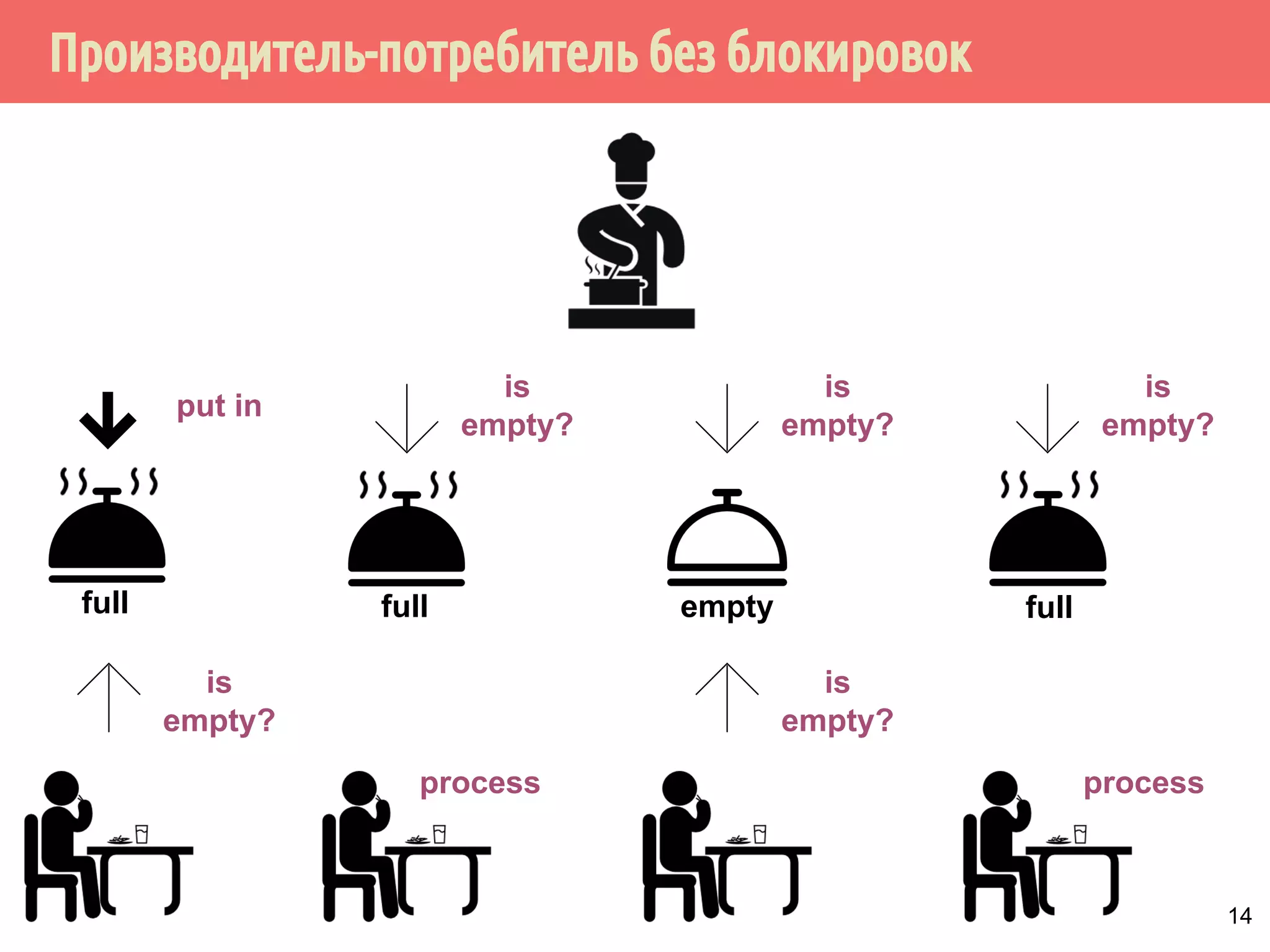
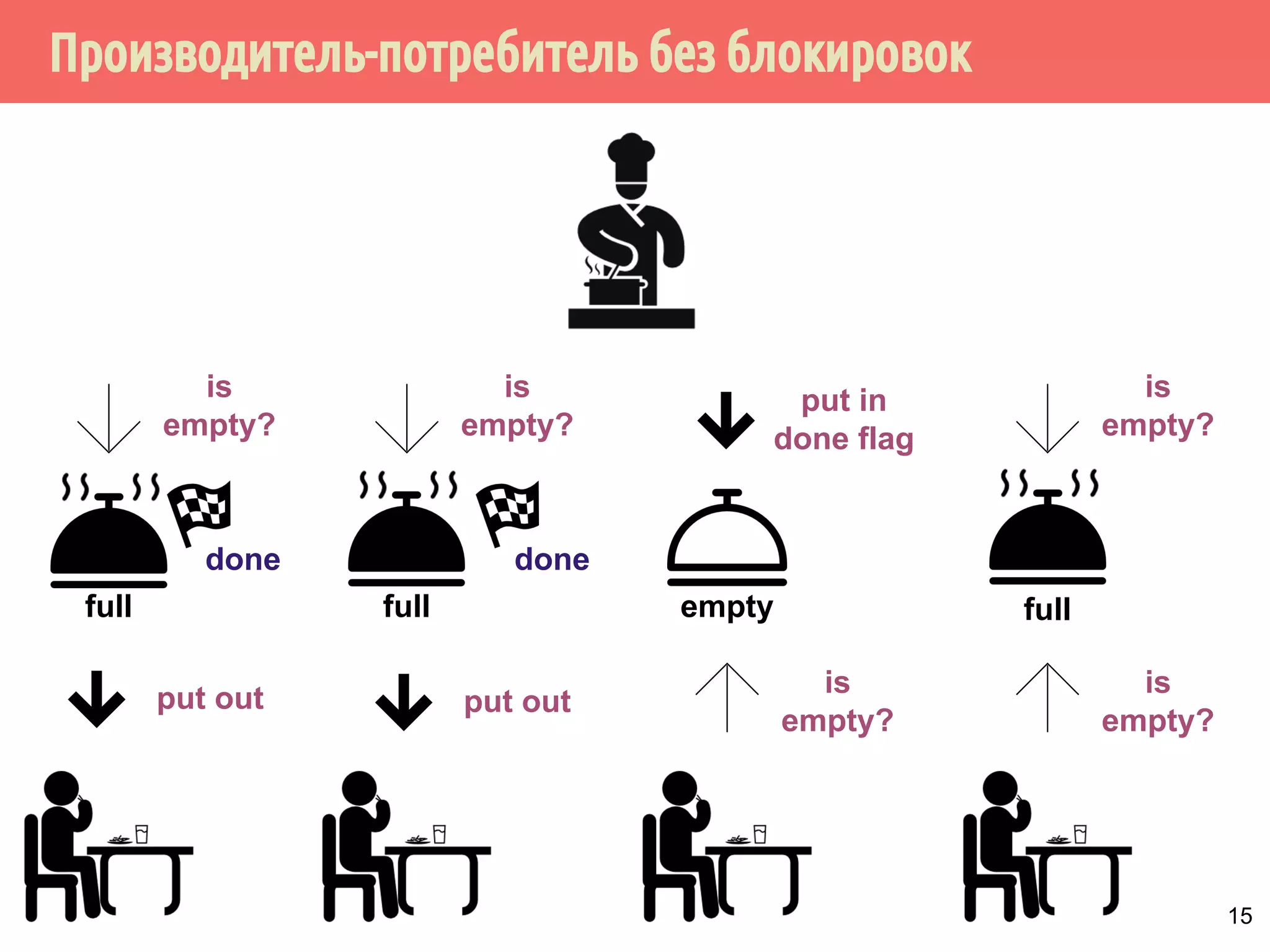
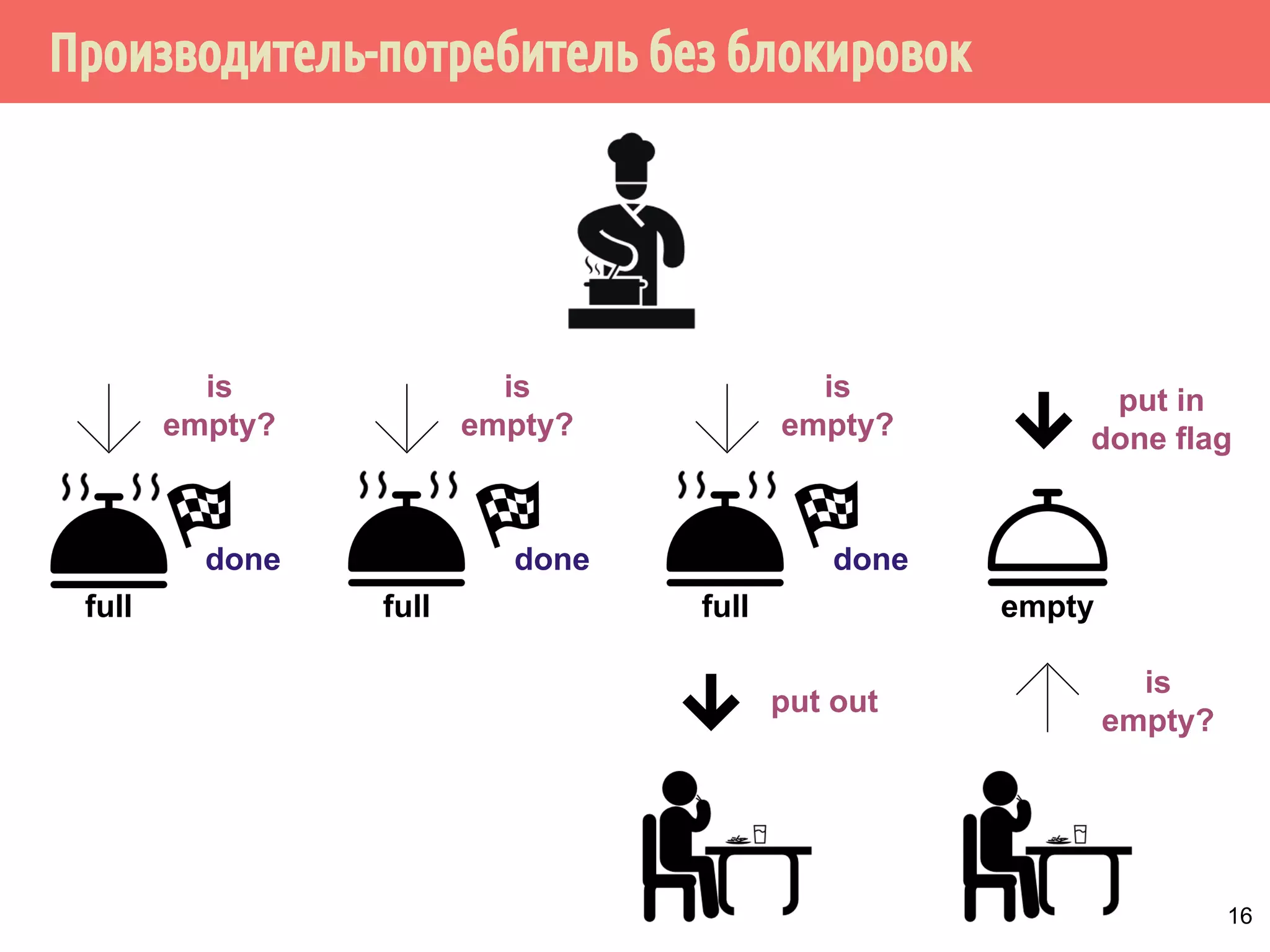
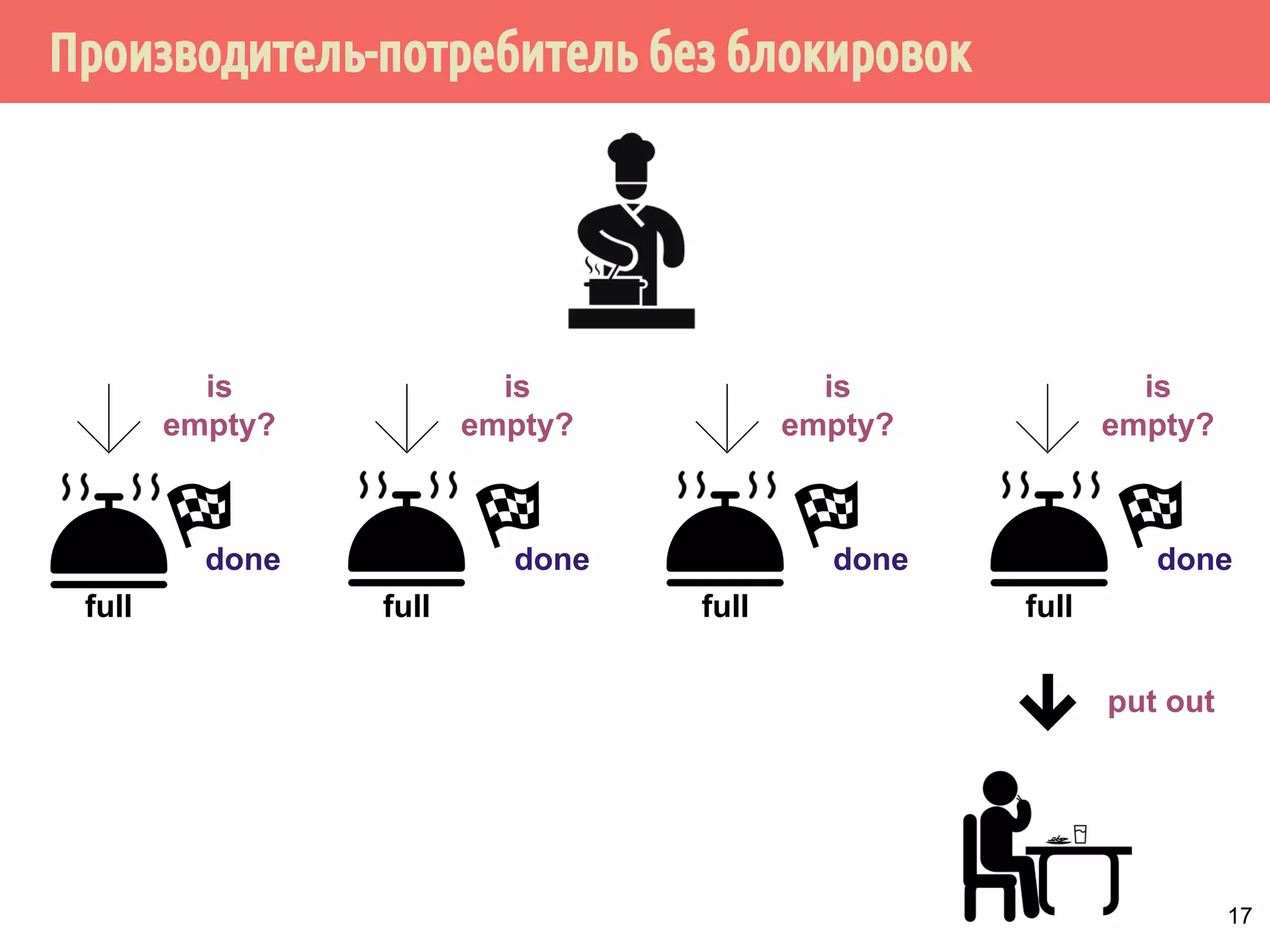
![Производитель
20
curr = 0; // указатель на текущий слот
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null) // если null, то проверить
curr = (curr + 1) % numOfConsumers; // следующий слот
slot[curr] = task;
sem[curr].signal();
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-20-2048.jpg)
![Производитель
21
curr = 0; // указатель на текущий слот
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null) // если null, то проверить
curr = (curr + 1) % numOfConsumers; // следующий слот
slot[curr] = task;
sem[curr].signal();
}
// Фаза 2: выставить флаги “done” во всех слотах
numNotified = 0;
while (numNotified < numOfConsumers) {
while (slot[curr] != null) // если null, то проверить
curr = (curr + 1) % numOfConsumers; // следующий
slot[curr] = done; // освободить слот
sem[curr].signal();
++numNotified;
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-21-2048.jpg)
![Потребитель
22
task = null;
while (task != done)
// Дождаться, когда слот будет полным
while ((task = slot[mySlot]) == null)
sem[mySlot].wait();
if (task != done) {
slot[mySlot] = null; // помечаем слот пустым
DoWork(task); // выполняем задачу
} // вне критической секции
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-22-2048.jpg)
![Потребитель
23
task = null;
while (task != done)
// Дождаться, когда слот будет полным
while ((task = slot[mySlot]) == null)
sem[mySlot].wait();
if (task != done) {
slot[mySlot] = null; // помечаем слот пустым
DoWork(task); // выполняем задачу
} // вне критической секции
}
Как применить модель памяти С++?](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-23-2048.jpg)
![Производитель, модель памяти С++
24
curr = 0;
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = task; // release non-null
sem[curr].signal();
}
// Фаза 2: выставить флаги “done” во всех слотах
numNotified = 0;
while (numNotified < numOfConsumers) {
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = done; // release done
sem[curr].signal();
++numNotified;
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-24-2048.jpg)
![Птребитель, модель памяти С++
25
task = null;
while (task != done)
// Дождаться, когда слот будет полным
while ((task = slot[mySlot]) // acquire non-null
== null)
sem[mySlot].wait();
if (task != done) {
slot[mySlot] = null; // release null
DoWork(task);
}
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-25-2048.jpg)
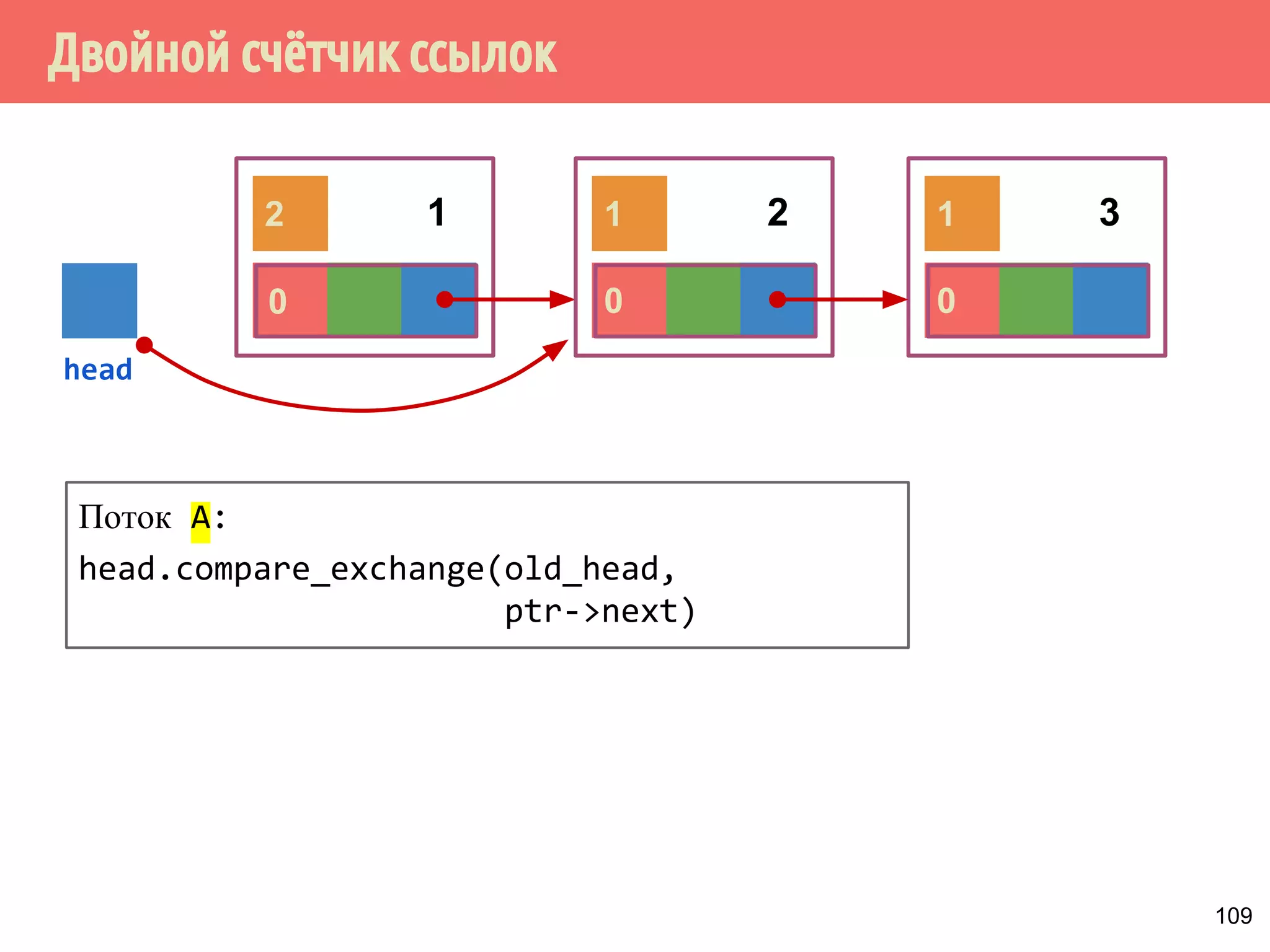
![Производитель-потребитель, класс алгоритма
26
curr = 0;
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = task; // release non-null
sem[curr].signal();
}
// Фаза 2: выставить флаги “done” во всех слотах
numNotified = 0;
while (numNotified < numOfConsumers) {
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = done; // release done
sem[curr].signal();
++numNotified;
}
Алгоритм - свободный от ожиданий, свободный от
блокировок или свободный от остановок?](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-26-2048.jpg)
![Производитель-потребитель, класс алгоритма
27
curr = 0;
while (ThereAreMoreTasks()) {
task = AllocateAndBuildNewTask();
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = task; // release non-null
sem[curr].signal();
}
// Фаза 2: выставить флаги “done” во всех слотах
numNotified = 0;
while (numNotified < numOfConsumers) {
while (slot[curr] != null) // acquire null
curr = (curr + 1) % numOfConsumers;
slot[curr] = done; // release done
sem[curr].signal();
++numNotified;
}
Алгоритм - свободный от ожиданий, свободный от
блокировок или свободный от остановок?
Этап 2:
Свободная от остановок
Этап 1:
Свободный от ожиданий](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-27-2048.jpg)
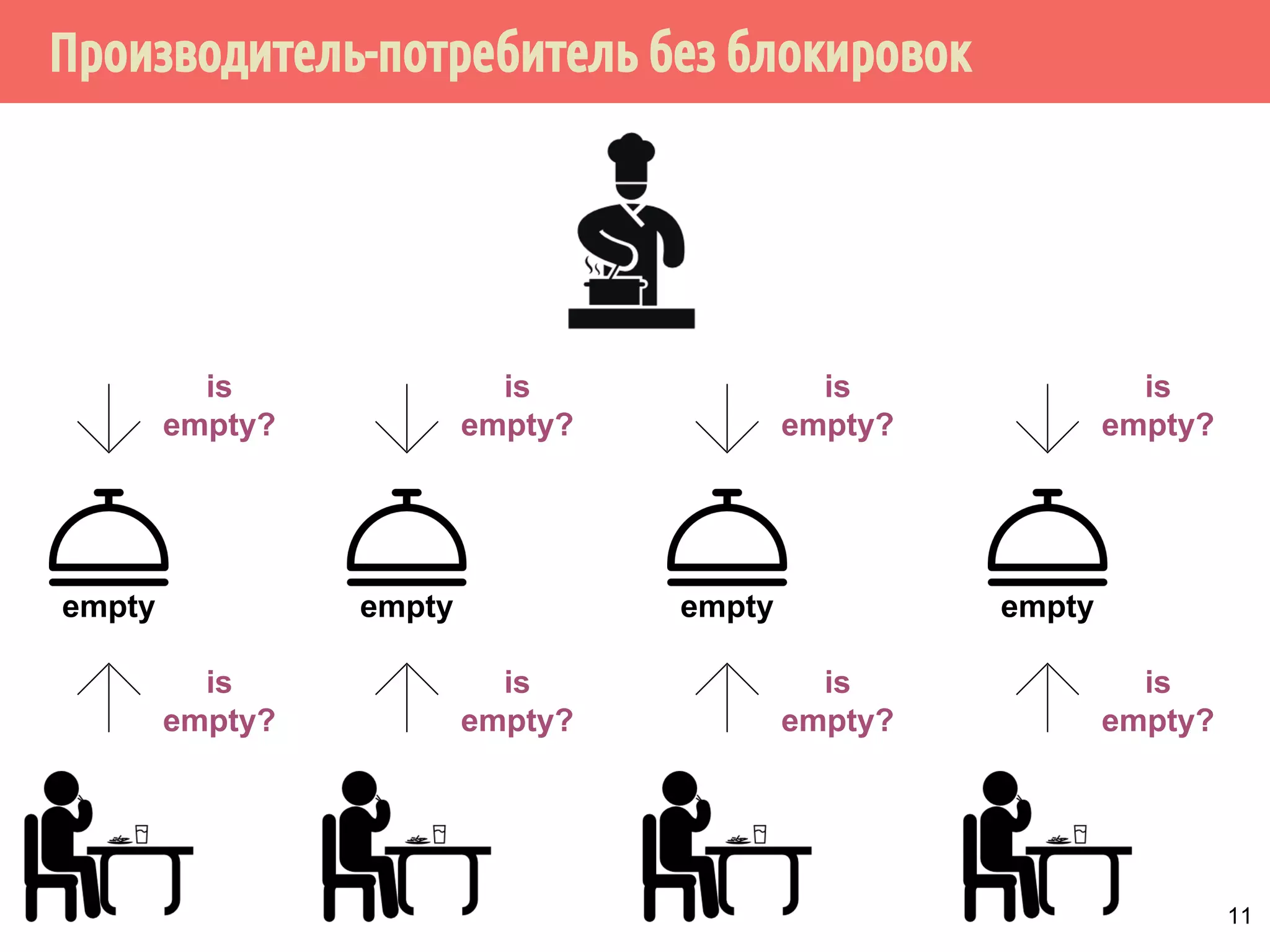
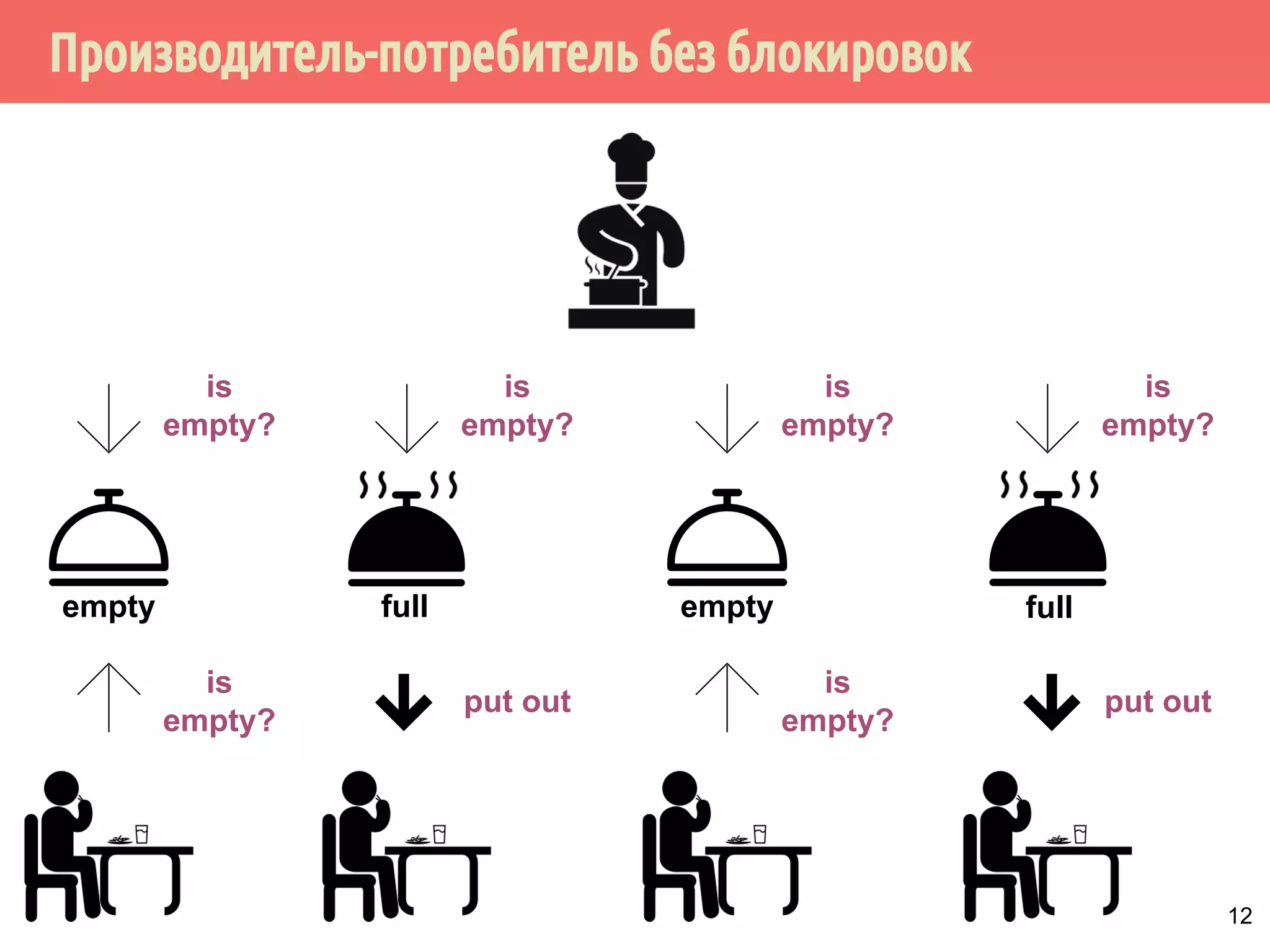
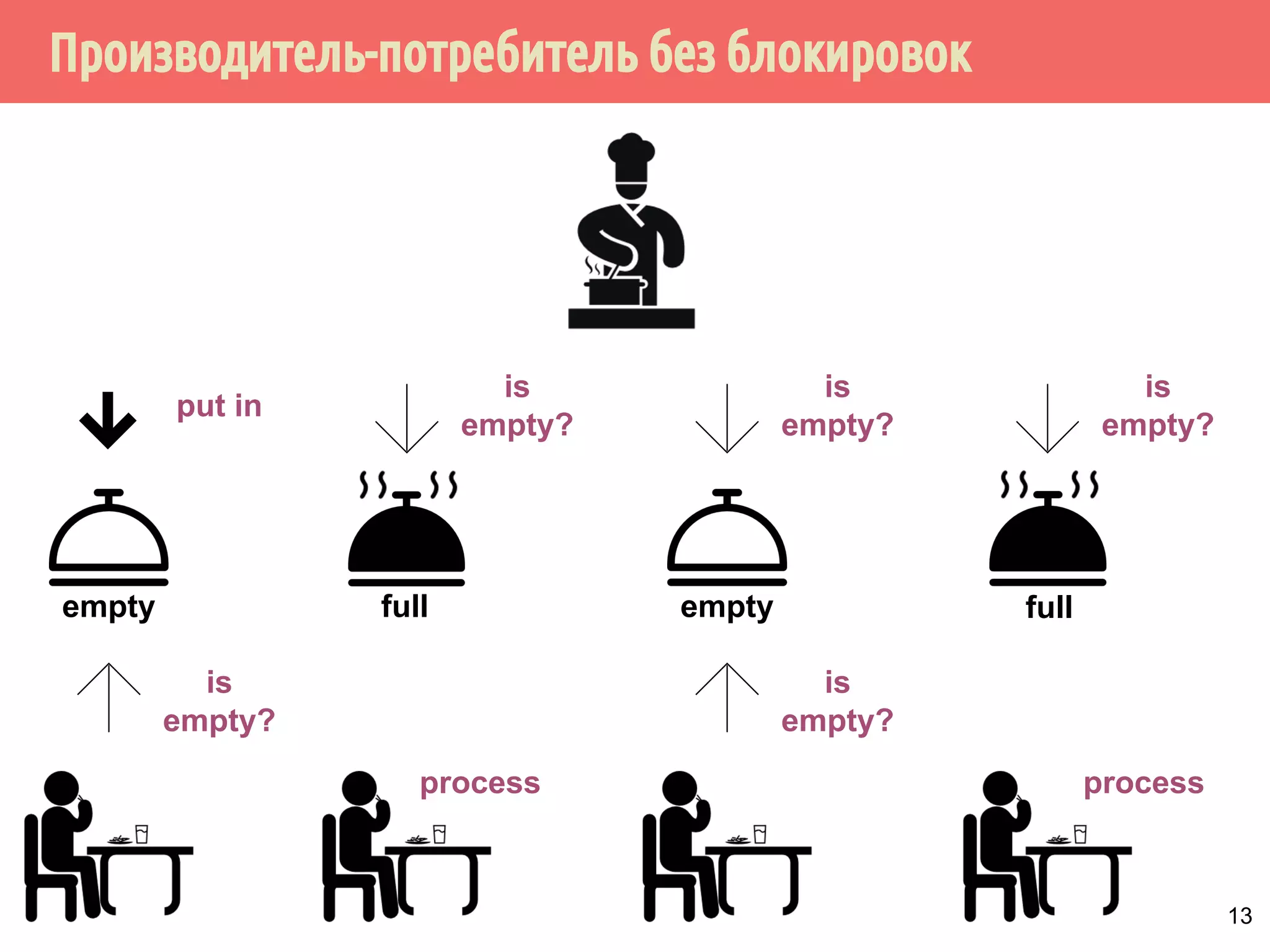
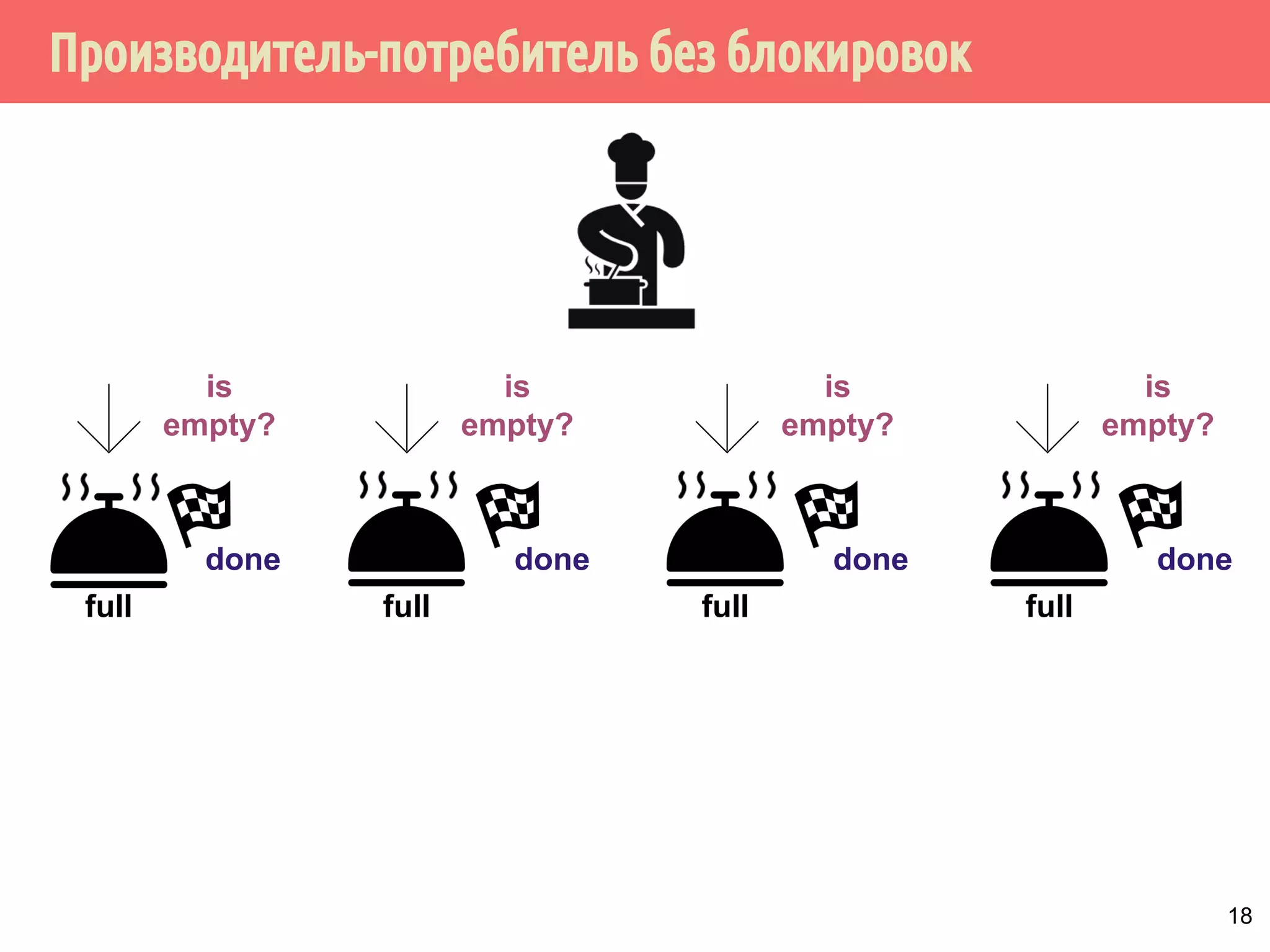
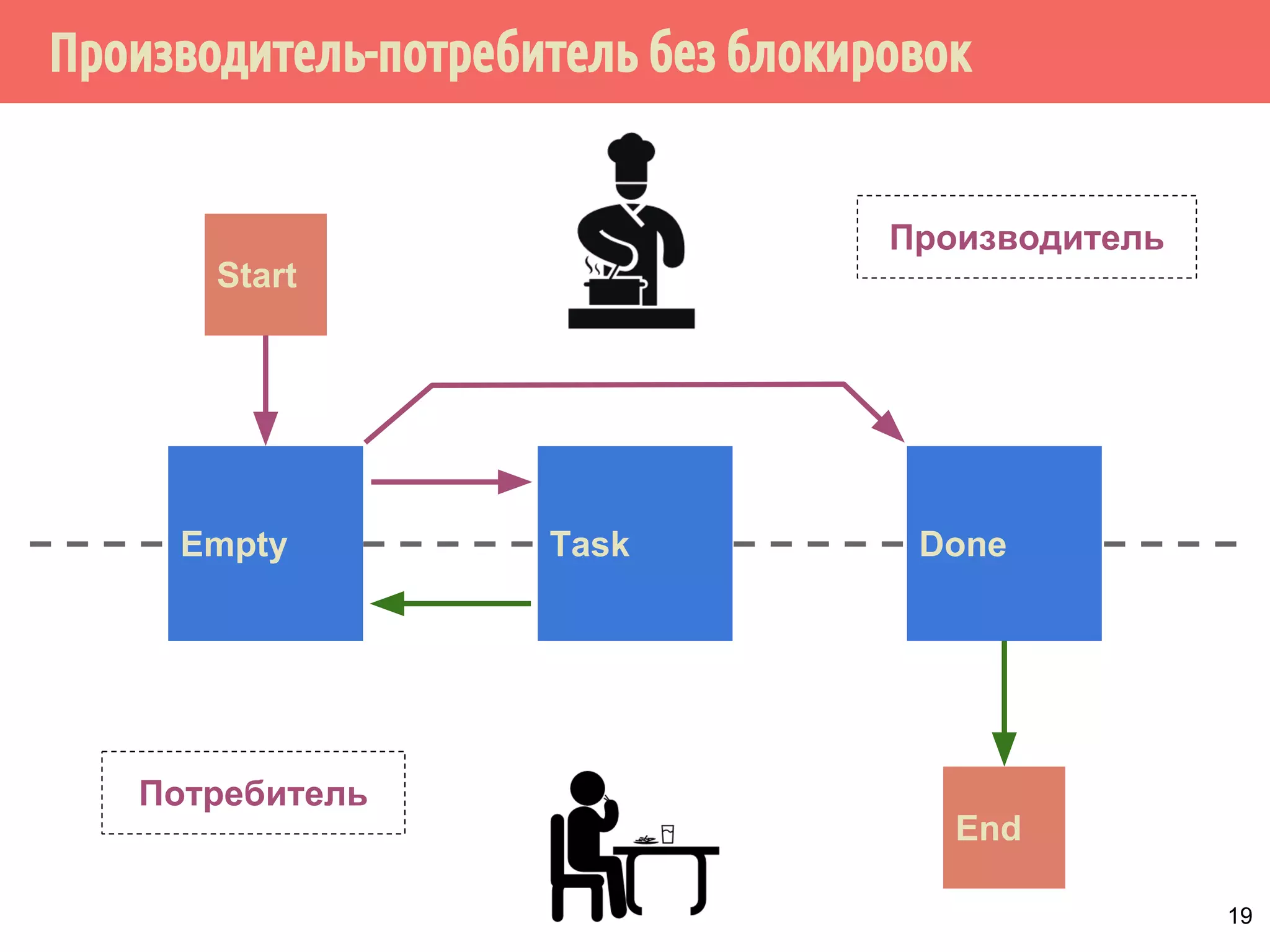
![Производитель-потребитель без блокировок
28
task = null;
while (task != done)
// Дождаться, когда слот будет полным
while ((task = slot[mySlot]) == null)
sem[mySlot].wait();
if (task != done) {
slot[mySlot] = null;
DoWork(task);
}
}
можно ли поменять две строки?
нужно ли это сделать?](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-28-2048.jpg)

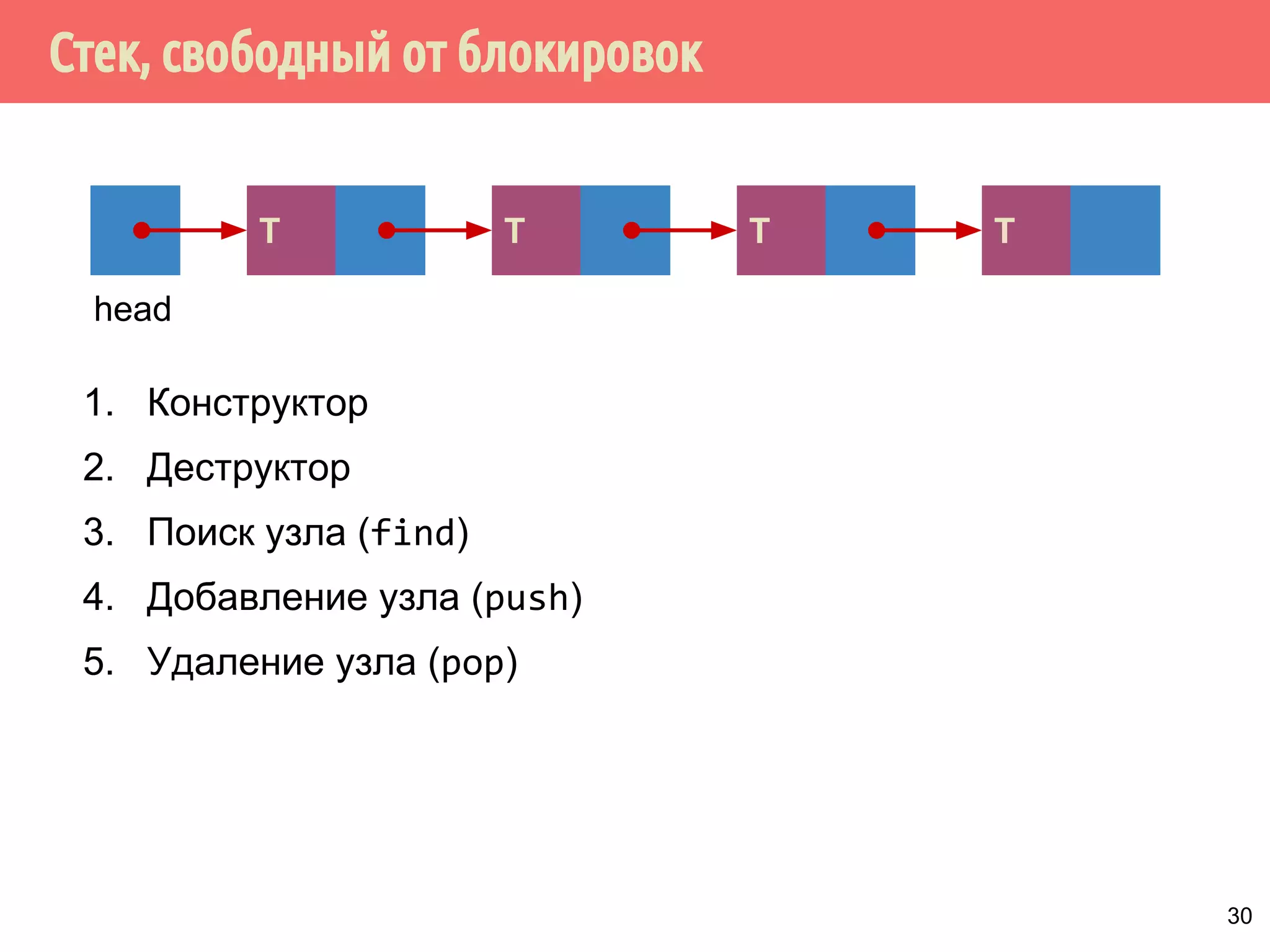

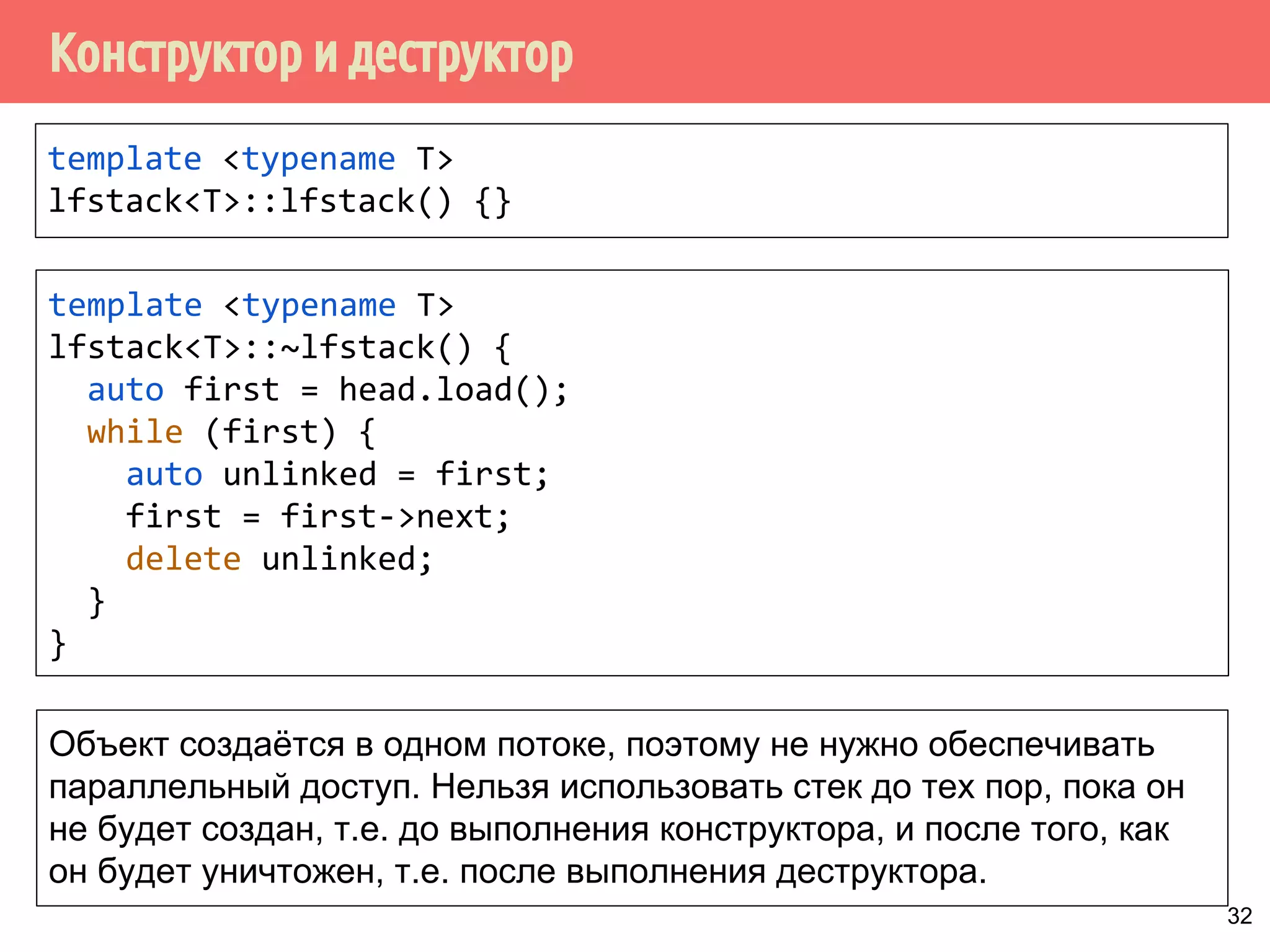

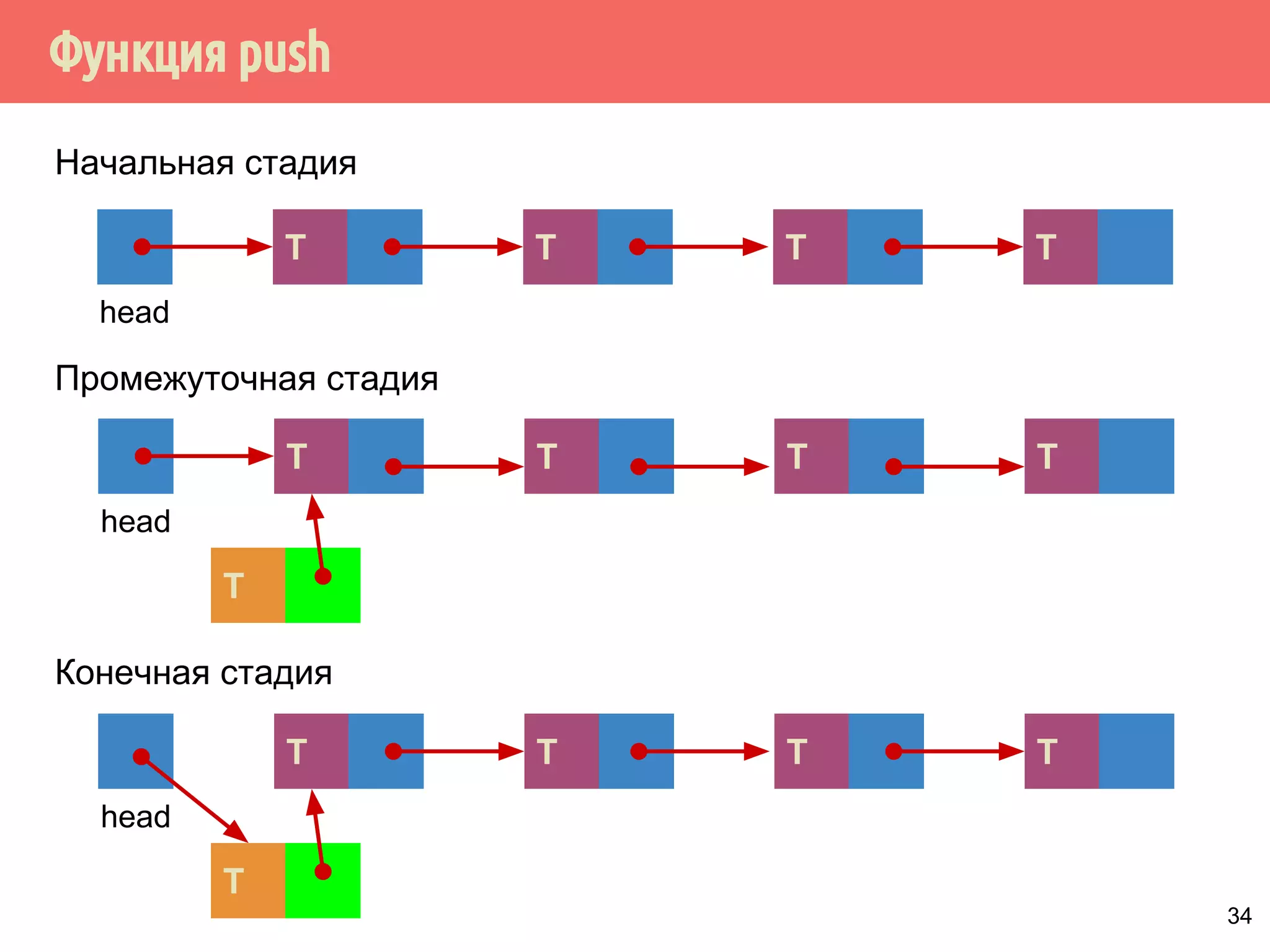
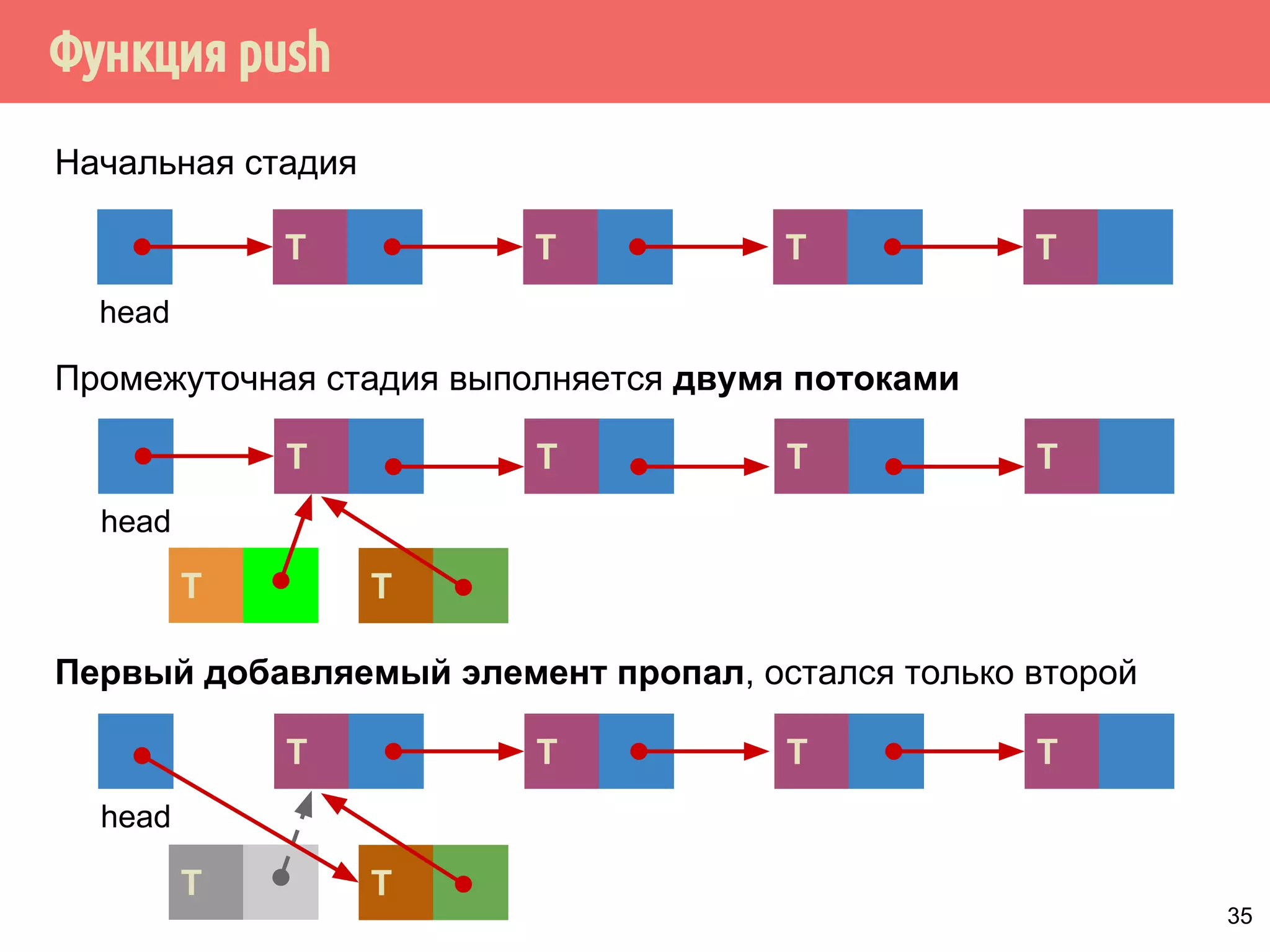


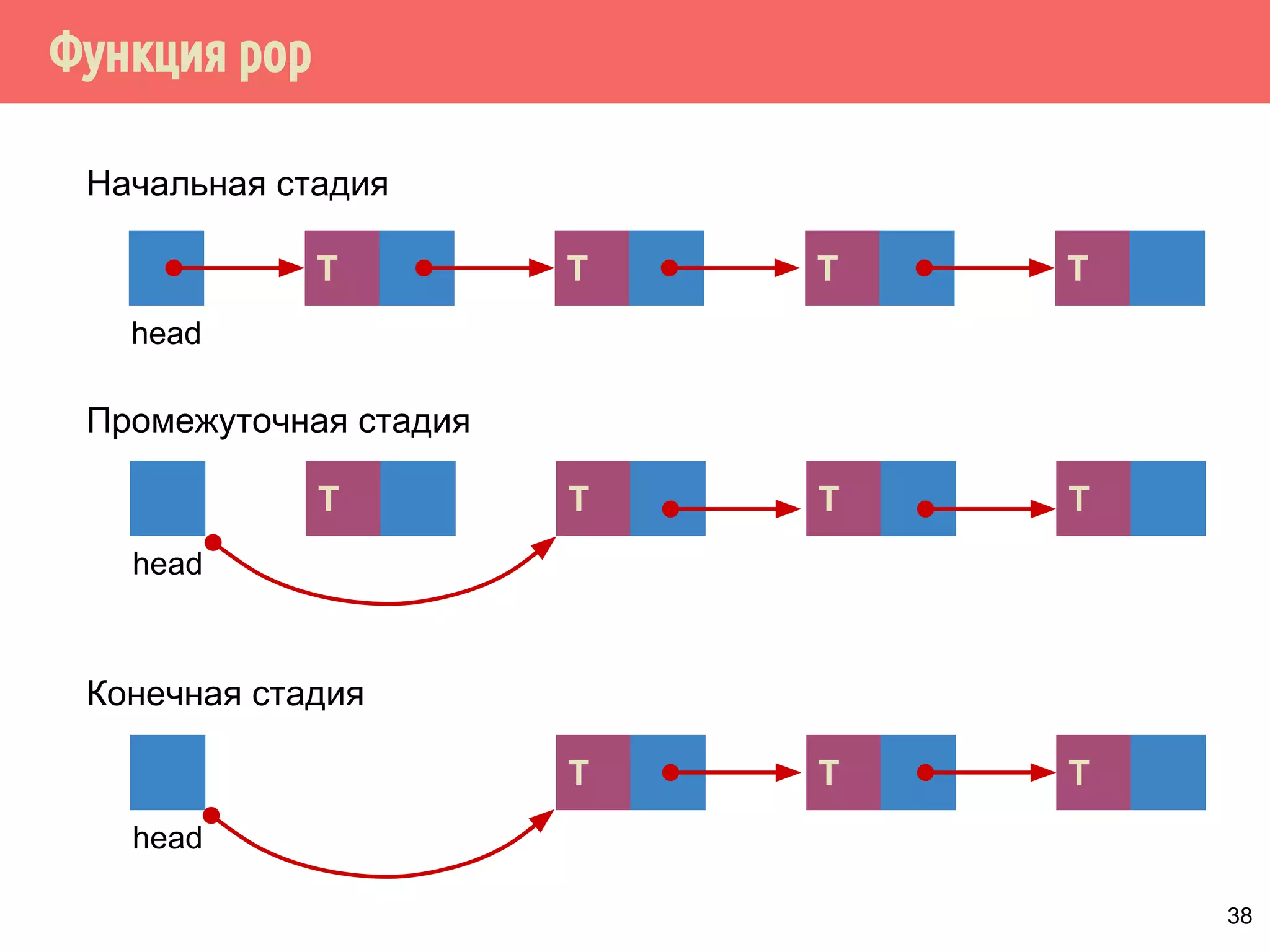
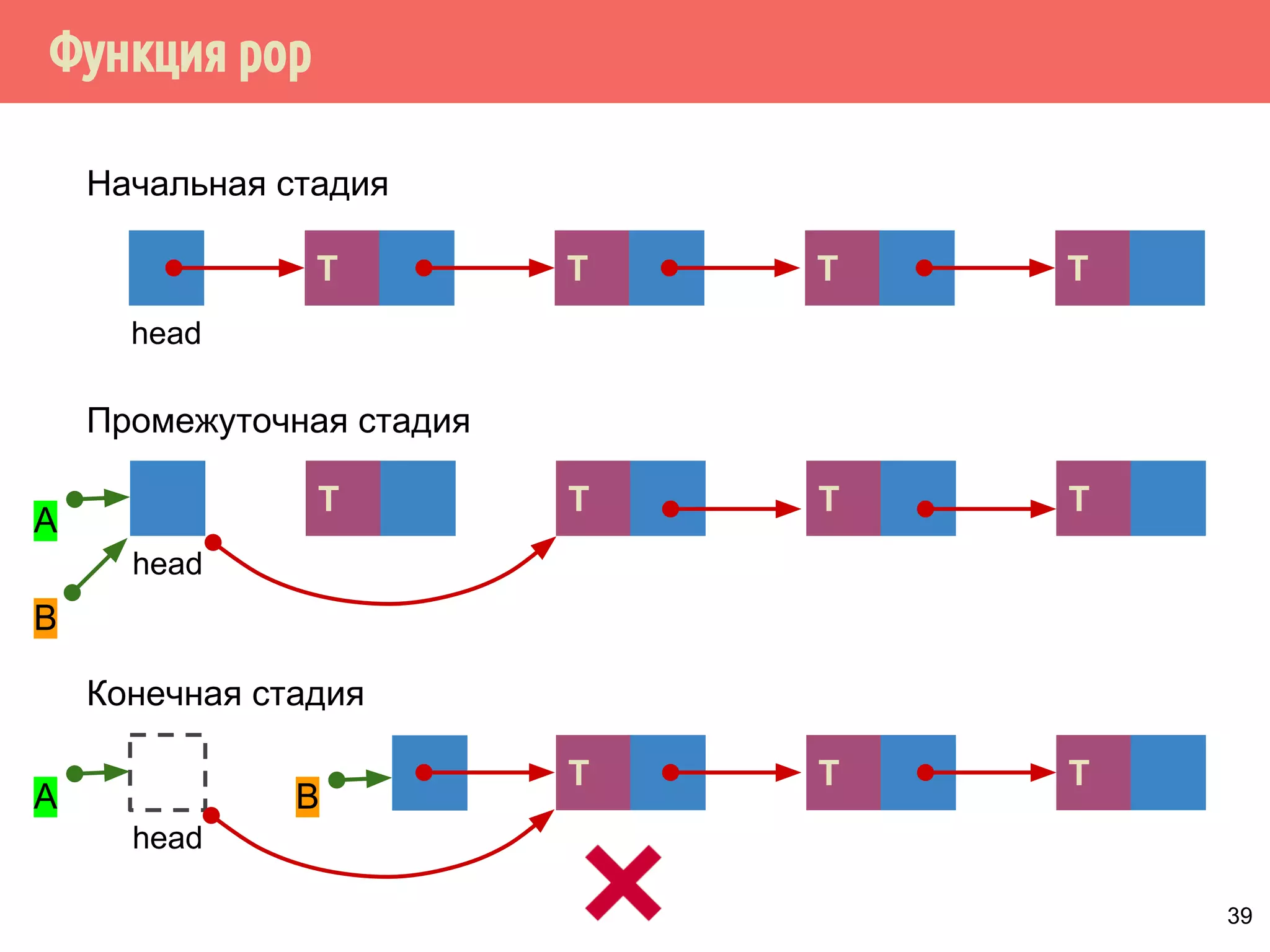


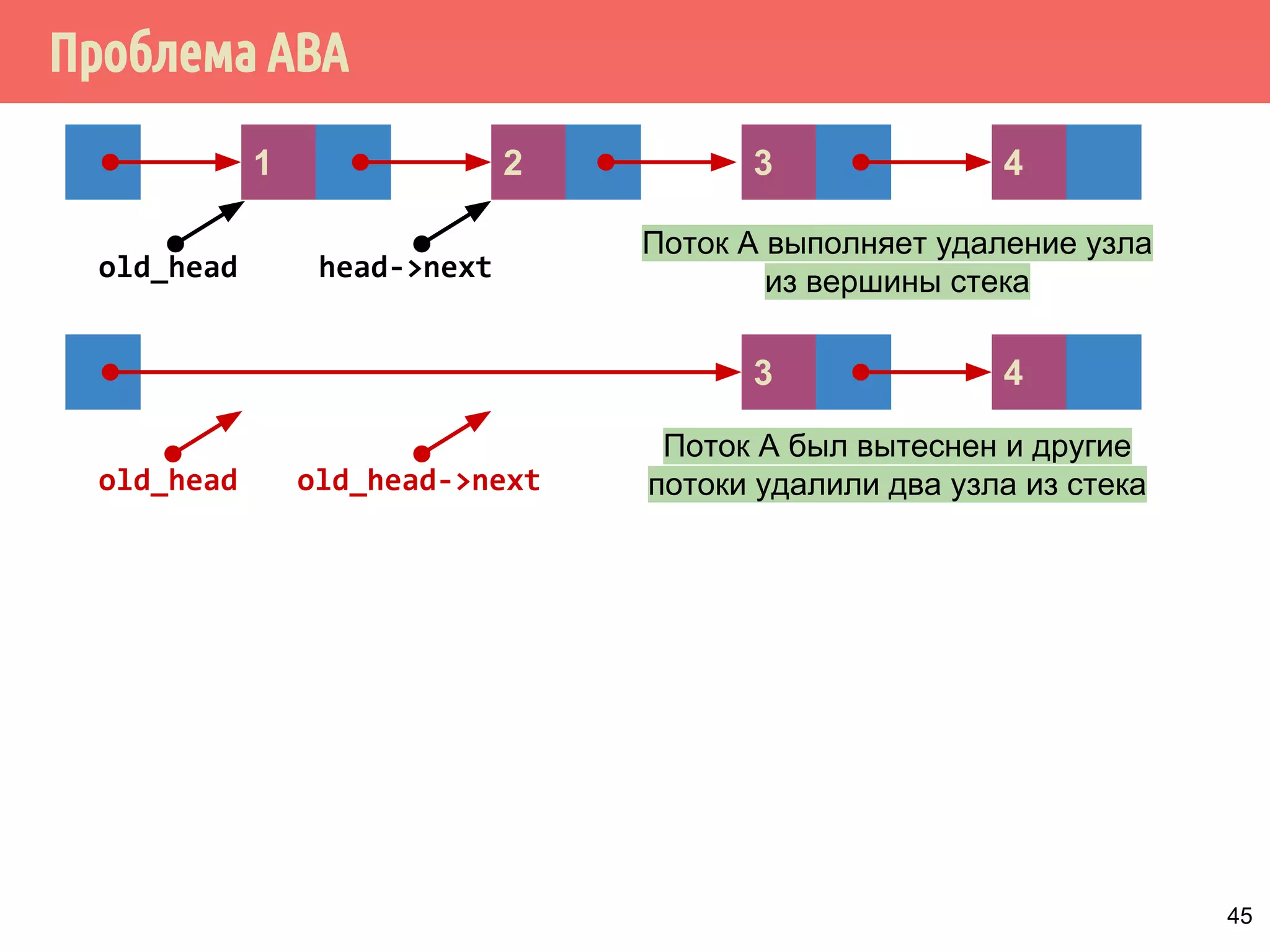




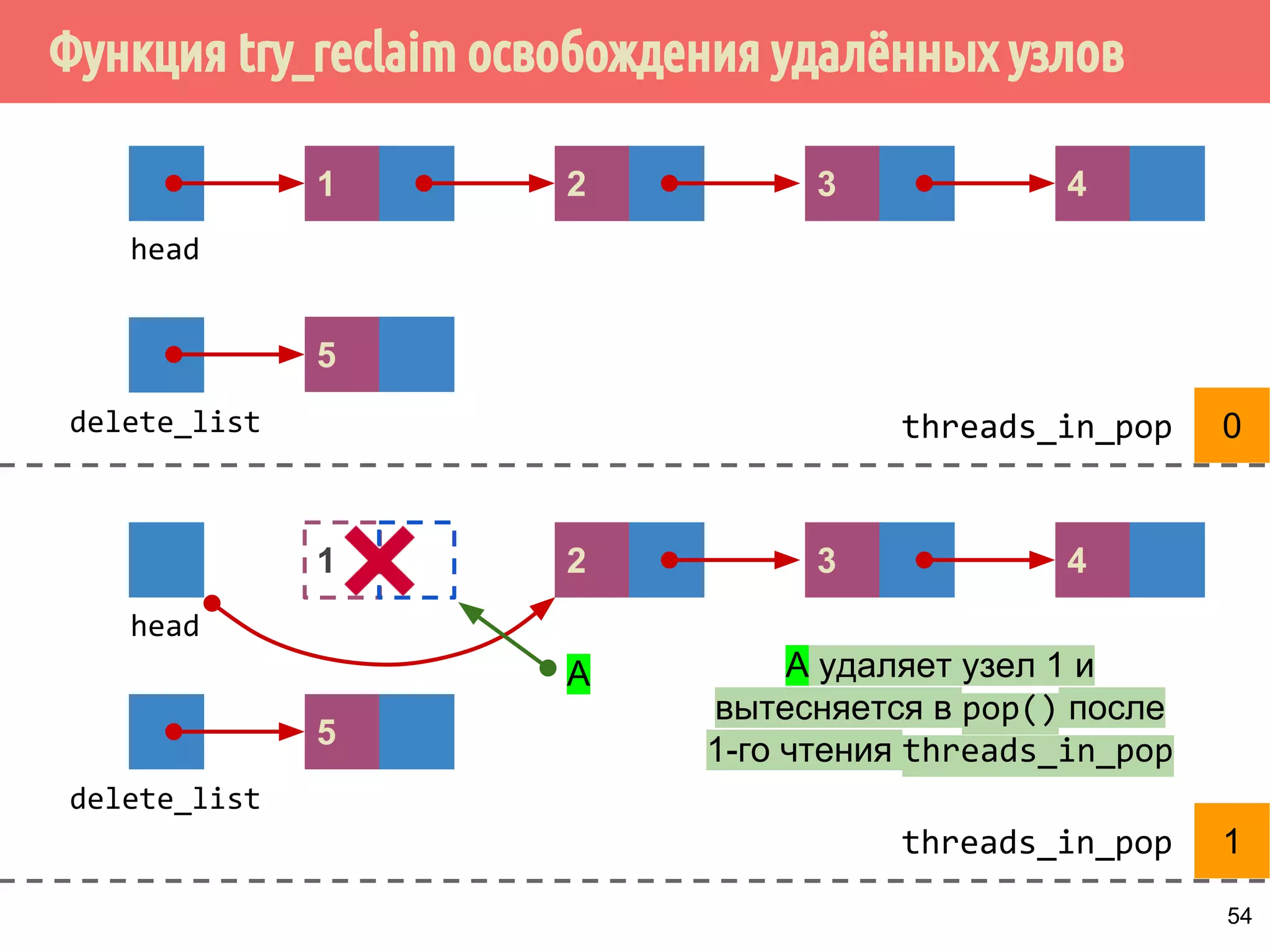





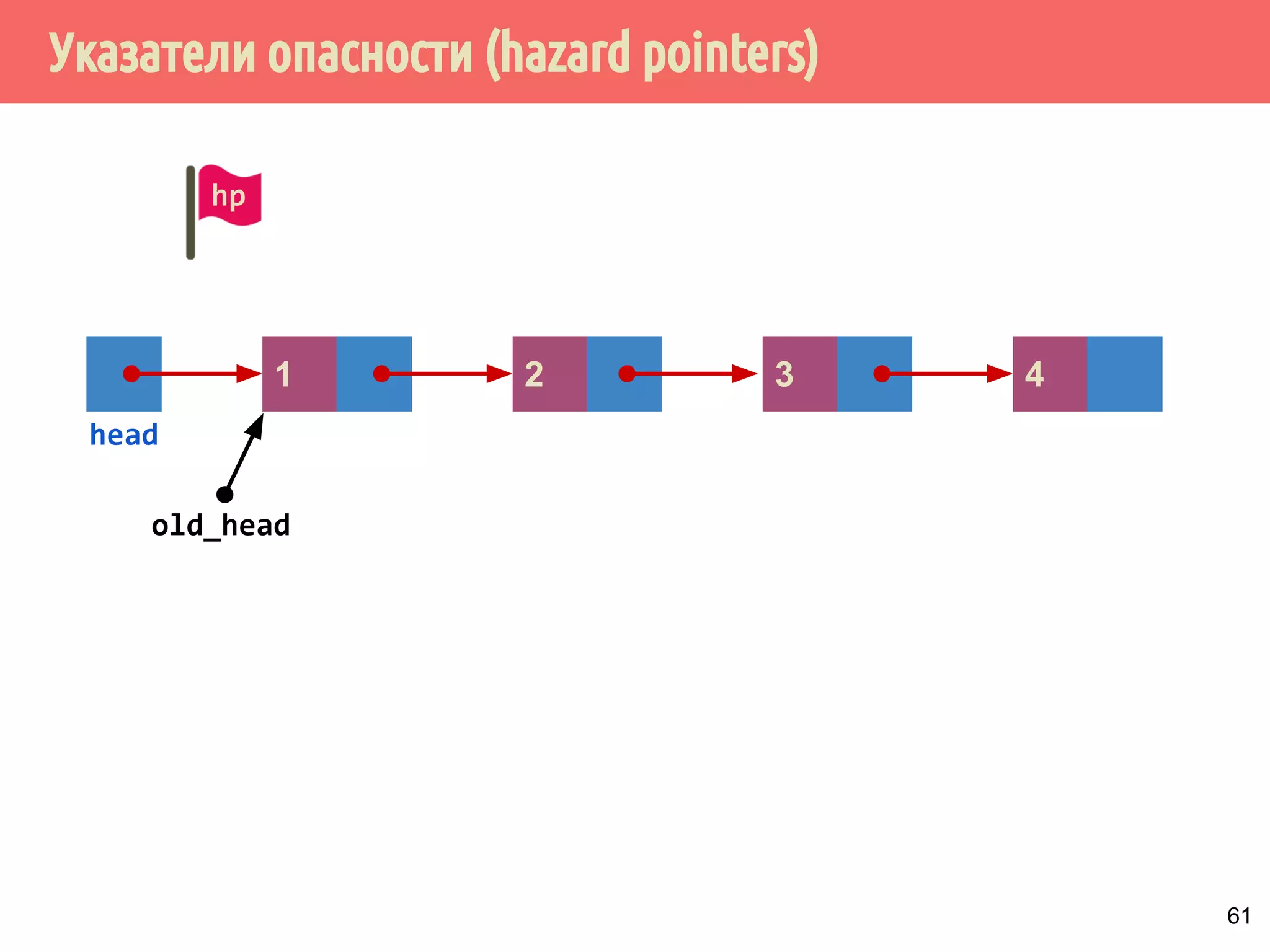
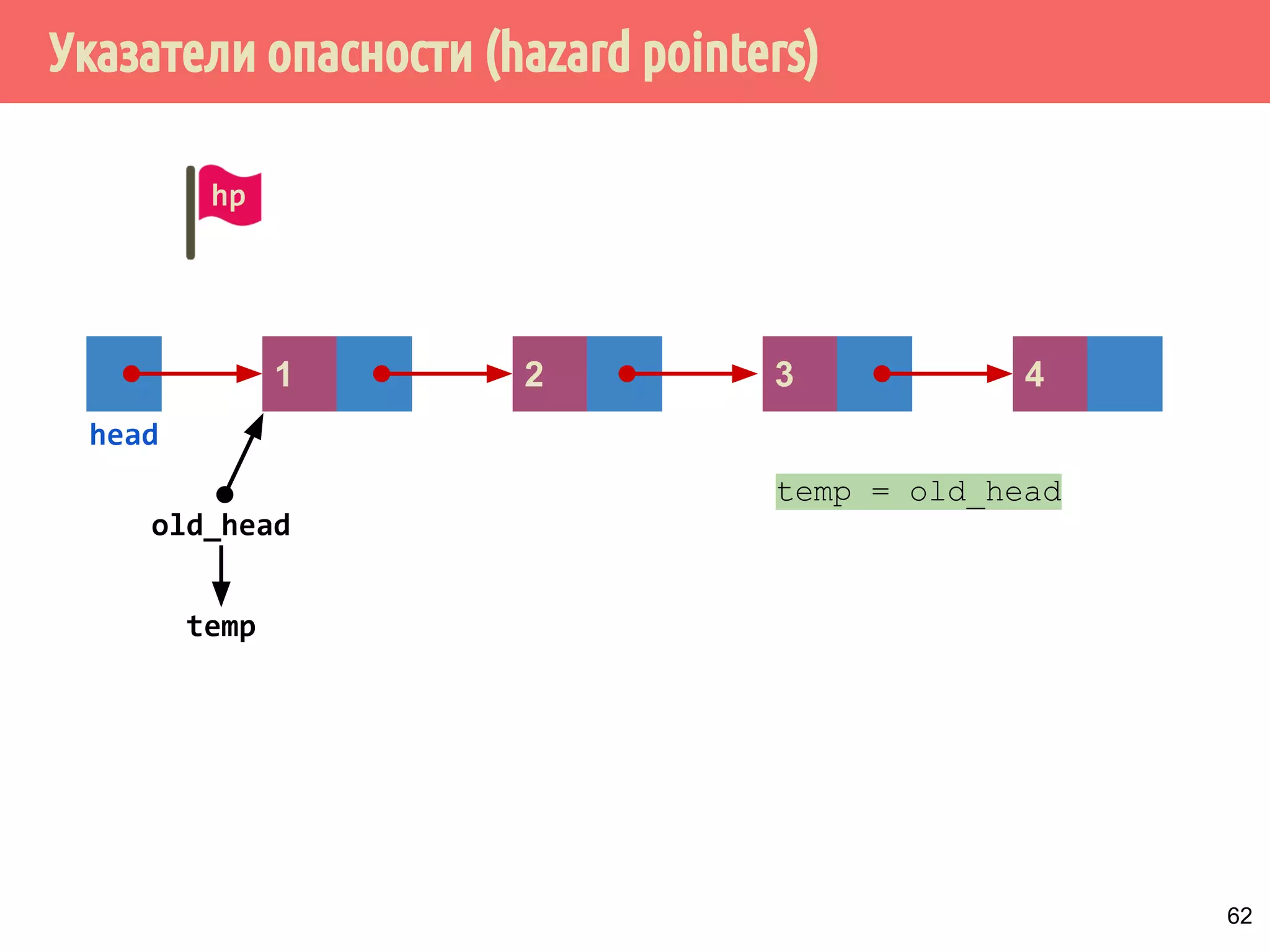

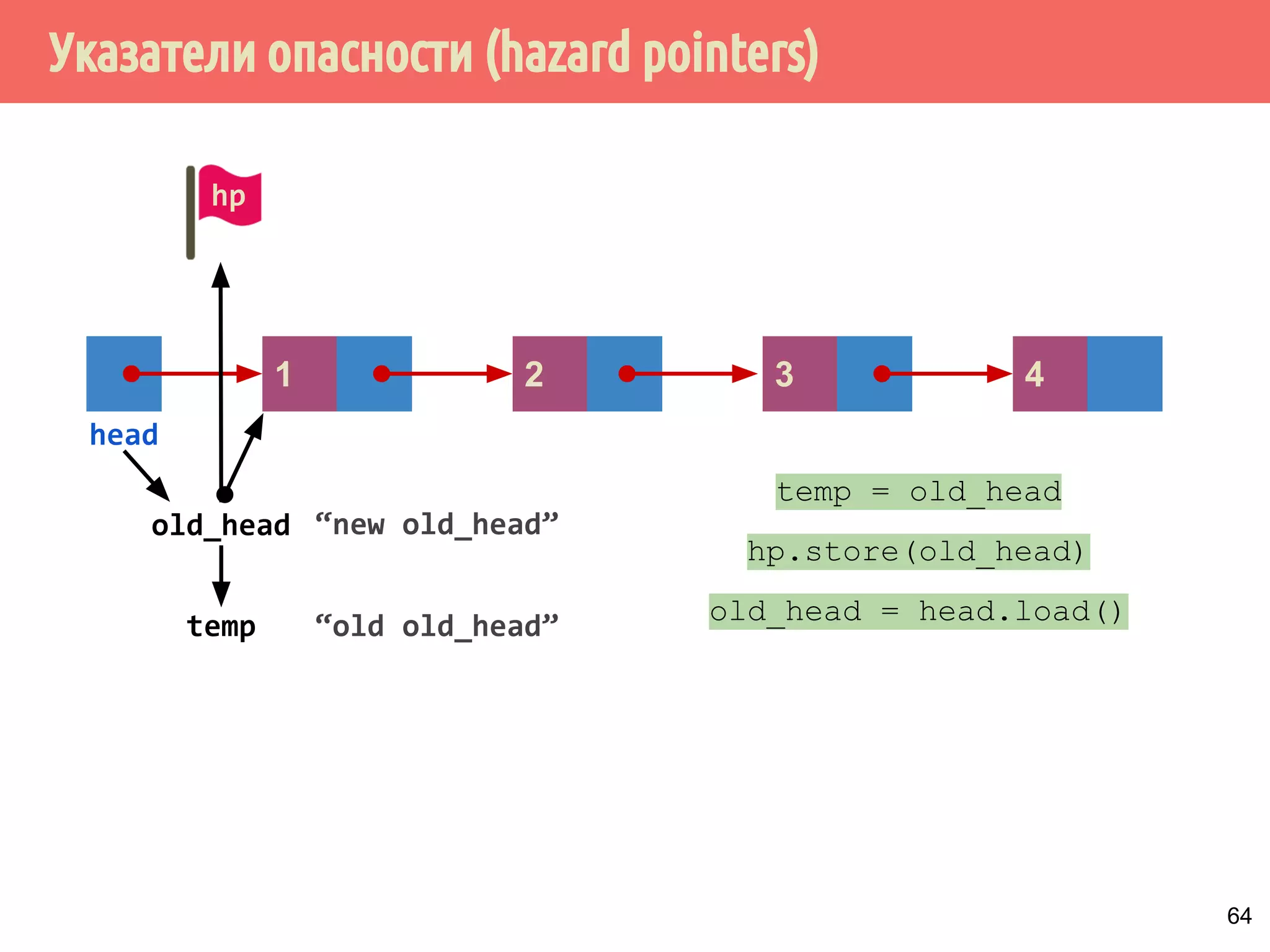


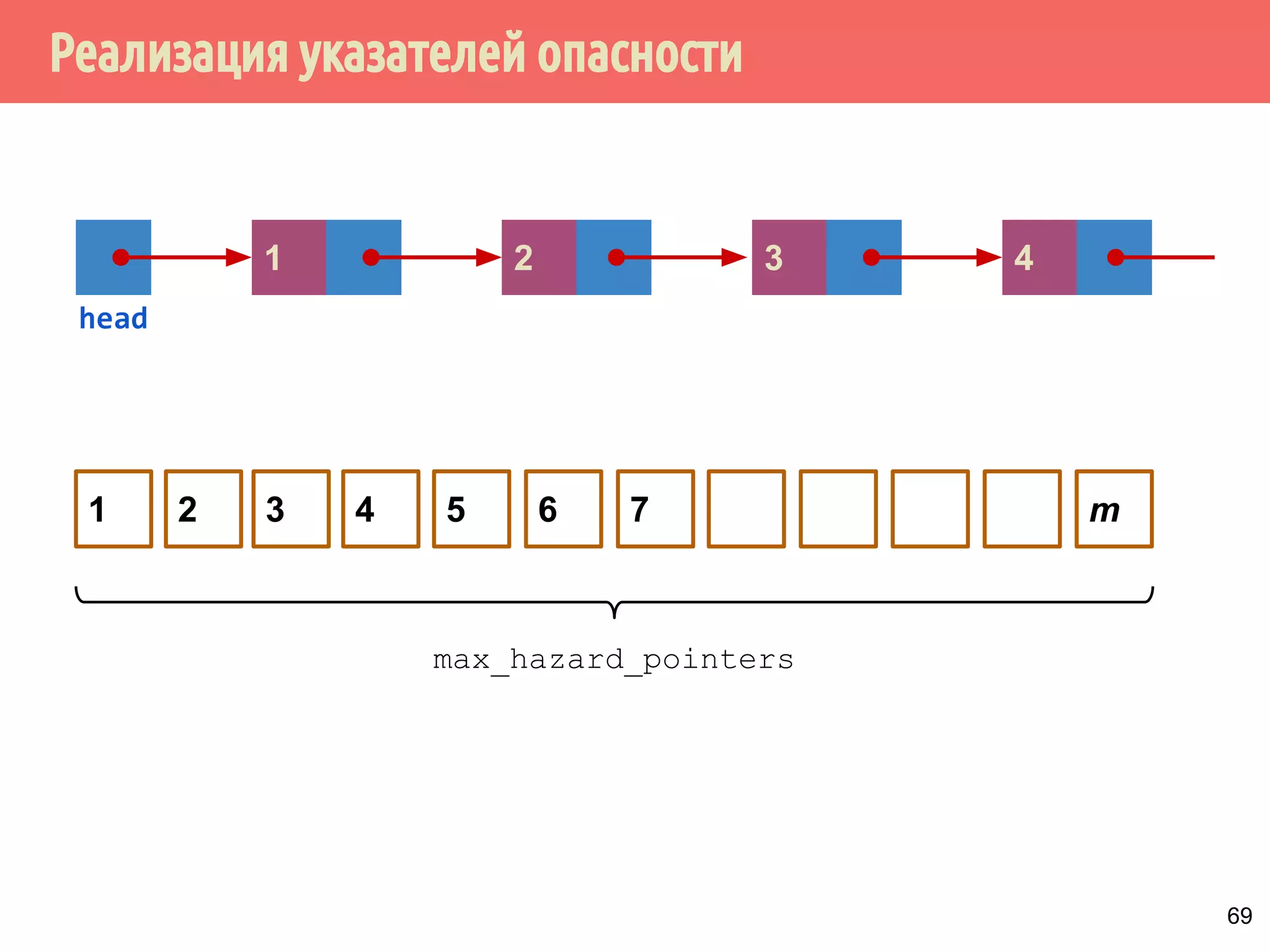
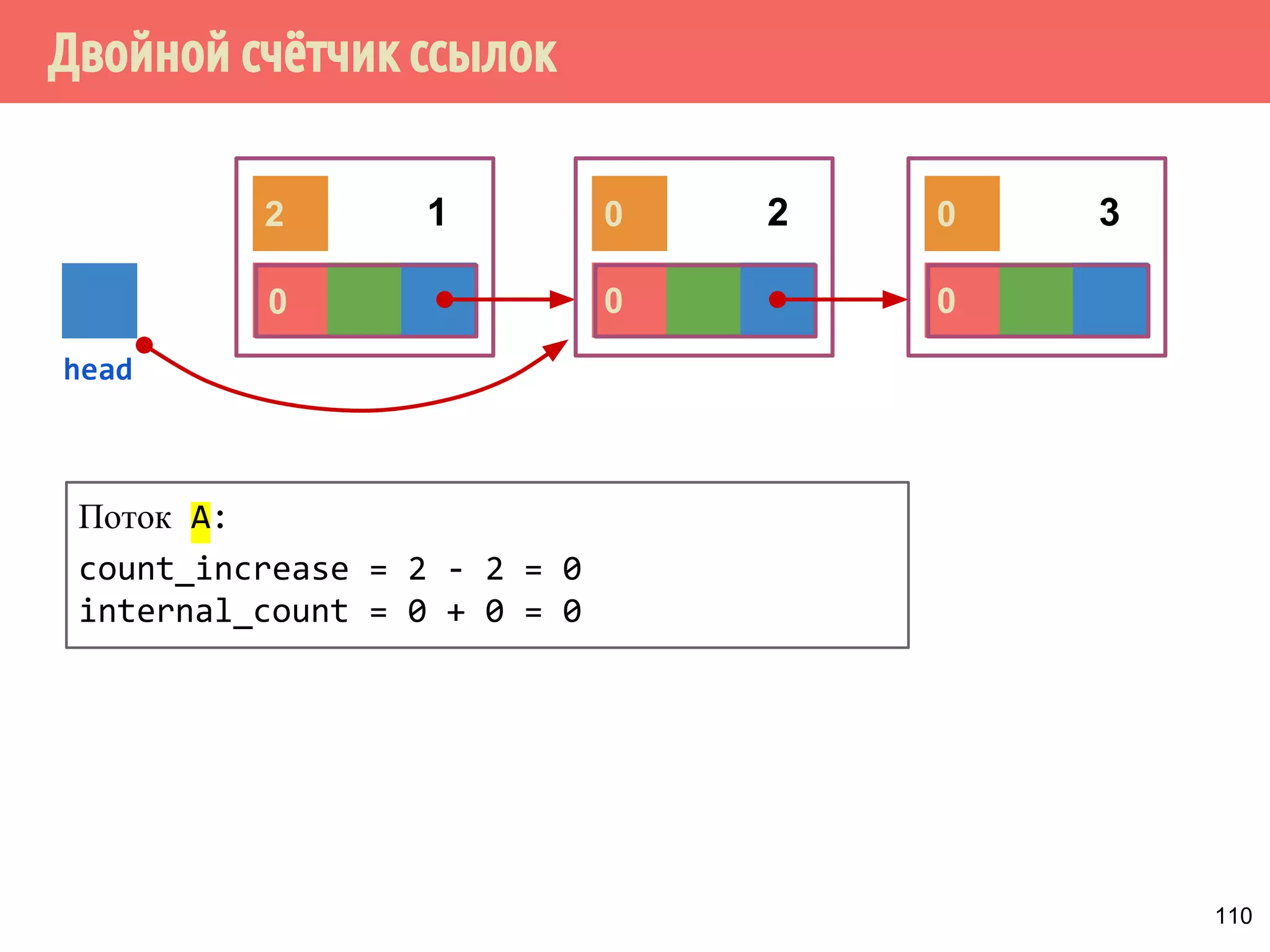
![Реализация указателей опасности
70
4321
head
1 5 6 7 m432
Указатели опасности, m = max_hazard_pointers
пустой?
нет
if (hazard_pointers[i].id.
compare_exchange_strong(
old_id,
std::this_thread::get_id()))
thread_local
hp](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-70-2048.jpg)
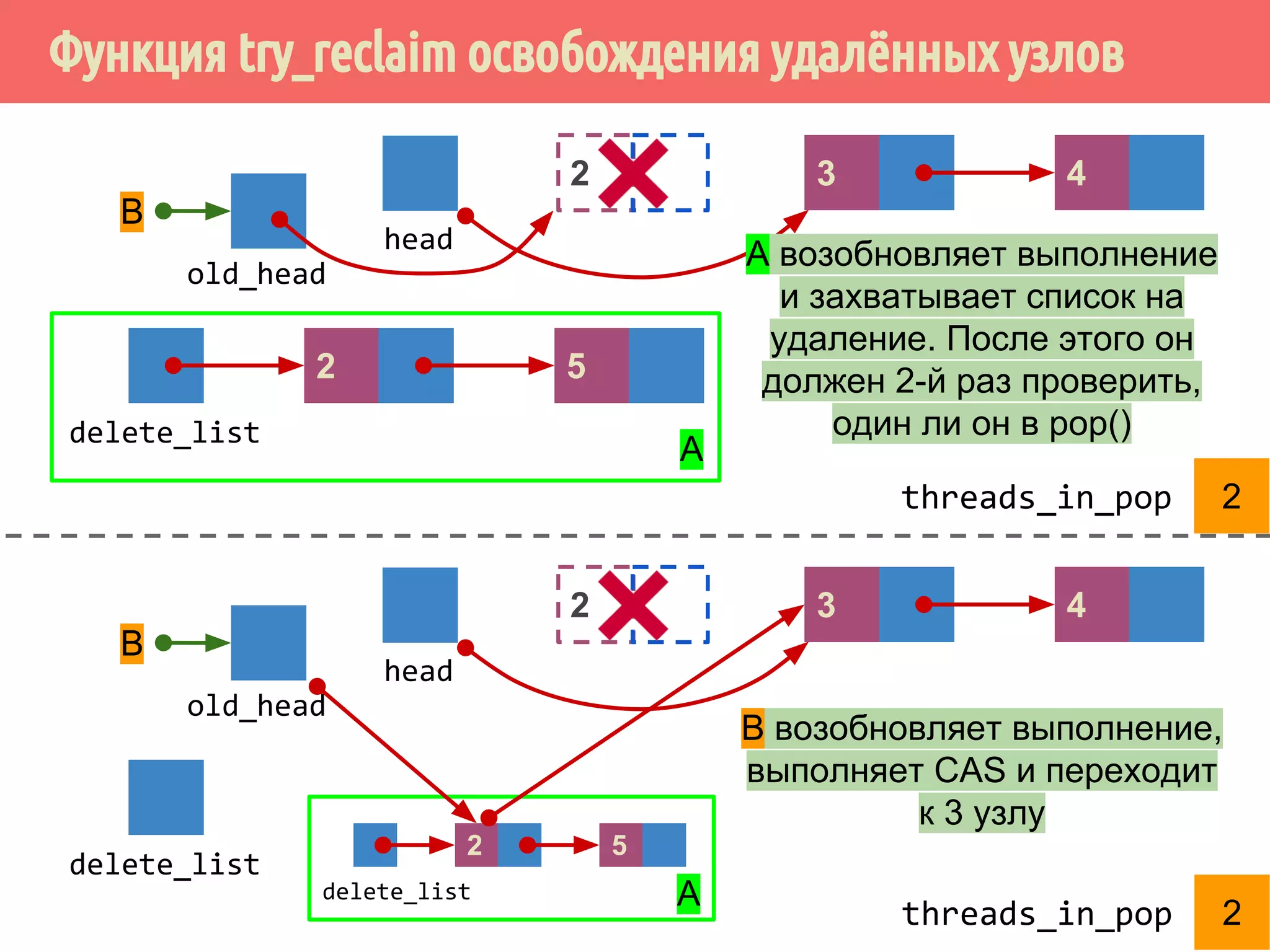
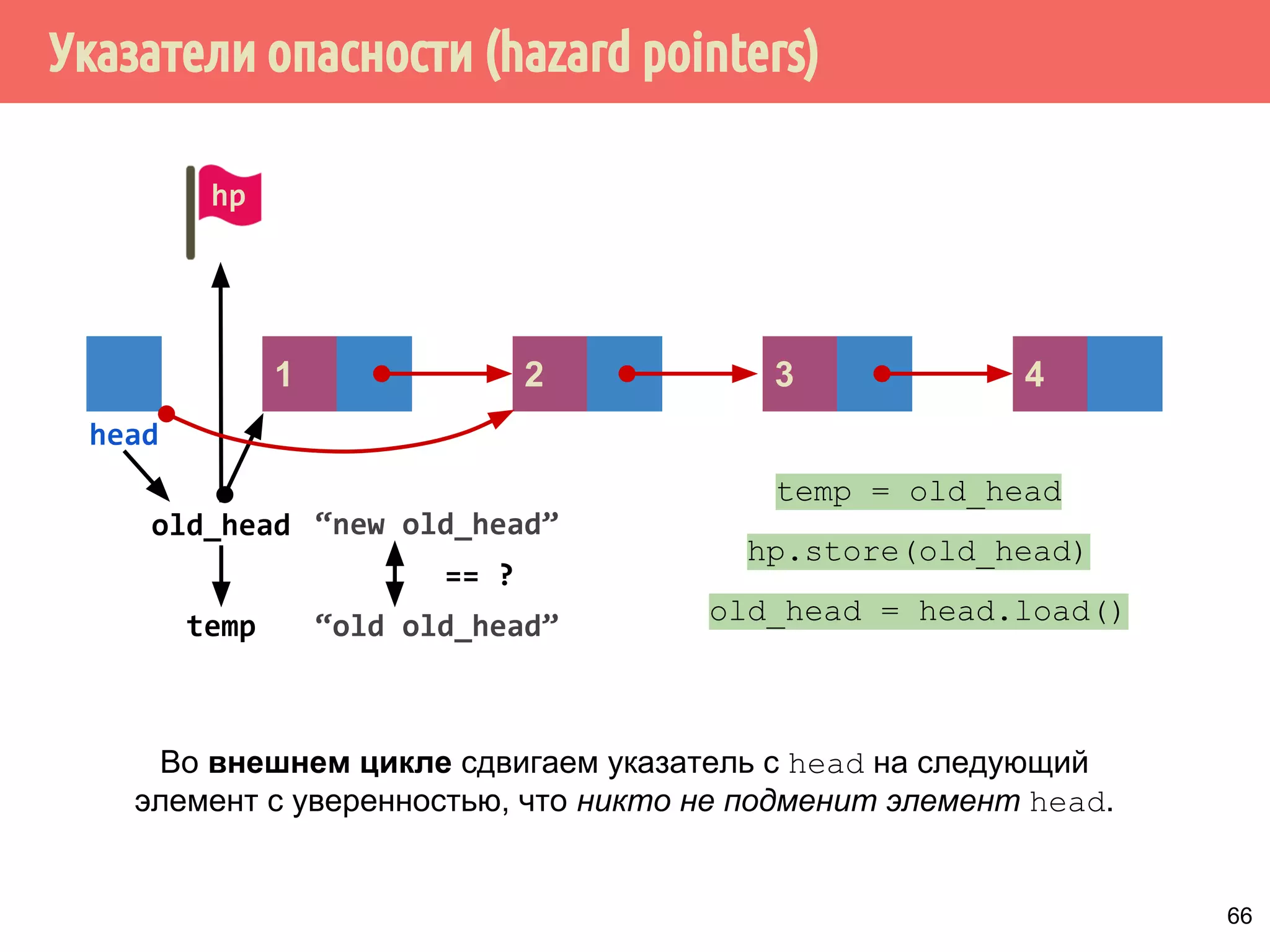
![Реализация указателей опасности
71
4321
head
1 5 6 7 m432
Указатели опасности, m = max_hazard_pointers
пустой?
да
if (hazard_pointers[i].id.
compare_exchange_strong(
old_id,
std::this_thread::get_id()))
thread_local
hp](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-71-2048.jpg)
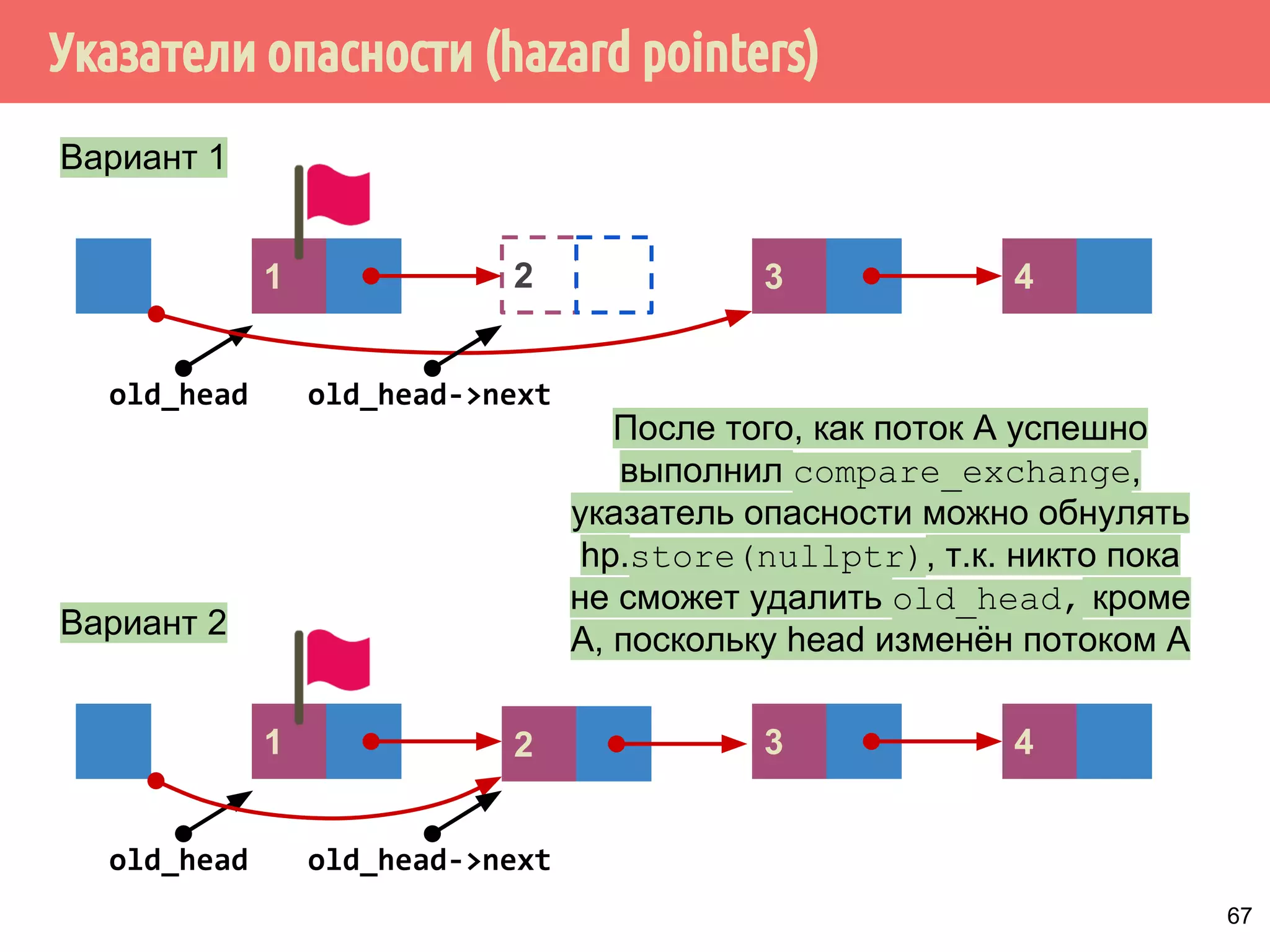
![Реализация указателей опасности
72
4321
head
1 5 6 7 m432
Указатели опасности, m = max_hazard_pointers
пустой?
да
if (hazard_pointers[i].id.
compare_exchange_strong(
old_id,
std::this_thread::get_id()))
thread_local
hp](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-72-2048.jpg)
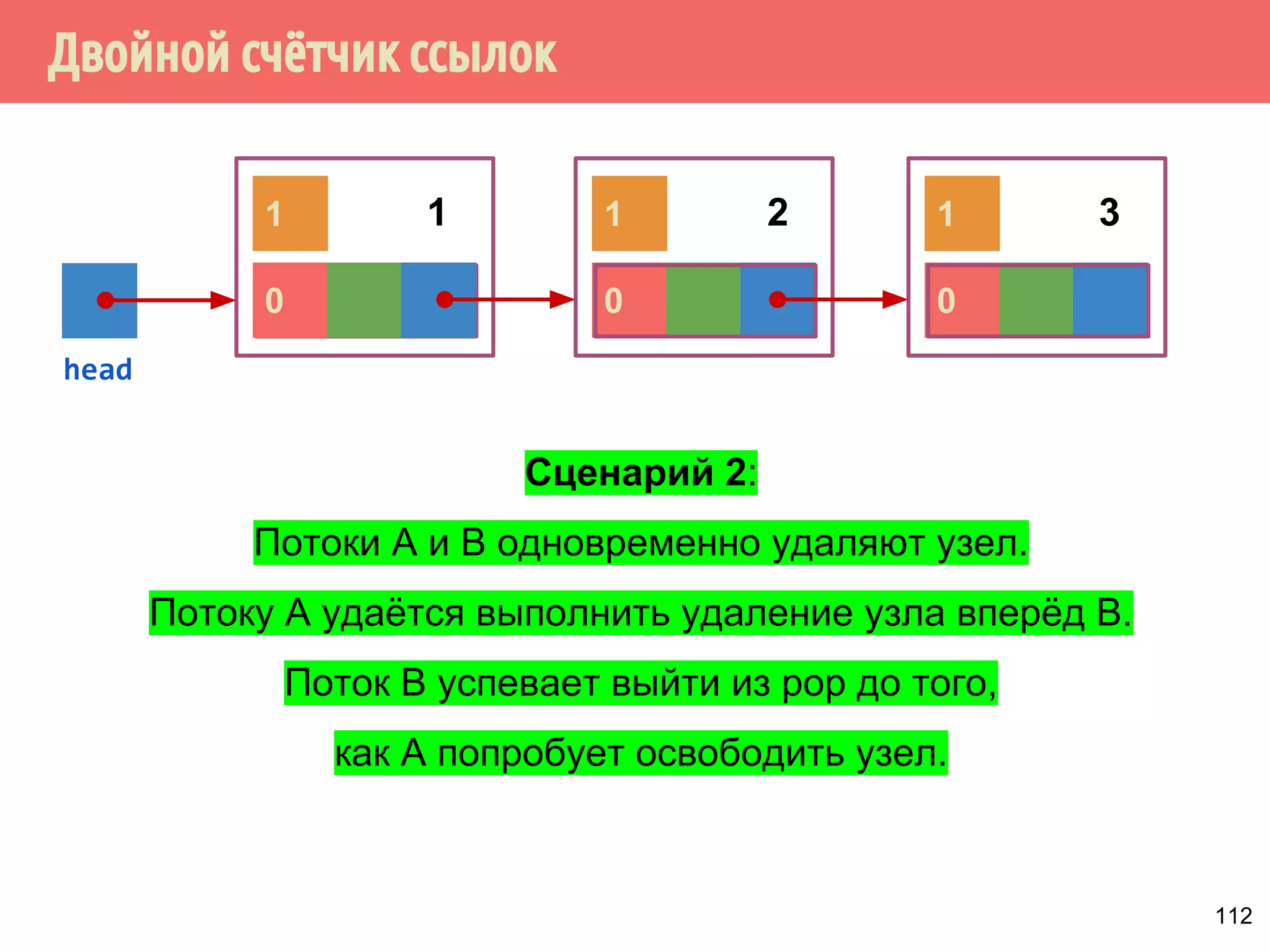
![Реализация указателей опасности
73
const auto max_hazard_pointers = 100;
struct hazard_pointer {
std::atomic<std::thread::id> id;
std::atomic<void*> pointer;
};
hazard_pointer hazard_pointers[max_hazard_pointers];
class hp_owner {
hazard_pointer* hp;
public:
hp_owner(hp_owner const&) = delete;
hp_owner operator=(hp_owner const&) = delete;](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-73-2048.jpg)
![Реализация указателей опасности
74
hp_owner(): hp{nullptr} {
for (auto i = 0; i < max_hazard_pointers; i++) {
std::thread::id old_id; // пустой незанятый УО
// если i-й УО не занят, завладеть им, записав в него
// свой идентификатор потока
if (hazard_pointers[i].id.compare_exchange_strong(
old_id, std::this_thread::get_id())) {
hp = &hazard_pointers[i]; // я владею i-м УО
break;
}
}
// таблица УО закончилась, указателей нам не досталось
if (!hp)
throw std::runtime_error("No hazard ptrs available");
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-74-2048.jpg)
![Реализация указателей опасности
75
hp_owner(): hp{nullptr} {
for (auto i = 0; i < max_hazard_pointers; i++) {
std::thread::id old_id;
if (hazard_pointers[i].id.compare_exchange_strong(
old_id, std::this_thread::get_id())) {
hp = &hazard_pointers[i];
break;
}
}
if (!hp)
throw std::runtime_error("No hazard ptrs available");
}
std::atomic<void*>& get_pointer() {
return hp->pointer;
}
~hp_owner() {
hp->pointer.store(nullptr);
hp->id.store(std::thread::id());
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-75-2048.jpg)
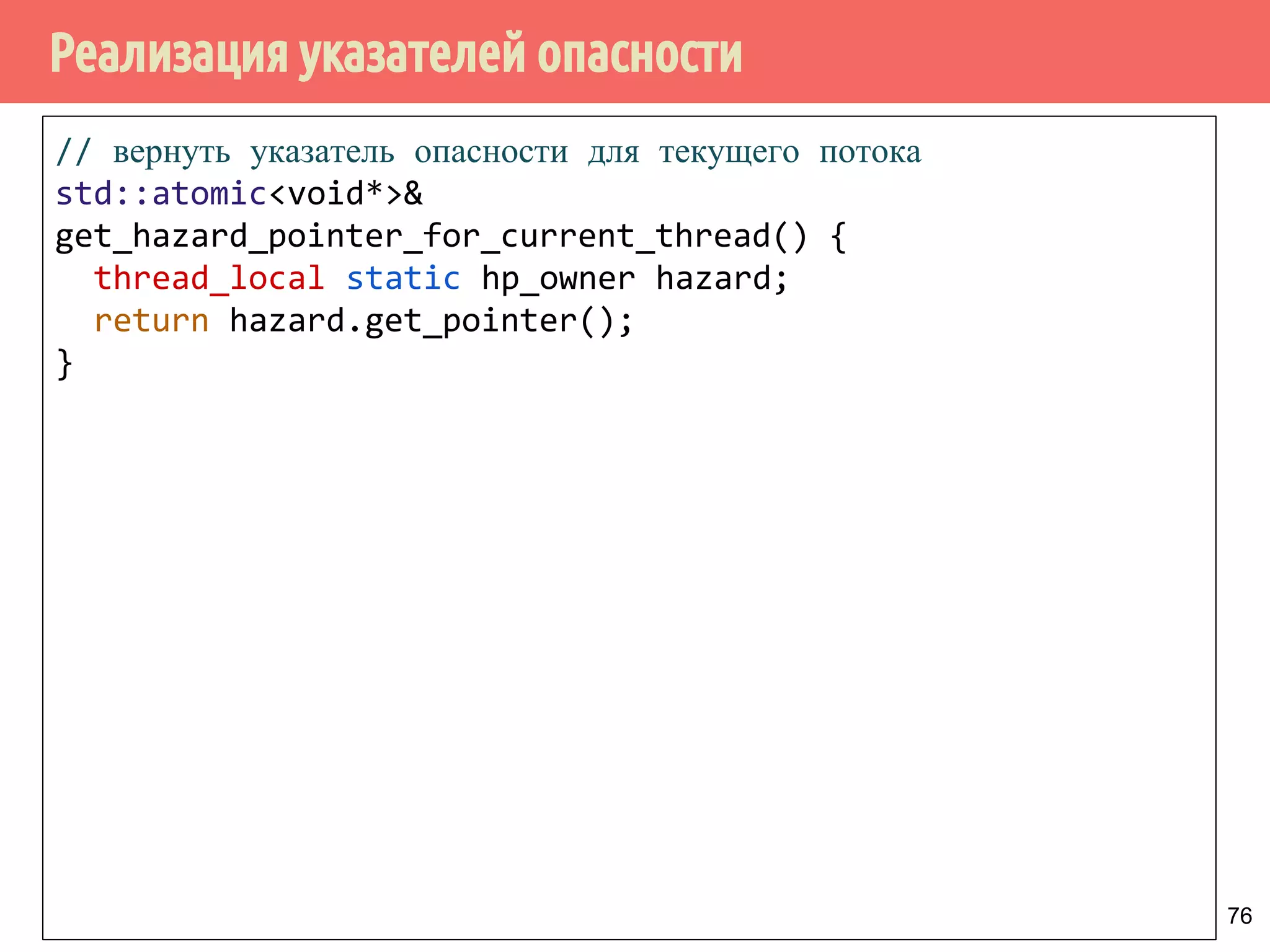
![Реализация указателей опасности
77
// вернуть указатель опасности для текущего потока
std::atomic<void*>&
get_hazard_pointer_for_current_thread() {
thread_local static hp_owner hazard;
return hazard.get_pointer();
}
// проверить, не ссылается ли на указатель какой-то из УО
bool outstanding_hazard_pointers_for(void* p) {
for (auto i = 0; i < max_hazard_pointers; i++) {
if (hazard_pointers[i].pointer.load() == p) {
return true;
}
}
return false;
}](https://image.slidesharecdn.com/pct-autumn2014-lec78-141225083546-conversion-gate01/75/2014-7-77-2048.jpg)





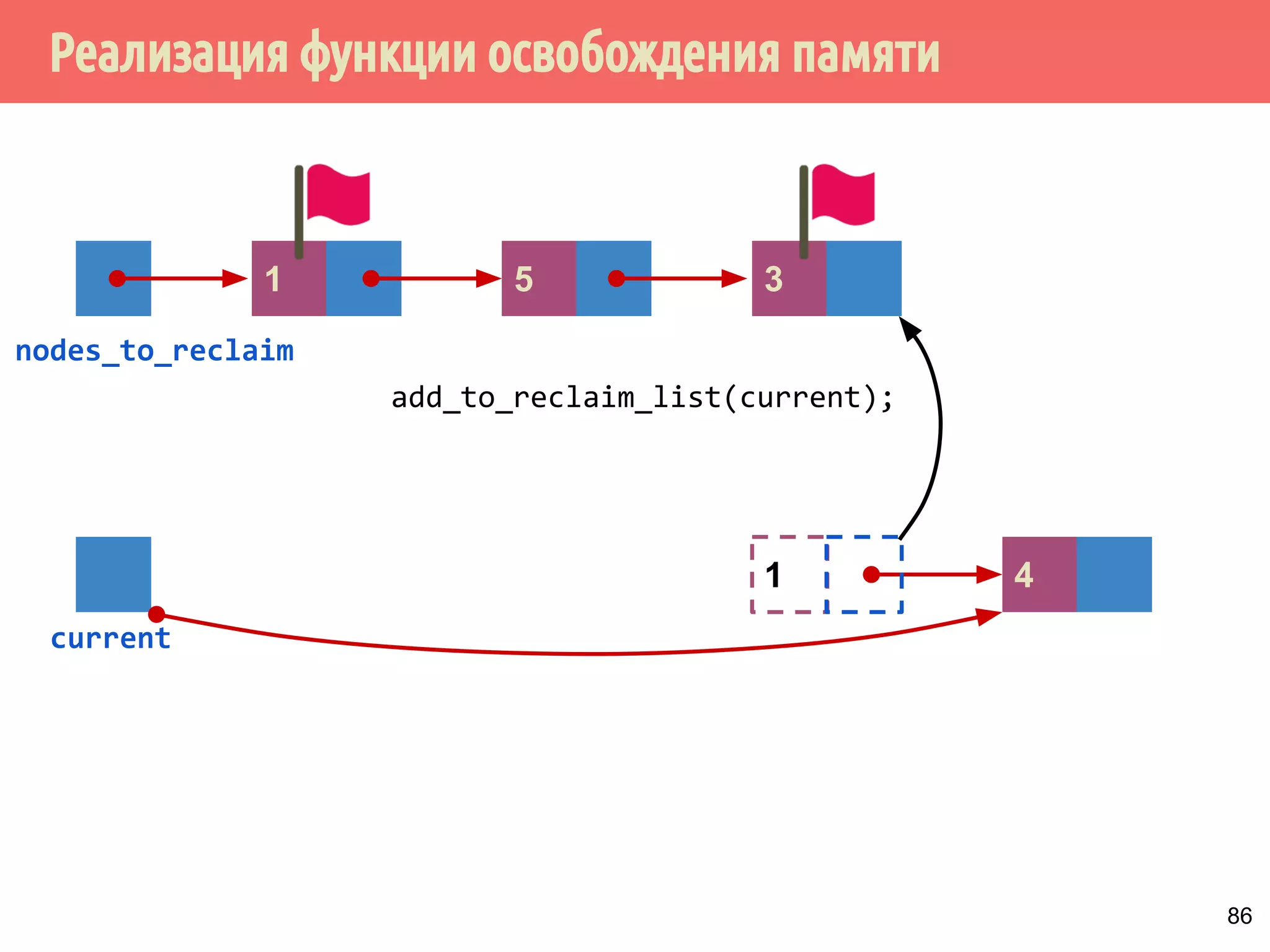






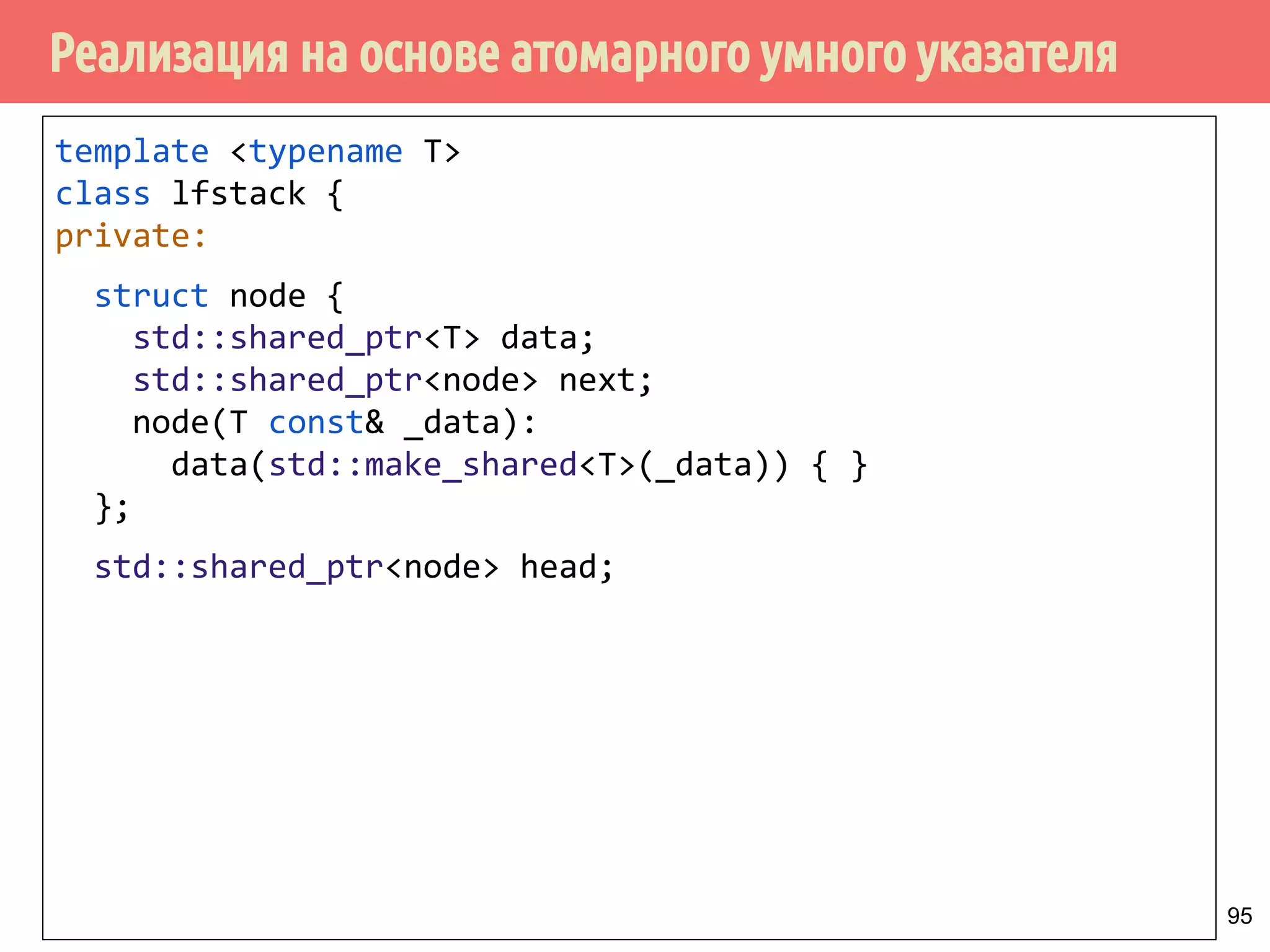





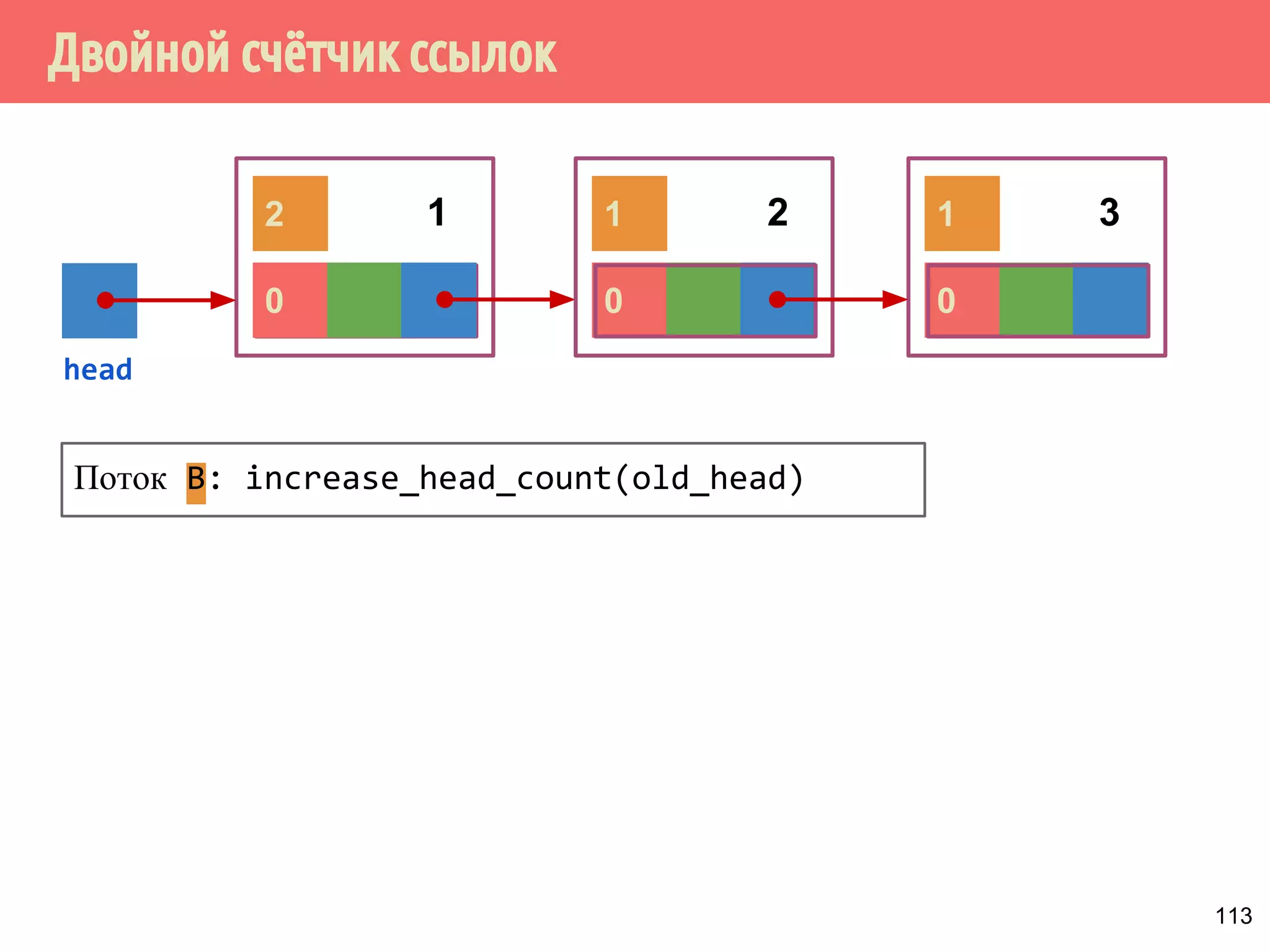

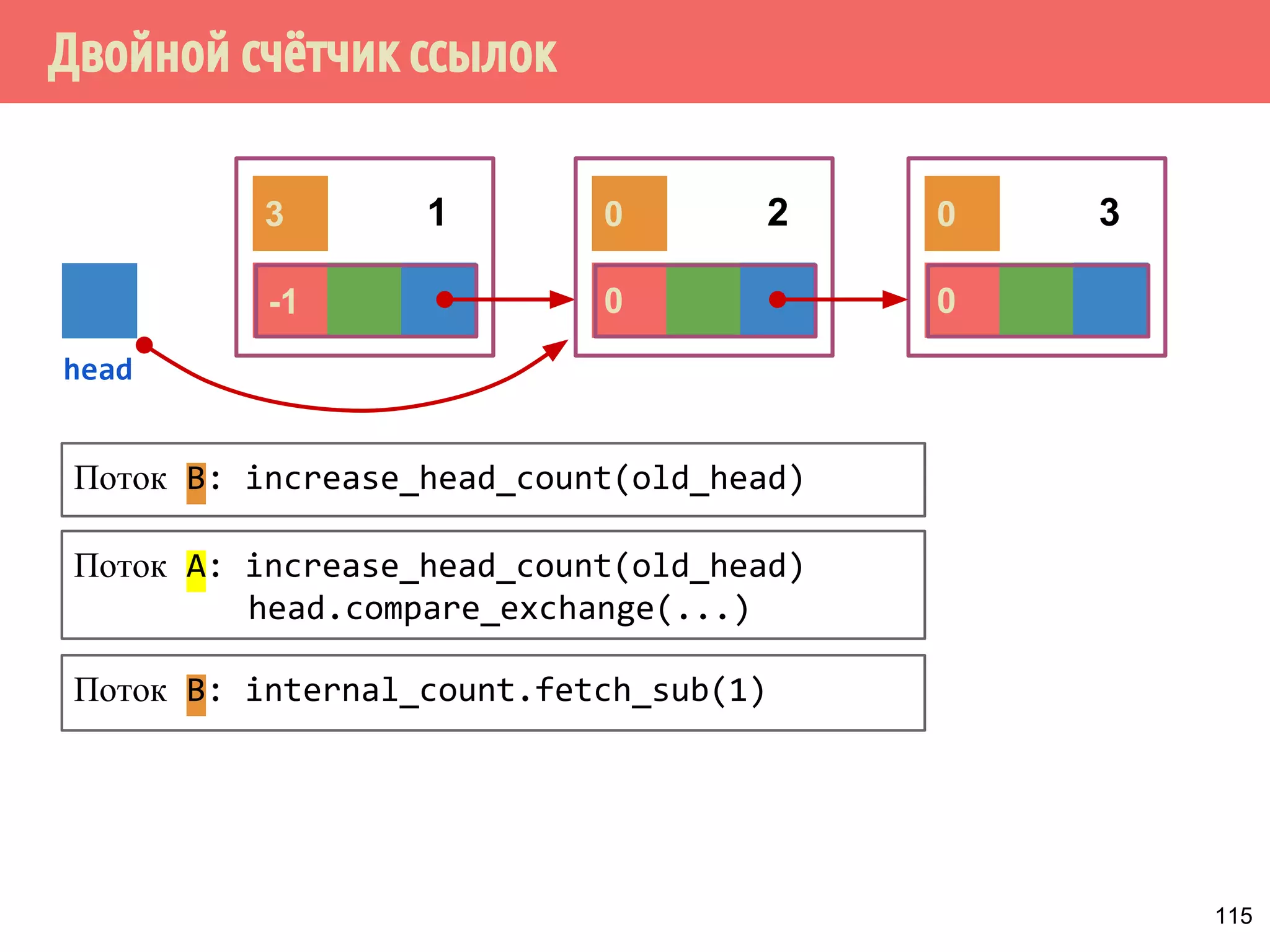


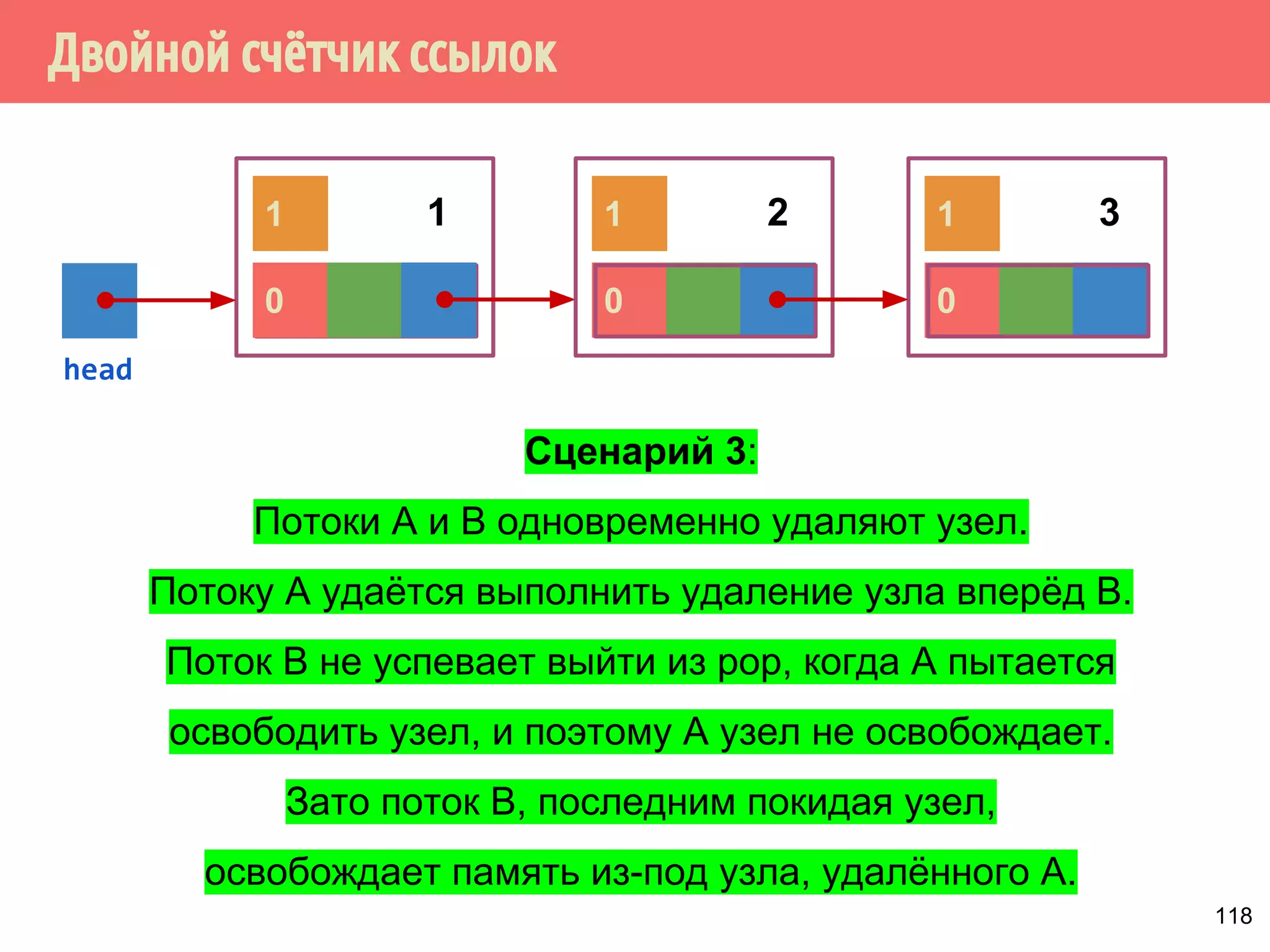

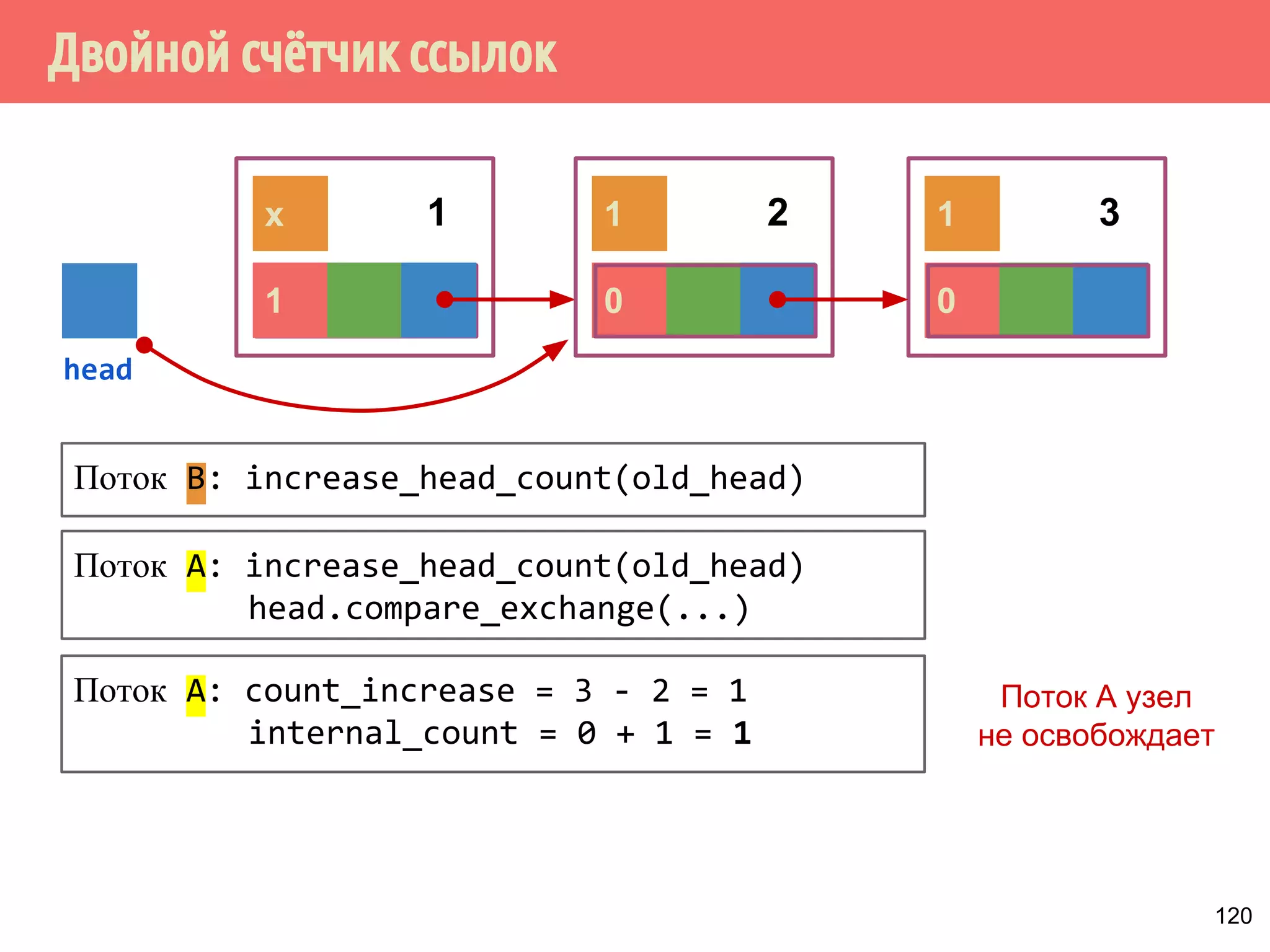













Документ представляет собой лекцию о многопоточном программировании без блокировок, исследуя модель потребитель-производитель и потокобезопасные структуры данных, такие как стек. Основные принципы включают различные виды алгоритмов, свободных от блокировок, методы реализации и проблемы, такие как гонки и дедлоки. Важное внимание уделяется реализации спинлоков и коррекции ошибок в методах работы со стеком.

































































