Downloaded 68 times


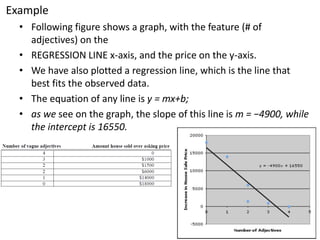
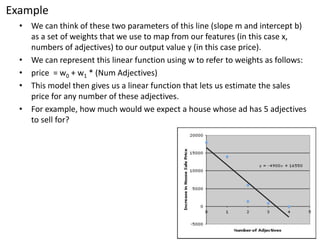







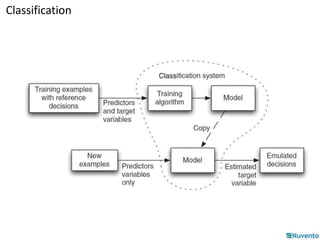









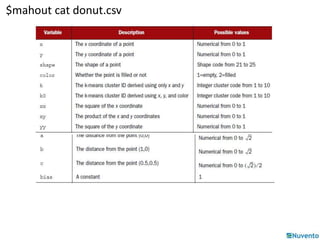






This document provides an overview of logistic regression using stochastic gradient descent. It explains that logistic regression can be used for classification problems where the output is discrete. The key aspects covered include: - Logistic regression estimates the logit (log odds) of the probability rather than the probability directly, using a linear function of the input features. - It learns a hyperplane that separates the classes by choosing weights to maximize the likelihood of the training data. - Stochastic gradient descent can be used as an optimization technique to learn the weights by minimizing the negative log likelihood. - An example is provided of using the Mahout machine learning library to build a logistic regression model for classification using features from a donut-
































































































