Downloaded 64 times


![3 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-3-2048.jpg)
![4 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-4-2048.jpg)
![5 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags
Sometimes with location – spatial data](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-5-2048.jpg)
![6 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags
Sometimes with location – spatial data
But, strictly time-series](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-6-2048.jpg)
![7 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags
Sometimes with location – spatial data
But, strictly time-series
Do we have good time series data store?](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-7-2048.jpg)
![8 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags
Sometimes with location – spatial data
But, strictly time-series
Do we have good time series data store?
Open source?](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-8-2048.jpg)
![9 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
IoT data stream
Sequence of data points
Triplet: [ID][TIME][VALUE] – basic time-series
Multiplet: [ID][TIME][TAG1][…][TAGN][VALUE] – time-series with tags
Sometimes with location – spatial data
But, strictly time-series
Do we have good time series data store?
Open source?
But commercially supported?](https://image.slidesharecdn.com/june30210hortonworksrodionovv2-160711213408/75/IoT-what-about-data-storage-9-2048.jpg)









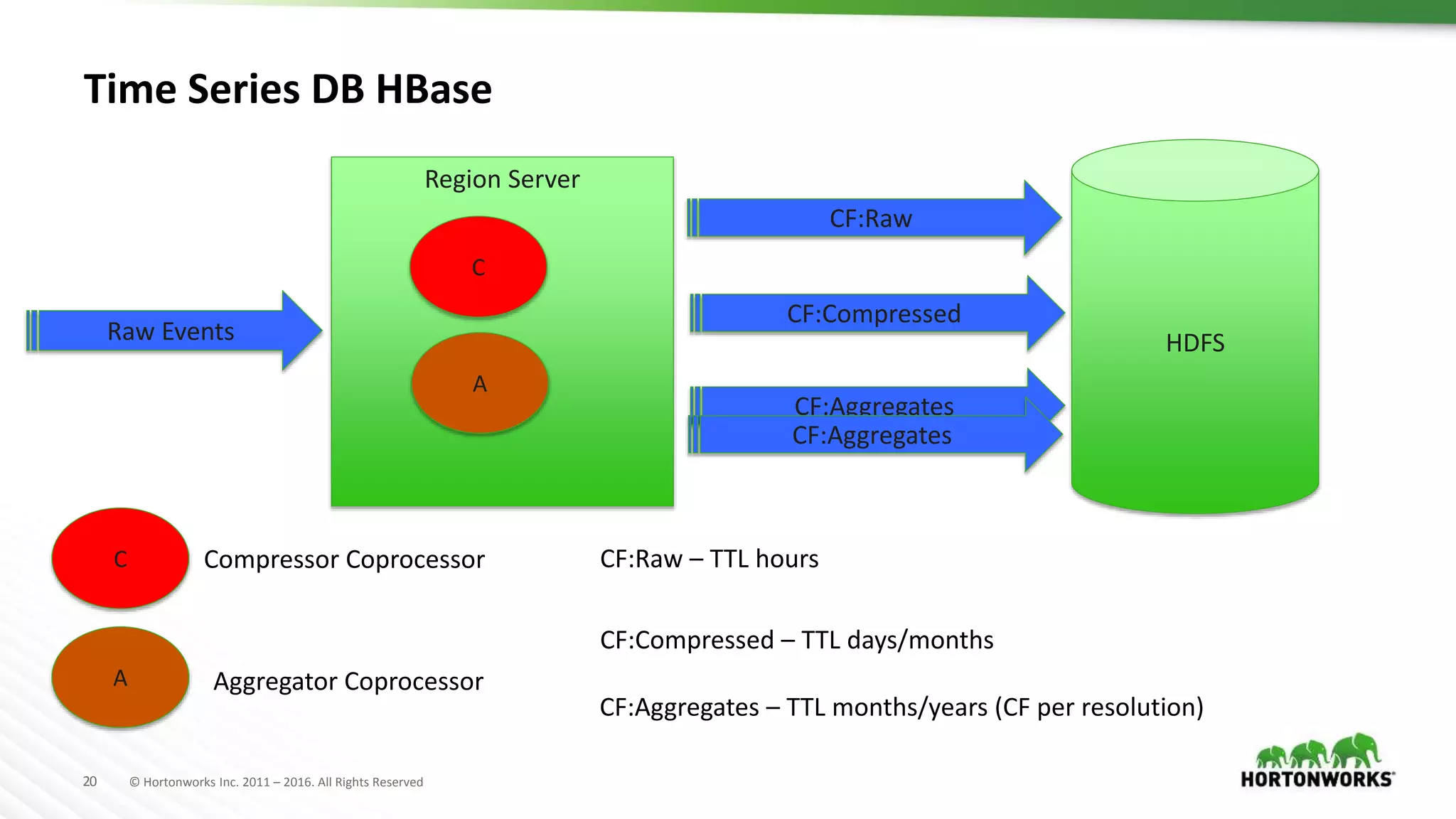







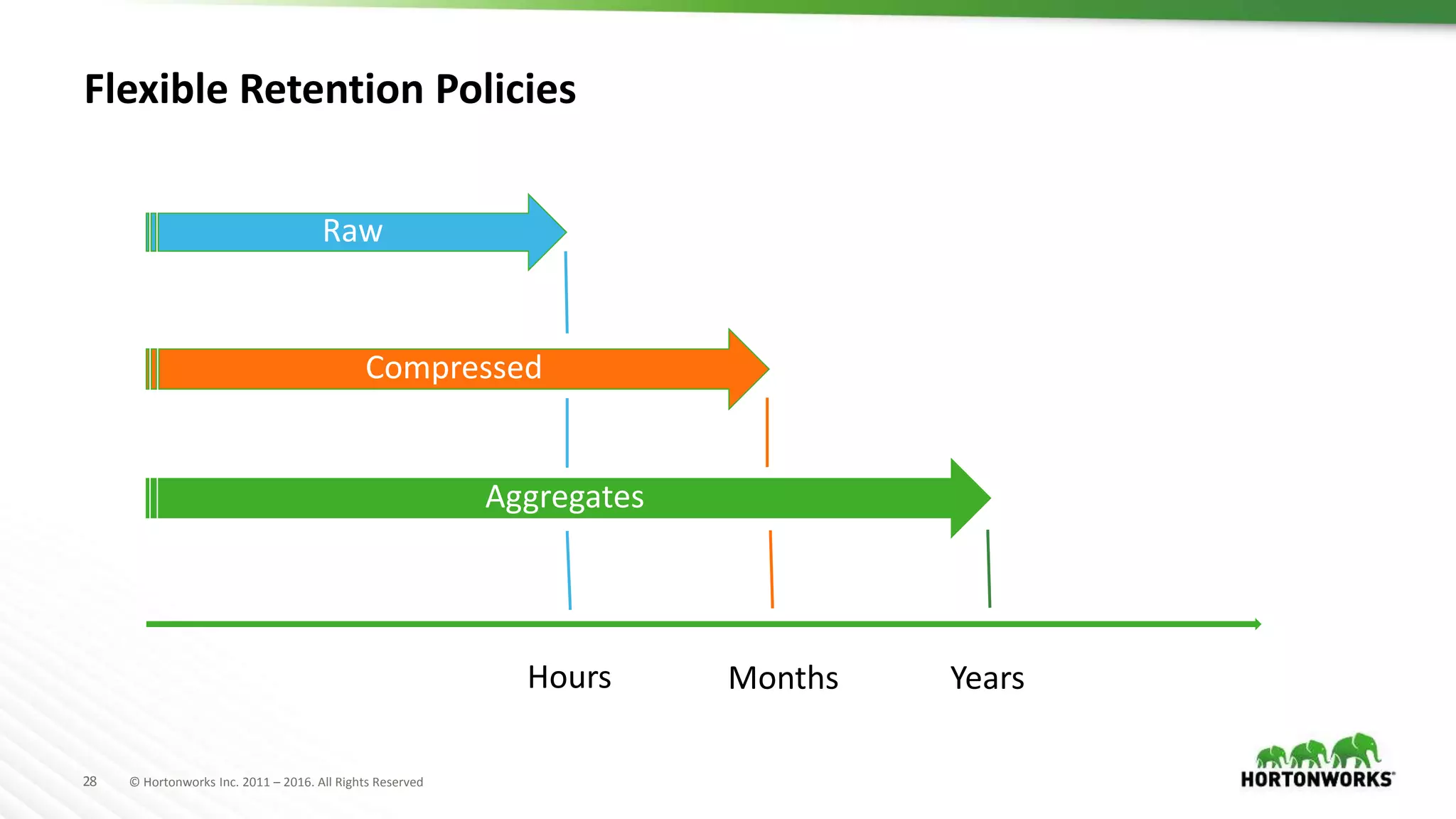
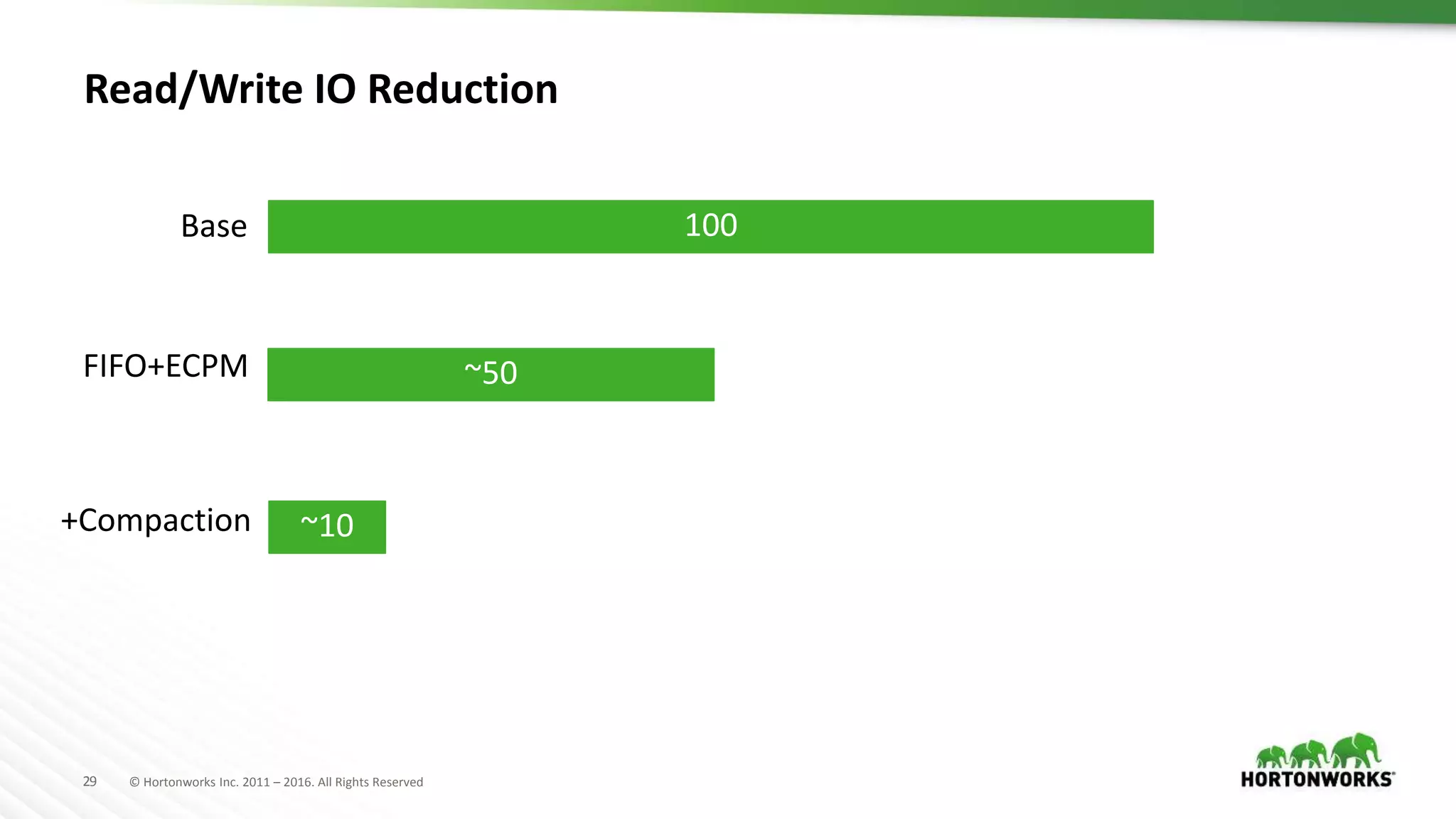
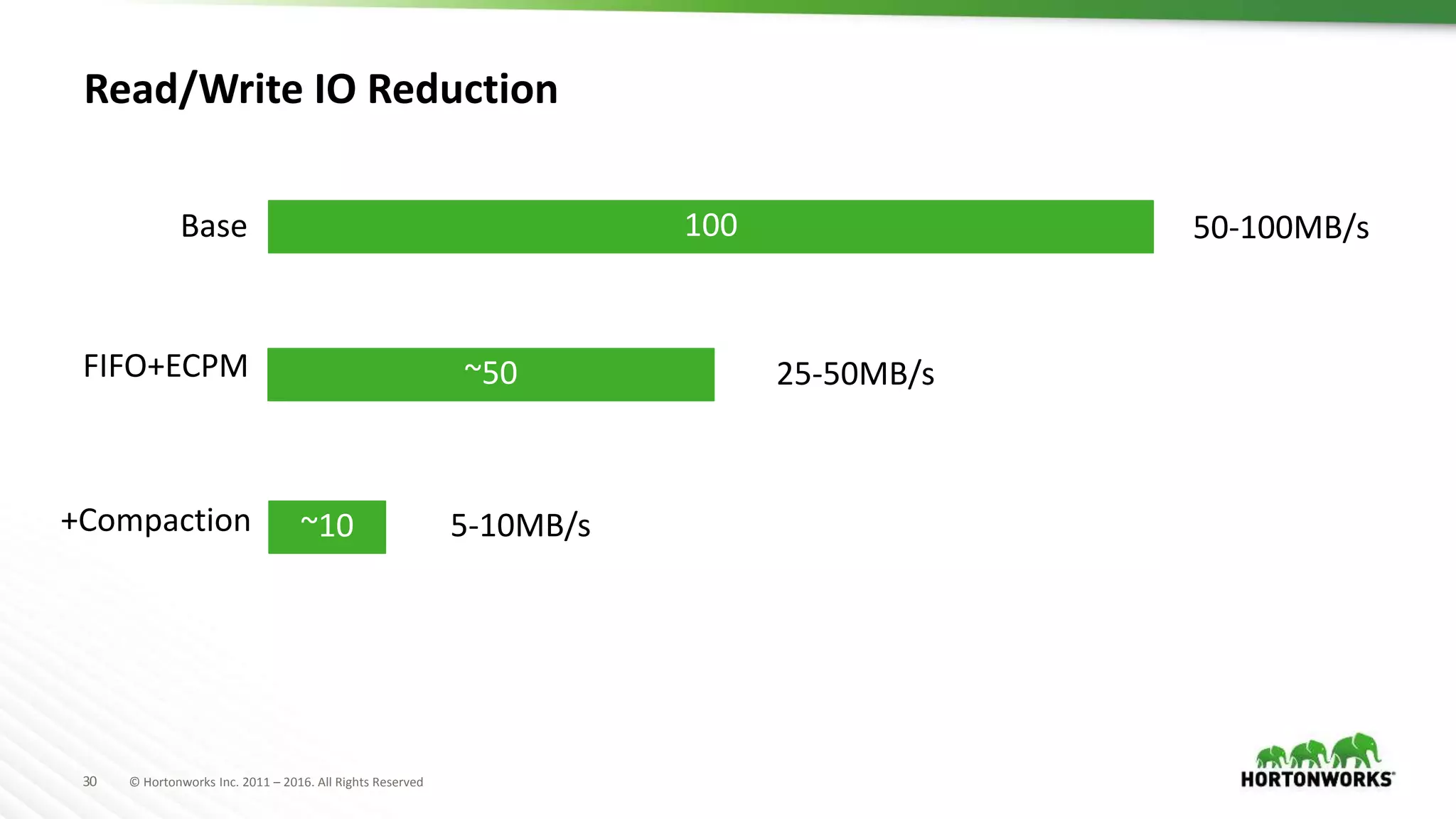
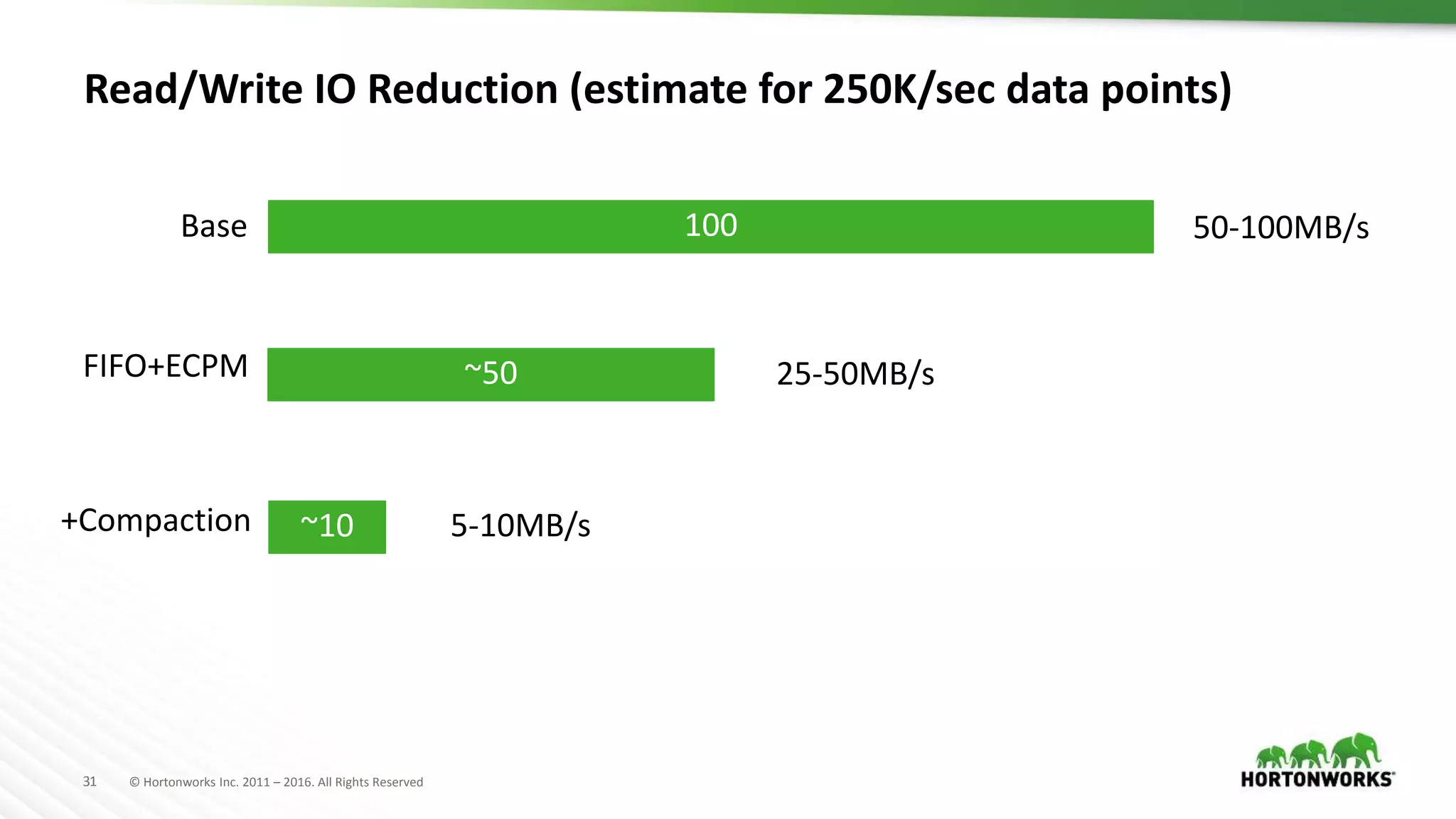




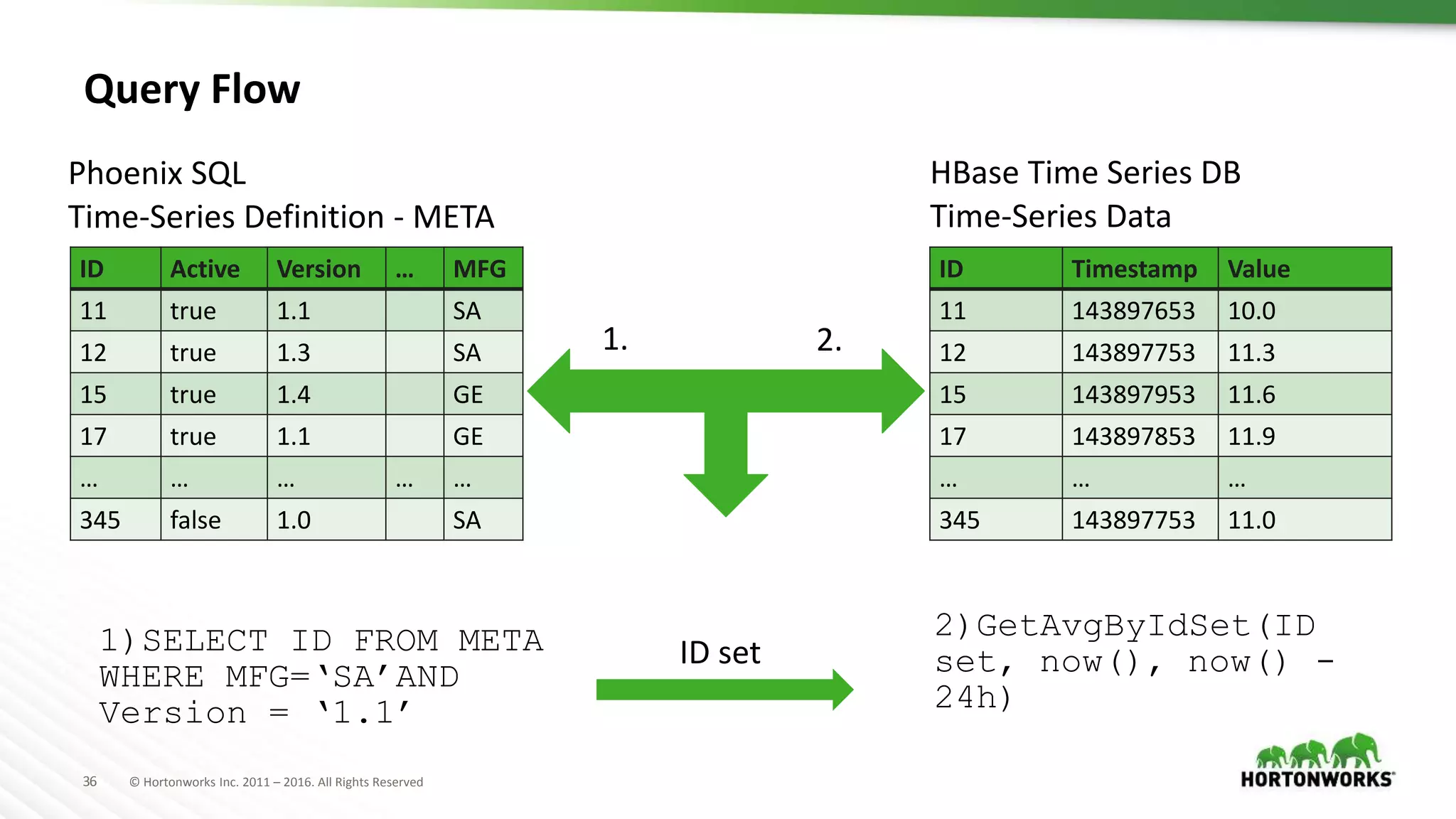




The document discusses strategies for storing time series data from IoT devices in Apache HBase. It describes how IoT data streams typically have a time-series format with identifiers, timestamps and values. It proposes using HBase to store the raw, compressed and aggregated time series data separately with different retention policies. FIFO compaction is recommended for raw data while ECPM or date tiered compaction could be used for compressed and aggregated data. This would reduce read and write I/O compared to the default HBase settings while preserving the temporal locality of the time series data.
Introduction to IoT data streams involves sequences of data points, such as triplet and multiplet formats, including time-series data.
Discussion on the need for a good, open-source, commercially supported time-series data store.
Apache HBase is introduced as an open-source, scalable, distributed NoSQL data store, suitable for temporal data.
Requirements include efficient storage and compression, support for IoT use cases, and automatic aggregations.
Various compaction strategies in HBase, including FIFO and Date Tiered Compaction, to optimize time-series data handling.
Recommendations on flexible retention policies and read/write I/O reductions through various strategies.
Integration of time-series data with Phoenix SQL for metadata management and the development of a Time-Series DB API.
Wrap-up of the presentation with a Q&A session.
























































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)