More Related Content

PPTX

PDF

PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜 
PPTX

PDF

PDF
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF
What's hot

PDF

PDF

PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情 
PPTX
【論文紹介】How Powerful are Graph Neural Networks? 
PDF

PDF

PDF

PDF

PDF
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De... 
PDF

PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PDF

ZIP
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PDF

PDF

PDF

PPTX

PDF
Viewers also liked

PDF

PPTX

PDF
自然言語処理はじめました - Ngramを数え上げまくる ![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/170224qrnn-170224005353-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS 
PPTX

PDF
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS 
PDF
Prophet入門【Python編】Facebookの時系列予測ツール 
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification) 
PDF
Similar to 言語モデル入門

PDF

PDF
大規模日本語ブログコーパスにおける言語モデルの構築と評価 
PDF
TensorFlow math ja 05 word2vec 
PDF

PDF

PPT

PPTX
Machine Learning Seminar (5) 
PDF
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con... 
PDF

PDF

PDF

PDF

PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl... 
PDF

PDF

PDF

PDF
A scalable probablistic classifier for language modeling: ACL 2011 読み会 
PDF

PDF

PDF
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena More from Yoshinari Fujinuma

PPTX
Probabilistic Graphical Models 輪読会 Chapter 4.1 - 4.4 
PPTX

PDF

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PDF

PDF

PDF

PDF

PPTX

PDF
Tweet Recommendation with Graph Co-Ranking 言語モデル入門
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
言語モデルは何に使うの?
• 例:基本タスク
– 機械翻訳
•翻訳した日本語は日本語らしいか。
– かな漢字変換
• 変換候補はよく使われる漢字(+送り仮名等)か。
• 例:変化球系タスク
– 翻字(マイケル=Michael)検出(Li+ ACL 2004)
– Twitter上のTopic tracking(Lin+ KDD 2011)
– ユーザのオンラインコミュニティの退会予測
(Danescu-Niculescu-Mizil+ WWW 2013)
- 7.
Noisy Channel Model
(BayesRule applied)
• O: output, I: input
• かな漢字変換
– O: 変換候補, I: ひらがな列
– P(I|O): かな漢字モデル
• 機械翻訳:
– O: 日本語, I: 英語
– P(I|O): 翻訳モデル(言語間の対応)
言語モデル!
- 8.
- 9.
- 10.
- 11.
- 12.
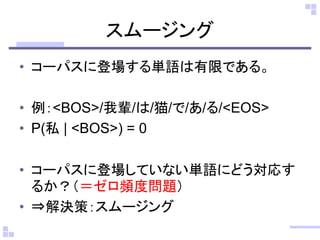
スムージングの種類
• 加算スムージング ⇒不十分
• n-1, n-2, …と低次のn-gramを用いよう!
• 補完(interpolated)型
– 常に低次を考慮
– Interpolated Kneser-neyスムージング
• バックオフ型
– 高次のngramが存在しない場合、低次を考慮
– Good Turingによる推定値で低次をDiscount
- 13.
- 14.
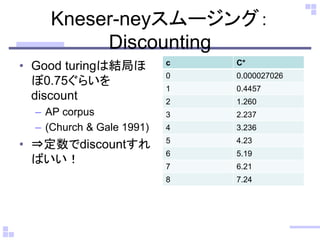
Good Turing 推定:バックオフ型
•頻度の頻度を用いた、頻度の補正
• N_c: 頻度の頻度
• 例:マグロ:2、鮭:3、こはだ:1, 玉子:1, い
か:1
– 合計8単語
• N_1 = 3, N_2 = 1, N_3 = 1
• 1回しか観測されていない単語を「未知の単
語が観測される確率」と扱う
- 15.
Good Turing 推定:例
•P_gt(ゼロ頻度) = N_1 / N
• 一回だけ観測された単語:
– c*(こはだ) =2 * N_2 / N_1 = 2/3
– P_gt(一回だけの単語) = 2/3 / 8 = 1/12
• ゼロ頻度:
– P_gt(ゼロ頻度) = 3/8
- 16.
- 17.
- 18.
Kneser-neyスムージング:例
• I wantto go to ______
– Toyama? Fransisco?
– Fransiscoは頻度が高いが、ほぼSanの後に続く
• 通常の場合:unigramの頻度
– 単語wは現れている頻度は?
• Kneser-neyのアイディア:
– P_continuation: 単語wは直前の単語toの後に
続く単語として、未知の例かどうか?
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
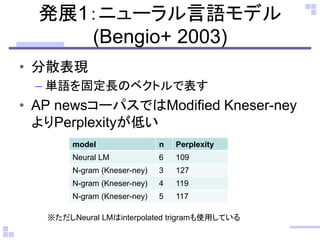
発展1:ニューラル言語モデル
(Bengio+ 2003)
• 分散表現
–単語を固定長のベクトルで表す
• AP newsコーパスではModified Kneser-ney
よりPerplexityが低い
model n Perplexity
Neural LM 6 109
N-gram (Kneser-ney) 3 127
N-gram (Kneser-ney) 4 119
N-gram (Kneser-ney) 5 117
※ただしNeural LMはinterpolated trigramも使用している
- 25.
- 26.
- 27.
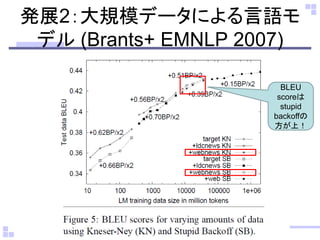
発展3:ベイズ階層言語モデル
• Hierarchical DirichletLanguage Model (Mackay,
NLE 1998)
– Kneser-neyにPPで勝てない。。。
• Hierarchical Pitman-Yor Language Model (Teh,
ACL 2006)
– Priorをディリクレ過程ではなくPitman-Yor過程に変えたら
Modified Kneser-neyと同じぐらい!
• Nested Pitman-Yor Language Model (持橋+,
ACL 2009)
- 28.
- 29.
- 30.
- 31.
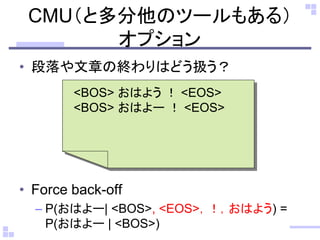
実際のコマンド (CMU toolkit)
•-backoff_from_ccs_inc
– Inclusive force back offを指定
– P(おはよー| <BOS>, <EOS>,!,おはよう)
• P(おはよー | <BOS>): inclusive
• P(おはよー): exclusive
• -include_unks
– 未知語をPerplexity算出に含めるか
– 同じ文字トークン(<unk>)として扱うか
– 別々の文字トークン(<unk_1>, <unk_2>…)
- 32.
参考文献
• 日本語入力を支える技術
• StanfordのNLPの授業
–https://class.coursera.org/nlp/lecture
• NYUの言語モデルの授業スライド
– http://www.cs.nyu.edu/~petrov/lecture2.pdf
• Univ. of Marylandの言語モデルの授業スライド
– http://www.umiacs.umd.edu/~jimmylin/cloud-2010-
Spring/session9-slides.pdf
• Neural Language Modelの授業スライド
– http://www.inf.ed.ac.uk/teaching/courses/asr/2013-
14/asr09-nnlm.pdf