論文紹介 A Bayesian framework for word segmentation: Exploring the effects of context
1.
A Bayesian frameworkfor
word segmentation:
Exploring the effects of context
Sharon Goldwater a,*, Thomas L. Griffiths b, Mark Johnson c
a School of Informatics, University of Edinburgh, Informatics Forum, 10 Crichton Street,
Edinburgh, EH8 9AB, UK
b Department of Psychology, University of California, Berkeley, CA, United States
c Department of Cognitive and Linguistic Sciences, Brown University, United States 1
担当:谷口彰
Cognition 112 (2009) 21–54 被引用数(2015/07/05時点):229
2.
A b st r a c t
• Saffran et al. [Saffran, J., Aslin, R., & Newport, E. (1996). Statistical learning in 8-
month-old infants. Science, 274, 1926–1928]の研究以来、幼児がどのように
して音声系列に存在する統計的な規則性を個別の単語を識別するために
使用しているのか、という問題への関心が強くなっている
⇒単語分割の問題
• 本研究では、計算モデル(Computational model)を用いて、学習者(幼
児)が用いる可能性のある単語の性質に関するいくつかの仮説
(Assumptions)の効果を検証する
• 特に、これらの仮説がどのように単語の種類に影響を及ぼすのか
• child-directed speech(子供に向けて発話した音声)の書き起こしコーパス
から単語に分割
• ベイズ理論のフレームワークの中でいくつかのモデルを提案する 2
3.
A b st r a c t
• 単語に関して仮定する因果関係
1. 個々の単語が独立
2. 他の単語を予測するための手助けとなる(例えば、n-gram)
• 独立性の仮定は、コーパス内の2,3個の単語列をundersegment
(孤立単語として誤認識)することを示す
• 例:What‘sthat, doyou, inthehouse
• その一方、学習者が単語を予測すると仮定したとき、分割結果は、
はるかに正確(far more accurate)になる
• これらの結果は、以下のことが示唆される
• 文脈(context)を考慮に入れることが、統計的単語分割を成功させる
ために重要である
• 若い幼児ですら、通常考えられるよりも、もっとかすかな(subtle)
統計的パターンを発見できるという可能性をもたらす 3
2. Words andtransitional probabilities
• 著者らは、言語の性質に関する2つの異なる仮定により
開発されたモデルについて調査する
1. 単語が統計的に独立
2. 単語が次の単語を予測できる
• これら2つの仮定による学習者の違いについて考察する
• それぞれの学習者が考える言語の仮説空間( the space of
linguistic hypotheses )の違い
15
2.1.1. Maximum-likelihood estimation
•Venkataraman (2001) の研究
• コーパス内の発話の数:U
• 発話境界(終端文字)を表す識別記号:$
• 確率モデルの基本的な流れ
• 全ての可能な単語の集合上の確率分布:Pw
• 生成された単語は、これまでに生成された単語の列に連結される
• 境界以外の記号は、発話の終わりの記号$が生成されない限り追加される
23
Repeat U times:
Repeat until $ is generated:
1. Generate the next word, w, with probability Pw(W).
2. Generate $ with probability p$.
2.1.2. Bayesian models
•結果として、コーパスと一致した仮説のみを考慮する
• 事前確率は生成モデルを用いて計算される
• コーパス内の単語列は、以下の4ステップにより生成されると
仮定する
• Step 1: 語彙の種類の数を生成する
• Generate the number of types that will be in the lexicon.
• Step 2: 各単語の発話される頻度を生成する
• Generate a token frequency for each lexical type.
• Step 3: 各単語の音素表現を生成する(発話境界「$」を除く)
• Generate the phonemic representation of each type (except for the
single distinguished ‘‘utterance boundary” type, $).
• Step 4: 発話の集合を生成する
• Generate an ordering for the set of tokens.
32
3. Unigram model
3.1.Generative model
• :分割された単語
• ユニグラムモデルは、i番目の単語Wiが以下のように生成されること
を仮定する
36
37.
3. Unigram model
3.1.Generative model
• 次のように、確率を割り当てる
• α0:モデルのパラメータ
• 𝑛:以前に生成された単語の数(=i-1)
• 𝑛𝑙:単語𝑙の出現回数
• p#:単語境界の生成確率
37
38.
3. Unigram model
3.1.Generative model
• 以前の単語 W-i が与えられたときの𝑤𝑖の分布
• P0:Step 2aでのユニグラム音素分布を参照する
• (The p# and 1-p# factors in this distribution result from the process
used to generate a word from constituent phonemes: after each
phoneme is generated, a word boundary is generated with
probability p# and the process ends, or else no word boundary is
generated with probability 1-p# and another phoneme is generated.) 38
39.
3. Unigram model
3.1.Generative model
• nが小さいとき
• Step 1において、新規な語彙を生成する確率が比較的大きく
なる
• より多くの単語が生成され、nが増える
• 新規な語彙を生成する確率は相対的に減少する
• 完全に消えることはない
39
3. Unigram model
3.1.Generative model
• この種のモデルの例はDirichlet process (Ferguson, 1973)と
して知られている
• Dirichlet process
• ベイズ統計で一般的に使用されるクラスタリングのモデル
• ノンパラメトリックな事前分布を仮定
• The Dirichlet process has two parameters:
• 集中度パラメータ(the concentration parameter): α0
• 基底分布(the base distribution): P0
• the ‘‘Dirichlet process” (DP) modelの詳細はAppendix A 41
42.
3.2. Inference
• すべての可能性の中から最も高い確率となるセグメン
テーションを特定する問題
•Gibbs sampling (Geman & Geman, 1984)
• Markov chain Monte Carlo algorithm (Gilks et al., 1996)の一種
• 条件付き事後分布から変数を繰り返しサンプリング
42
ギブスサンプリング
https://ja.wikipedia.org/wiki/%E3%82%AE%E3%83%96%E3%82%B9%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AA%E3%83%B3%E3%82%B0
3.3. Simulations
3.3.1. Data
•単語分割のこれまでのモデルとの比較を容易にするため
に、Brent (1999) and Venkataraman (2001)で用いられたも
のと同じコーパスでの結果を示す
• the Bernstein–Ratner corpus (Bernstein-Ratner, 1987) of the
CHILDES database (MacWhinney & Snow, 1985)
• 13- to 23-month-olds
• 9790 utterances, with 33,399 word tokens
• 1発話における平均単語数:3.41
• 1単語の長さ(音素数)の平均:2.87 44
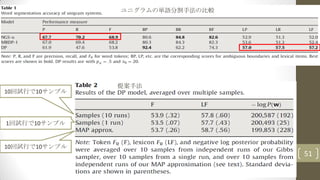
3.3.2. Evaluation procedure
•モデルごとに以下のスコアを計算する
• P, R, F: precision, recall, and F0 on words
• LP, LR, LF: precision, recall, and F0 on the lexicon
• BP, BR, BF: precision, recall, and F0 on potentially ambiguous
boundaries (潜在的にあいまいな境界)
• (i.e. utterance boundaries are not included in the counts).
46
47.
3.3.2. Evaluation procedure
•分割による単語数:7語
• 正しい分割による単語数:6語
• 単語の一致数:3語
• P = 42.9% (3/7), R = 50.0% (3/6), F = 46.2%
• LP = 50.0% (3/6), LR = 50.0% (3/6), LF = 50.0%
• BP = 66.7% (4/6), BR = 80.0% (4/5), BF = 72.7% 47
例: look at the big dog there
分割例:look at the bigdo g the re
48.
3.3.2. Evaluation procedure
•比較
• Brent’s MBDP-1 system (Brent, 1999)
• Venkataraman’s n-gram segmentation systems (Venkataraman,
2001)
• NGS-u and NGS-b (for the unigram and bigram models)
• 提案したアルゴリズムの性能評価
• a single sample taken after 20,000 iterations
• an approximation of the MAP solution 48
49.
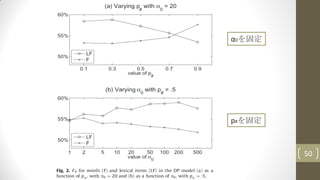
3.3.3. Results anddiscussion
• DPモデル(提案モデル)には2つのパラメータがある
• p# (the prior probability of a word boundary)
• α0 (which affects the number of word types proposed)
• Fig. 2 shows the effects of varying of p# and α0.
• p#の値が小さいと、語彙のF値が向上する傾向がある
• より長い単語を許容する
• α0の値が大きいと、語彙のF値が向上する傾向がある
• より新規な単語を許容する
• 他のセクションでは、 p# = 0.5; α0 = 20の結果を示す 49
5. Bigram model
5.1.The hierarchicalDirichletprocessmodel
• α0とα1:モデルパラメータ
• P0:ユニグラムモデルとして定義された語彙のモデル
• 𝑙’:Wi-1のthe lexical form
• :ユニグラムl’の出現集
• :バイグラム<𝑙’, 𝑙>の出現数
• 𝑏:1番目のi-1単語でのバイグラムの数
• the number of bigram types in the first i-1 words
• 𝑏𝑙:2番目の単語𝑙の数
• the number of those types whose second word is 𝑙
62


![A b s t r a c t
• Saffran et al. [Saffran, J., Aslin, R., & Newport, E. (1996). Statistical learning in 8-
month-old infants. Science, 274, 1926–1928]の研究以来、幼児がどのように
して音声系列に存在する統計的な規則性を個別の単語を識別するために
使用しているのか、という問題への関心が強くなっている
⇒単語分割の問題
• 本研究では、計算モデル(Computational model)を用いて、学習者(幼
児)が用いる可能性のある単語の性質に関するいくつかの仮説
(Assumptions)の効果を検証する
• 特に、これらの仮説がどのように単語の種類に影響を及ぼすのか
• child-directed speech(子供に向けて発話した音声)の書き起こしコーパス
から単語に分割
• ベイズ理論のフレームワークの中でいくつかのモデルを提案する 2](https://image.slidesharecdn.com/s-170612092818/85/A-Bayesian-framework-for-word-segmentation-Exploring-the-effects-of-context-2-320.jpg)























































































![[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding](https://cdn.slidesharecdn.com/ss_thumbnails/pfnonthedimensionalityofwordembedding-190126060357-thumbnail.jpg?width=640&height=640&fit=bounds)










![[IROS2017] Online Spatial Concept and Lexical Acquisition with Simultaneous L...](https://cdn.slidesharecdn.com/ss_thumbnails/iros2017presentationslide01ss-171002001359-thumbnail.jpg?width=640&height=640&fit=bounds)







