More Related Content

PDF
DSIRNLP06 Nested Pitman-Yor Language Model 
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~ 
ODP

PDF

PDF

PDF
DATUM STUDIO PyCon2016 Turorial 
PDF

PPTX
What's hot

PDF
実践・最強最速のアルゴリズム勉強会 第四回講義資料(ワークスアプリケーションズ & AtCoder) 
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~ 
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V7 
PDF
実践・最強最速のアルゴリズム勉強会 第三回講義資料(ワークスアプリケーションズ & AtCoder) 
PDF
Ruby を用いた超絶技巧プログラミング(夏のプログラミングシンポジウム 2012) 
PDF
10分で分かるr言語入門ver2.15 15 1010 
PDF
クックパッド春の超絶技巧パンまつり 超絶技巧プログラミング編 資料 
PDF
Cmdstanr入門とreduce_sum()解説 
PDF

PDF
実践・最強最速のアルゴリズム勉強会 第五回講義資料(ワークスアプリケーションズ & AtCoder) 
PDF

PDF
10分で分かるr言語入門ver2 upload用 
PDF

PDF

PPTX
Text classification zansa 
PDF

PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V6 
PDF
10分で分かるr言語入門ver2.14 15 0905 
PDF

PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V8 Similar to 自然言語処理はじめました - Ngramを数え上げまくる

PDF

PDF
プログラミング講座 #6 競プロのテクニック(初級) 
KEY
Algebraic DP: 動的計画法を書きやすく 
PDF

PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP 
PDF

PDF
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる ![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート] 
PDF
AtCoder Beginner Contest 029 解説 
PDF

PDF

PDF
Data-Intensive Text Processing with MapReduce ch4 
PDF

PDF

PDF

PDF
Programming in Scala Chapter 17 Collections 
PDF
2012.11.17 CLR/H&札幌C++勉強会 発表資料「部分文字列の取得を�効率よく!楽に!� - fundoshi.hppの紹介と今後の予定 -」 
PDF
2011.12.10 関数型都市忘年会 発表資料「最近書いた、関数型言語と関連する?C++プログラムの紹介」 
PDF
Introduction of tango! (jp) 
DOCX
自然言語処理はじめました - Ngramを数え上げまくる
- 1.
- 2.
自己紹介
ID : phyllo
ブログ: http://d.hatena.ne.jp/jetbead
• 某Web企業の新卒
• 入社してから自然言語処理始めました!!
• 最近の興味
– 自然言語処理を使って、効果的なダイエット法を見つ
けること
- 3.
- 4.
- 5.
Ngram頻度を数える
• 超基礎!
–「入門自然言語処理」でいうと18ページ目の内容
– というか、ただの統計処理
• しかし!
– 頻度分布
– Ngram言語モデル
– その他いろんな応用が考えられる!(はず)
- 6.
Ngramとは?
• 「隣り合うN個の塊」のこと
–単語ngramや文字ngramなどがある
「金持ち喧嘩せず」の文字2gram(bigram)
→{金持, 持ち, ち喧, 喧嘩, 嘩せ, せず}
「This is apple computer」の単語3gram(trigram)
→{This-is-apple, is-apple-computer}
- 7.
- 8.
方法
1. ナイーブな方法
2. Suffix Arrayを使った方法
3. 近似カウント法
4. 分散処理を使う方法
- 9.
- 10.
1.ナイーブな方法
• やるだけ!
–Perlだとハッシュに入れて数えたり
use strict;
use warnings;
use utf8;
use encoding "utf8";
my $ngram = shift;
my %hash;
while(my $line = <>){ #一行とってきて
chomp $line; #最後の改行を削って
for(my $i=0; $i<length($line)-$ngram+1; $i++){ #ずらしながら
$hash{substr($line,$i,$ngram)}++; #ngram文字ずつ数える
}
}
foreach my $key (keys %hash){
print $key,"¥t",$hash{$key},"¥n";
}
- 11.
- 12.
- 13.
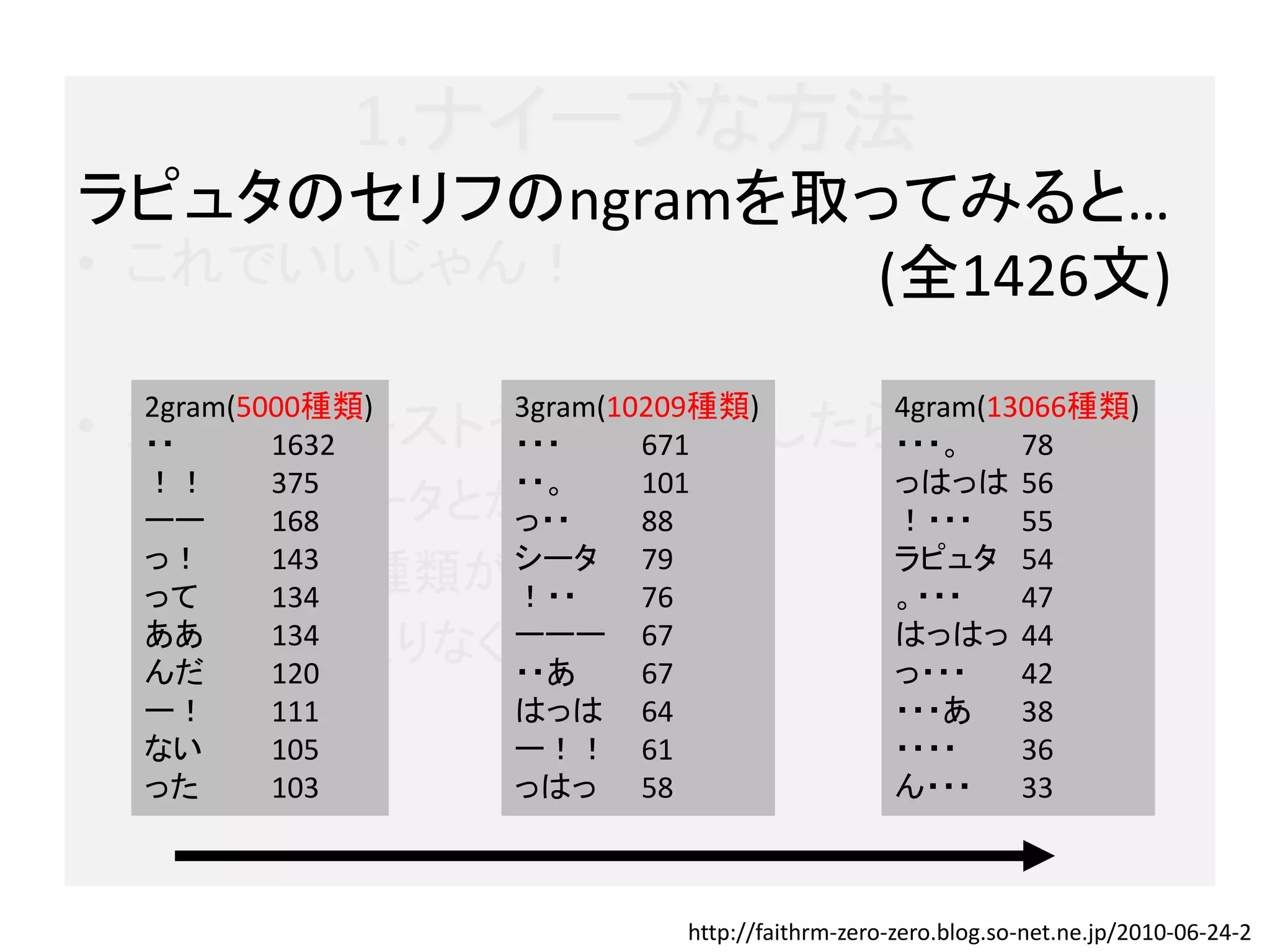
1.ナイーブな方法
ラピュタのセリフのngramを取ってみると…
• これでいいじゃん! (全1426文)
2gram(5000種類) 3gram(10209種類) 4gram(13066種類)
• 大規模テキストやNを大きくしたら?
・・ 1632 ・・・ 671 ・・・。 78
!! 375 ・・。 101 っはっは 56
– 1GBのデータとかは? 88
ーー 168 っ・・ !・・・ 55
っ! シータ ラピュタ 54
– Ngramの種類が増える79
って
143
134 !・・ 76 。・・・ 47
– メモリが足りなくなる… 67
ああ
んだ
134
120
ーーー
・・あ 67
はっはっ 44
っ・・・ 42
ー! 111 はっは 64 ・・・あ 38
ない 105 ー!! 61 ・・・・ 36
った 103 っはっ 58 ん・・・ 33
http://faithrm-zero-zero.blog.so-net.ne.jp/2010-06-24-2
- 14.
- 15.
- 16.
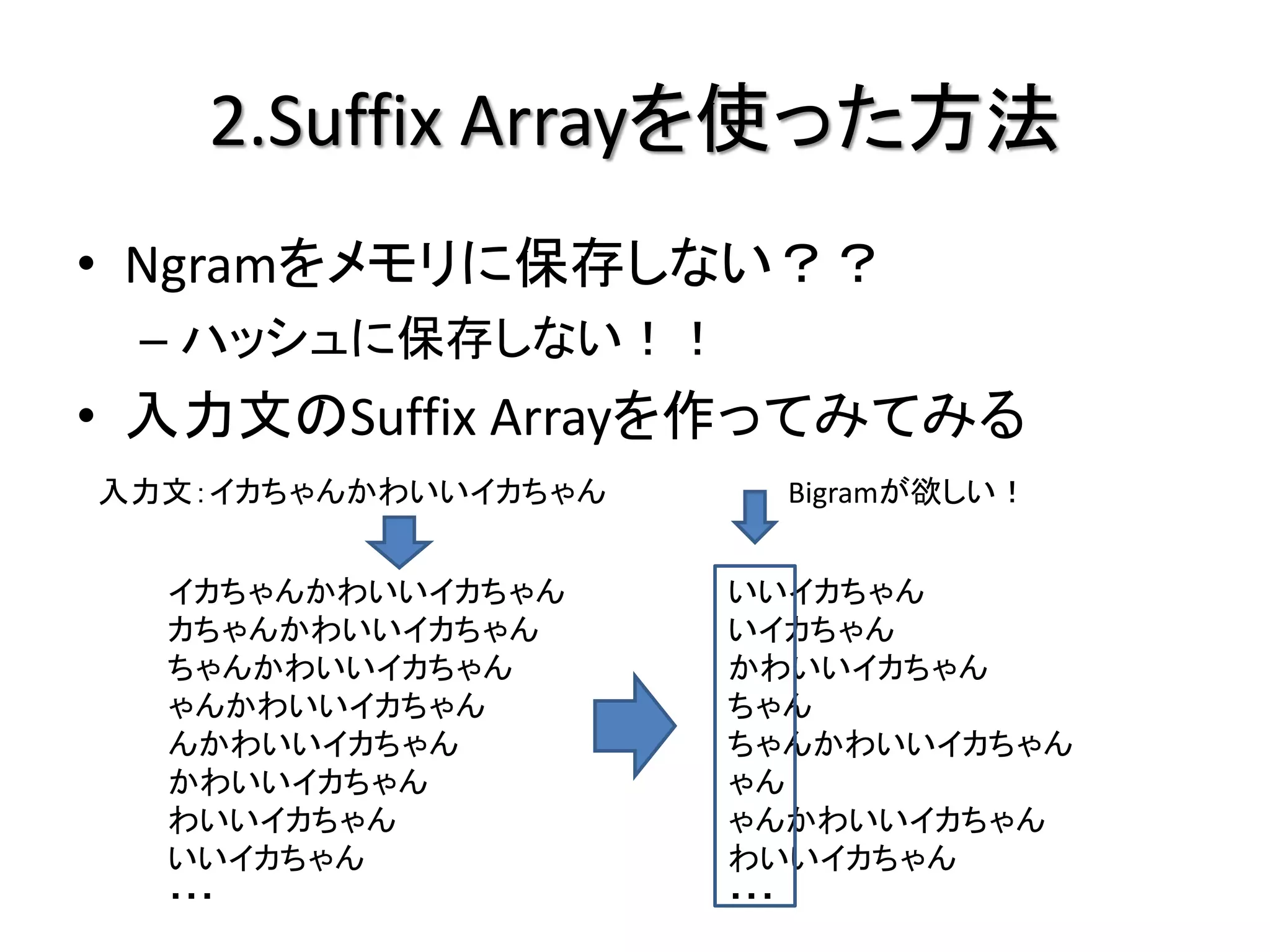
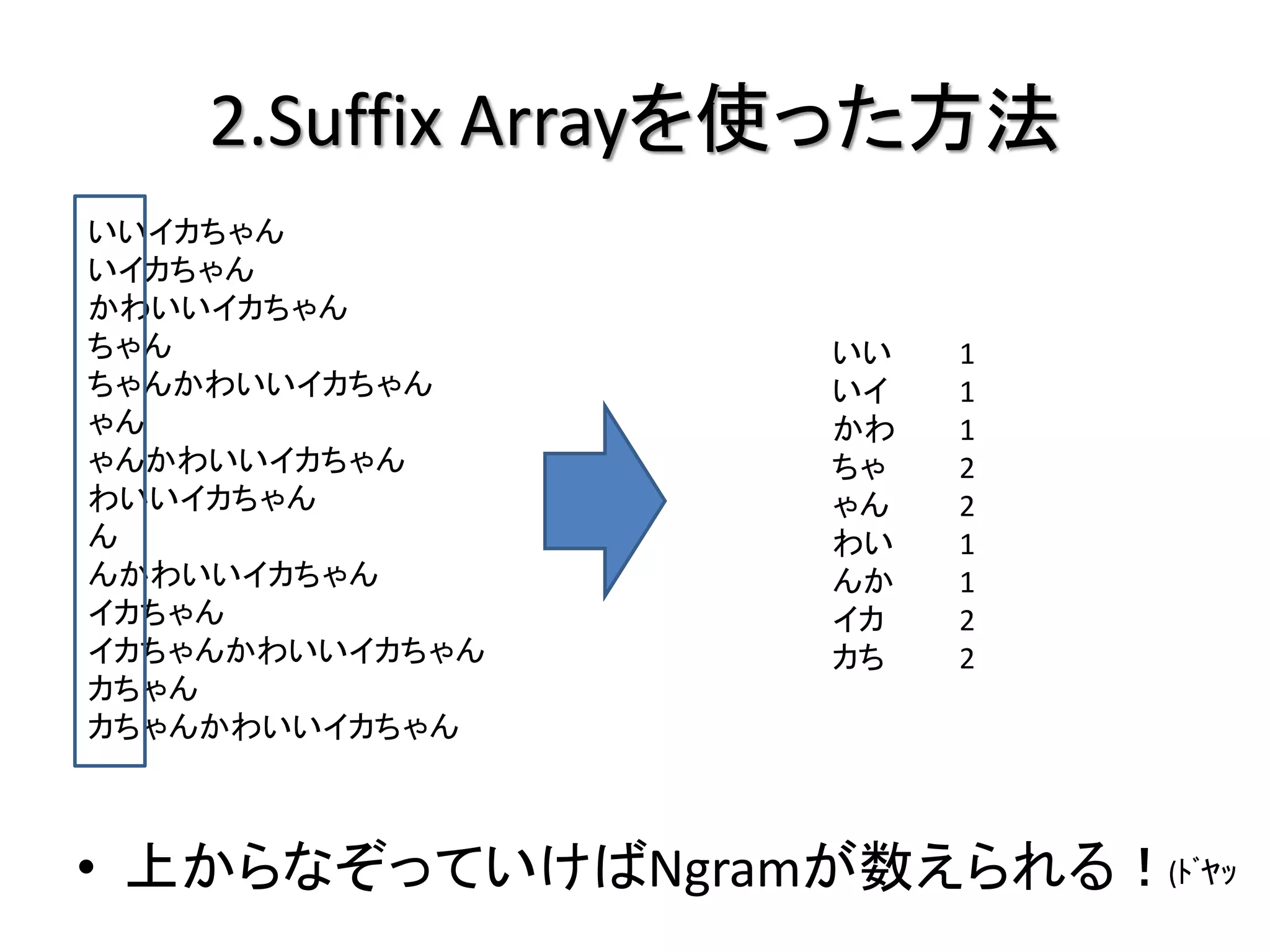
2.Suffix Arrayを使った方法
• Ngramをメモリに保存しない??
– ハッシュに保存しない!!
• 入力文のSuffix Arrayを作ってみてみる
入力文:イカちゃんかわいいイカちゃん
イカちゃんかわいいイカちゃん いいイカちゃん
カちゃんかわいいイカちゃん いイカちゃん
ちゃんかわいいイカちゃん かわいいイカちゃん
ゃんかわいいイカちゃん ちゃん
んかわいいイカちゃん ちゃんかわいいイカちゃん
かわいいイカちゃん ゃん
わいいイカちゃん ゃんかわいいイカちゃん
いいイカちゃん わいいイカちゃん
・・・ ・・・
- 17.
2.Suffix Arrayを使った方法
• Ngramをメモリに保存しない??
– ハッシュに保存しない!!
• 入力文のSuffix Arrayを作ってみてみる
入力文:イカちゃんかわいいイカちゃん Bigramが欲しい!
イカちゃんかわいいイカちゃん いいイカちゃん
カちゃんかわいいイカちゃん いイカちゃん
ちゃんかわいいイカちゃん かわいいイカちゃん
ゃんかわいいイカちゃん ちゃん
んかわいいイカちゃん ちゃんかわいいイカちゃん
かわいいイカちゃん ゃん
わいいイカちゃん ゃんかわいいイカちゃん
いいイカちゃん わいいイカちゃん
・・・ ・・・
- 18.
- 19.
- 20.
2.Suffix Arrayを使った方法
/* 効率的ではないC++のコード*/
vector<size_t> ptr; //★先頭位置を保持するポインタ(のかわりのindex)
for(size_t i=0; i<ustr.length()-N+1; i++){ ptr.push_back(i); }
vector<int> cmn_char; //次の文字との共通文字数
Cmp cmp(ustr); //ポインタで文字列を比較するためのファンクタ
//★Suffix Arrayの辞書順ソート
sort(ptr.begin(), ptr.end(), cmp);
//★共通文字数カウント
for(size_t i=0; i<ptr.size(); i++){
if(i+1<ptr.size()){
cmn_char.push_back(common_prefix_length(ustr, N, ptr[i], ptr[i+1])); //次の文と何文字共通しているか
}else{
cmn_char.push_back(0);
}
}
//★順番にptrを見ていって、cmn_charがN以上な個数を数える
...
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
3.Lossy Counting ※Δを要素ごとに保存してない
# 新しい要素が来た!
# n個目だね
# もし保存してたら頻度+1
# 新しい要素なら
## 新たに保存
## 頻度はΔ+1
# 定期的に
## Δを更新して
## すべての要素を確認
## 頻度がΔより小さければ
削除
Graham Cormode and Marios Hadjieleftheriou, “Methods for finding frequent items in data streams”, The VLDB Journal
- 30.
3.Lossy Counting
• C++のmapで実装すると…
/* 効率的でないC++のコード */
class LossyCounter {
//★保存している要素リスト
map<string,pair<int,int> > S;
//パラメータ
int N;
double gamma, epsilon;
int b_current; //Δ
//★保存している要素で頻度がΔより小さいものを削除
void next_backet();
public:
//★初期化
LossyCounter(double gamma, double epsilon);
//★新しい要素をSに追加
void add(const string &str);
//要素strの頻度
int get(const string &str);
//要素リストをすべて表示
void show();
//要素リストのサイズを返す
int size();
};
- 31.
- 32.
- 33.
- 34.
- 35.
- 37.
補足情報
• 他のNgram数え上げ方法
–PrefixSpan
• http://www.cs.uiuc.edu/~hanj/pdf/span01.pdf
• http://chasen.org/~taku/publications/nlp2002.pdf
• http://2boy.org/~yuta/publications/substring_mining.p
df
- 38.
補足情報
• ちょっと試してみたい!
–(自己責任で自由に使用・加工してください)
– SuffixArrayを使った頻度カウント
• http://d.hatena.ne.jp/jetbead/20111012/1318422417
– Lossy Countingを使った頻度カウント
• http://d.hatena.ne.jp/jetbead/20111014/1318547950
- 39.
補足情報
• 参考資料など
–岩波講座ソフトウェア科学15「自然言語処理」
– アルゴリズム・サイエンスシリーズ5 数理技法編
「オンラインアルゴリズムとストリームアルゴリズ
ム」
– 入門「自然言語処理」
- 40.
補足情報
• 参考資料など
–http://ci.nii.ac.jp/naid/110002934647
– http://chalow.net/2010-06-21-1.html
– http://diary.overlasting.net/2010-04-23-3.html
– http://chalow.net/2010-05-12-1.html
– http://d.hatena.ne.jp/ny23/20101108/p1










![1.ナイーブな方法
[入力文]
イカちゃんかわいい
[出力]
ゃん 1 かわ 1
ちゃ 1 イカ 1
カち 1 んか 1
わい 1 いい 1](https://image.slidesharecdn.com/random-111209232856-phpapp02/75/Ngram-11-2048.jpg)





![2.Suffix Arrayを使った方法
/* 効率的ではないC++のコード */
vector<size_t> ptr; //★先頭位置を保持するポインタ(のかわりのindex)
for(size_t i=0; i<ustr.length()-N+1; i++){ ptr.push_back(i); }
vector<int> cmn_char; //次の文字との共通文字数
Cmp cmp(ustr); //ポインタで文字列を比較するためのファンクタ
//★Suffix Arrayの辞書順ソート
sort(ptr.begin(), ptr.end(), cmp);
//★共通文字数カウント
for(size_t i=0; i<ptr.size(); i++){
if(i+1<ptr.size()){
cmn_char.push_back(common_prefix_length(ustr, N, ptr[i], ptr[i+1])); //次の文と何文字共通しているか
}else{
cmn_char.push_back(0);
}
}
//★順番にptrを見ていって、cmn_charがN以上な個数を数える
...](https://image.slidesharecdn.com/random-111209232856-phpapp02/75/Ngram-20-2048.jpg)



















