Download to read offline


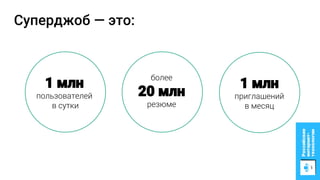


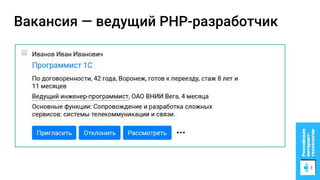
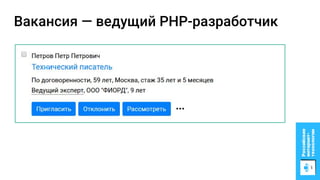




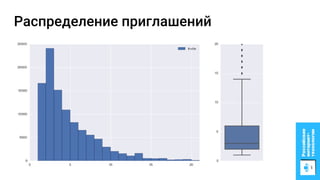
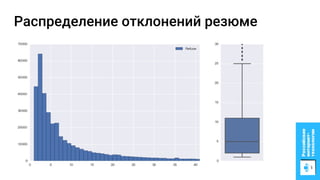


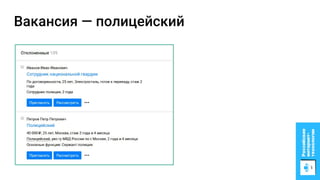



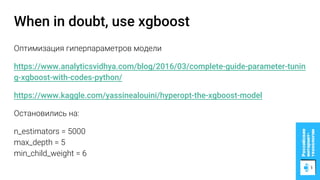

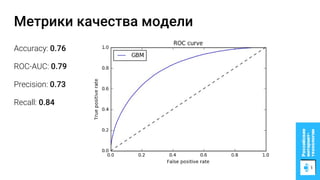


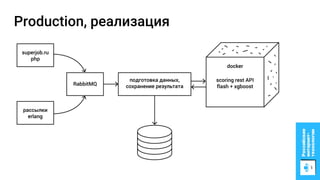
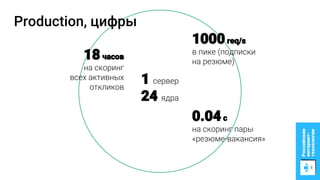

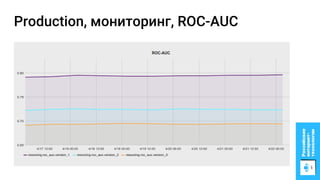
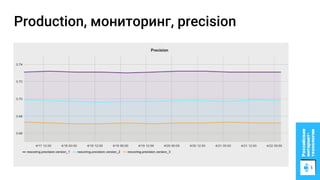





Документ описывает процесс применения машинного обучения для ранжирования откликов соискателей на позиции на сайте superjob.ru с целью оптимизации подбора кандидатов. Представлены методы подготовки данных, обучения модели, внедрения в производственную среду и мониторинга её качества, а также примеры признаков, использованных для классификации откликов. В результате достигнуты значительные улучшения в показателях качества модели и сокращении времени на обработку откликов.



































































