Download to read offline




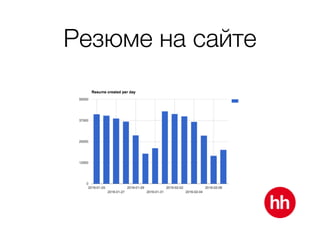






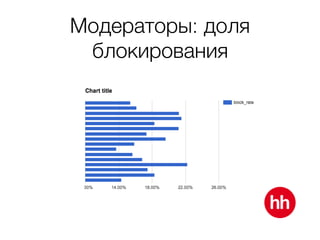

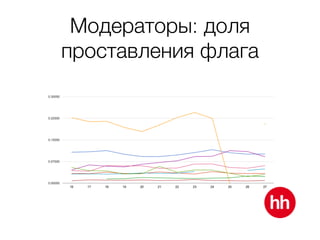






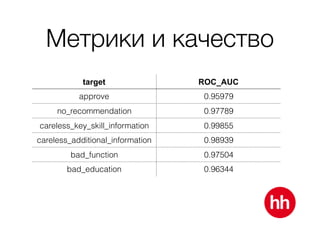
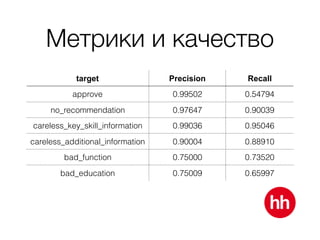



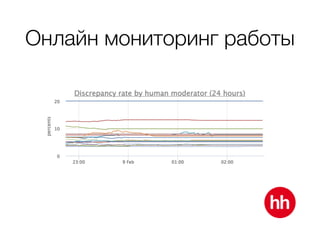
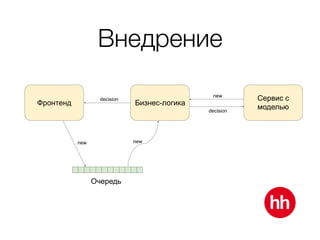





Документ обсуждает процесс модерации резюме на сайте hh.ru, включая детали работы модераторов и использование машинного обучения для улучшения процесса. В нем рассмотрены методы обучения модели на основе данных о подтвержденных, заблокированных и удаленных резюме, а также важные признаки, влияющие на классификацию. Также упоминаются проблемы внедрения и мониторинга качества работы алгоритма модерации.

































































