Download as KEY, PPTX




















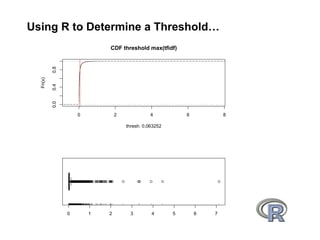
![Using R to Determine a Threshold…
data <- read.csv("thresh.tsv", sep='t', header=F)
t_data <- data[,3]
print(summary(t_data))
# pass through values for 80+ percentile
qntile <- .8
t_thresh <- quantile(t_data, qntile)
# CDF plot
title <- "CDF threshold max(tfidf)"
xtitle <- paste("thresh:", t_thresh)
par(mfrow=c(2, 1))
plot(ecdf(t_data), xlab=xtitle, main=title)
abline(v=t_thresh, col="red")
abline(h=qtile, col="yellow")
# box-and-whisker plot
boxplot(t_data, horizontal=TRUE)
rug(t_data, side=1)](https://image.slidesharecdn.com/enron-100719200921-phpapp01/85/Getting-Started-on-Hadoop-35-320.jpg)
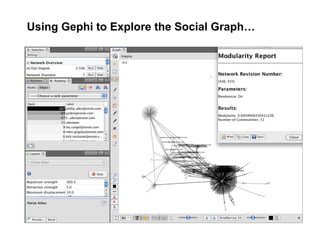






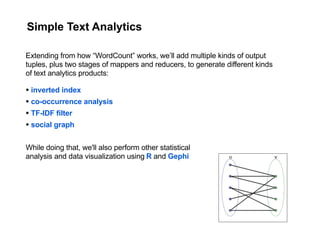
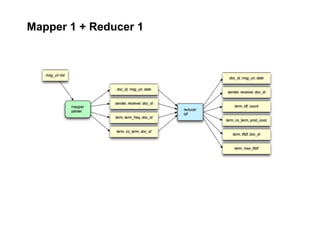
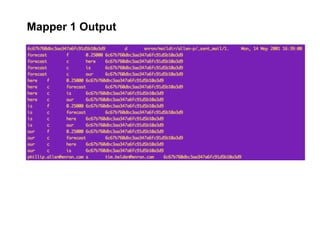
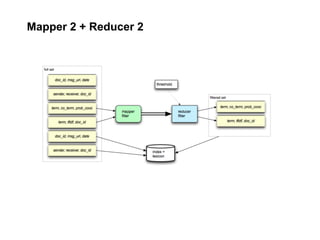
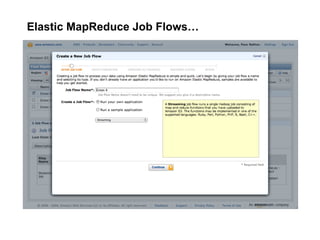
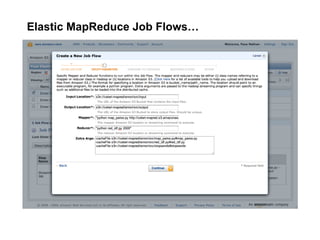
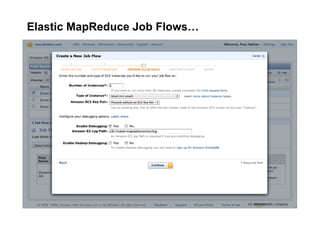
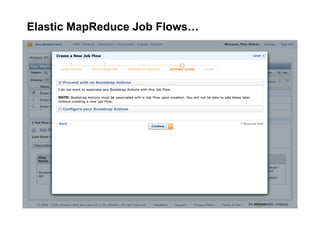
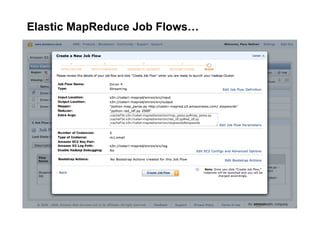
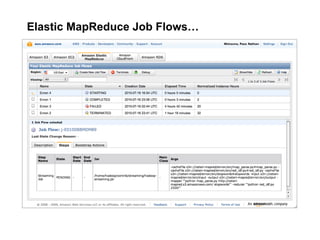
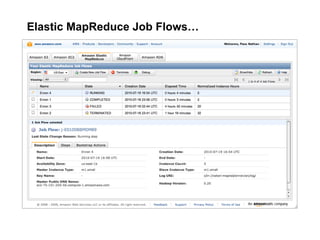
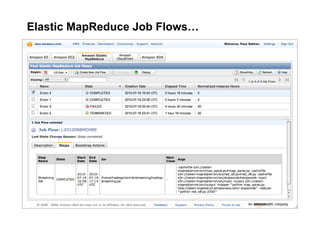
The document discusses a meetup focused on using Hadoop and AWS Elastic MapReduce for data processing, particularly illustrating the 'wordcount' example as a fundamental use case. It covers the architecture and workflow of MapReduce, including phases like mapping, shuffling, and reducing, as well as the significance of fault tolerance and scalability in cloud environments. Additionally, it highlights practical applications of text analytics using the Enron email dataset, showcasing techniques such as inverted index and social graph analysis.















![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























































































