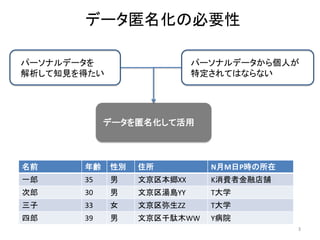
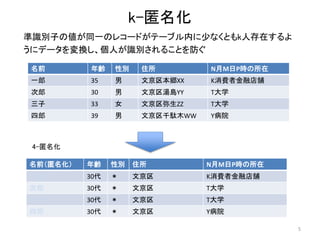
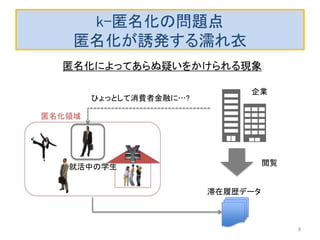
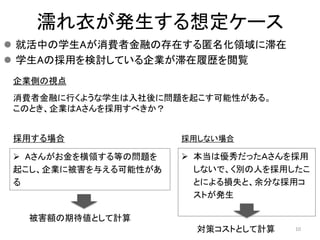
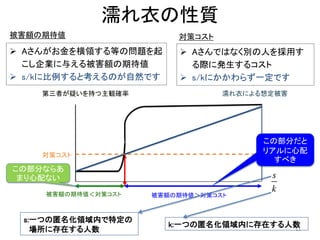
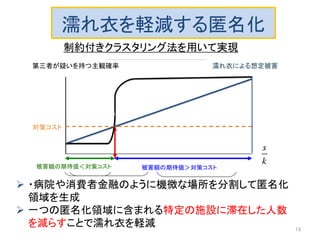
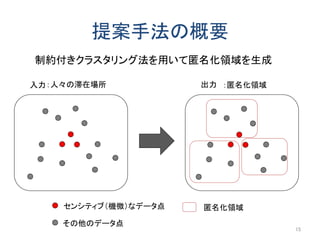
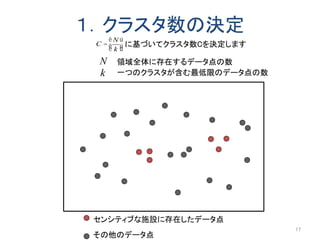
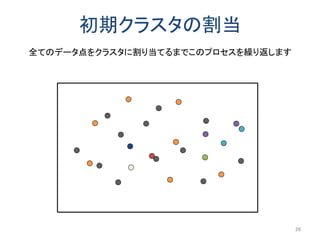
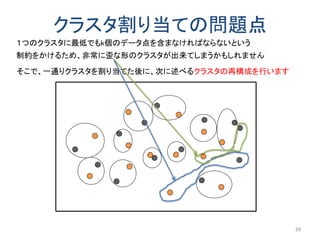
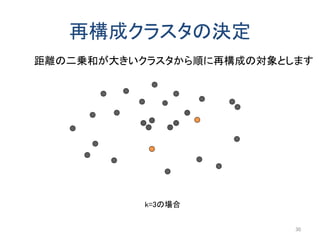
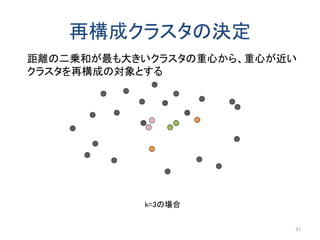
以前にアップロードした「k-匿名化と濡れ衣」で示した問題の解決編です。 内容は以下のようになります。 k-匿名化 テーブル形式のデータのk-匿名化 位置情報のk-匿名化 k-匿名化が誘発する濡れ衣 匿名化領域を工夫して濡れ衣を起こりにくくする方法 実験結果





















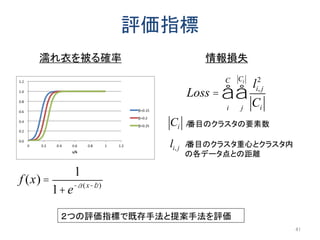
![評価基準:濡れ衣を被る確率
42
既存手法と比較して提案手法が濡れ衣を被る確率を
低減することを確認
Interval Cloak(IC)[Gruteser, MobiSys06],
Casper[Mok,VLDB06]](https://image.slidesharecdn.com/jsaisumino-140515102619-phpapp02/85/k-42-320.jpg)
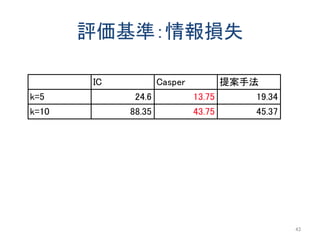


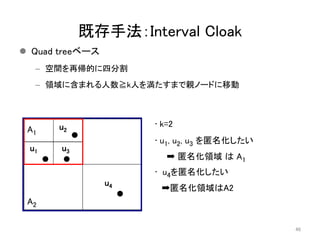
![既存手法:Casper[Mok06]
47
u1
u2
u3
u4
A1
A2
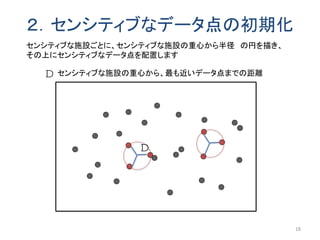
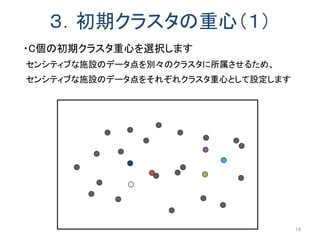
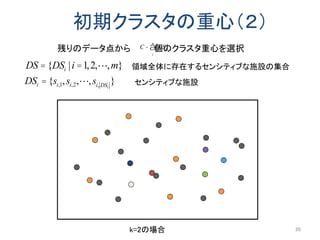
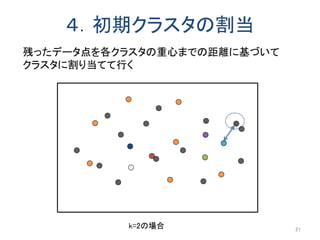
同じ階層のノードも探索するため匿名化領域のサイズが小さくなる
Interval Cloakの改良版](https://image.slidesharecdn.com/jsaisumino-140515102619-phpapp02/85/k-47-320.jpg)










![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)























































