Downloaded 136 times



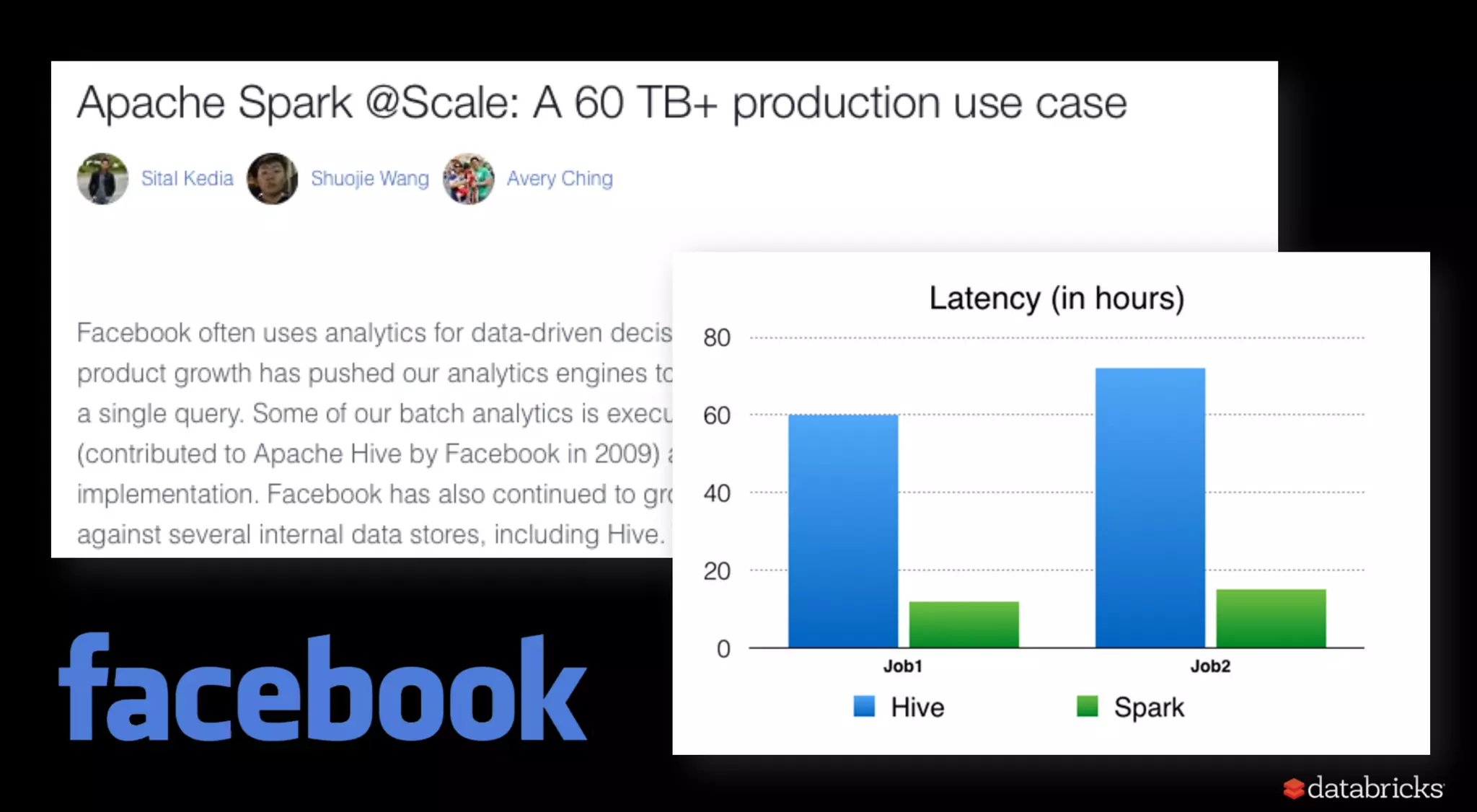



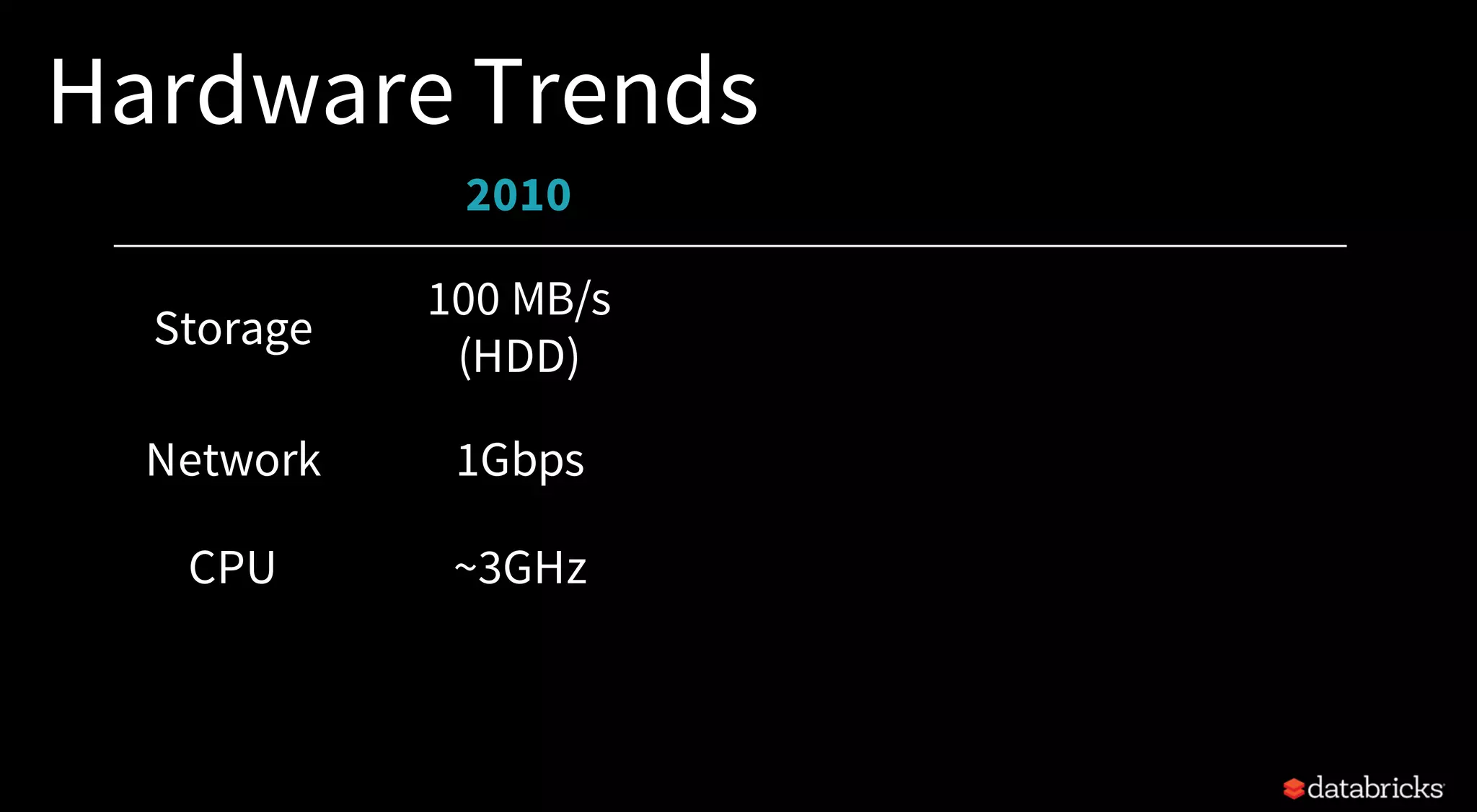
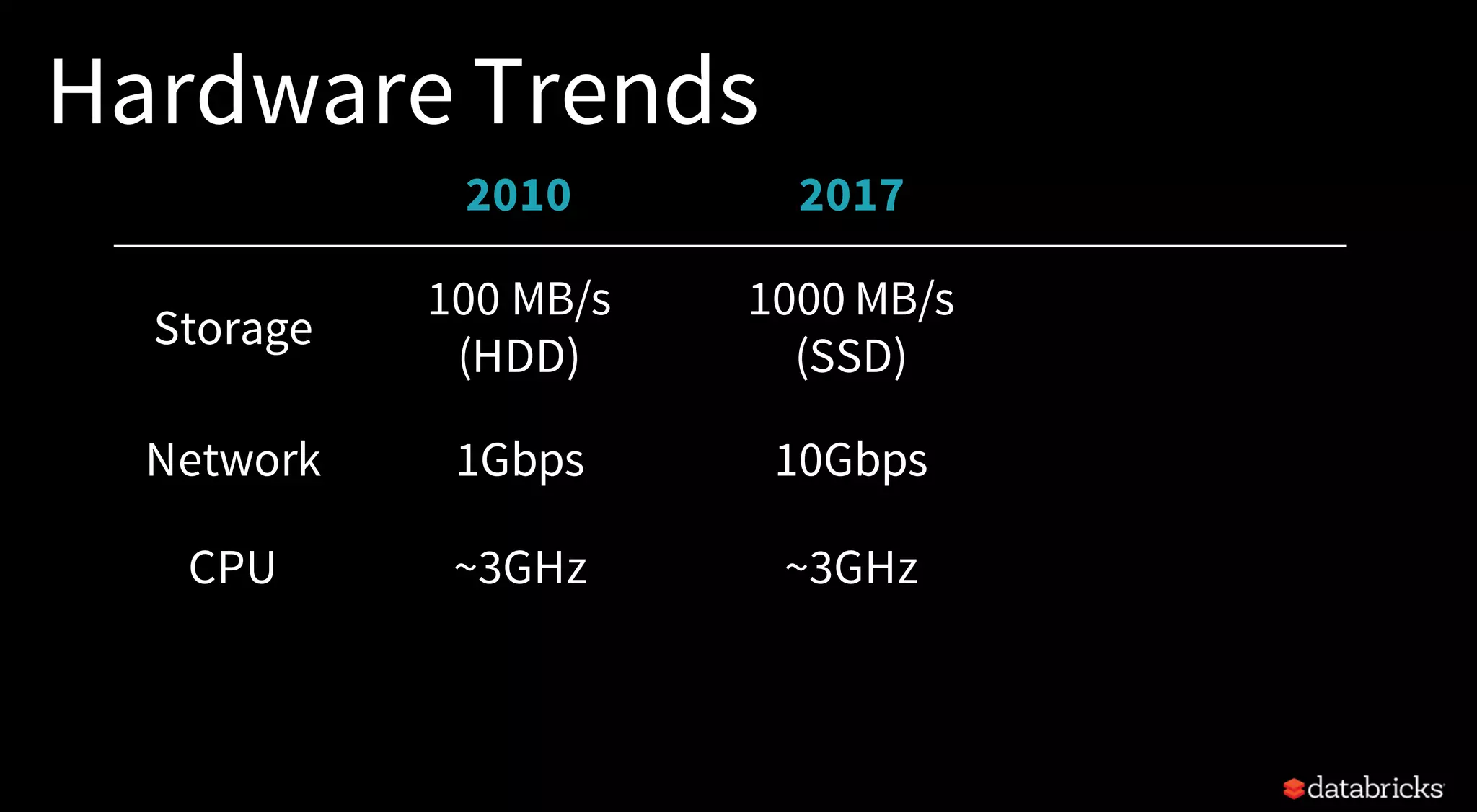
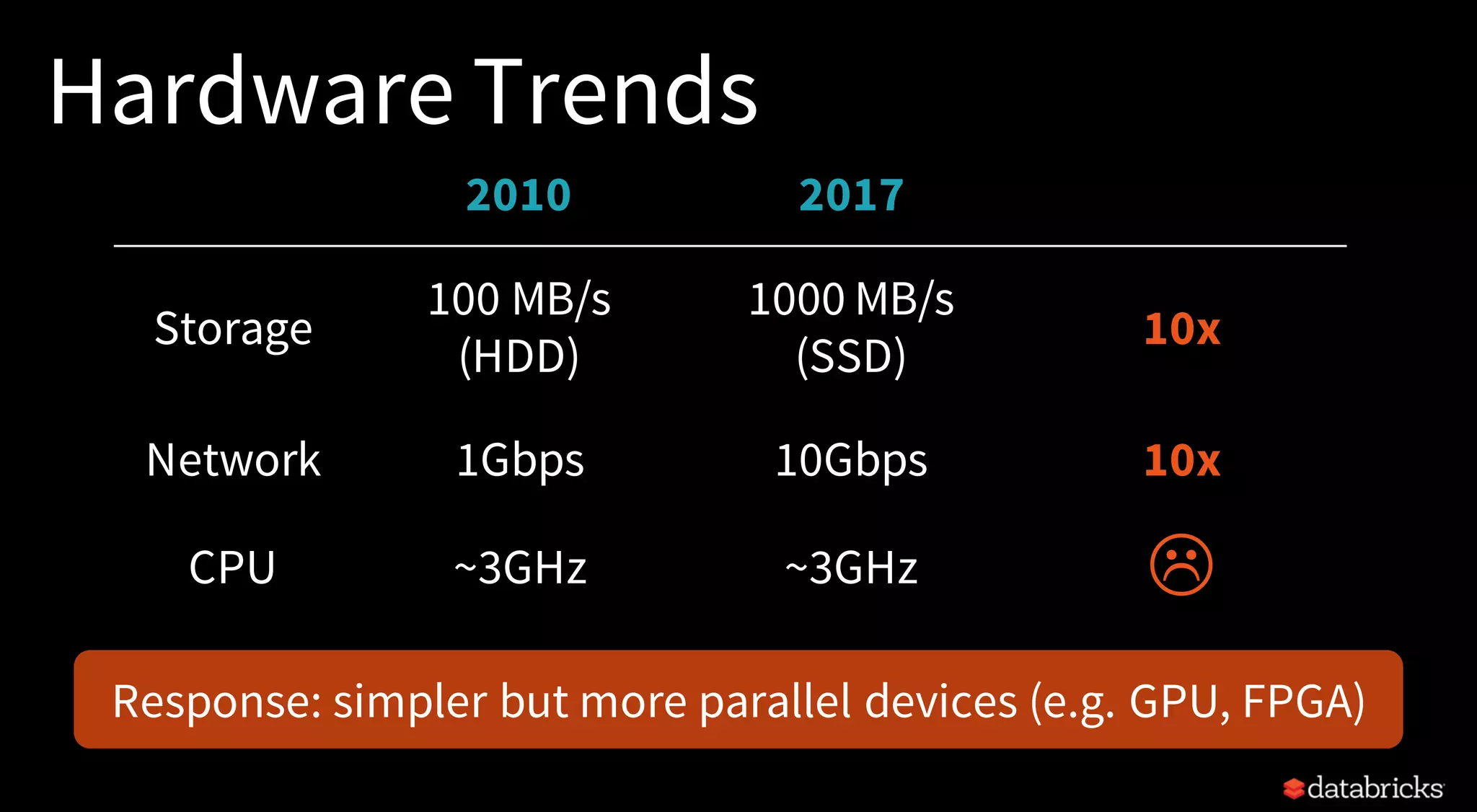


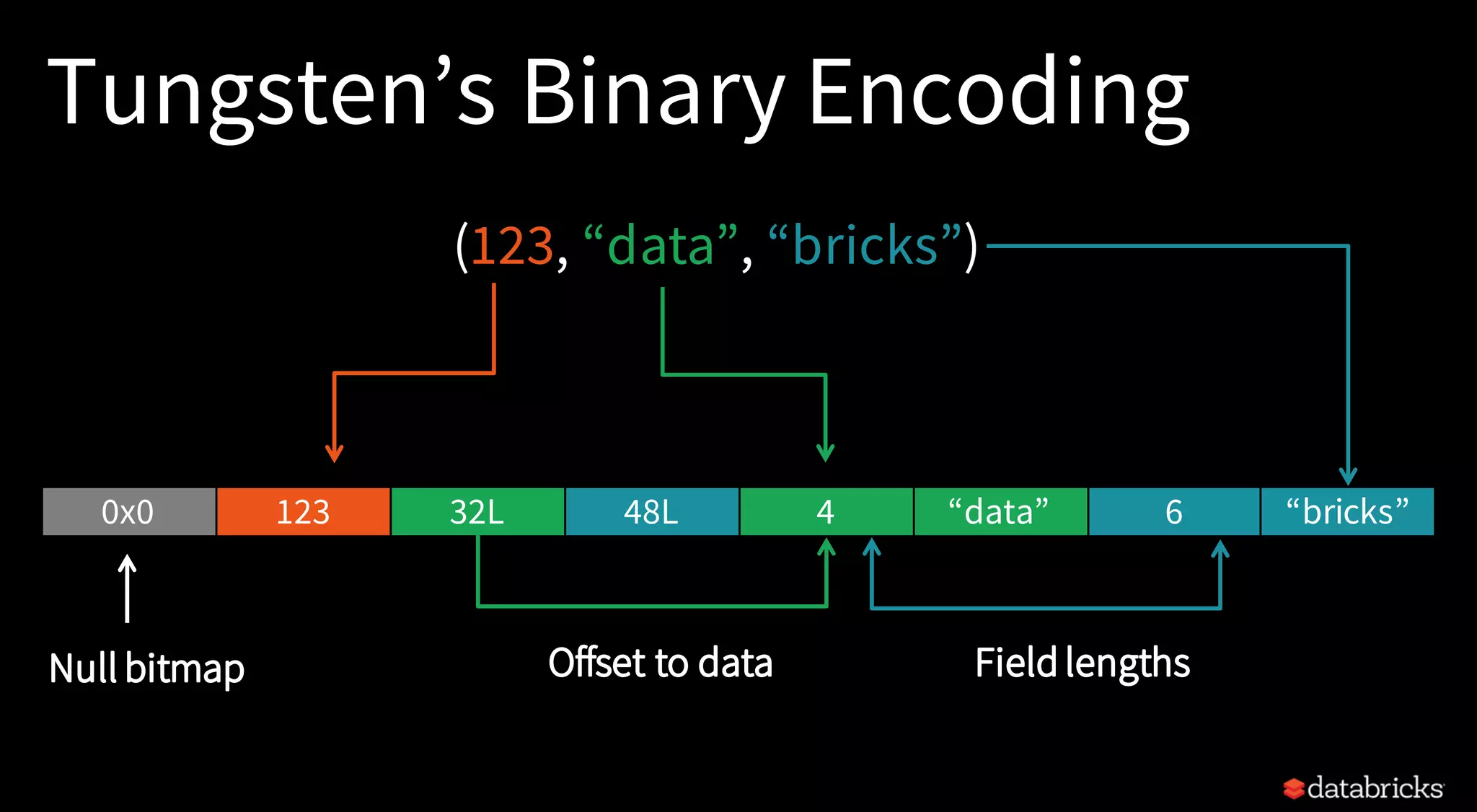








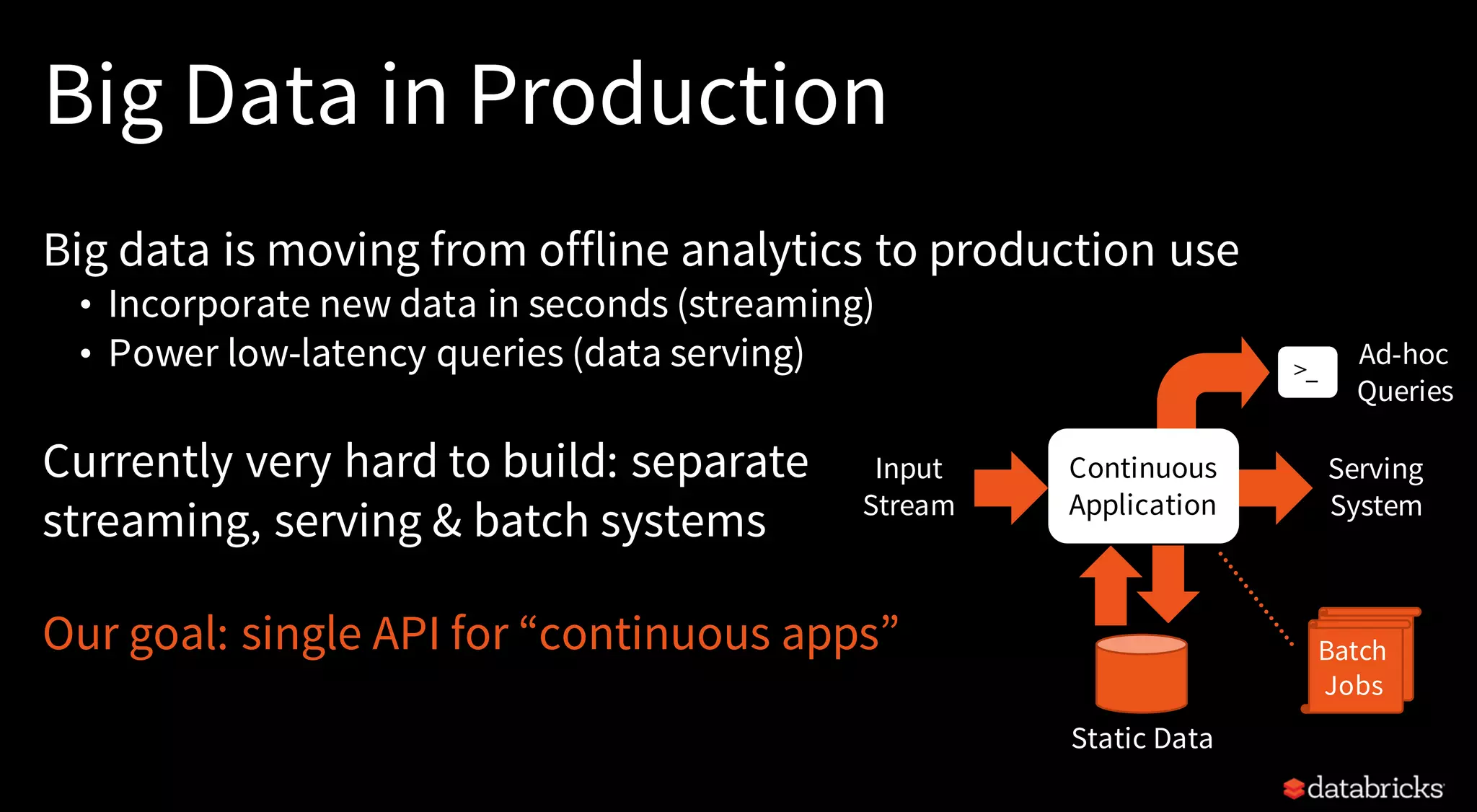








The document discusses trends for big data and Apache Spark in 2017, highlighting the stabilization of structured APIs, significant performance improvements, and the increased use of Spark in production applications. Key trends include addressing hardware bottlenecks, democratizing access to big data applications, and the integration of streaming and batch processing into a unified API for continuous applications. It also touches on ongoing developments to enhance Spark's performance, usability, and integration with other systems and technologies.
































































































