Downloaded 153 times




![7
IN THE NEED FOR THE PLATFORM
START
• Begin small and
focused
• Prove value
GROW
• Grow organically
as more use cases
arise
SCALE
• Go production and
scale to the revel
required
We are in the need of the truly elastic data platform, to avoid any upfront planning, deployment and
operations expenses, and put business value discovery first. The platform should support the [big]data
projects in any stage, without the need to reengineer the whole solution.
##SAISDev6](https://image.slidesharecdn.com/06andreivaranovich-181010204304/85/Lambda-Architecture-in-the-Cloud-with-Azure-Databricks-with-Andrei-Varanovich-7-320.jpg)
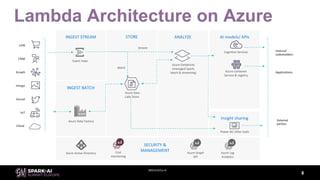
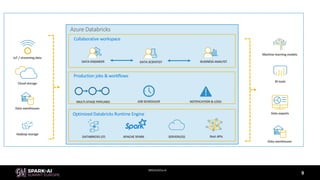





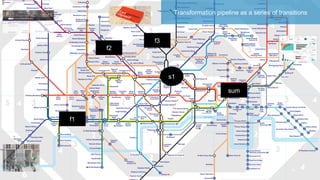





The document discusses the importance of using a lambda architecture on Azure Databricks for processing and analyzing large datasets efficiently. It emphasizes the need for an elastic data platform that supports various projects and scales as necessary without extensive reengineering. The document also highlights the advantages of standardizing on Apache Spark, utilizing PaaS offerings, and implementing data pipelines as function compositions for enhanced consistency and error detection.























































































