Downloaded 15 times












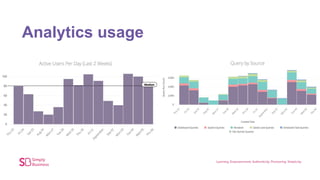


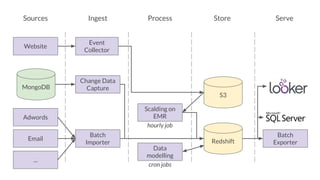

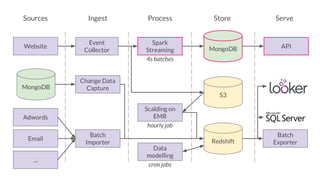

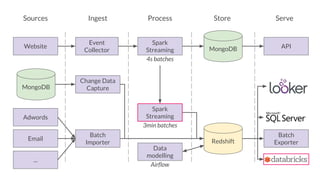



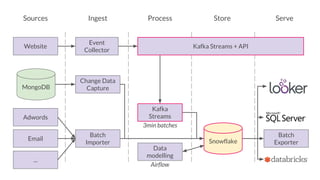



















The document outlines the evolution of Simply Business' data platform since its inception, highlighting its shift from batch processing to real-time data analysis and integration capabilities. It details the technological advancements made, including the use of tools like Kafka and Snowflake, and presents key projects such as lead scoring algorithms and customer behavior analysis. Additionally, the document discusses lessons learned in data management and provides insights into future trends in data analytics and machine learning.



























































