Downloaded 25 times


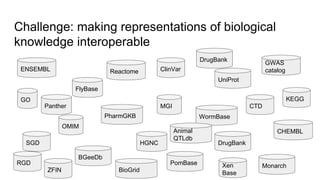




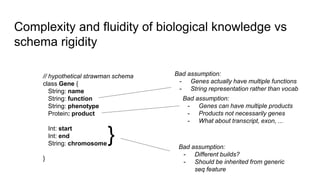

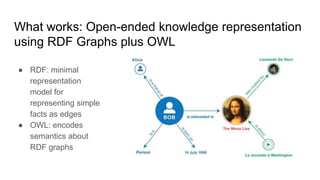
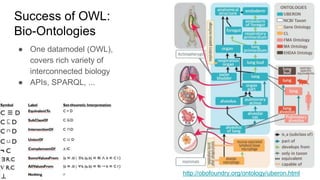
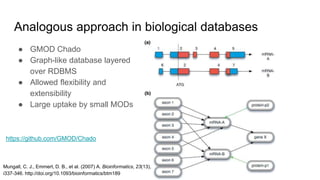
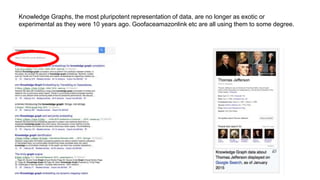




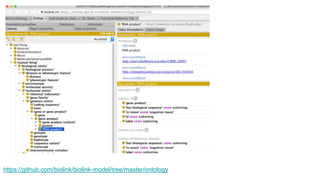
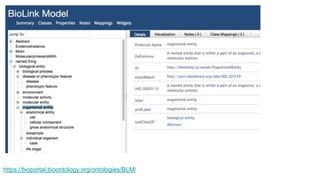
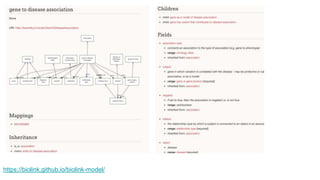
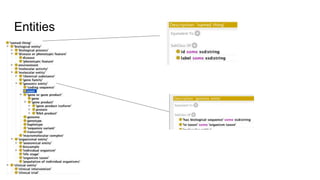






The document discusses the Biolink Model as a standardized schema for representing biological knowledge, addressing challenges of interoperability among various databases. It emphasizes the distinction between data and knowledge, advocates for extensibility in biological representation through RDF and OWL, and outlines the Biolink Model's approach to defining core biological types and relationships. Additionally, it notes the importance of flexibility in knowledge representation while maintaining necessary constraints for software systems.





































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)

















