Downloaded 11 times




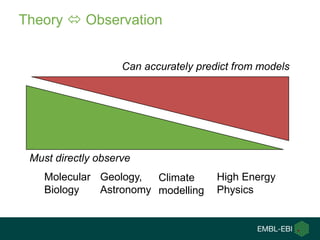
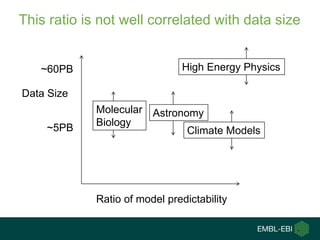



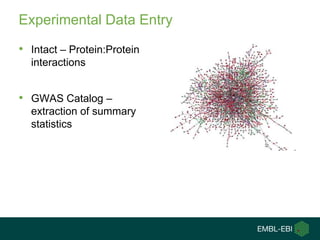
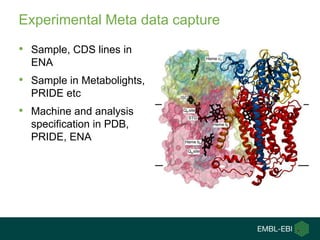
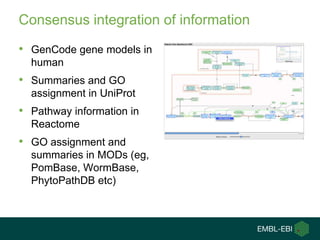
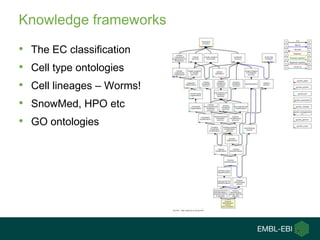

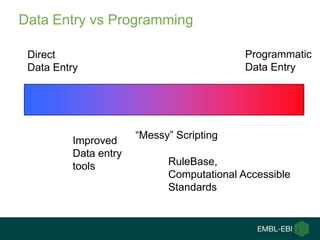








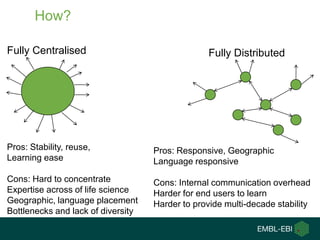



Ewan Birney summarizes the types of curation needed in molecular biology. There are five main types: experimental data entry, experimental metadata capture, consensus integration of information, knowledge frameworks, and knowledge management. Curation is critical for biology to integrate and organize the vast amounts of data being generated, but curation work is often overlooked despite its complexity. Large infrastructures are needed to support curation efforts and ensure biological data and knowledge can be reliably accessed and built upon over decades.













































































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)









