Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Keisuke Sugawara
PPTX, PDF
29,642 views
PRML第6章「カーネル法」
パターン認識と機械学習(PRML)の第6章「カーネル法」です 文字多め
Engineering
◦
Read more
42
Save
Share
Embed
Embed presentation
Download
Downloaded 282 times
1
/ 61
2
/ 61
3
/ 61
4
/ 61
5
/ 61
6
/ 61
7
/ 61
8
/ 61
9
/ 61
10
/ 61
11
/ 61
12
/ 61
13
/ 61
14
/ 61
15
/ 61
16
/ 61
17
/ 61
18
/ 61
19
/ 61
20
/ 61
21
/ 61
22
/ 61
23
/ 61
24
/ 61
25
/ 61
Most read
26
/ 61
27
/ 61
28
/ 61
29
/ 61
30
/ 61
31
/ 61
32
/ 61
33
/ 61
34
/ 61
Most read
35
/ 61
36
/ 61
37
/ 61
38
/ 61
Most read
39
/ 61
40
/ 61
41
/ 61
42
/ 61
43
/ 61
44
/ 61
45
/ 61
46
/ 61
47
/ 61
48
/ 61
49
/ 61
50
/ 61
51
/ 61
52
/ 61
53
/ 61
54
/ 61
55
/ 61
56
/ 61
57
/ 61
58
/ 61
59
/ 61
60
/ 61
61
/ 61
More Related Content
PDF
PRML輪読#6
by
matsuolab
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
PRML 第4章
by
Akira Miyazawa
PDF
PRML Chapter 14
by
Masahito Ohue
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PRML輪読#6
by
matsuolab
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PRML 第4章
by
Akira Miyazawa
PRML Chapter 14
by
Masahito Ohue
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
What's hot
PDF
PRML輪読#1
by
matsuolab
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
PRML輪読#4
by
matsuolab
PDF
パターン認識と機械学習 §6.2 カーネル関数の構成
by
Prunus 1350
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
PRML輪読#3
by
matsuolab
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
PRML輪読#2
by
matsuolab
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
PRML輪読#12
by
matsuolab
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
Prml 2.3
by
Yuuki Saitoh
PDF
PRML 1.6 情報理論
by
sleepy_yoshi
PDF
PRML輪読#10
by
matsuolab
PDF
PRML輪読#7
by
matsuolab
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式
by
Hiroshi Nakagawa
PDF
PRML輪読#8
by
matsuolab
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
PRML輪読#1
by
matsuolab
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PRML輪読#4
by
matsuolab
パターン認識と機械学習 §6.2 カーネル関数の構成
by
Prunus 1350
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PRML輪読#3
by
matsuolab
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PRML輪読#2
by
matsuolab
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PRML輪読#12
by
matsuolab
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
Prml 2.3
by
Yuuki Saitoh
PRML 1.6 情報理論
by
sleepy_yoshi
PRML輪読#10
by
matsuolab
PRML輪読#7
by
matsuolab
クラシックな機械学習入門:付録:よく使う線形代数の公式
by
Hiroshi Nakagawa
PRML輪読#8
by
matsuolab
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
Viewers also liked
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PPTX
Greed is Good: 劣モジュラ関数最大化とその発展
by
Yuichi Yoshida
PPTX
ニューラルチューリングマシン入門
by
naoto moriyama
PDF
Fisher Vectorによる画像認識
by
Takao Yamanaka
PDF
機械学習と深層学習の数理
by
Ryo Nakamura
PDF
深層リカレントニューラルネットワークを用いた日本語述語項構造解析
by
Hiroki Ouchi
PDF
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
PDF
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
PDF
人工知能のための哲学塾 東洋哲学篇 第零夜 資料
by
Youichiro Miyake
PDF
Decoupled Neural Interfaces輪読資料
by
Reiji Hatsugai
PDF
Duolingo.pptx
by
syou6162
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
Greed is Good: 劣モジュラ関数最大化とその発展
by
Yuichi Yoshida
ニューラルチューリングマシン入門
by
naoto moriyama
Fisher Vectorによる画像認識
by
Takao Yamanaka
機械学習と深層学習の数理
by
Ryo Nakamura
深層リカレントニューラルネットワークを用いた日本語述語項構造解析
by
Hiroki Ouchi
“確率的最適化”を読む前に知っておくといいかもしれない関数解析のこと
by
Hiroaki Kudo
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
人工知能のための哲学塾 東洋哲学篇 第零夜 資料
by
Youichiro Miyake
Decoupled Neural Interfaces輪読資料
by
Reiji Hatsugai
Duolingo.pptx
by
syou6162
Similar to PRML第6章「カーネル法」
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PDF
パターン認識と機械学習 13章 系列データ
by
emonosuke
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
PDF
Prml sec6
by
Keisuke OTAKI
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
Infomation geometry(overview)
by
Yoshitake Misaki
PDF
20170422 数学カフェ Part1
by
Kenta Oono
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
W8PRML5.1-5.3
by
Masahito Ohue
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PRML Chapter 5
by
Masahito Ohue
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
パターン認識と機械学習 13章 系列データ
by
emonosuke
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
Stanでガウス過程
by
Hiroshi Shimizu
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
Prml sec6
by
Keisuke OTAKI
PRML_from5.1to5.3.1
by
禎晃 山崎
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
Infomation geometry(overview)
by
Yoshitake Misaki
20170422 数学カフェ Part1
by
Kenta Oono
PRML第6章「カーネル法」
1.
パターン認識と機械学習 M1 菅原啓介 第6章 カーネル法 2015/6/29
1
2.
目次 • 6.1 双対表現 •
6.2 カーネル関数の構成 • 6.3 RBFネットワーク • 6.4 ガウス過程 2015/6/29 2
3.
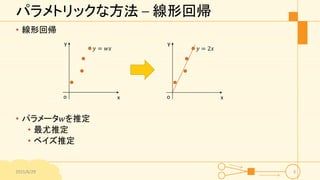
パラメトリックな方法 – 線形回帰 •
線形回帰 • パラメータ𝑤を推定 • 最尤推定 • ベイズ推定 2015/6/29 3 𝑦 = 𝑤𝑥 x y o 𝑦 = 2𝑥 x y o
4.
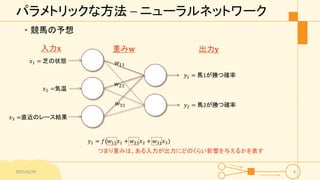
パラメトリックな方法 – ニューラルネットワーク •
競馬の予想 2015/6/29 4 𝑥1 = 芝の状態 𝑥2 =気温 𝑥3 =直近のレース結果 入力𝐱 重み𝐰 𝑤21 𝑤11 𝑤31 𝑦1 = 馬1が勝つ確率 𝑦2 = 馬2が勝つ確率 出力𝐲 𝑦1 = 𝑓(𝑤11 𝑥1 + 𝑤21 𝑥2 + 𝑤31 𝑥3) つまり重みは、ある入力が出力にどのくらい影響を与えるかを表す
5.
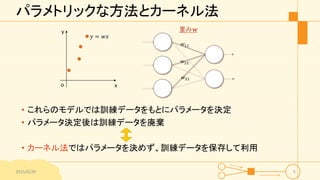
パラメトリックな方法とカーネル法 • これらのモデルでは訓練データをもとにパラメータを決定 • パラメータ決定後は訓練データを廃棄 •
カーネル法ではパラメータを決めず、訓練データを保存して利用 2015/6/29 5 𝑦 = 𝑤𝑥 x y o
6.
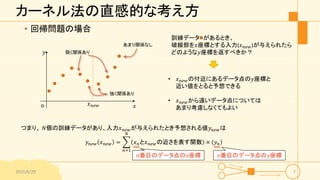
カーネル法の直感的な考え方 • 回帰問題の場合 2015/6/29 7 𝑥 𝑦 o 訓練データ
があるとき、 破線部を𝑥座標とする入力(𝑥 𝑛𝑒𝑤)が与えられたら どのような𝑦座標を返すべきか? • 𝑥 𝑛𝑒𝑤の付近にあるデータ点の𝑦座標と 近い値をとると予想できる • 𝑥 𝑛𝑒𝑤から遠いデータ点については あまり考慮しなくてもよい つまり、 𝑁個の訓練データがあり、入力𝑥 𝑛𝑒𝑤が与えられたとき予想される値𝑦 𝑛𝑒𝑤は 𝑦 𝑛𝑒𝑤 𝑥 𝑛𝑒𝑤 = 𝑛=1 𝑁 𝑥 𝑛と𝑥 𝑛𝑒𝑤の近さを表す関数 × 𝑦 𝑛 強く関係あり あまり関係なし 弱く関係あり 𝑥 𝑛𝑒𝑤 𝑛番目のデータ点の𝑥座標 𝑛番目のデータ点の𝑦座標
7.
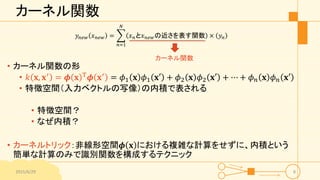
カーネル関数 𝑦𝑛𝑒𝑤 𝑥 𝑛𝑒𝑤
= 𝑛=1 𝑁 𝑥 𝑛と𝑥 𝑛𝑒𝑤の近さを表す関数 × 𝑦𝑛 • カーネル関数の形 • 𝑘 𝐱, 𝐱′ = 𝝓 𝐱 T 𝝓 𝐱′ = 𝜙1 𝐱 𝜙1 𝐱′ + 𝜙2 𝐱 𝜙2 𝐱′ + ⋯ + 𝜙 𝑛 𝐱 𝜙 𝑛 𝐱′ • 特徴空間(入力ベクトルの写像)の内積で表される • 特徴空間? • なぜ内積? • カーネルトリック:非線形空間𝝓 𝐱 における複雑な計算をせずに、内積という 簡単な計算のみで識別関数を構成するテクニック 2015/6/29 8 カーネル関数
8.
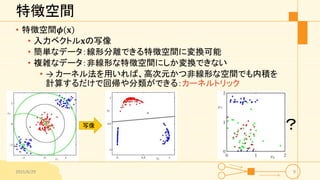
特徴空間 • 特徴空間𝝓 𝐱 •
入力ベクトル𝐱の写像 • 簡単なデータ:線形分離できる特徴空間に変換可能 • 複雑なデータ:非線形な特徴空間にしか変換できない • → カーネル法を用いれば、高次元かつ非線形な空間でも内積を 計算するだけで回帰や分類ができる:カーネルトリック 2015/6/29 9 写像 ?
9.
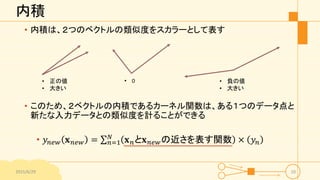
内積 • 内積は、2つのベクトルの類似度をスカラーとして表す • このため、2ベクトルの内積であるカーネル関数は、ある1つのデータ点と 新たな入力データとの類似度を計ることができる •
𝑦𝑛𝑒𝑤 𝐱 𝑛𝑒𝑤 = 𝑛=1 𝑁 𝐱 𝑛と𝐱 𝑛𝑒𝑤の近さを表す関数 × 𝑦𝑛 2015/6/29 10 • 正の値 • 大きい • 0 • 負の値 • 大きい
10.
6.1 双対表現 p.2 ~ 2015/6/29
11
11.
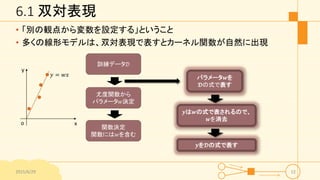
6.1 双対表現 • 「別の観点から変数を設定する」ということ •
多くの線形モデルは、双対表現で表すとカーネル関数が自然に出現 2015/6/29 12 訓練データ𝒟 尤度関数から パラメータ𝑤決定 𝑦 = 𝑤𝑥 x y o 関数決定 関数には𝑤を含む パラメータ𝒘を 𝓓の式で表す 𝒚は𝒘の式で表されるので、 𝒘を消去 𝒚を𝓓の式で表す
12.
双対表現の計算(1) • 目標:線形モデルを双対表現で表すとカーネル関数が現れるのを確認 • データ点𝒟
= 𝑥1, 𝑡1 , … , 𝑥 𝑁, 𝑡 𝑁 • 二乗和誤差関数 𝐽 𝐰 = 1 2 𝑛=1 𝑁 𝐰 𝑇 𝝓 𝐱 𝑛 − 𝑡 𝑛 2 + 𝜆𝐰 𝑇 𝐰 • 𝐽 𝐰 の𝐰についての勾配を0とおくと、 • 𝐰 = − 1 𝜆 𝑛=1 𝑁 𝐰 𝑇 𝝓 𝐱 𝑛 − 𝑡 𝑛 𝝓 𝐱 𝑛 = 𝑛=1 𝑁 𝑎 𝑛 𝝓 𝐱 𝑛 = 𝚽T 𝐚 • ベクトル関数𝝓 𝐱 𝑛 の線形結合の形 • 𝚽は,n番目の行が𝝓 𝐱 𝑛 𝑇 で与えられる計画行列 • また、𝑎 𝑛 = − 1 𝜆 𝐰 𝑇 𝝓 𝐱 𝑛 − 𝑡 𝑛 2015/6/29 13 パラメータ𝐰を直接扱う代わりに、 𝐚で表現しなおすこと:双対表現 𝝓 𝐱0 T 𝝓 𝐱1 T 𝝓 𝐱 𝑁 T 𝚽 = ⋮
13.
双対表現の計算(2) • 𝐰 =
𝚽T 𝐚 を𝐽 𝐰 に代入 • 𝐽 𝐚 = 1 2 𝐚T 𝚽𝚽T 𝚽𝚽T 𝐚 − 𝐚T 𝚽𝚽T 𝐭 + 1 2 𝐭T 𝐭 + 𝜆 𝟐 𝐚T 𝚽𝚽T 𝐚 • ただし𝐭 = 𝑡1, … , 𝑡 𝑁 𝑇 • 𝑁 × 𝑁の対象行列であるグラム行列𝐊 = 𝚽𝚽 𝑇 を定義する • 𝐾 𝑚𝑛 = 𝝓 𝐱 𝑛 𝑇 𝝓 𝐱 𝑚 = 𝑘 𝐱 𝑛, 𝐱 𝑚 • 𝐽 𝐚 = 1 2 𝐚T 𝐊𝐊𝐚 − 𝐚T 𝐊𝐭 + 1 2 𝐭T 𝐭 + 𝜆 𝟐 𝐚T 𝐊𝐚 2015/6/29 14 カーネル関数
14.
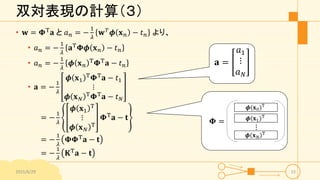
双対表現の計算(3) • 𝐰 =
𝚽T 𝐚 と 𝑎 𝑛 = − 1 𝜆 𝐰 𝑇 𝝓 𝐱 𝑛 − 𝑡 𝑛 より、 • 𝑎 𝑛 = − 1 𝜆 𝐚T 𝚽𝝓 𝐱 𝑛 − 𝑡 𝑛 • 𝑎 𝑛 = − 1 𝜆 𝝓 𝐱 𝑛 T 𝚽T 𝐚 − 𝑡 𝑛 • 𝐚 = − 1 𝜆 𝝓 𝐱1 T 𝚽T 𝐚 − 𝑡1 ⋮ 𝝓 𝐱 𝑁 T 𝚽T 𝐚 − 𝑡 𝑁 = − 1 𝜆 𝝓 𝐱1 T ⋮ 𝝓 𝐱 𝑁 T 𝚽T 𝐚 − 𝐭 = − 1 𝜆 𝚽𝚽T 𝐚 − 𝐭 = − 1 𝜆 𝐊T 𝐚 − 𝐭 2015/6/29 15 𝐚 = 𝑎1 ⋮ 𝑎 𝑁
15.
双対表現の計算(4) • 前ページ 𝐚
= − 1 𝜆 𝐊T 𝐚 − 𝐭 より • 𝐚 = 𝐊 + 𝛌𝐈 𝑁 −1 𝒕 • これを線形回帰モデルに代入しなおすと、入力に対する予測は • 𝑦 𝐱 = 𝐰T 𝝓 𝐱 = 𝐚T 𝚽𝝓 𝐱 = 𝐤 𝐱 T 𝐊 + 𝜆𝐈 𝑁 −1 𝐭 • 𝐤 𝐱 は要素𝑘 𝑛 𝑥 = 𝑘 𝐱 𝑛, 𝐱 • 線形回帰モデルをカーネル関数により表せる • 目標値𝐭の線形結合で表せる 2015/6/29 16
16.
6.2 カーネル関数の構成 p.4 ~ 2015/6/29
17
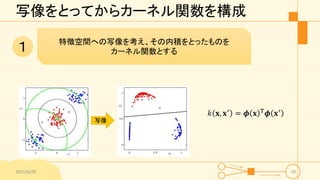
17.
カーネル関数の構成 • カーネル関数を作る方法 2015/6/29 18 特徴空間への写像を考え、その内積をとったものを カーネル関数とする カーネル関数を直接定義する (カーネル関数として有効であることを保障する必要あり) 1 2
18.
写像をとってからカーネル関数を構成 2015/6/29 19 特徴空間への写像を考え、その内積をとったものを カーネル関数とする1 写像 𝑘 𝐱,
𝐱′ = 𝝓 𝐱 T 𝝓 𝐱′
19.
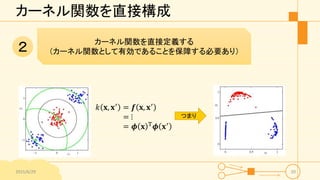
カーネル関数を直接構成 2015/6/29 20 カーネル関数を直接定義する (カーネル関数として有効であることを保障する必要あり)2 つまり 𝑘 𝐱,
𝐱′ = 𝒇 𝐱, 𝐱′ = ⋮ = 𝝓 𝐱 T 𝝓 𝐱′
20.
カーネル関数の直接定義 例 • 次のカーネル関数を考える •
𝑘 𝐱, 𝐳 = 𝐱T 𝐳 2 • 2次元の入力空間𝐱 = 𝑥1, 𝑥2 を考え、展開していくと • 𝑘 𝐱, 𝐳 = 𝑥1 𝑧1 + 𝑥2 𝑧2 2 = 𝑥1 2 𝑧1 2 + 2𝑥1 𝑧1 𝑥2 𝑧2 + 𝑥2 2 𝑧2 2 = 𝑥1 2 , 2𝑥1 𝑥2, 𝑥2 2 𝑧1 2 , 2𝑧1 𝑧2, 𝑧2 2 𝑇 = 𝝓 𝐱 𝑇 𝝓 𝐳 • 特徴空間への写像は𝝓 𝐱 = 𝑥1 2 , 2𝑥1 𝑥2, 𝑥2 2 の形をもつことがわかる • 特徴ベクトルの内積で表されたので、有効なカーネル関数と考えられる 2015/6/29 21
21.
有効なカーネルであるための条件 • 前ページでは、特徴ベクトルの内積の形に変形することで有効性を示した • 特徴ベクトルを明示的に構成するのが難しい場合も •
関数𝑘 𝐱, 𝐱′ が有効なカーネル関数であるための必要十分条件は 2015/6/29 22 任意の 𝐱 𝑛 に対して、要素が𝑘 𝐱 𝑛, 𝐱 𝑚 で与えられるグラム行列𝐊が 半正定値であること 𝑛次元の任意のベクトル𝐲に対して 𝐲T 𝐊𝐲 ≥ 0 が成り立つこと
22.
新たなカーネルを構築する方法 • 𝑘1 𝐱,
𝐱′ , 𝑘2 𝐱, 𝐱′ が有効なカーネルであるとき、以下のカーネルも有効 • 𝑘 𝐱, 𝐱′ = 𝑐𝑘1 𝐱, 𝐱′ • 𝑘 𝐱, 𝐱′ = 𝑓 𝐱 𝑘1 𝐱, 𝐱′ 𝑓 𝐱′ • 𝑘 𝐱, 𝐱′ = 𝑞 𝑘1 𝐱, 𝐱′ • 𝑘 𝐱, 𝐱′ = exp 𝑘1 𝐱, 𝐱′ • 𝑘 𝐱, 𝐱′ = 𝑘1 𝐱, 𝐱′ + 𝑘2 𝐱, 𝐱′ • 𝑘 𝐱, 𝐱′ = 𝑘3 𝝓 𝐱 , 𝝓 𝐱′ • 𝑘 𝐱, 𝐱′ = 𝐱T 𝐀𝐱′ • 𝑘 𝐱, 𝐱′ = 𝑘 𝑎 𝐱 𝑎, 𝐱 𝑏 ′ + 𝑘 𝑏 𝐱 𝑎, 𝐱 𝑏 ′ • 𝑘 𝐱, 𝐱′ = 𝑘 𝑎 𝐱 𝑎, 𝐱 𝑏 ′ 𝑘 𝑏 𝐱 𝑎, 𝐱 𝑏 ′ 2015/6/29 23
23.
カーネル関数の種類 • 単純な多項式カーネル𝑘 𝐱,
𝐱′ = 𝐱T 𝐱′ 2 • ↑のカーネルを少し一般化すると𝑘 𝐱, 𝐱′ = 𝐱T 𝐱′ + 𝑐 2 • 写像𝝓 𝐱 が、定数の項と1次の項ももつ • 例: 𝐱 = 𝑥1, 𝑥2 , 𝐳 = 𝑧1, 𝑧2 とすると • 𝑘 𝐱, 𝒛 = 𝑥1 𝑧1 + 𝑥2 𝑧2 + 𝑐 2 = 𝑥1 2 𝑧1 2 + 2𝑥1 𝑧1 𝑥2 𝑧2 + 𝑥2 2 𝑧2 2 + 2𝑐𝑥1 𝑦1 + 2𝑐𝑥2 𝑦2 + 𝑐2 = 𝑥1 2 , 2𝑥1 𝑥2, 𝑥2 2 , 2𝑐𝑥1, 2𝑐𝑥2, 𝑐 𝑦1 2 , 2𝑦1 𝑦2, 𝑦2 2 , 2𝑐𝑦1, 2𝑐𝑦2, 𝑐 T • つまり写像は𝝓 𝐱 = 𝑥1 2 , 2𝑥1 𝑥2, 𝑥2 2 , 2𝑐𝑥1, 2𝑐𝑥2, 𝑐 2015/6/29 24
24.
さまざまなカーネル関数 • 𝑘 𝐱,
𝐱′ = 𝐱T 𝐱′ 𝑀 • 𝑘 𝐱, 𝐱′ = 𝐱T 𝐱′ + 𝑐 𝑀 • 𝑘 𝐱, 𝐱′ = exp − 𝐱−𝐱′ 2 2𝜎2 ・・・ ガウスカーネル(無限個の基底関数) • カーネル法は、実数値ベクトルの入力だけではなく記号などにも対応 • グラフ、集合、文字列など 2015/6/29 25
25.
生成モデル・識別モデルとカーネル関数 • 生成モデル:欠損データを自然に扱える • 識別モデル:分類問題においては生成モデルより高性能 2015/6/29
26 生成モデルを用いてカーネルを定義し、 そのカーネルを用いて識別 組み合わせ
26.
生成モデルを用いたカーネル関数の定義 • 生成モデル𝑝 𝐱
が与えられたとき • 𝑘 𝐱, 𝐱′ = 𝑝 𝐱 𝑝 𝐱 ′ • 写像𝑝 𝐱 で定義された1次元の特徴空間における内積 • 重み係数𝑝 𝑖 を用いて以下のように拡張可能 • 𝑘 𝐱, 𝐱′ = 𝑖 𝑝 𝐱|𝑖 𝑝 𝐱′ |𝑖 𝑝 𝑖 • 𝑝 𝐱|𝑖 は𝑖という条件のもとでの条件付確率 • 条件𝑖は潜在変数と解釈できる(9.2節) • データが長さ𝐿の配列の場合(𝐗 = 𝐱1, … 𝐱 𝐿 ) • 隠れマルコフモデル(13.2節) • 𝑘 𝐗, 𝐗′ = 𝐙 𝑝 𝐗|𝐙 𝑝 𝐗′ |𝐙 𝑝 𝐙 2015/6/29 27
27.
フィッシャーカーネル(1) • パラメトリックな生成モデル𝑝 𝐱|𝜽 •
目的:生成モデルから、2つの入力ベクトル𝐱, 𝐱′の類似度を測るカーネル を見つけること • フィッシャースコア • 𝐠 𝜽, 𝐱 = 𝛻𝜽 ln 𝑝 𝐱|𝜽 • フィッシャーカーネル • 𝑘 𝐱, 𝐱′ = 𝐠 𝜽, 𝐱 T 𝐅−1 𝐠 𝜽, 𝐱′ • ただしはフィッシャー情報量行列 • 𝐅 = 𝔼 𝐱 𝐠 𝜽, 𝐱 𝐠 𝜽, 𝐱 T 2015/6/29 29
28.
フィッシャーカーネル(2) • フィッシャー情報量行列の計算は不可能なため、期待値を単純平均で 置き換える • 𝐅
≅ 1 𝑁 𝑛=1 𝑁 𝐠 𝜽, 𝐱 𝑛 𝐠 𝜽, 𝐱 𝑛 T • さらに簡単に、次のように定義することもある • 𝑘 𝐱, 𝐱′ = 𝐠 𝜽, 𝐱 T 𝐠 𝜽, 𝐱′ • 解釈: 𝜽を変化させる(=複数の生成モデルを考える)ことで、 さまざまなカーネル関数を得られる 2015/6/29 30
29.
6.3 RBFネットワーク p.10 ~ 2015/6/29
31
30.
RBFネットワーク • RBF :
動径基底関数(radial basis function) • 基底関数𝜙 𝐱 が、その中心からの動径のみに依存する • 𝜙 𝐱 = ℎ 𝐱 − 𝝁 𝑗 • 入力変数にノイズが含まれるモデルにも対応 • 入力変数に含まれるノイズが確率分布𝜈 𝝃 に従う確率変数𝝃で 表されるとき、二乗和誤差関数は • 𝐸 = 1 2 𝑛=1 𝑁 𝑦 𝐱 𝑛 + 𝝃 − 𝑡 𝑛 2 𝜈 𝝃 d𝝃 2015/6/29 32
31.
RBFの導出 • 𝐸 = 1 2
𝑛=1 𝑁 𝑦 𝐱 𝑛 + 𝝃 − 𝑡 𝑛 2 𝜈 𝝃 d𝝃 • 変分法により𝑦 𝐱 についての最適化を行うと • 𝑦 𝐱 = 𝑛=1 𝑁 𝑡 𝑛ℎ 𝐱 − 𝐱 𝑛 • RBFは以下の通り • ℎ 𝐱 − 𝐱 𝑛 = 𝜈 𝐱−𝐱 𝑛 𝑛=1 𝑁 𝜈 𝐱−𝐱 𝑛 • 基底関数は正規化されている • 𝑛=1 ℎ 𝐱 − 𝐱 𝑛 = 1 2015/6/29 33
32.
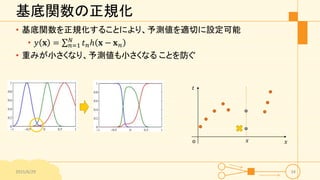
基底関数の正規化 • 基底関数を正規化することにより、予測値を適切に設定可能 • 𝑦
𝐱 = 𝑛=1 𝑁 𝑡 𝑛ℎ 𝐱 − 𝐱 𝑛 • 重みが小さくなり、予測値も小さくなる ことを防ぐ 2015/6/29 34 𝑥 𝑡 o 𝑥
33.
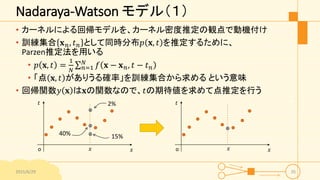
Nadaraya-Watson モデル(1) • カーネルによる回帰モデルを、カーネル密度推定の観点で動機付け •
訓練集合 𝐱 𝑛, 𝑡 𝑛 として同時分布𝑝 𝐱, 𝑡 を推定するために、 Parzen推定法を用いる • 𝑝 𝐱, 𝑡 = 1 𝑁 𝑛=1 𝑁 𝑓 𝐱 − 𝐱 𝑛, 𝑡 − 𝑡 𝑛 • 「点 𝐱, 𝑡 がありうる確率」を訓練集合から求める という意味 • 回帰関数𝑦 𝐱 は𝐱の関数なので、𝑡の期待値を求めて点推定を行う 2015/6/29 35 𝑥 𝑡 o 𝑥𝑥 𝑡 o 𝑥 2% 15%40%
34.
Nadaraya-Watson モデル(2) 𝑦 𝐱
= 𝔼 𝑡|𝐱 = −∞ ∞ 𝑡𝑝 𝑡|𝐱 d𝑡 = 𝑡𝑝 𝐱, 𝑡 d𝑡 𝑝 𝐱, 𝑡 d𝑡 = 𝑛 𝑡𝑓 𝐱 − 𝐱 𝑛, 𝑡 − 𝑡 𝑛 d𝑡 𝑚 𝑓 𝐱 − 𝐱 𝑛, 𝑡 − 𝑡 𝑛 d𝑡 簡単のため、𝑓 𝐱, 𝑡 についての平均は0であるとする。つまり −∞ ∞ 𝑓 𝐱, 𝑡 𝑡d𝑡 = 0 2015/6/29 36
35.
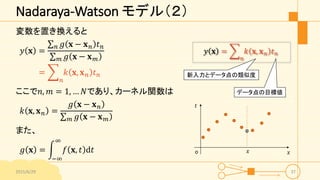
Nadaraya-Watson モデル(2) 変数を置き換えると 𝑦 𝐱
= 𝑛 𝑔 𝐱 − 𝐱 𝑛 𝑡 𝑛 𝑚 𝑔 𝐱 − 𝐱 𝑚 = 𝑛 𝑘 𝐱, 𝐱 𝑛 𝑡 𝑛 ここで𝑛, 𝑚 = 1, … 𝑁であり、カーネル関数は 𝑘 𝐱, 𝐱 𝑛 = 𝑔 𝐱 − 𝐱 𝑛 𝑚 𝑔 𝐱 − 𝐱 𝑚 また、 𝑔 𝐱 = −∞ ∞ 𝑓 𝐱, 𝑡 d𝑡 2015/6/29 37 𝑥 𝑡 o 𝑥 𝑦 𝐱 = 𝑛 𝑘 𝐱, 𝐱 𝑛 𝑡 𝑛 新入力とデータ点の類似度 データ点の目標値
36.
6.4 ガウス過程 p.14 ~ 2015/6/29
38
37.
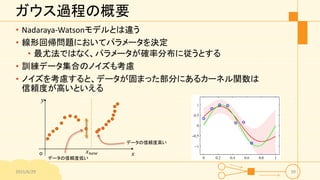
ガウス過程の概要 • Nadaraya-Watsonモデルとは違う • 線形回帰問題においてパラメータを決定 •
最尤法ではなく、パラメータが確率分布に従うとする • 訓練データ集合のノイズも考慮 • ノイズを考慮すると、データが固まった部分にあるカーネル関数は 信頼度が高いといえる 2015/6/29 39 𝑥 𝑦 o データの信頼度高い データの信頼度低い 𝑥 𝑛𝑒𝑤
38.
線形回帰再訪 • M個の固定された基底関数の線形結合で表されるモデルを考える • 𝑦
𝐱 = 𝐰 𝑇 𝝓 𝐱 • 𝐰の事前分布として等方的なガウス分布を考える • 𝑝 𝐰 = 𝒩 𝐰|0, 𝛼−1 𝐈 • 𝐰の確率分布を求めることにより、𝑦 𝐱 の確率分布を導くことになる 2015/6/29 40 これが目的
39.
ガウス過程 • 一般に、ある変数や関数 𝑋𝑡
𝑡∈𝑇によるベクトル𝐗 = 𝑋𝑡1 , … 𝑋𝑡 𝑘 T が ガウス分布に従うとき、 𝐗をガウス過程という • 線形回帰関数の値を要素とするベクトルを𝐲と表す。要素は • 𝑦𝑛 = 𝑦 𝐱 𝑛 = 𝐰 𝑇 𝝓 𝐱 𝑛 • 𝐲 = 𝑦1, 𝑦2, … 𝑦 𝑁 • 線形回帰問題の場合では、 • 𝐰がガウス分布に従う • 𝑦 𝐱 もガウス分布に従う • 𝐲もガウス分布に従う • つまり、 𝐲はガウス過程 2015/6/29 41
40.
ガウス過程のポイント • 𝐲がガウス過程であることのメリット • 平均と共分散を求めれば十分 •
平均 • 𝔼 𝐲 = 𝚽𝔼 𝐰 = 0 • 共分散 • cov 𝐲 = 𝔼 𝐲𝐲 𝑇 = 𝚽𝔼 𝐰𝐰 𝑇 𝚽T = 1 𝛼 𝚽𝚽 𝑇 = 𝐊 • ただし、は以下を要素にもつグラム行列 • 𝐾 𝑛𝑚 = 𝑘 𝐱 𝑛, 𝐱 𝑚 = 1 𝛼 𝜙 𝐱 𝑛 𝑇 𝜙 𝐱 𝑚 • 𝑦 𝐱 の平均は、それについての事前知識がないので、対象性より0とする 2015/6/29 42
41.
ガウス過程による回帰 • 目標変数の値に含まれるノイズを考える • 𝑡
𝑛 = 𝑦𝑛 + 𝜖 𝑛 • ノイズがガウス分布に従うとすると • 𝑝 𝑡 𝑛|𝑦𝑛 = 𝒩 𝑡 𝑛|𝑦𝑛, 𝛽−1 • 𝐲 = 𝑦1, … , 𝑦 𝑁 𝑇 が与えられたときの目標値𝐭 = 𝑡1, … , 𝑡 𝑁 𝑇 の同時分布も ガウス分布に従うので • 𝑝 𝐭|𝐲 = 𝒩 𝐭|𝐲, 𝛽−1 𝐈 𝑁 • ガウス過程の定義より、周辺分布𝑝 𝐲 は平均が0、 共分散がグラム行列𝐊で与えられるガウス分布 • 𝑝 𝐲 = 𝒩 𝐲|0, 𝐊 2015/6/29 43
42.
ガウス過程による回帰 • 周辺分布𝑝 𝐭
を求めるためには𝐲についての積分をする必要あり • 𝑝 𝐭 = 𝑝 𝐭|𝐲 𝑝 𝐲 d𝐲 = 𝒩 𝐭|0, 𝐂 • 共分散行列𝐂は • 𝐶 𝐱 𝑛, 𝐱 𝑚 = 𝑘 𝐱 𝑛, 𝐱 𝑚 + 𝛽−1 𝛿 𝑛𝑚 • カーネル関数 • 𝑘 𝐱 𝑛, 𝐱 𝑚 = 𝜃0 exp − 𝜃1 2 𝐱 𝑛 − 𝐱 𝑚 2 + 𝜃2 + 𝜃3 𝐱 𝑛 𝑇 𝐱 𝑚 • 定数と線形の項を加えてある 2015/6/29 44 2.3.3 節の結果より 𝑦 𝐱 の分散 𝜖の分散
43.
共分散行列𝐂 𝑁の意味 • 要素は𝐶
𝐱 𝑛, 𝐱 𝑚 = 𝑘 𝐱 𝑛, 𝐱 𝑚 + 𝛽−1 𝛿 𝑛𝑚 • 例:データ点が4つの場合 • 𝐂4 = 𝑘 𝐱1, 𝐱1 + 𝛽−1 𝑘 𝐱 𝟏, 𝐱 𝟐 𝑘 𝐱 𝟏, 𝐱 𝟑 𝑘 𝐱 𝟏, 𝐱 𝟒 𝑘 𝐱2, 𝐱1 𝑘 𝐱2, 𝐱2 + 𝛽−1 𝑘 𝐱 𝟐, 𝐱 𝟑 𝑘 𝐱 𝟐, 𝐱 𝟒 𝑘 𝐱 𝟑, 𝐱1 𝑘 𝐱 𝟑, 𝐱 𝟐 𝑘 𝐱3, 𝐱3 + 𝛽−1 𝑘 𝐱 𝟑, 𝐱 𝟒 𝑘 𝐱 𝟒, 𝐱 𝟏 𝑘 𝐱 𝟒, 𝐱 𝟐 𝑘 𝐱 𝟒, 𝐱 𝟑 𝑘 𝐱4, 𝐱4 + 𝛽−1 • 各要素は、データ点2つの類似度を表している 2015/6/29 45 ここに注目
44.
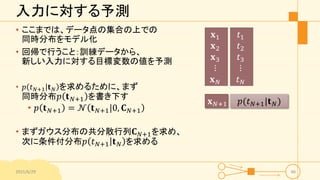
入力に対する予測 • ここまでは、データ点の集合の上での 同時分布をモデル化 • 回帰で行うこと:訓練データから、 新しい入力に対する目標変数の値を予測 •
𝑝 𝑡 𝑁+1 𝐭 𝑁 を求めるために、まず 同時分布 𝑝 𝐭 𝑁+1 を書き下す • 𝑝 𝐭 𝑁+1 = 𝒩 𝐭 𝑁+1|0, 𝐂 𝑁+1 • まずガウス分布の共分散行列 𝐂 𝑁+1を求め、 次に条件付分布 𝑝 𝑡 𝑁+1 𝐭 𝑁 を求める 2015/6/29 46 𝐱1 𝐱2 𝐱3 ⋮ 𝐱 𝑁 𝑡1 𝑡2 𝑡3 ⋮ 𝑡 𝑁 𝐱 𝑁+1 𝑝(𝑡 𝑁+1|𝐭 𝑁)
45.
共分散行列𝐂 𝑁+1 • 𝐂
𝑁+1の導出のため、共分散行列の分割を行う • 𝐂 𝑁+1 = 𝐂 𝑁 𝐤 𝐤 𝑇 𝑐 • 𝐂 𝑁は共分散行列であり、𝐶 𝐱 𝑛, 𝐱 𝑚 = 𝑘 𝐱 𝑛, 𝐱 𝑚 + 𝛽−1 𝛿 𝑛𝑚 • 𝐤は要素𝑘 𝐱 𝑛, 𝐱 𝑁+1 𝑛 = 1, … , 𝑁 を持つベクトル • スカラー 𝑐 = 𝑘 𝐱 𝑁+1, 𝐱 𝑁+1 + 𝛽−1 2015/6/29 47
46.
入力値に対する予測値の平均と共分散 • 2章の結果 • 𝛍
𝑎|𝑏 = 𝛍 𝑎 + 𝚺 𝑎𝑏 𝚺 𝑏𝑏 −1 𝐱 𝑏 − 𝛍 𝑏 • 𝚺 𝑎𝑏 = 𝚺 𝑎𝑎 − 𝚺 𝑎𝑏 𝚺 𝑏𝑏 −1 𝚺 𝑏𝑎 • これを用いて平均と共分散を求めると • 𝑚 𝐱 𝑁+1 = 𝐤 𝑇 𝐂 𝑁 −1 𝐤 • 𝜎2 = 𝑐 − 𝐤 𝑇 𝐂 𝑁 −1 𝐤 • 訓練データの密度によって、予測分布の分散が変化する • 訓練データが多いところほど正確に推定可能 2015/6/29 48 入力と各訓練データ との類似度 データ点に関する 共分散行列
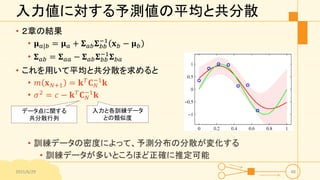
47.
計算量の比較 • ガウス過程 • 𝐱
𝑛, 𝑡 𝑛 𝑛 = 1, … , 𝑁 • 𝑁個の訓練データ • 逆行列計算のコスト:𝑂 𝑁3 • 新入力の計算コスト:𝑂 𝑁2 2015/6/29 49 • 基底関数の和で表す方法(3章) • 𝑦 = 𝐰 𝑇 𝝓 𝐱 • 𝐰と𝝓 𝐱 の次元は𝑀 • 逆行列計算のコスト:𝑂 𝑀3 • 新入力の計算コスト:𝑂 𝑀2 • 計算コストは変わらないが・・・ • ガウス過程では、無限個の基底関数でしか表せないような 共分散行列にも対応可能というメリット • データ点が多すぎる場合は近似手法を用いる
48.
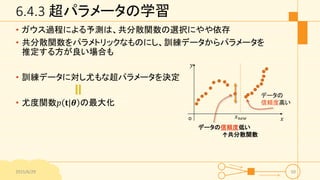
6.4.3 超パラメータの学習 • ガウス過程による予測は、共分散関数の選択にやや依存 •
共分散関数をパラメトリックなものにし、訓練データからパラメータを 推定する方が良い場合も • 訓練データに対し尤もな超パラメータを決定 • 尤度関数𝑝 𝐭|𝜽 の最大化 2015/6/29 50 𝑥 𝑦 o データの 信頼度高い データの信頼度低い ↑共分散関数 𝑥 𝑛𝑒𝑤
49.
超パラメータの最尤推定 • 対数尤度関数は • ln
𝑝 𝐭|𝜽 = − 1 2 ln 𝐂 𝑁 − 1 2 𝐭T 𝐂 𝑁 −1 𝐭 − 𝑁 2 ln 2𝜋 • これを微分したものは • 𝜕 𝜕𝜃 𝑖 ln 𝑝 𝐭|𝜽 = − 1 2 Tr 𝐂 𝑁 −1 𝜕𝐂 𝑁 𝜕𝜃 𝑖 + 1 2 𝐭T 𝐂 𝑁 −1 𝜕𝐂 𝑁 𝜕𝜃 𝑖 𝐂 𝑁 −1 𝐭 • Tr はトレース(対角成分の和) • ベイズ的に取り扱うためには、𝑝 𝐭|𝜽 と𝑝 𝜽 の積を𝜽で積分(周辺化) • 厳密な周辺化は不可能 → 近似 2015/6/29 51
50.
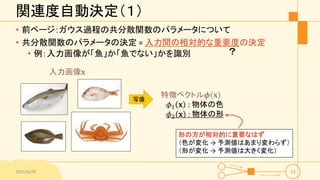
関連度自動決定(1) • 前ページ:ガウス過程の共分散関数のパラメータについて • 共分散関数のパラメータの決定
= 入力間の相対的な重要度の決定 • 例:入力画像が「魚」か「魚でない」かを識別 2015/6/29 52 入力画像𝐱 特徴ベクトル𝝓 𝐱 𝜙1 𝐱 : 物体の色 𝜙2 𝐱 : 物体の形 写像 形の方が相対的に重要なはず (色が変化 → 予測値はあまり変わらず) (形が変化 → 予測値は大きく変化) ?
51.
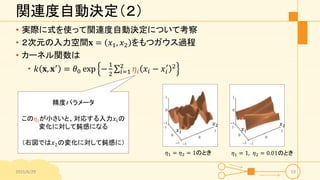
関連度自動決定(2) • 実際に式を使って関連度自動決定について考察 • 2次元の入力空間𝐱
= 𝑥1, 𝑥2 をもつガウス過程 • カーネル関数は • 𝑘 𝐱, 𝐱′ = 𝜃0 exp − 1 2 𝑖=1 2 𝜂𝑖 𝑥𝑖 − 𝑥𝑖 ′ 2 2015/6/29 53 精度パラメータ この𝜂𝑖が小さいと、対応する入力𝑥𝑖の 変化に対して鈍感になる (右図では𝑥2の変化に対して鈍感に) 𝑥1 𝑥2 𝑥1 𝑥2 𝜂1 = 𝜂2 = 1のとき 𝜂1 = 1, 𝜂2 = 0.01のとき
52.
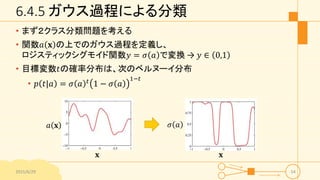
6.4.5 ガウス過程による分類 • まず2クラス分類問題を考える •
関数𝑎 𝐱 の上でのガウス過程を定義し、 ロジスティックシグモイド関数𝑦 = 𝜎 𝑎 で変換 → 𝑦 ∈ 0,1 • 目標変数𝑡の確率分布は、次のベルヌーイ分布 • 𝑝 𝑡|𝑎 = 𝜎 𝑎 𝑡 1 − 𝜎 𝑎 1−𝑡 2015/6/29 54 𝐱 𝑎 𝐱 𝜎 𝑎 𝐱
53.
ガウス過程による分類 • 入力の訓練集合:𝐱1, …
𝐱 𝑁 , 目標変数の観測値:𝐭 𝑁 = 𝑡1, … 𝑡 𝑁 𝑇 • テスト点の入力:𝐱 𝑁+1, その目標変数値𝑡 𝑁+1 • 求めるもの:予測分布𝑝 𝑡 𝑁+1|𝐭 • 𝐚 𝑁+1に対するガウス過程による事前分布は • 𝑝 𝐚 𝑁+1 = 𝒩 𝐚 𝑁+1|0, 𝐂 𝑁+1 • 共分散行列𝐂 𝑁+1の各要素は • 𝐶 𝐱 𝑛, 𝐱 𝑚 = k 𝐱 𝑛, 𝐱 𝑚 + 𝜈𝛿 𝑛𝑚 2015/6/29 55
54.
ガウス過程による分類 • 2クラス分類問題においては、次の値を予測 • 𝑝
𝑡 𝑁+1 = 1|𝐭 𝑁 = 𝑝 𝑡 𝑁+1 = 1|𝑎 𝑁+1 𝑝 𝑎 𝑁+1|𝐭 𝑁 d𝑎 𝑁+1 • ここで𝑝 𝑡 𝑁+1 = 1|𝑎 𝑁+1 = 𝜎 𝑎 𝑁+1 • 解析的に求めることは不可能 → 近似 • サンプリングによる近似 • ガウス分布による近似 1. 変分推論法(10.1節) 2. EP法(10.7節) 3. ラプラス近似(本節、次スライド) 2015/6/29 56
55.
6.4.6 ラプラス近似 • ベイズの定理と𝑝
𝐭 𝑁|𝑎 𝑁+1, 𝐚 𝑁 = 𝑝 𝐭 𝑁|𝐚 𝑁 を用いることにより 𝑝 𝑎 𝑁+1|𝐭 𝑁 = 𝑝 𝑎 𝑁+1, 𝐚 𝑁|𝐭 𝑁 d𝐭 𝑁 = 1 𝑝 𝐭 𝑁 𝑝 𝑎 𝑁+1, 𝐚 𝑁 𝑝 𝐭 𝑁|𝑎 𝑁+1, 𝐚 𝑁 d𝐚 𝑁 = 1 𝑝 𝐭 𝑁 𝑝 𝑎 𝑁+1|𝐚 𝑁 𝑝 𝐚 𝑁 𝑝 𝐭 𝑁|𝐚 𝑁 d𝐚 𝑁 = 𝑝 𝑎 𝑁+1|𝐚 𝑁 𝑝 𝐚 𝑁|𝐭 𝑁 d𝐚 𝑁 ここで𝑝 𝑎 𝑁+1|𝐚 𝑁 = 𝒩 𝑎 𝑁+1|𝐤 𝑇 𝐂 𝑁 −1 𝐚 𝑁, 𝑐 − 𝐤 𝑇 𝐂 𝑁 −1 𝐤 より、 𝑝 𝑎 𝑁+1|𝐭 𝑁 は2つのガウス分布のたたみ込みによって得られる 2015/6/29 57 ラプラス近似する
56.
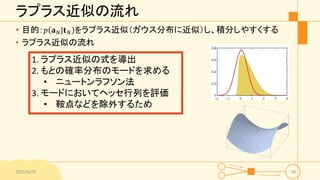
ラプラス近似の流れ • 目的: 𝑝
𝐚 𝑁|𝐭 𝑁 をラプラス近似(ガウス分布に近似)し、積分しやすくする • ラプラス近似の流れ 2015/6/29 58 1. ラプラス近似の式を導出 2. もとの確率分布のモードを求める • ニュートンラフソン法 3. モードにおいてヘッセ行列を評価 • 鞍点などを除外するため
57.
ステップ1 ラプラス近似の式を導出 • 事前分布
𝑝 𝐚 𝑁 は、平均が0で共分散行列が𝐂 𝑁であるガウス過程 • データについての項は • 𝑝 𝐭 𝑁|𝐚 𝑁 = 𝑛=1 𝑁 𝜎 𝑎 𝑛 𝑡 𝑛 1 − 𝜎 𝑎 𝑛 1−𝑡 𝑛 = 𝑛=1 𝑁 𝑒 𝑎 𝑛 𝑡 𝑛 𝜎 −𝑎 𝑛 • テイラー展開により𝑝 𝐚 𝑁|𝐭 𝑁 の対数を展開し、ラプラス近似を得る • Ψ 𝐚 𝑛 = ln 𝑝 𝐚 𝑛 + ln 𝑝 𝐭 𝑁|𝐚 𝑁 = − 1 2 𝐚 𝑁 𝑇 𝐂 𝑁 −1 𝐚 𝑁 − 𝑁 2 ln 2𝜋 − 1 2 ln 𝐂 𝑁 + 𝐭 𝑁 T 𝐚N − 𝑛=1 𝑁 ln 1 + 𝑒 𝑎 𝑛 2015/6/29 59
58.
ステップ2 もとの確率分布のモードを求める • Ψ
𝐚 𝑛 の勾配を求める • 𝛻Ψ 𝐚 𝑛 = 𝐭 𝑛 − 𝝈 𝑁 − 𝐂 𝑁 −1 𝐚 𝑛 • ニュートンラフソン法により勾配が0になる点を近似的に求める • 再反復重み付け最小二乗 • Ψ 𝐚 𝑛 の2階微分は • 𝛻𝛻Ψ 𝐚 𝑛 = −𝐖 𝑁 − 𝐂 𝑁 −1 • 𝐖 𝑁は 𝜎 𝑎 𝑛 1 − 𝜎 𝑎 𝑛 を要素に持つ対格行列 • ニュートンラフソン法による逐次更新式 • 𝐚 𝑁 𝑛𝑒𝑤 = 𝐂 𝑁 𝐼 + 𝑊𝑁 𝐶 𝑁 −1 𝐭 𝑁 − 𝛔 𝑁 + 𝐖 𝑁 𝐚 𝑁 • 勾配が0になる点において満たす条件 • 𝐚 𝑁 ∗ = 𝐂 𝑁 𝐭 𝑁 − 𝛔 𝑁 2015/6/29 60 𝝈 𝑁 = 𝜎 𝑎1 , … , 𝜎 𝑎 𝑁 𝑇
59.
ステップ3 ヘッセ行列の評価、積分 • 𝐇
= −𝛻𝛻Ψ 𝐚 𝑛 = 𝐖 𝑁 + 𝐂 𝑁 −1 • これを評価し𝑝 𝐚 𝑁|𝐭 𝑁 のガウス分布による近似を求めると • 𝑞 𝐚 𝑁 = 𝒩 𝐚 𝑁|𝐚 𝑁 ∗ , 𝐇−1 • これらの結果からガウス分布のたたみ込み積分を求めると(2.115式) • 𝔼 𝑎 𝑁+1| 𝐭 𝑁 = 𝐤 𝑇 𝐭 𝑁 − 𝛔 𝑁 • var 𝑎 𝑁+1| 𝐭 𝑁 = 𝑐 − 𝐤 𝑇 𝐖 𝑁 + 𝐂 𝑁 −1 −1 𝐤 2015/6/29 61
60.
共分散関数のパラメータ𝜽の決定 • 尤度関数を最大化することにより求める • 共分散行列𝐂
𝑁と訓練データ点のモード𝐚 𝑁 ∗ の両方が𝜽に依存する • 対数尤度の勾配は • 𝜕 ln 𝑝 𝐭 𝑁|𝜽 𝜕𝜃 𝑗 = 1 2 𝐚 𝑁 ∗ 𝑇 𝐂 𝑁 −1 𝜕𝐂 𝑁 𝜕𝜃 𝑗 𝐂 𝑁 −1 𝐚 𝑁 ∗ − 1 2 Tr 𝐼 + 𝐂 𝑁 𝐖 𝑁 −1 𝐖 𝑁 𝜕𝐂 𝑁 𝜕𝜃 𝑗 • 𝜽の要素𝜃𝑗についての微分は • − 1 2 𝑛=1 𝑁 𝜕 ln 𝐖 𝑁+𝐂 𝑁 −1 𝜕𝐚 𝑁 ∗ 𝜕𝐚 𝑁 ∗ 𝜃 𝑗 = − 1 2 𝑛=1 𝑁 𝐼 + 𝐂 𝑁 𝐖 𝑁 −1 𝐂 𝑁 𝑛𝑛 𝜎 𝑛 ∗ 1 − 𝜎 𝑛 ∗ 1 − 2𝜎 𝑛 ∗ 𝜕𝑎 𝑁 ∗ 𝜕𝜃 𝑗 • このうち、 𝜕𝑎 𝑁 ∗ 𝜕𝜃 𝑗 = 𝐼 + 𝐂 𝑁 𝐖 𝑁 −1 𝜕𝐂 𝑁 𝜕𝜃 𝑗 𝐭 𝑁 − 𝛔 𝑁 • これらの式と、非線形最適化アルゴリズムにより𝜽を決定 2015/6/29 62
61.
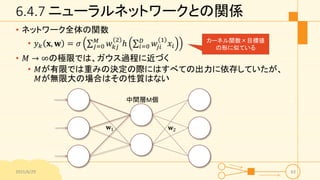
6.4.7 ニューラルネットワークとの関係 • ネットワーク全体の関数 •
𝑦 𝑘 𝐱, 𝐰 = 𝜎 𝑗=0 𝑀 𝑤 𝑘𝑗 2 ℎ 𝑖=0 𝐷 𝑤𝑗𝑖 1 𝑥𝑖 • 𝑀 → ∞の極限では、ガウス過程に近づく • 𝑀が有限では重みの決定の際にはすべての出力に依存していたが、 𝑀が無限大の場合はその性質はない 2015/6/29 63 𝐰2𝐰1 中間層M個 カーネル関数×目標値 の形に似ている
Editor's Notes
#4
まずは今までのモデルと比較しながらカーネル法の概要を説明
#13
双対表現とは一般に、別の・・・ yをDの式であらわすとカーネル関数が出現
#21
式変形して保障されてることを確認
#23
特徴ベクトルを明示的に構成するのが難しい場合もある、だからといってどんな関数でもカーネルとして使っていいわけではない
#25
カーネル関数の種類をみていきます
#28
生成モデルを用いたカーネル関数の定義について少し説明 この章にはほぼ式だけ載っていて、詳しいことは9章と13章で説明 さまざまに条件iを変えたうえでの内積
#29
パラメトリックということは、パラメータθの値を決めれば生成モデルの形が決まる このため、抽出されたデータ点に対して、パラメータの尤もらしさつまり尤度関数を定義できる
#30
パラメトリックということは、パラメータθの値を決めれば生成モデルの形が決まる このため、抽出されたデータ点に対して、パラメータの尤もらしさつまり尤度関数を定義できる
#33
RBFを使用する理由として、目的変数ではなく入力変数にノイズが含まれるようなモデルにも対応
#35
左のグラフの縦軸が基底関数hの値
#36
パルツェン推定法を用いるとxとtの同時分布が得られる しかし同時分布ということは
#40
ガウス過程という単語の意味はおいておいて・・・
#47
ここまでは、データ点の集合の上での 同時分布をガウス分布の枠組みでモデル化
#50
パラメータと基底関数の次元はM 新入力の計算:新しい入力があったときに行列とベクトルを計算するとスト
#51
2行目 共分散関数をあらかじめ固定せず、
#52
最尤法によりθを決定することもできるが、ベイズ的に
#59
確率分布p(an|tn)をガウス分布に・・・ 中段 まずは確率分布をラプラス近似した式を求めます 次にその式から・・・
#62
中段 2章の一般的な式から
Download










































































![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)







![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)










