






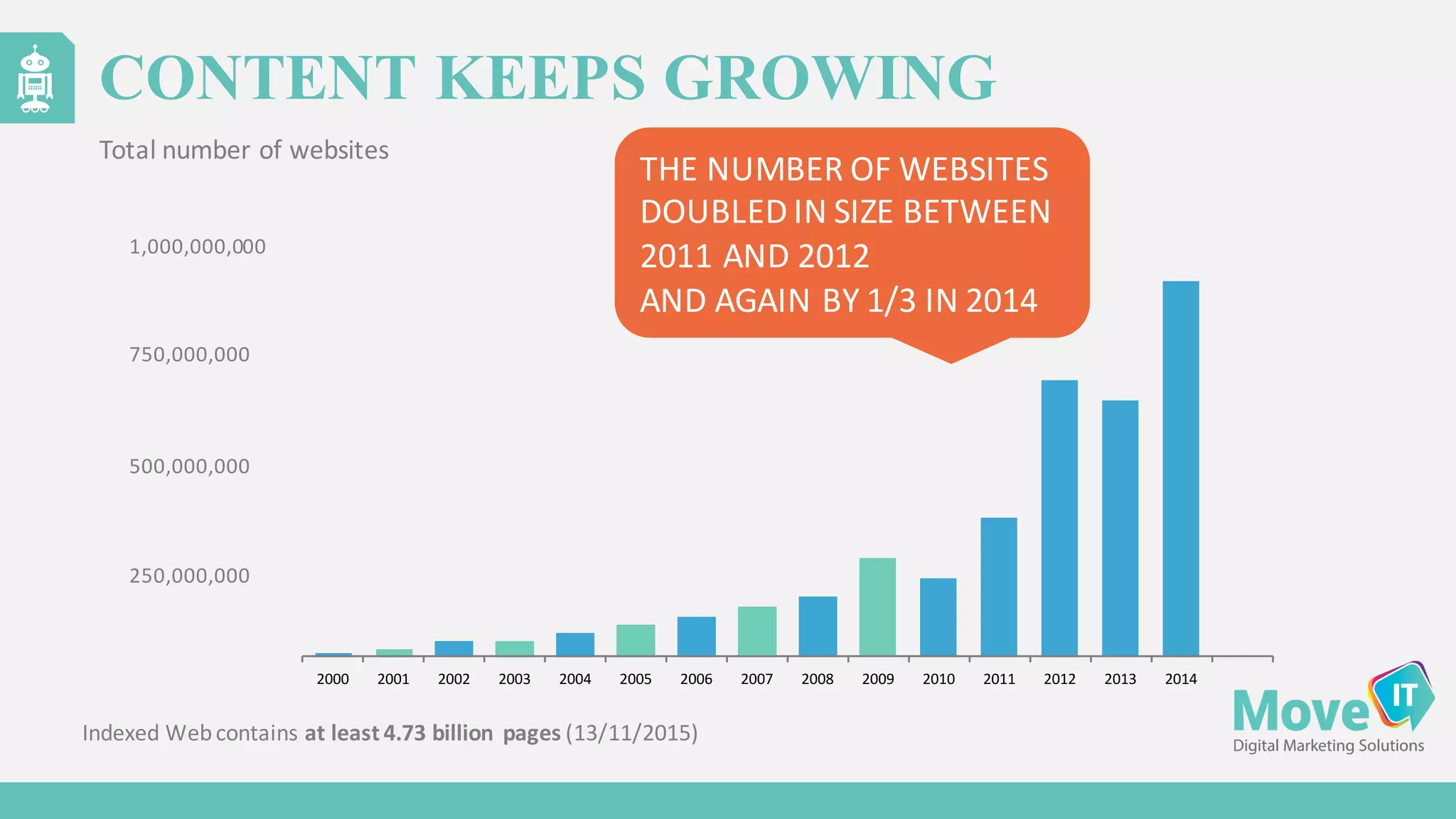


















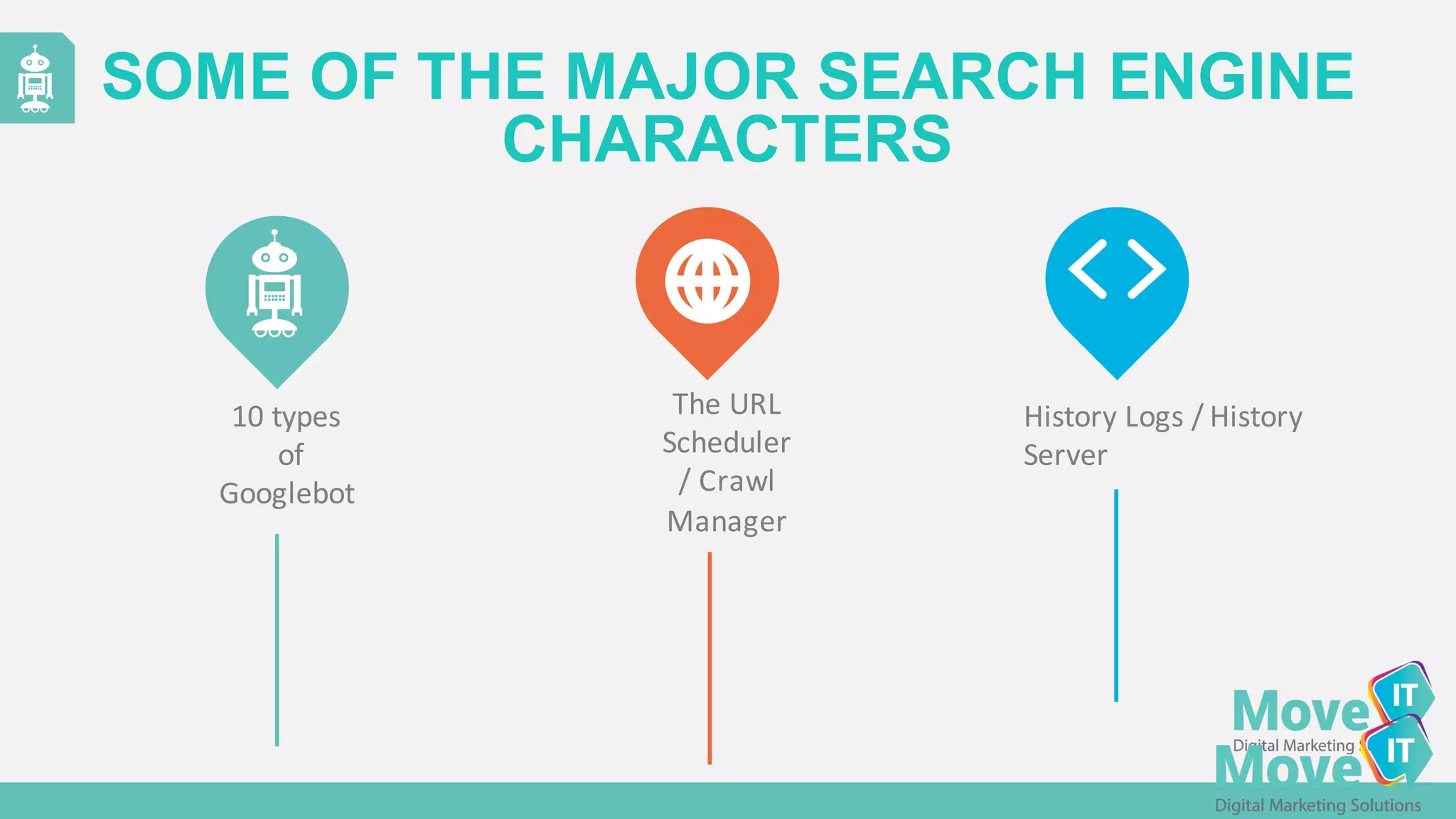






























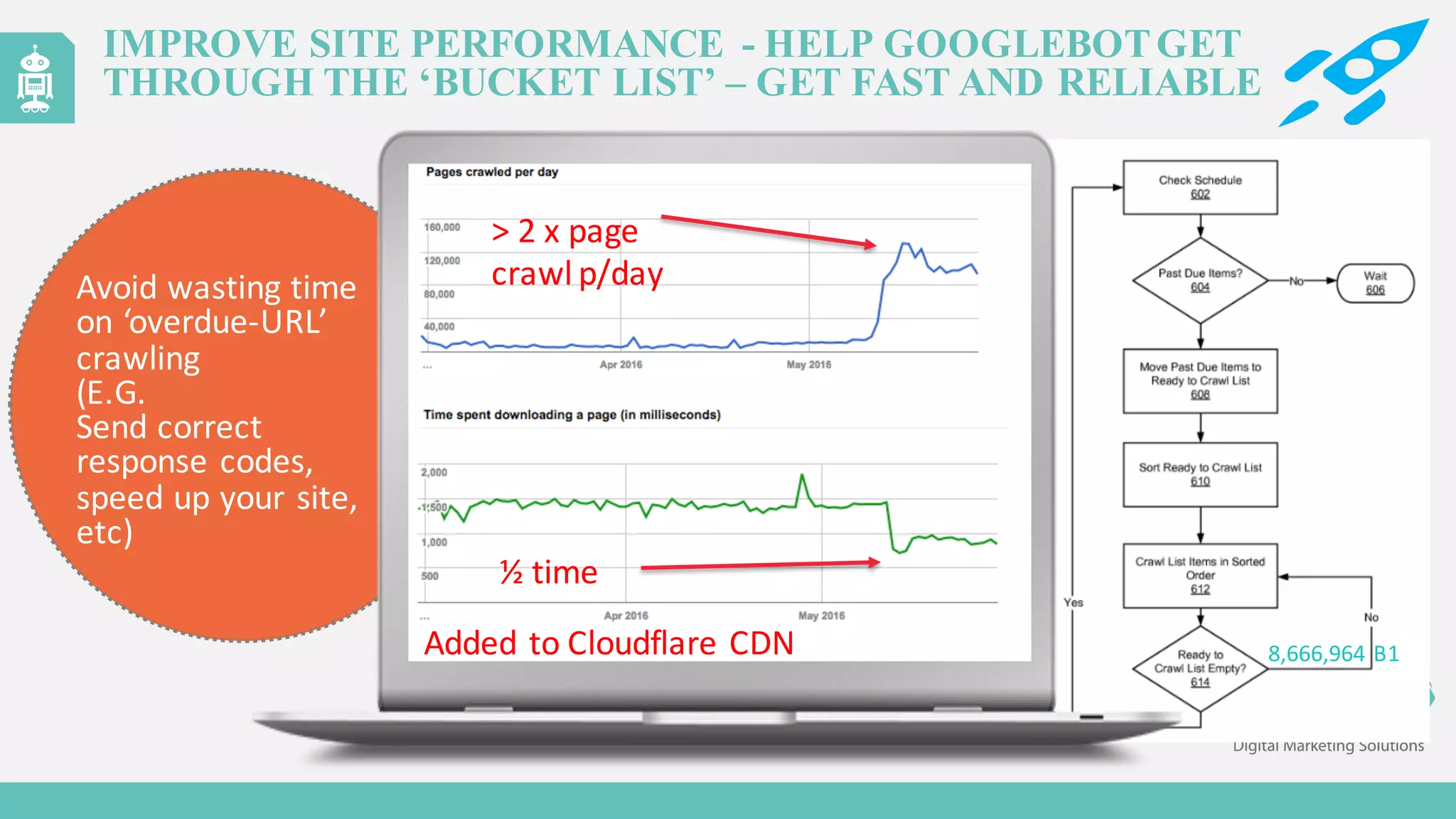




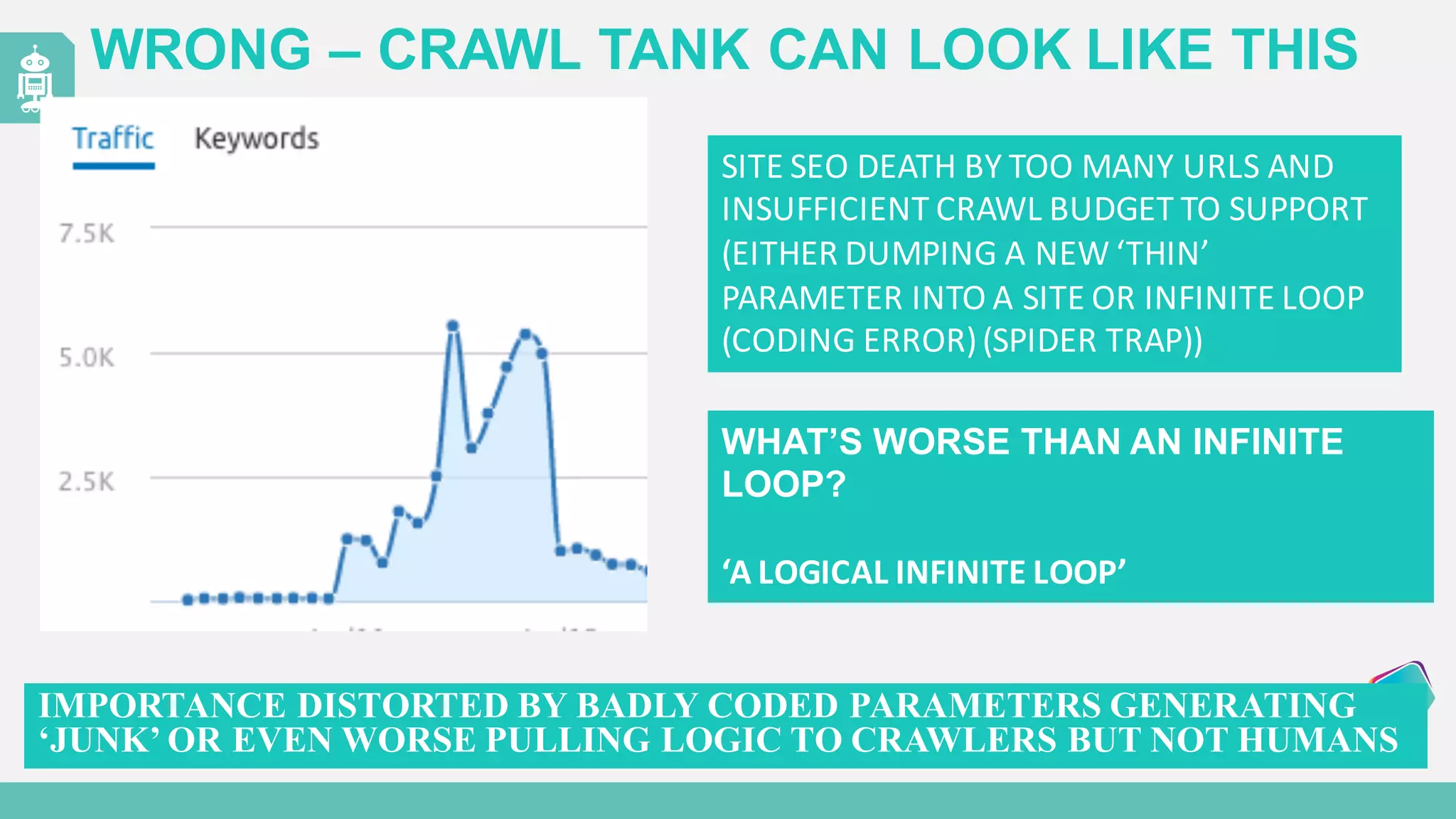


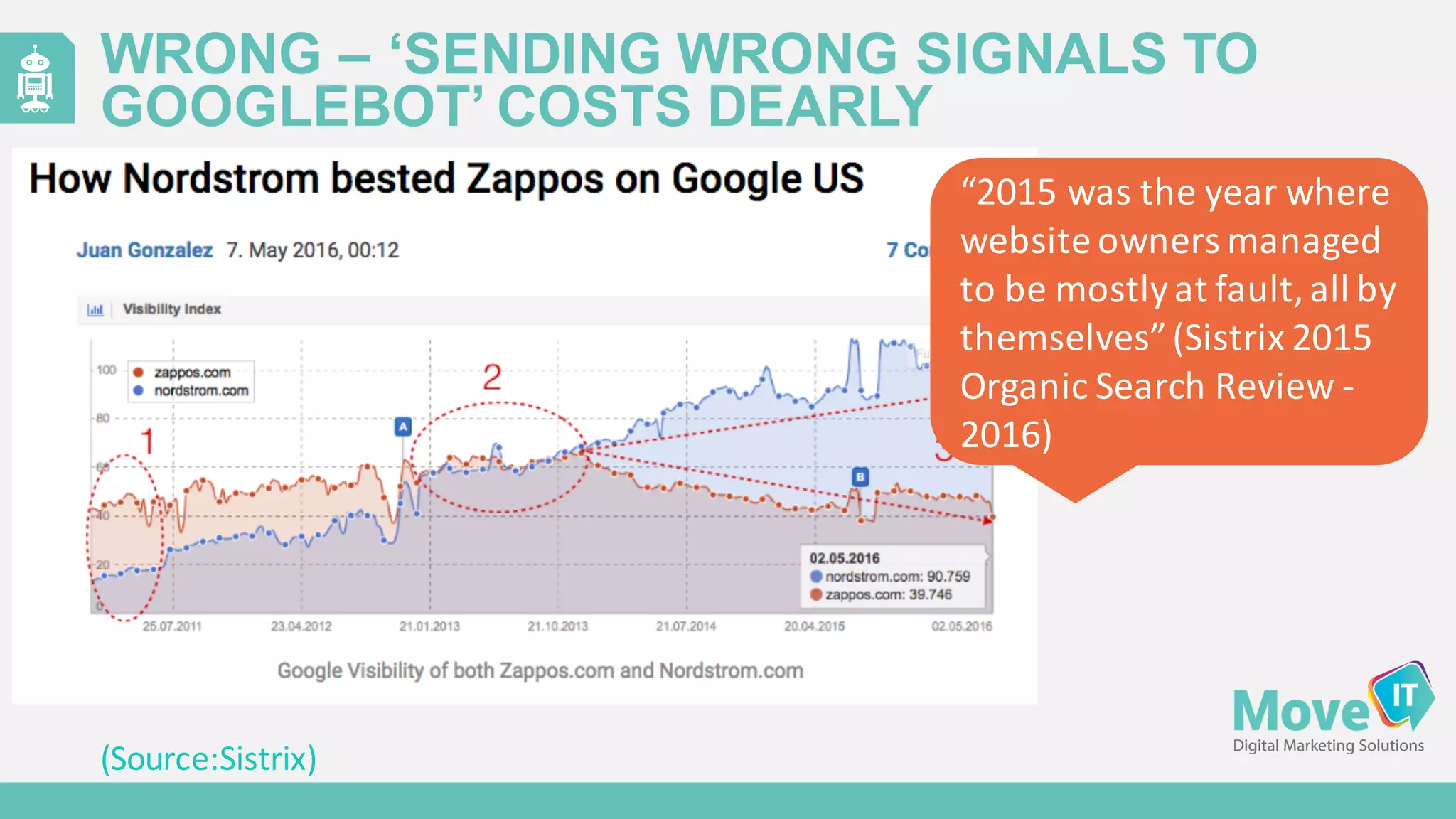
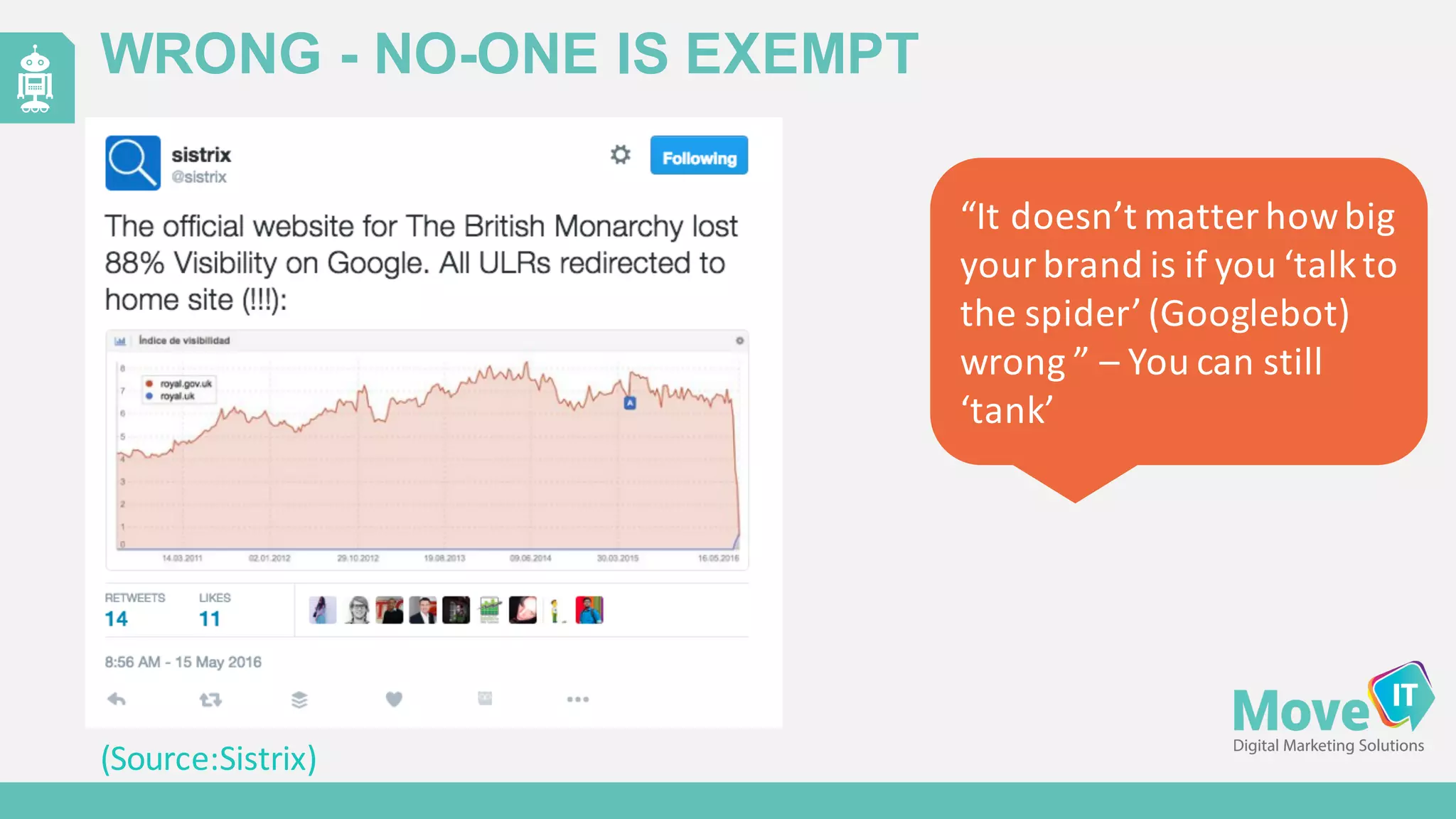





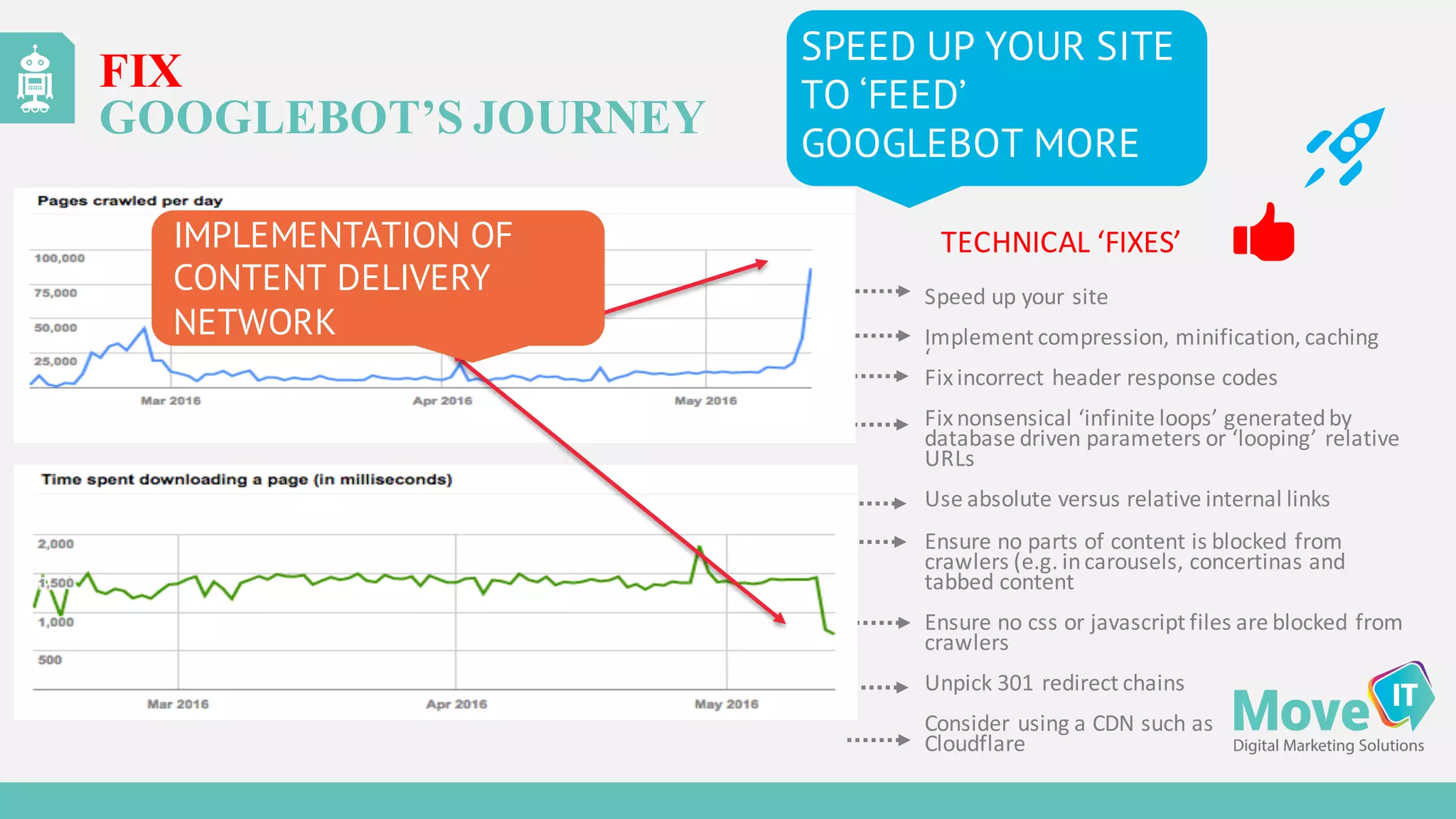








The document discusses the evolution of web content generation and Google's crawling mechanisms, highlighting the growth of user-generated content and the challenges of managing crawl budgets. It details how Googlebot prioritizes which pages to crawl based on factors like page importance, server performance, and historical data. Additionally, it outlines strategies for webmasters to improve their site's crawlability and subsequently influence their search engine visibility.














![Content Design & its Role in SEO and Accessibility [BrightonSEO Spring 2023]](https://cdn.slidesharecdn.com/ss_thumbnails/bseocontentdesignitsroleinseoandaccessibility-230419114610-31da7d19-thumbnail.jpg?width=640&height=640&fit=bounds)



























































































