






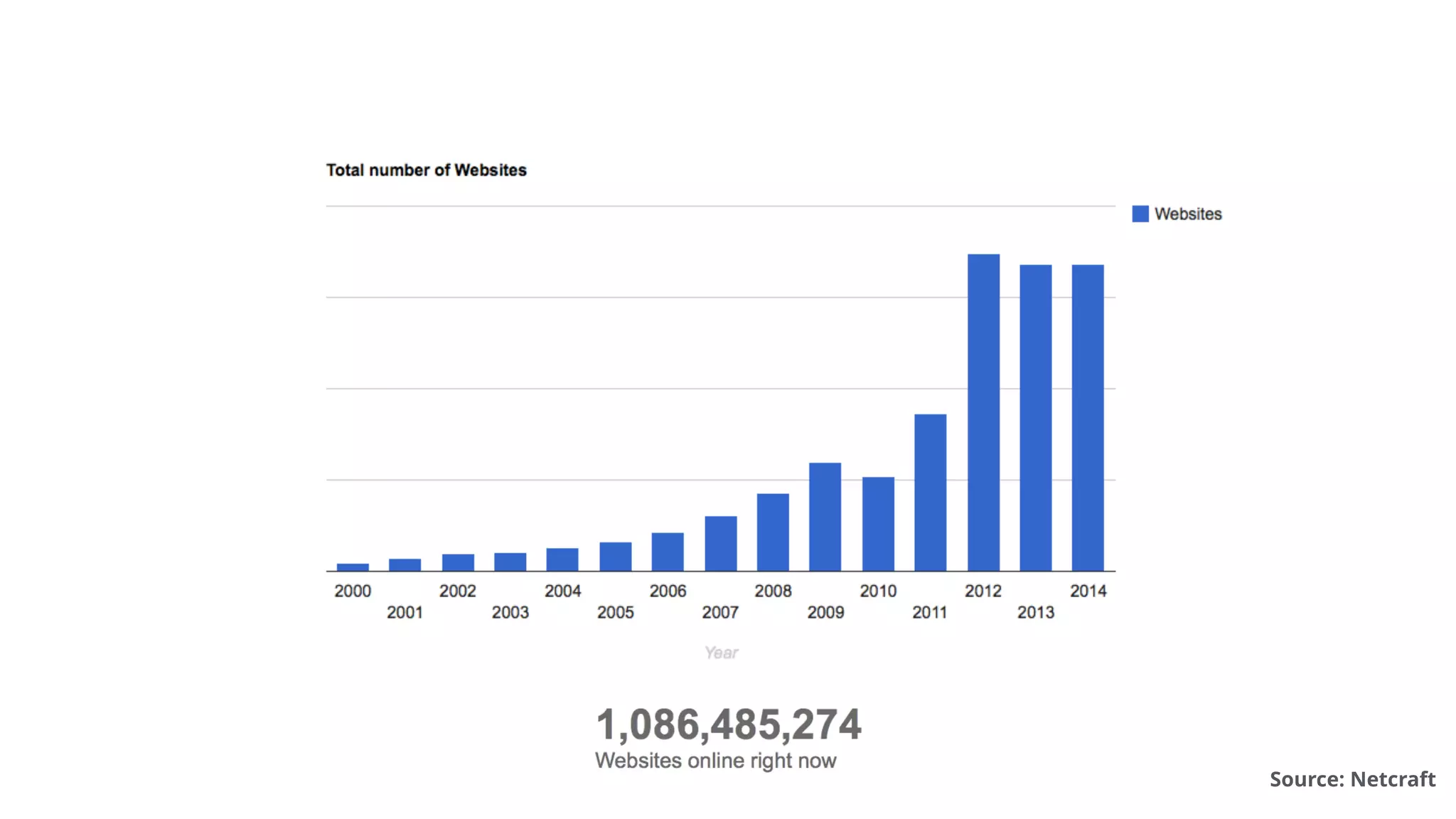





























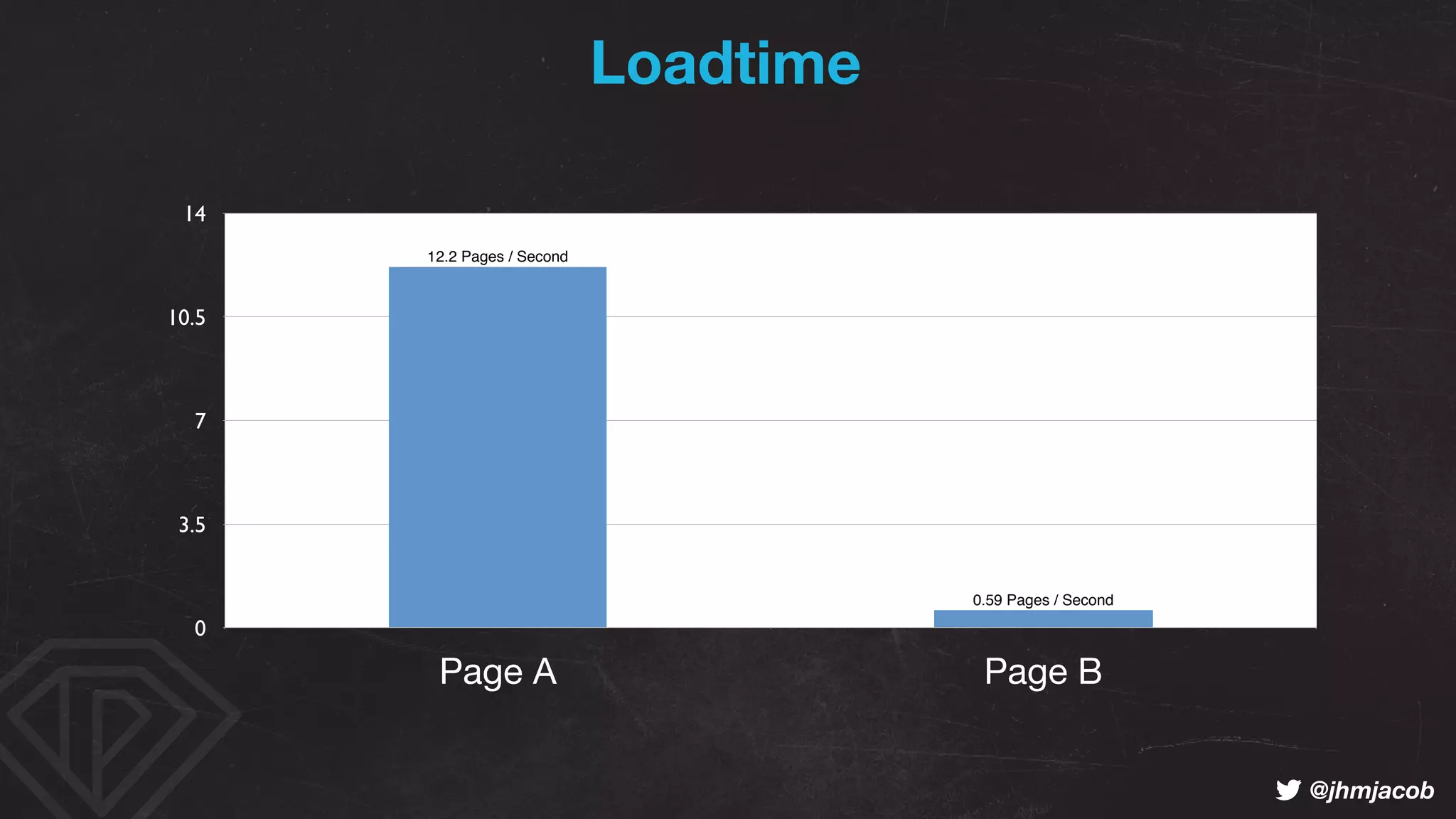





























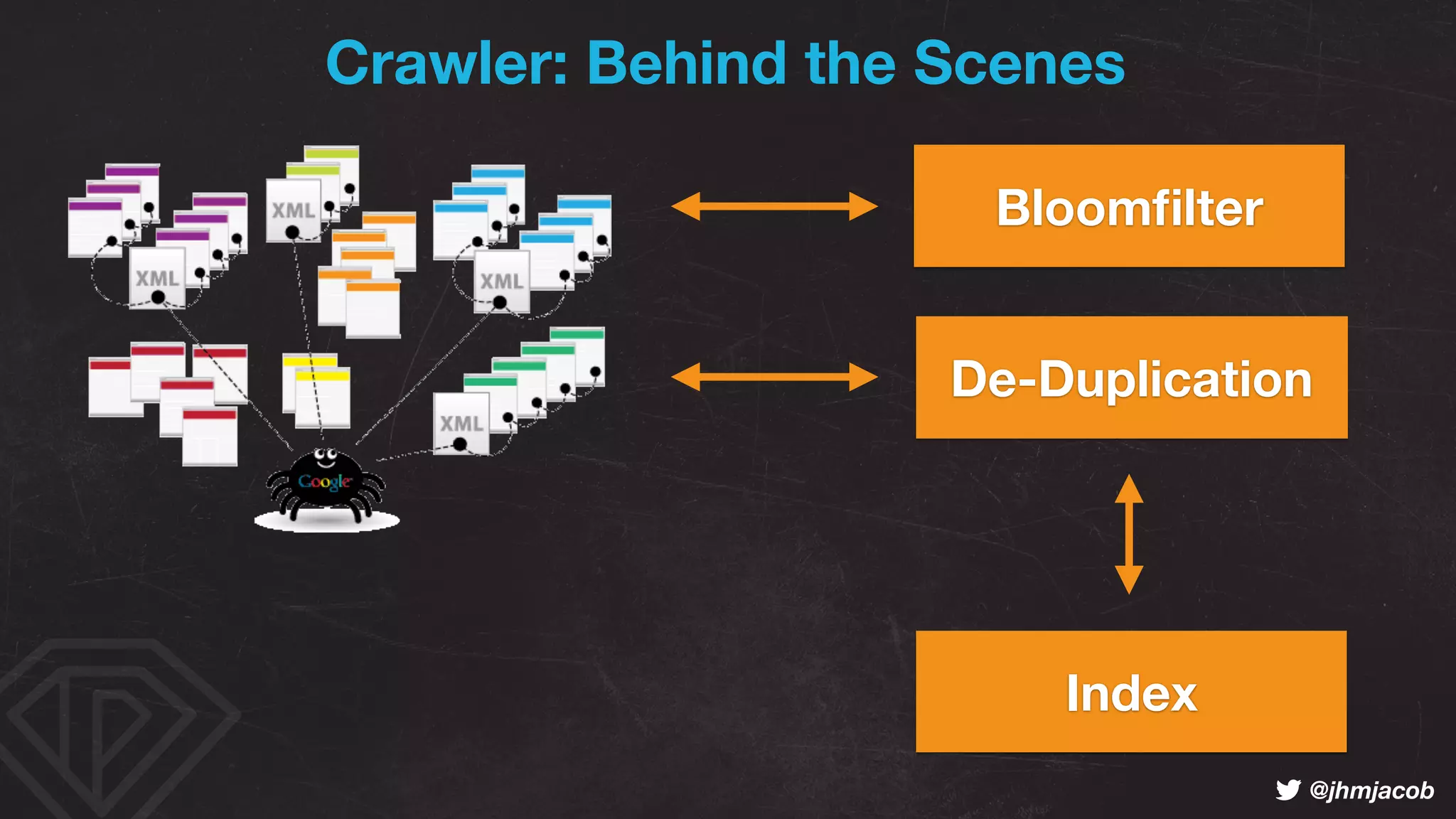


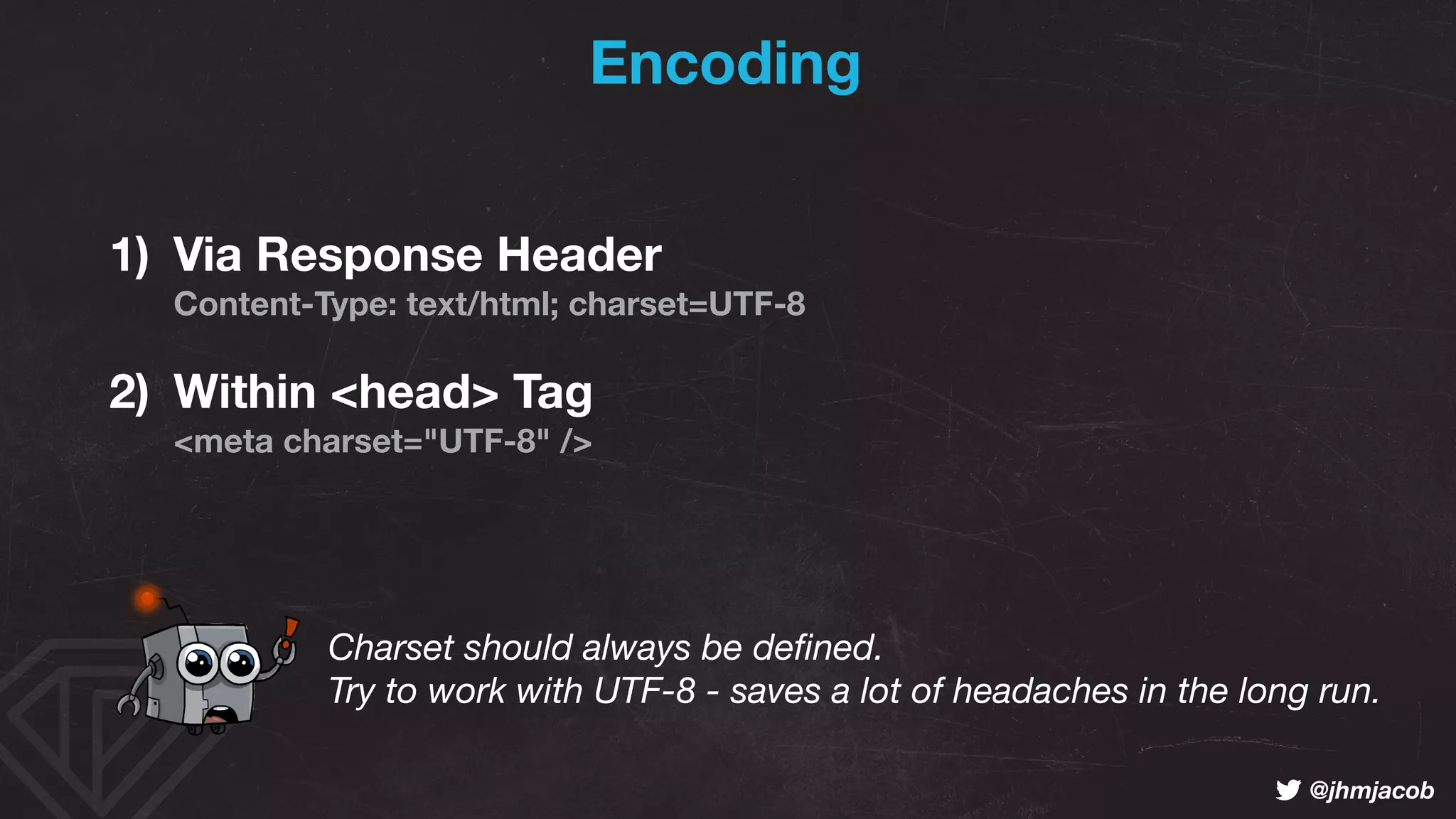










































The document outlines strategies to optimize a website's crawl budget, emphasizing the importance of clear, deep, and easily found content to enhance indexing by search engines like Google and Bing. It discusses the impact of website structure, internal linking, and content quality on crawl efficiency and searchability, while also highlighting technical aspects like robots.txt configuration and response codes. Best practices are recommended to improve the crawlability, indexability, and rankability of web pages, thereby maximizing visibility in search results.


















































![Website Audit [On Page and Off Page] by Carl Benedic Pantaleon](https://cdn.slidesharecdn.com/ss_thumbnails/websiteauditonpageandoffpage-181119200930-thumbnail.jpg?width=640&height=640&fit=bounds)


































