Download to read offline
























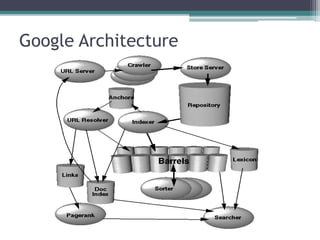




















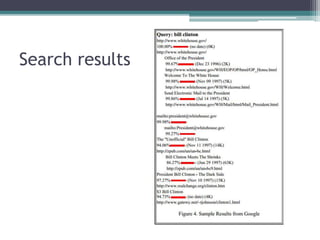




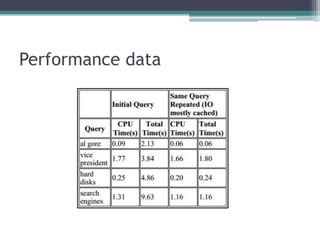











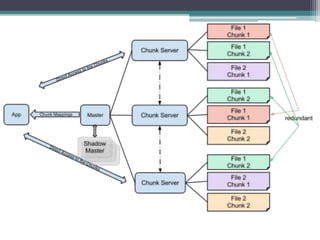











The paper presents Google, a large-scale web search engine prototype created by Sergey Brin and Lawrence Page. It addresses problems with existing search engines like returning too many low-quality results. The paper describes Google's use of PageRank, which assigns importance scores to pages based on the page's links, and its index structure. It also discusses Google's architecture including data structures like BigFiles and techniques for crawling, indexing, and searching the web rapidly and at scale. The paper concludes Google met its goals of building a scalable search engine that provides high-quality results.













































