Download as PDF, PPTX



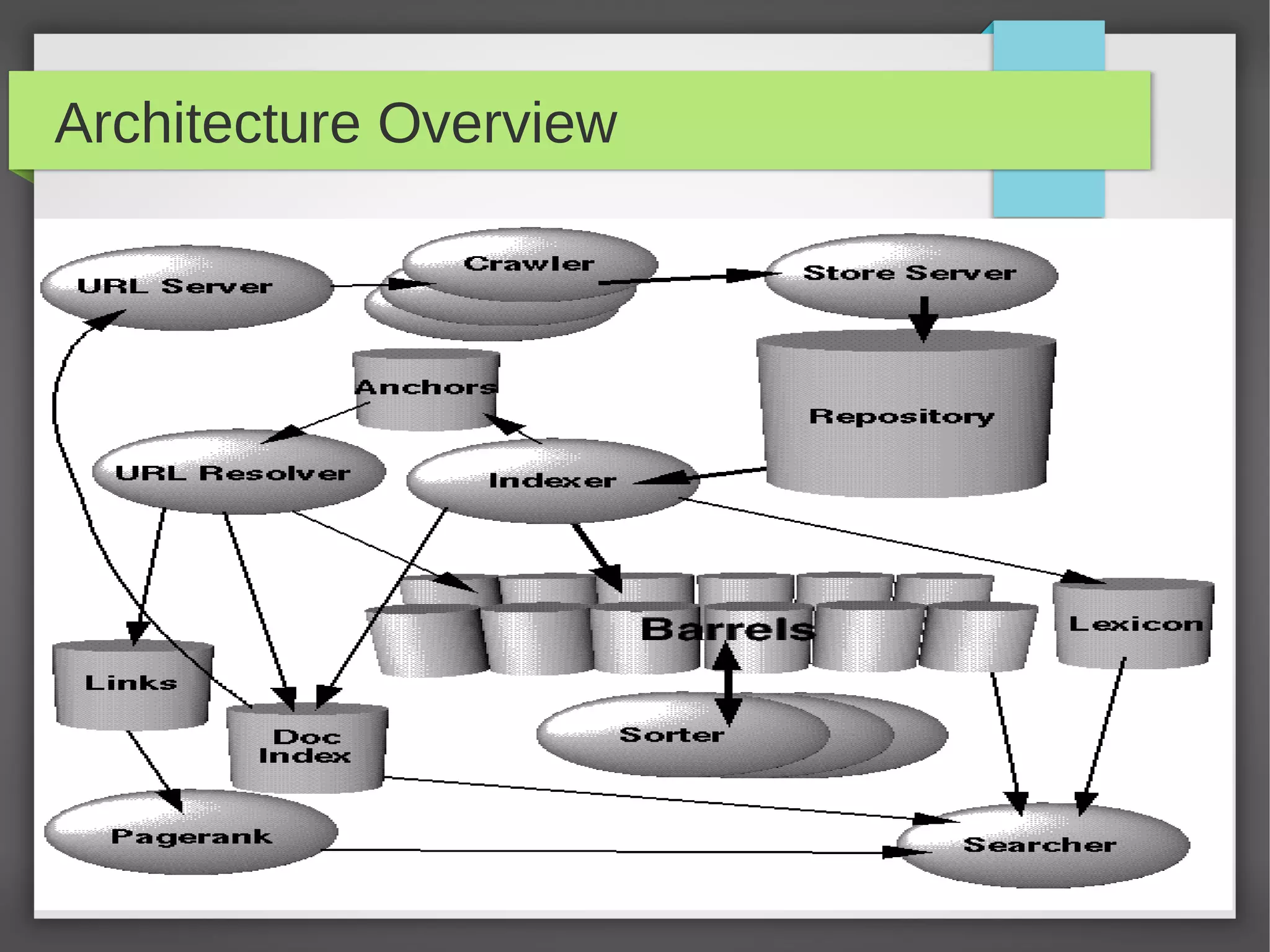





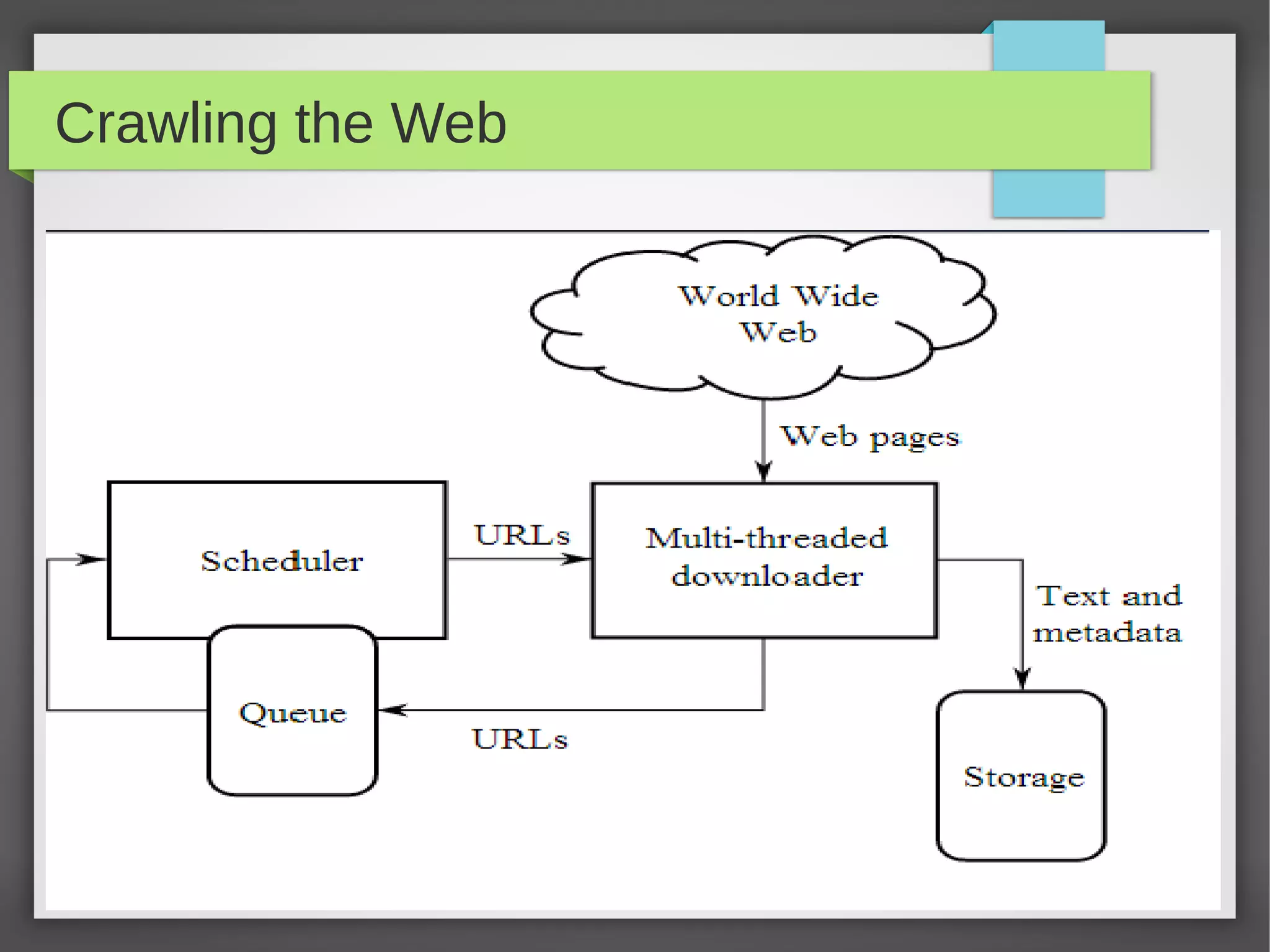

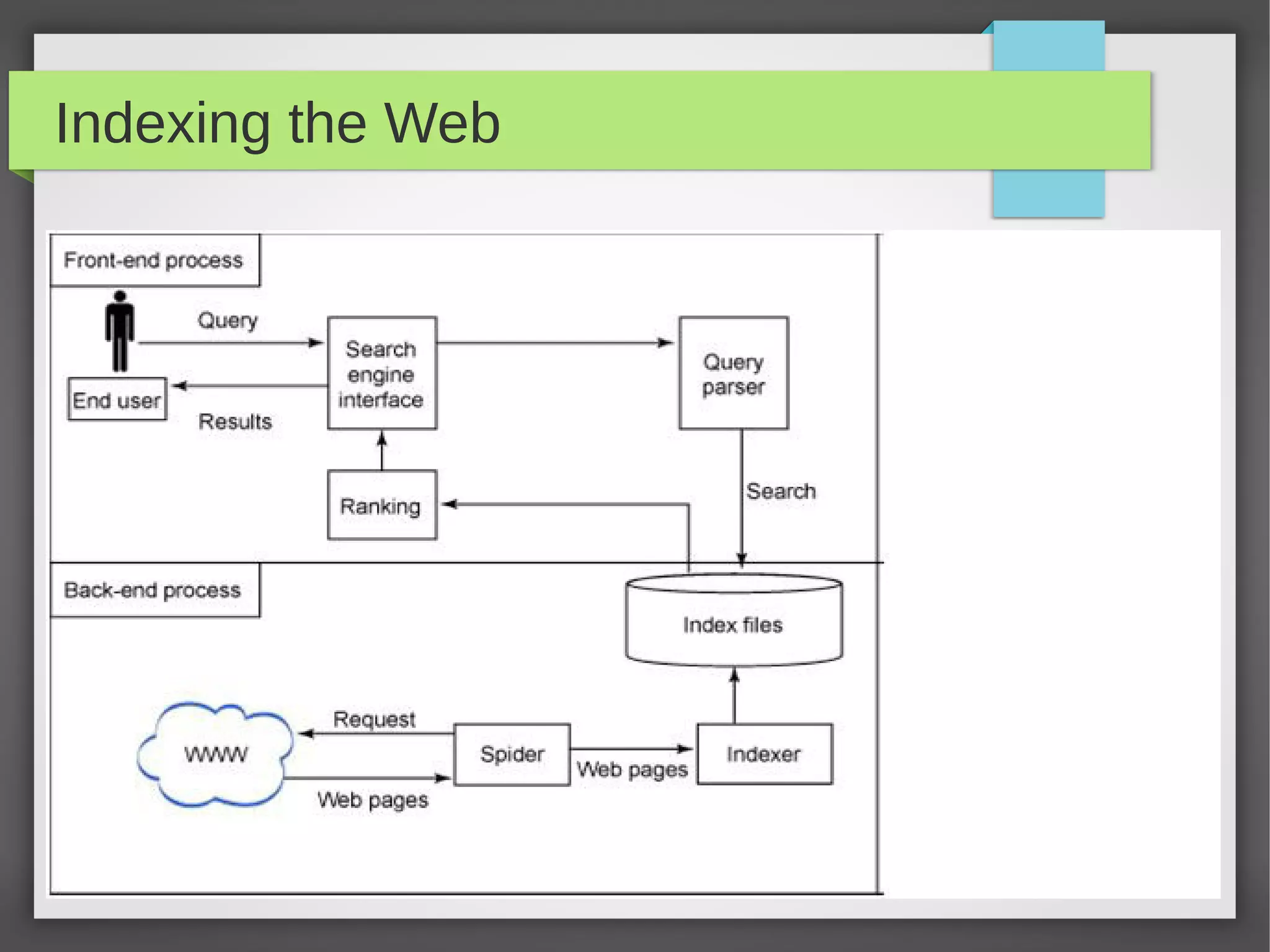

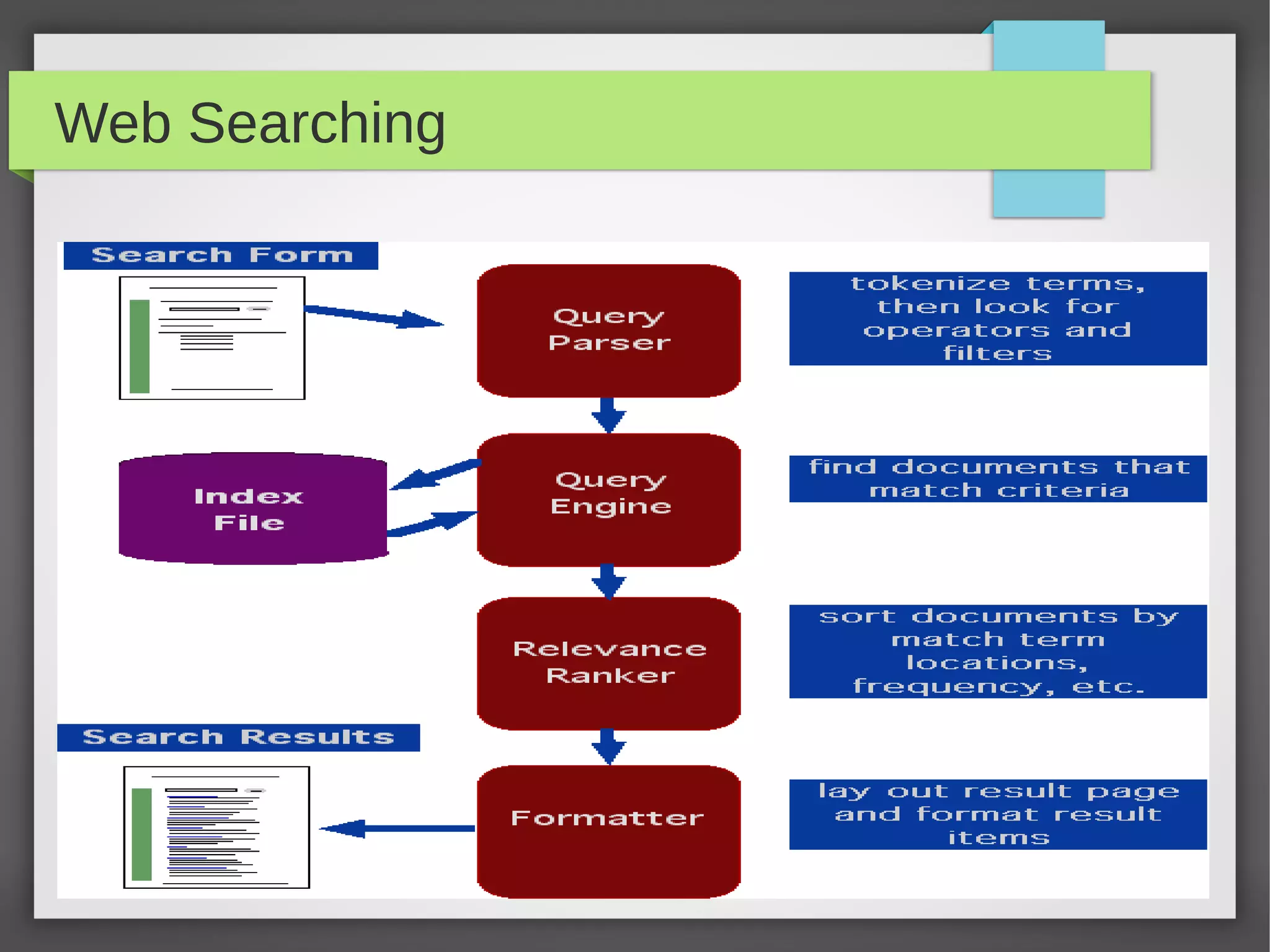











This document provides an overview of how search engines work. It discusses the key components of a search engine including crawling websites to index their content, calculating page ranks, building inverted indexes, and using these components to return relevant results for user queries. The future of search engines is focused on improving result quality over the rapidly growing web through techniques like understanding user intent from queries.



























































