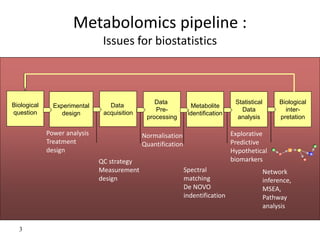
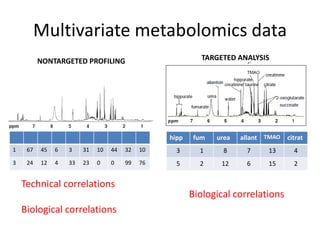
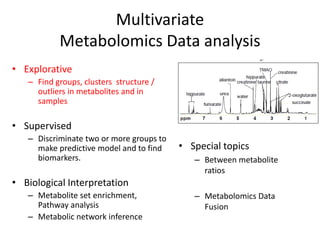
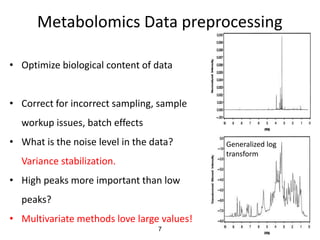
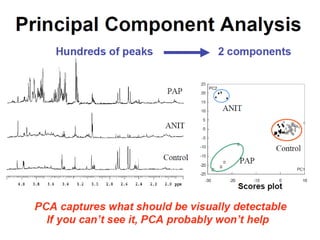
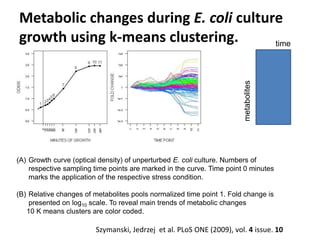
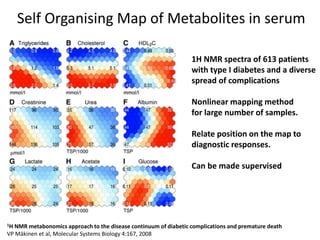
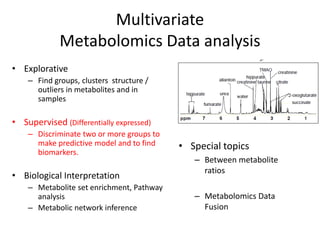
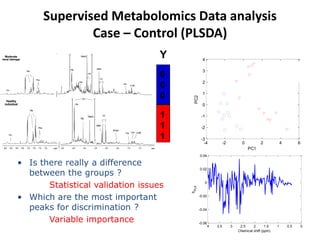
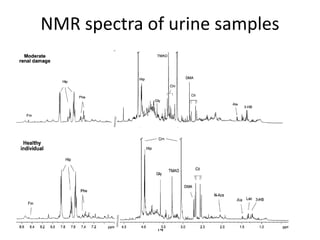
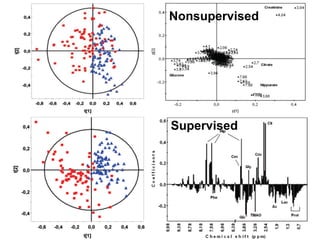
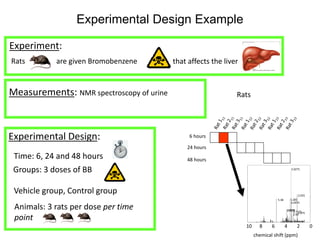
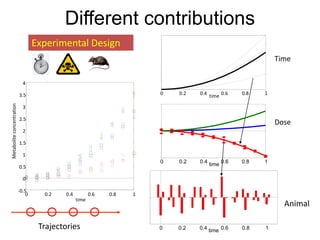
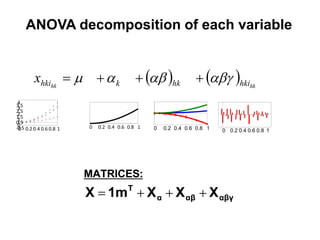
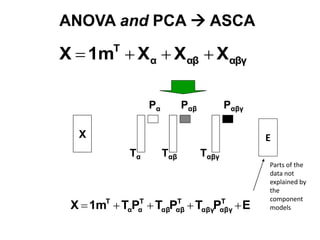
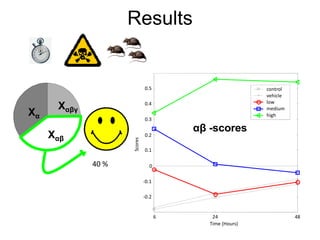
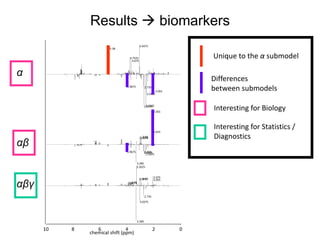
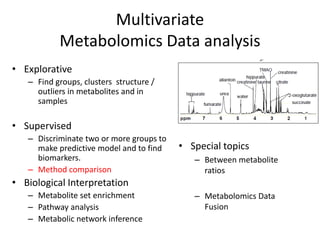
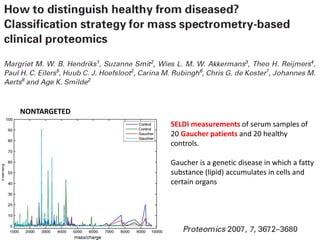
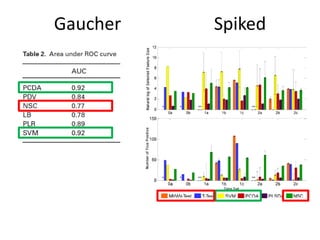
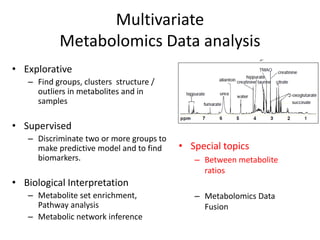
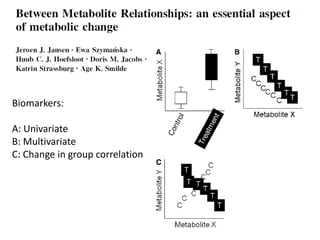
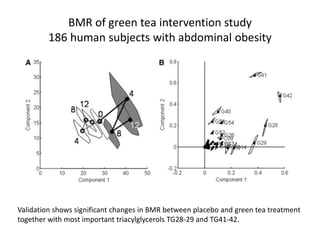
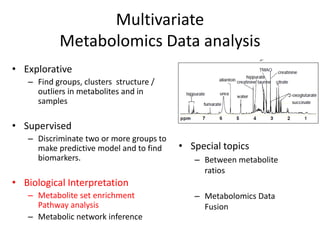
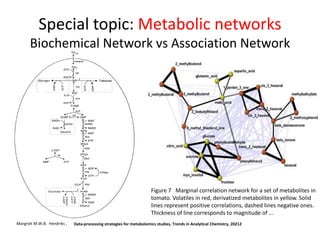
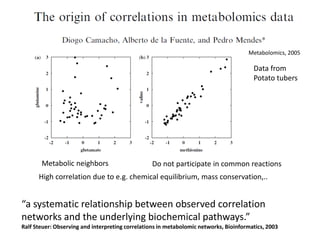
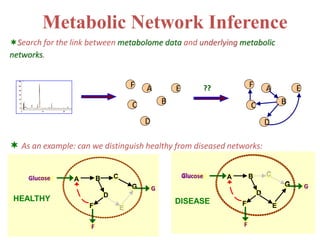
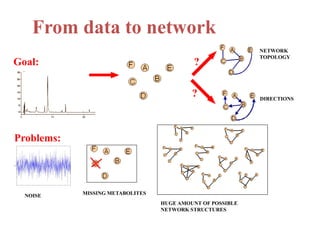
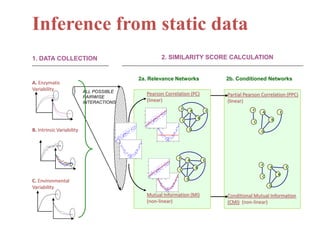
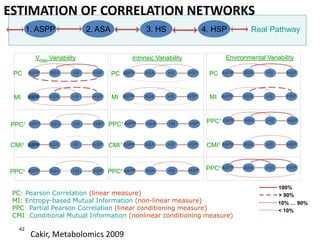
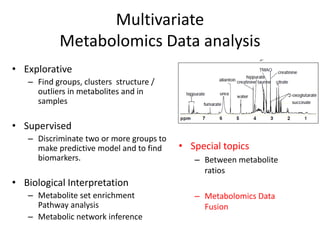
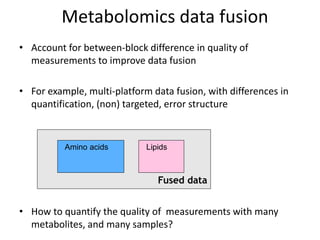
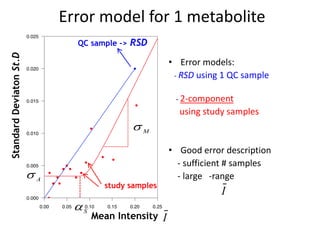
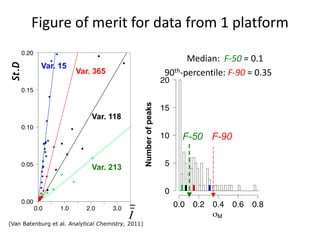
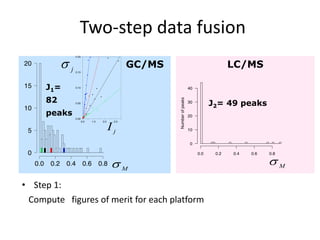
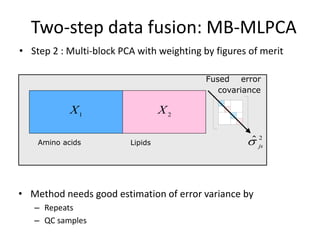
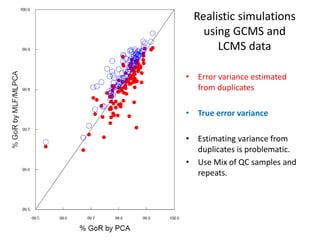
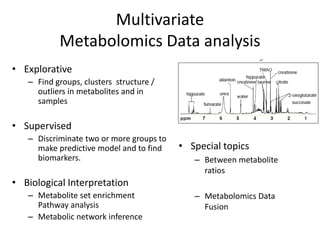
The document discusses metabolomics data analysis and issues for biostatistics. It describes the metabolomics pipeline from experimental design and data acquisition to statistical analysis and biological interpretation. Key aspects covered include data preprocessing methods, exploratory and supervised multivariate analysis, and biological interpretation tools like metabolic network inference and pathway analysis. Specific statistical challenges in metabolomics like handling non-detects and exploring variable importance are also addressed.