


















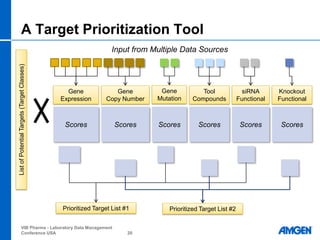


The document discusses the large amount of data, known as "omics" data, being generated from various biological studies. It is becoming difficult for scientists to sift through this flood of multi-omics data from different experimental sources and literature. Key challenges include a lack of data integration, different data formats and annotations, and bottlenecks in data storage, transfer, analysis and sharing. The large volumes and complexity of the data affect various stakeholders like information technologists, bioinformaticians, and scientists in different ways depending on their needs and roles. Next-generation sequencing in particular generates an enormous amount of raw read data per sample that requires extensive processing and summarization to extract useful biological insights.






























































